







一、hadoop本地运行模式介绍
默认的模式,无需运行任何守护进程,所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
使用本地文件系统,而不是分布式文件系统。
Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
用于对MapReduce程序的逻辑进行调试,确保程序的正确。
所谓默认模式,及安装完jdk及hadoop,配置好相应的环境,及本地模式配置完成。
二、hadoop本地运行模式环境搭建
2.1 创建虚拟机
在本文章中,hadoop的搭建是基于 VMware12 虚拟的 CentOS 6.8 系统,下面来讲解一下如何使用 VMware12 来虚拟一个 Centos 6.8 系统。
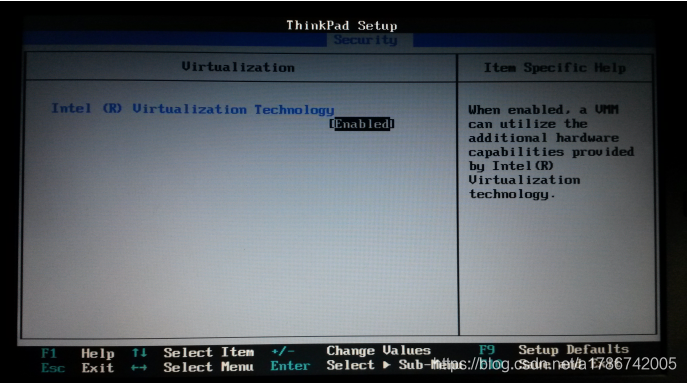
1、检查BIOS虚拟化支持
每台电脑进入BIOS的方式都不同,可以查看自己电脑型号,自行百度。
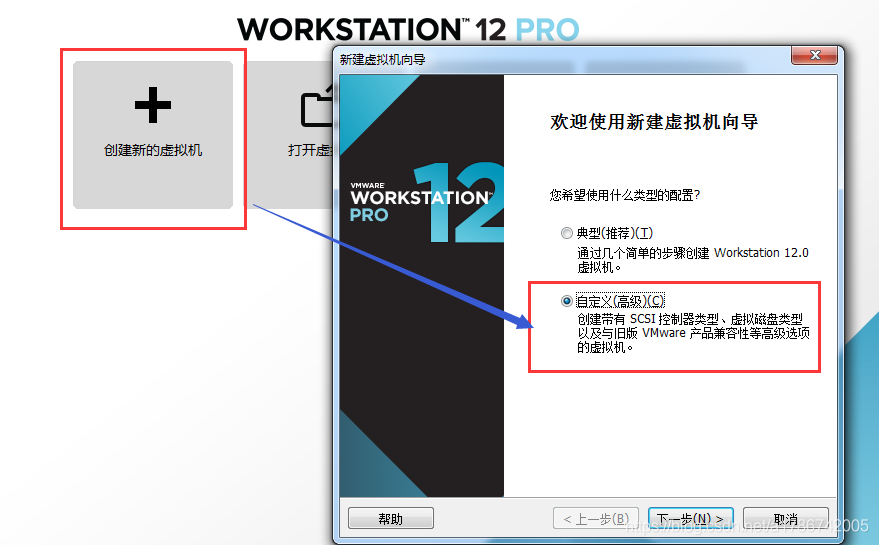
2、新建虚拟机
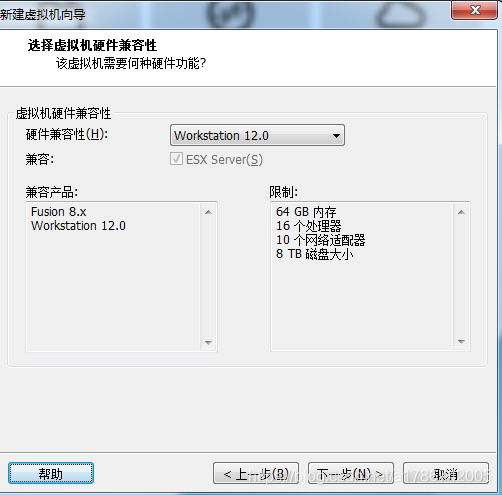
3、新建虚拟机向导
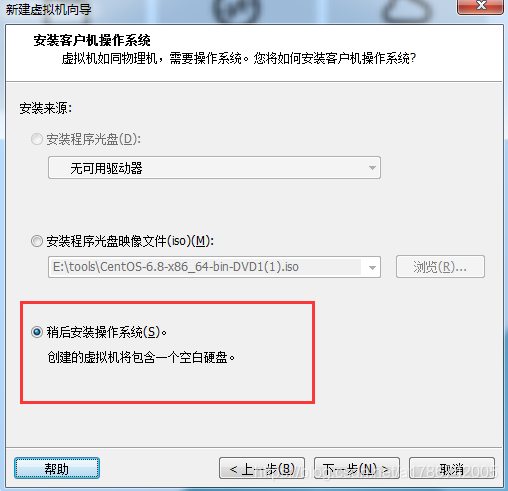
4、创建虚拟空白光盘
5、安装Linux系统对应的CentOS 64位

6、虚拟机命名和定位磁盘位置
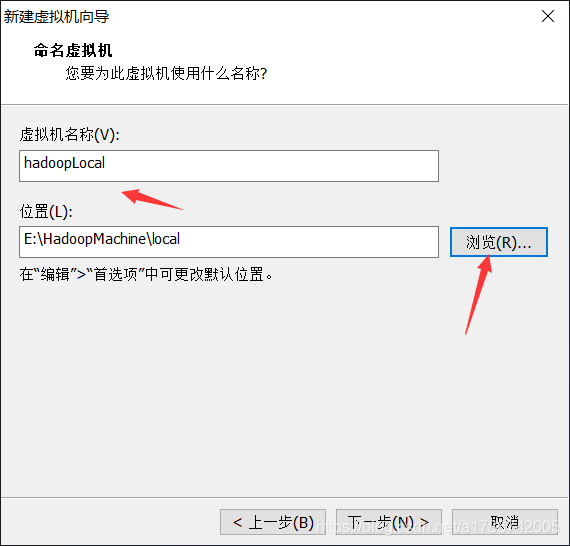
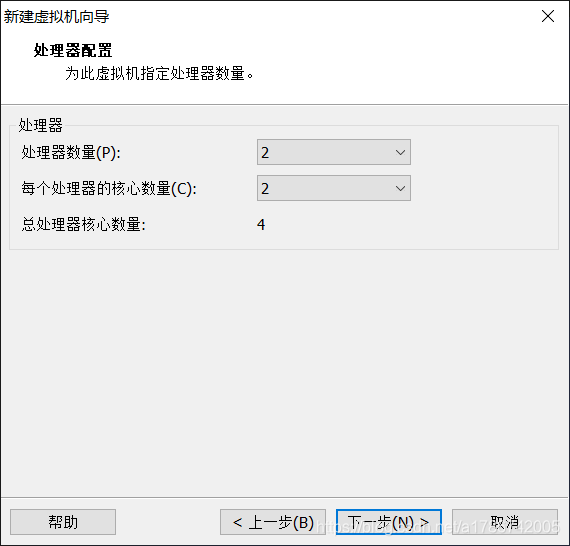
7、处理器配置
虚拟机处理器数量可以根据自己的机器配置来定,点击电脑的属性即可查看。
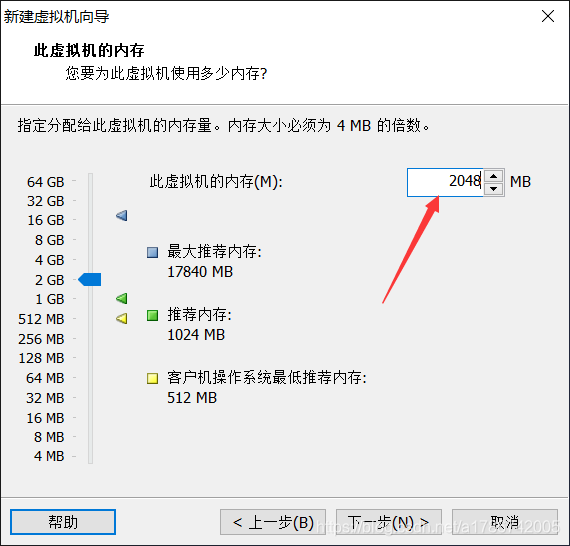
8、设置内存
这里可以根据自己电脑内存的大小进行设置,我选择2G。
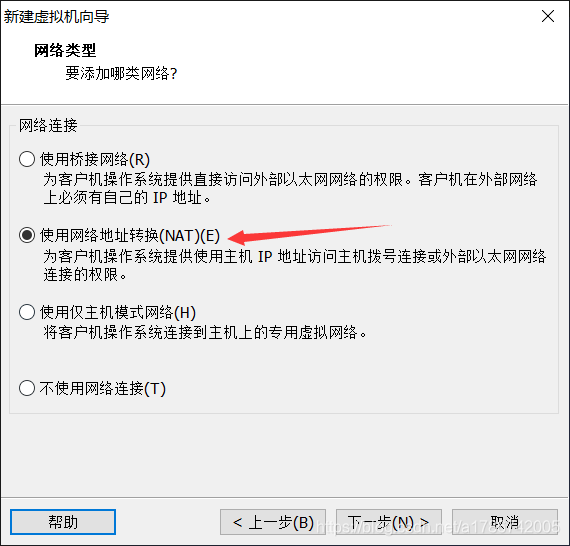
9、网络设置
这里我选择了NAT模式,关于其他网络连接方式大家可以自行百度查看其区别。
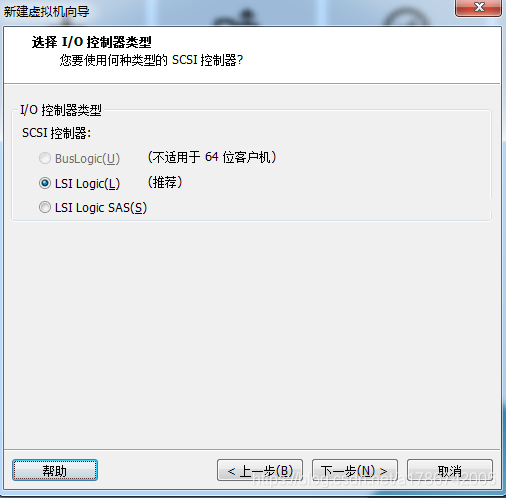
10、选择IO控制器类型
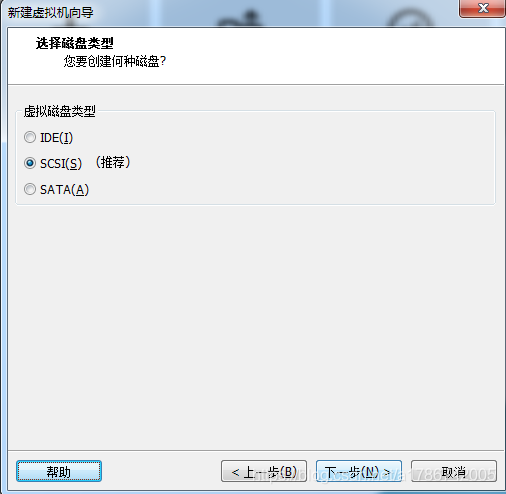
11、选择磁盘类型
IDE: 老的磁盘类型
SCSI: 服务器上推荐使用的磁盘类型,串口。
SATA: 也是串口,也是新的磁盘类型。
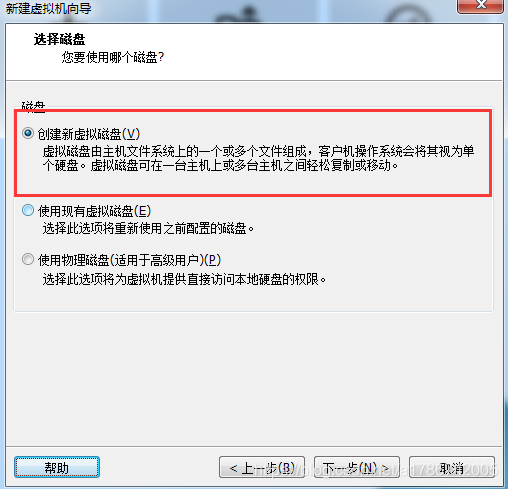
12、新建虚拟磁盘
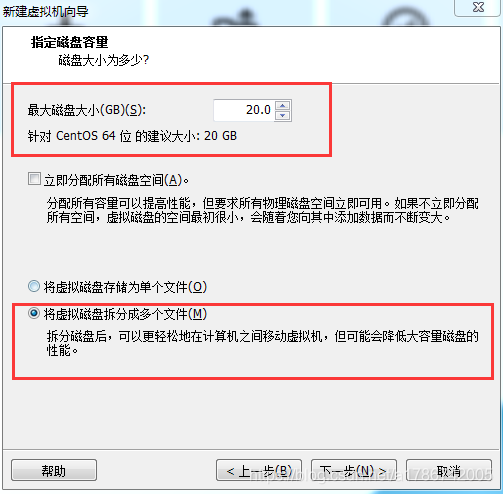
13、设置磁盘容量
14、指定磁盘文件存储位置
15、新建虚拟机向导完成
16、VM设置
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









