







这篇文章主要介绍了python爬取微信小程序,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。

url = “https://www.xbiquge.la/”
headers = { ‘User-agent’:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67’}
def main():
html_text = requests.get(url = url, headers = headers).text
#解析
<span class="token comment">#先实例化一个etree对象</span>
html_etree_object <span class="token operator">=</span> etree<span class="token punctuation">.</span>HTML<span class="token punctuation">(</span>html_text<span class="token punctuation">)</span>
passage_title_list1 <span class="token operator">=</span> html_etree_object<span class="token punctuation">.</span>xpath<span class="token punctuation">(</span><span class="token string">"//div/dl/dt/a[@href]"</span><span class="token punctuation">)</span>
passage_addre_list1 <span class="token operator">=</span> html_etree_object<span class="token punctuation">.</span>xpath<span class="token punctuation">(</span><span class="token string">"//dt/a/@href"</span><span class="token punctuation">)</span>
fp <span class="token operator">=</span> <span class="token builtin">open</span><span class="token punctuation">(</span><span class="token string">'data.txt'</span><span class="token punctuation">,</span><span class="token string">'w'</span><span class="token punctuation">,</span>encoding<span class="token operator">=</span><span class="token string">'utf-8'</span><span class="token punctuation">)</span>
<span class="token comment"># print(passage_title_list1)</span>
<span class="token comment"># print(passage_addre_list1)</span>
<span class="token comment"># print(passage_title_list1[0].xpath('./text()'))</span>
#局部解析并写入文件
for (ti,ad) in zip(passage_title_list1,passage_addre_list1):
#print(ti.xpath(“./text()”),ad) ti.xpath(“./text()”)是局部解析,注意需要是./text(),特别注意点号“ . ”不能少!!
fp.write(ti.xpath(“./text()”)[0] + “:” + ad + ‘\n’)
fp.close()
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
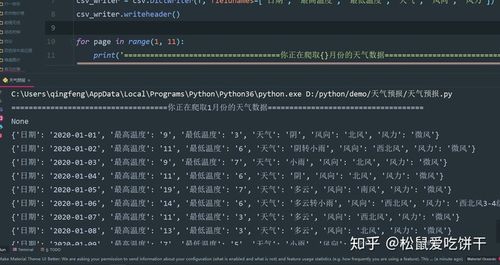
结果:
4k图片网站图片爬取
爬取结果:
图片存入文件夹
4k图片网站:4K壁纸_4K手机壁纸_4K高清壁纸大全_电脑壁纸_4K,5K,6K,7K,8K壁纸图片素材_彼岸图网
import requests
from lxml import etree
import os
def get_picture():
try:
url = “https://pic.netbian.com/4kdongman/index_2.html”
headers = { ‘User-agent’:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36’}
#抓取网页
html_pic = requests.get(url = url , headers = headers)
#查看状态码,若不是200返回异常
html_pic.raise_for_status()
#编码utf-8
html_pic.encoding = html_pic.apparent_encoding
#使用xpath数据解析
html_text = html_pic.text
etree_html = etree.HTML(html_text)
li_list = etree_html.xpath(‘//div[@class=“slist”]/ul/li’)
#创建文件夹
if not os.path.exists(‘./pictures1’):
os.mkdir(‘./pictures1’)
#写入文件picture1
for li in li_list:
#局部解析出图片地址和名字
pic_add =“https://pic.netbian.com/” + li.xpath(“./a/img/@src”)[0]#注意xpath返回一个列表所以取下标[0],而且返回的地址不完全,所以在网址上打开看一下,把少的域名补上
pic_name = li.xpath(“./a/img/@alt”)[0] + ‘.jpg’
img_data = requests.get(url = pic_add,headers = headers).content
img_path = “pictures1/” + pic_name
with open(img_path,‘ab’) as fp:
fp.write(img_data)
print(pic_name,“保存成功!”)
fp.close()
except:
return“产生异常”
def main():
get_picture()
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
结果展示:

简历模板爬取
爬取结果:
简历模板的压缩包保存到文件夹中
简历模板网站:免费简历模板 个人简历模板 简历模板免费下载-站长素材。
代码如下:(注释已注明)
import requests
from lxml import etree
import os
def main():
url = “https://sc.chinaz.com/jianli/free.html”
headers = { ‘User-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36’}
down_data(url, headers)
url_set = set()
#把每一页的url放到一个容器里(有待完善,不能爬取足够多的网址,比如789页)
url_set = get_url(url,headers,url_set)
for urll in url_set:
down_data(urll,headers)
def get_url(url,headers,url_set):#此函数有待完善,缺点是只能爬取第一页的几个分页链接
#其实这个也应该使用try-except
html_text = requests.get(url = url ,headers = headers ).text
html_tree = etree.HTML(html_text)
lable_list = html_tree.xpath(‘//div[@class=“pagination fr clearfix clear”]/a’)
for lable_ in lable_list[2:7]:
lable_url = “https://sc.chinaz.com/jianli/” + lable_.xpath(“./@href”)[0]
url_set.add(lable_url)
return url_set
def down_data(url,headers):
try:
html_ = requests.get(url = url,headers = headers)
#print(“状态码”,html_.status_code)
html_.raise_for_status()
html_.encoding = html_.apparent_encoding
#页面解析
html_text = html_.text
html_tree = etree.HTML(html_text)
<span class="token comment">#局部解析</span>
<span class="token comment">#下载地址列表</span>
loadadd_lable_list <span class="token operator">=</span> html_tree<span class="token punctuation">.</span>xpath<span class="token punctuation& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4699
4699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









