






最近学习linux进程编程,有一些知识点学的很迷糊,后查是因为进程空间理解不到位,所以经过一段的学习,结合自身的理解,写下这篇博客,顺便自己以后忘了,还能回来看一看
首先我们由一个小demo引入
1 1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<unistd.h>
4
5 int global_value = 100;
6
7 int main()
8 {
9 int cnt = 0;
10 int id = fork();
11 if(id==0)
12 {
13 while(1)
14 {
15 if(cnt == 5)
16 {
17 global_value = 999;
18 }
19 printf("I am a child process pid:%d ppid:%d global_value = %d &global_value = %p\n",getpid(),getppid(),global_value,&global_value);
20 cnt++;
21 sleep(1);
22 }
23 }
24 else
25 {
26 while(1)
27 {
28 printf("I am a father process pid:%d ppid:%d global_value = %d &global_value = %p\n",getpid(),getppid(),global_value,&global_value);
29 sleep(2);
30 }
31 }
32
33 return 0;
34 }
~
~
~
运行结果:
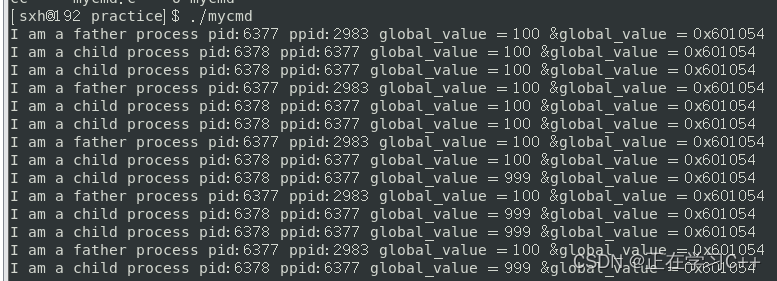
可以看到的是,刚开始他们访问global_value时,同一个地址,同一个值,这很合理,但在程序运行后五秒,子进程将全局变量的值改为了999,依旧是同一个地址,但并没有影响到父进程全局变量的值,这是怎么做到的?
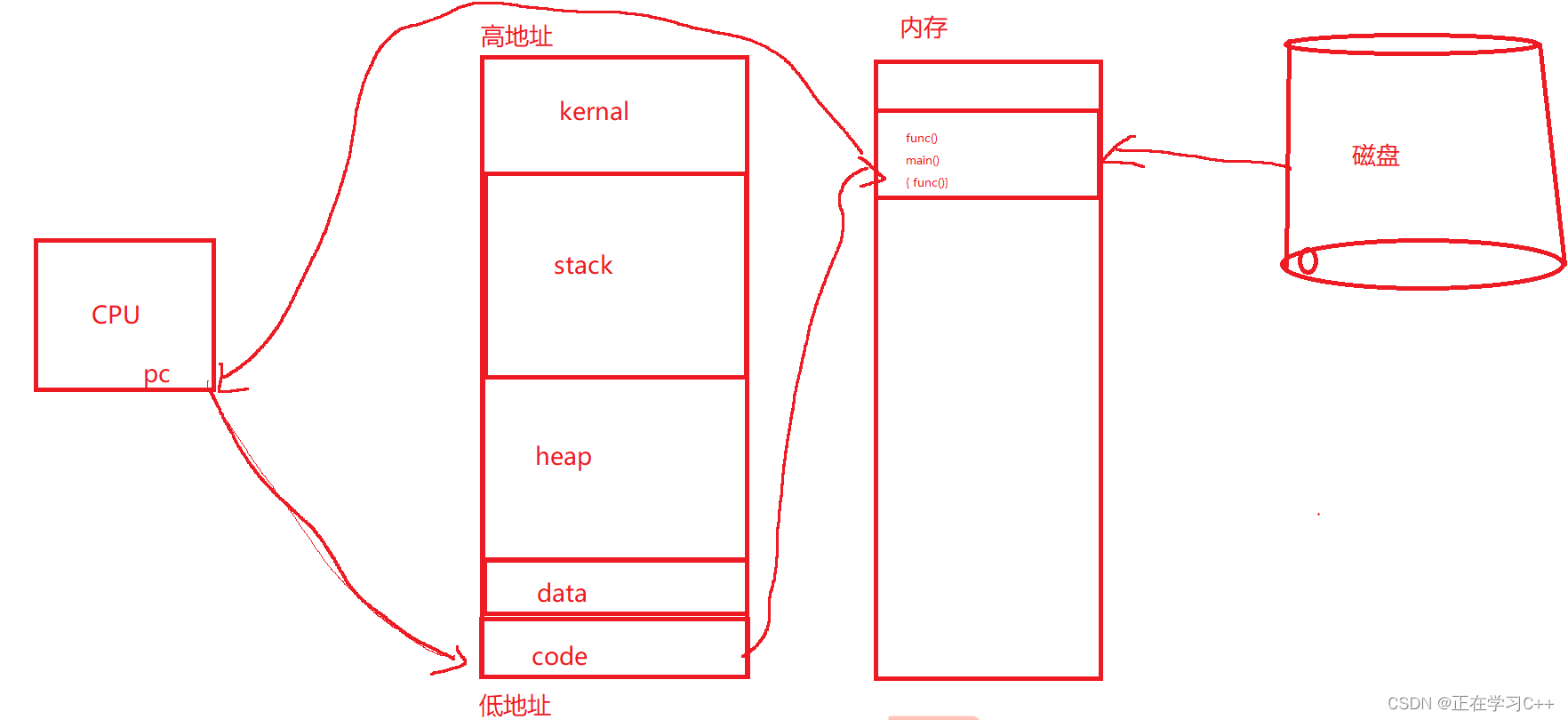
首先引入一个概念,叫虚拟地址空间,在学习C/C++时,一般都会讲局部变量存放在栈上,malloc / new出来的变量存放在堆上,这个栈/堆,事实上并不是物理内存上,而是虚拟地址空间,每个进程,都有属于自己的虚拟地址空间,大致如图
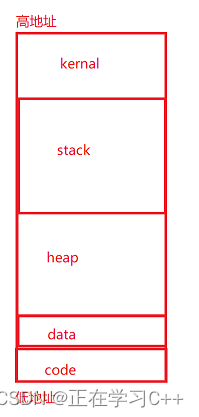
当然是不止这几个区,但是哪些不是今天写的重点,所以只保留重点
一个32位的程序,最多也就使用4GB内存,也就是2^32大小,也就是说如果地址起始为0000 0000的话,那么最高的地址就为FFFF FFFF,而这三十二位的地址,用一个unsigned int就能够存放下,分隔区域也非常简单,例如起始地址0000 0000 - 结束地址0000 1000为代码区, 0000 1000 - 0000 2000 为数据段,依次类推,根据不同的区域,划分不同的大小,操作系统内核有个mm_struct结构体,里面划分区域就是类似的做法,
下图是linux 2.6 mm_struct部分实现源码:
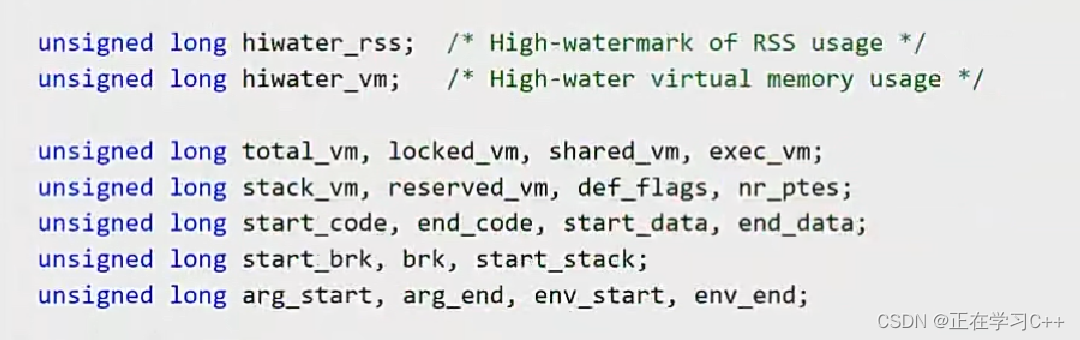
我们都知道,堆栈在运行时根据需求会调整它的大小,其实本质就是调整它的start or end
简单理解虚拟地址空间概念后,我们又该疑问,那既然它是虚拟地址,进程又该如何真正的与物理内存进行交互呢,我们应该知道,内存与磁盘进行io时,一个基本单位是4KB,内存会将自身划成一个一个的page,每一个page都是4kb,那么4GB内存总共就有4GB/4KB个page,每次寻址时,找到page的起始地址,再根据页内偏移确定数据位置(这块就不展开说那么多了,如果不懂,复习一下文件系统),而虚拟地址空间和物理内存之间的桥梁叫做页表,页表会将每个虚拟地址映射到对应的物理地址,例如 0x0001 对应 物理地址 0x0FFF,当然页表有自己的管理方式,页表不展开说,有机会把这块再写个博客,这里不懂的话就暂时理解为页表的作用是将虚拟地址映射对应的物理地址
所以进程在访问虚拟地址空间时,它以为自身有4GB可用空间,实际上,他能用多少还是取决于操作系统,当进程A和进程B并行时,A访问数据走自己的虚拟地址空间,页表,内存,B也同样,所以每个进程运行都有自己的唯一性,哪怕说A运行时程序崩了,也不会干扰到B进程,因为B进程的代码数据是独立的,如果A想要越界访问时,操作系统不会允许,在页表映射阶段,就给pass掉了,所以虚拟进程地址空间,保证了进程的唯一性和安全性
OK回到我们之前的小demo上,为什么两个虚拟地址相同的变量,不同进程访问,会有不同结果呢,其实这里有一个小操作,当父进程创建子进程时,会将自身的虚拟地址空间继承给子进程,所以刚开始我们看到的两个变量地址会是同一个,在页表映射时,也确实是映射的同一物理内存,这块物理内存是被父子进程共享的,当子进程想要修改这块地址内容时,操作系统为了不影响到父进程,会再开辟一块空间,将内容拷贝到新空间,再将新空间的物理地址,替换页表中旧物理内存地址,最后再修改地址内容,这种拷贝操作,叫做写时拷贝
如果前面的内容没看迷糊的话,我们再来进一步的了解进程地址空间,看迷糊的话就不要往下看了
来看一个小demo的反汇编:
void func()
{
printf("hello world\n");
}
int main()
{
func();
return 0;
}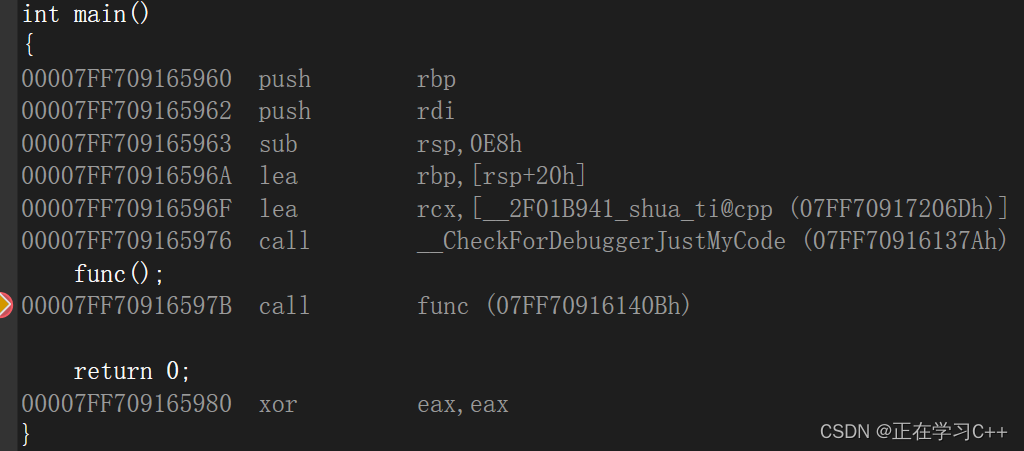
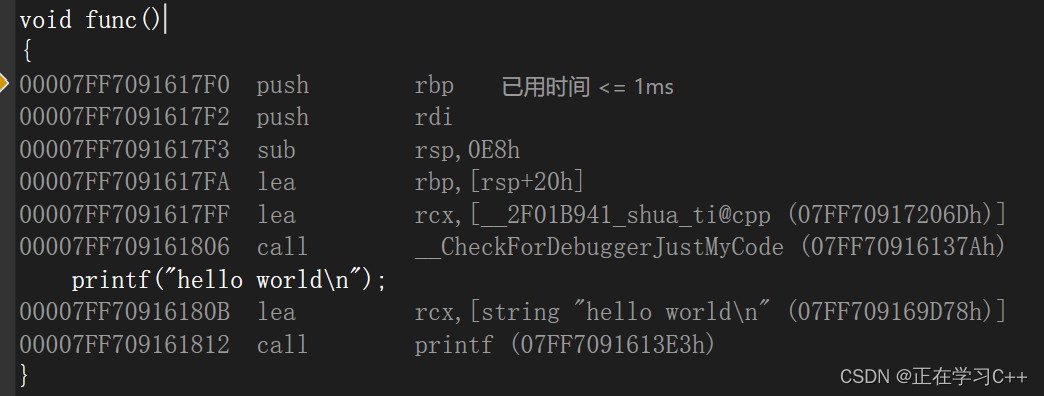
首先说一下,call在汇编里就是调用这个函数,我们可以看到在main函数汇编中,call func后面紧跟了一个地址,这说明func是在汇编阶段就产生了地址,当然我们发现这个地址和图二的地址不太一样,这是因为他中间做了一次跳转,如图:
![]()
call到这里,再jmp到了func,至于他为什么这么做,等以后我学习了编译原理再来补充,话题回到func地址上,这个地址,应该叫做逻辑地址,他和虚拟地址空间结构时一样的,都是线性结构,只不过逻辑地址是存放在磁盘上的,在我们运行这个程序时,这段代码会被加载到内存中,那么代码中已经有了逻辑地址,加载到内存中,就又具备了物理地址,同时,main函数的地址会被当做进程的起始地址存放在页表上,并加上代码大小的偏移量为结束地址,也同时,操作系统会将虚拟地址空间里的代码段的起始地址,与main函数物理地址在页表相对应,cpu在代码段执行main函数时,实际上也是转到main函数的地址,那么既然是逻辑地址,肯定是直接call不到的,这时操作系统会去页表中将main函数的虚拟地址,映射为main函数的物理地址,再找到main函数的物理地址后,将他放到cpu中的程序计数器上,cpu再去pc指针所保存的地址中去执行代码(不知道啥是程序计数器的建议先去了解一下),执行到call func时,这个地址又是汇编时所保存的逻辑地址,那么同样,操作系统也会将它到页表中去进行映射,拿到func的物理地址后,再保存到pc指针上,他们就形成了一个循环,大致流程如图:
我这个图画的很挫,可以根据我上面文字描述重新画一下,其实还是很容易理解的
在上述中,我们发现,编译器编译的逻辑地址,在程序运行后,可以直接被进程的虚拟地址空间使用,call到某个地址,这个地址在页表中映射到物理地址,再被cpu使用,进程虚拟地址空间,可以直接使用编译器的编好的逻辑地址,因为他们的规则是一样的,就像前文说的,逻辑地址是线性地址,虚拟进程空间也是线性地址,所以在进行运行时,直接可以将逻辑地址,作为自己的虚拟地址空间中的地址
最后总结一下进程地址空间的好处:
1.所有进程都可以统一的看待自己的代码和数据,方便进程使用,编译器也可以以统一的视角编译代码
2.保证了数据的安全,可以预防进程非法访问的问题
3.保证了进程的独立性,可以有效的控制进程之间的耦合















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









