







现在大数据是越来越火了,而我自己研究这方面也很长时间了,今天就根据我自己的经验教会大家学会如何使用MapReduce,下文中将MapReduce简写为MR。
本篇博客将结合实际案例来具体说明MR的每一个知识点。
| 1、本篇博客核心内容: |

| 2、MR的基本概念 |

| 3、MR中map()函数和reduce()函数如何编写 |

| 4、MR程序的基本编写流程(MR的基本执行过程) |


下面将用一个具体的电信业务说明MR最基本的编写过程:
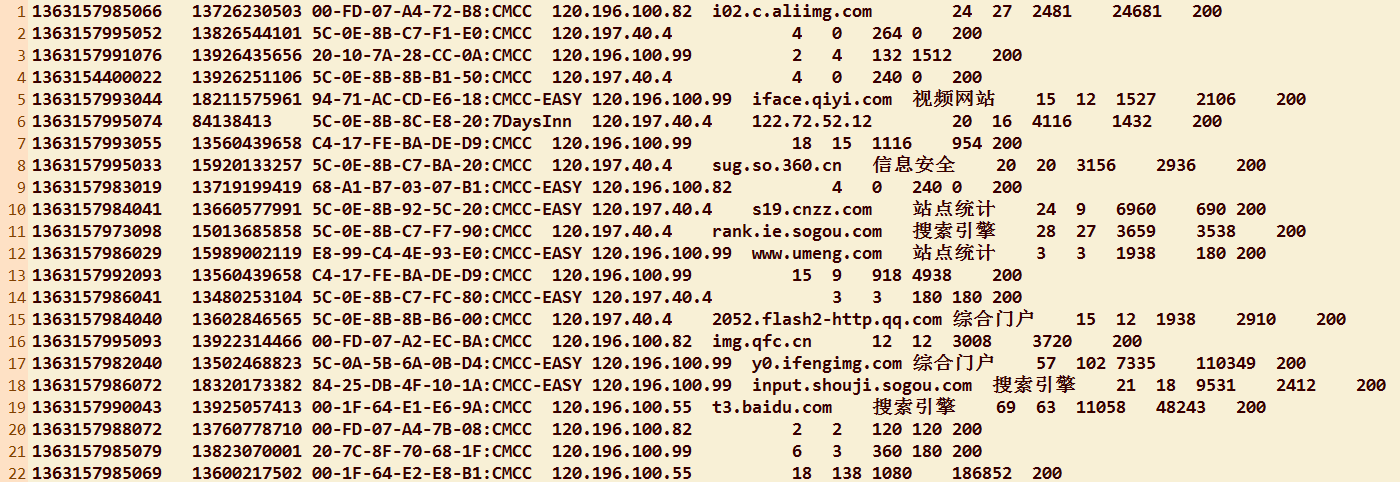
实验所用数据:
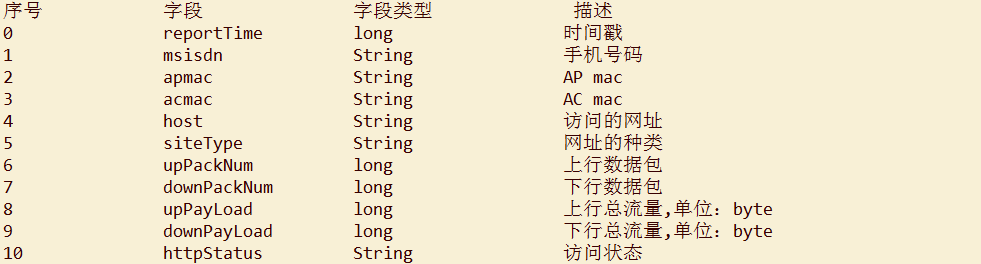
具体字段描述:
业务要求:统计同一个用户的上行总流量和,下行总流量和以及上下总流量和
例如:
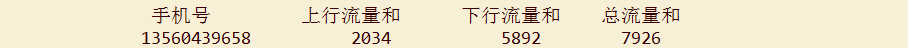
代码示例:
package com.appache.celephone3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class FlowCount
{
public static String path1 = "hdfs://hadoop:9000/dir/flowdata.txt";
public static String path2 = "hdfs://hadoop:9000/dirout/";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://hadoop:9000/");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = new Job(conf,"FlowCount");
job.setJarByClass(FlowCount.class);
//编写驱动
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//shuffle洗牌阶段
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
//将任务提交给JobTracker
job.waitForCompletion(true);
//查看程序的运行结果
FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop:9000/dirout/part-r-00000"));
IOUtils.copyBytes(fr,System.out,1024,true);
}
}
package com.appache.celephone3;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, Text>
{
@Override
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String line = v1.toString();//拿到日志中的一行数据
String[] splited = line.split("\t");//切分各个字段
//获取我们所需要的字段
String msisdn = splited[1];
String upFlow = splited[8];
String downFlow = splited[9];
long flowsum = Long.parseLong(upFlow) + Long.parseLong(downFlow);
context.write(new Text(msisdn), new Text(upFlow+"\t"+downFlow+"\t"+String.valueOf(flowsum)));
}
}
package com.appache.celephone3;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text k2, Iterable<Text> v2s,Context context)throws IOException, InterruptedException
{
long upFlowSum = 0L;
long downFlowSum = 0L;
long FlowSum = 0L;
for(Text v2:v2s)
{
String[] splited = v2.toString().split("\t");
upFlowSum += Long.parseLong(splited[0]);
downFlowSum += Long.parseLong(splited[1]);
FlowSum += Long.parseLong(splited[2]);
}
String data = String.valueOf(upFlowSum)+"\t"+String.valueOf(downFlowSum)+"\t"+String.valueOf(FlowSum);
context.write(k2,new Text(data));
}
}
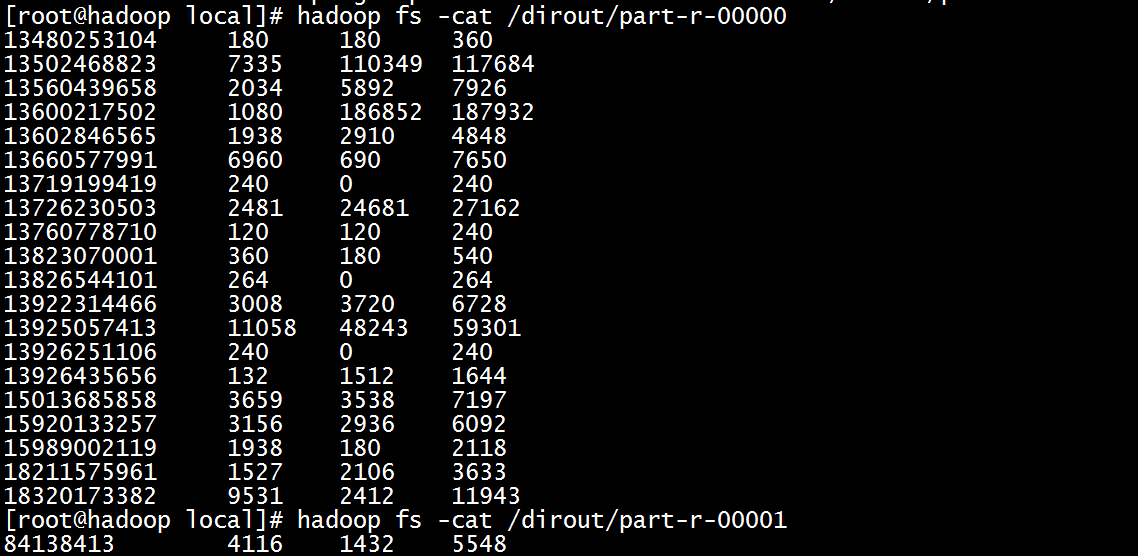
运行结果:

| 5、MR程序的优化方式1---分区 |

具体业务描述:对于上面的电信数据,统计同一个用户的上行总流量和,下行总流量和以及上下总流量和,并且手机号(11位)的信息输出到一个文件中,非手机号(8位)的信息输出到一个文件中
代码示例:
package com.appache.partitioner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class FlowCount
{
public static String path1 = "hdfs://hadoop:9000/dir/flowdata.txt";
public static String path2 = "hdfs://hadoop:9000/dirout/";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://hadoop:9000/");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = new Job(conf,"FlowCount");
job.setJarByClass(FlowCount.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);//<k1,v1>
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);//<k2,v2>
//shuffle阶段:分区、排序、分组、本地归并
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(2);
//<k2,v2s>
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
//提交作业
job.waitForCompletion(true);
}
}
package com.appache.partitioner;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable
{
long upFlow ; //上行流量
long downFlow; //下行流量
long flowSum; //总流量
public FlowBean() {}
public FlowBean(String upFlow,String downFlow)
{
this.upFlow = Long.parseLong(upFlow);
this.downFlow = Long.parseLong(downFlow);
this.flowSum = Long.parseLong(upFlow) + Long.parseLong(downFlow);
}
public long getupFlow()
{return upFlow;}
public long getdownFlow()
{return downFlow;}
public long getflowSum ()
{return flowSum;}
@Override
public void write(DataOutput out) throws IOException
{
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(flowSum);
}
@Override
public void readFields(DataInput in) throws IOException
{
upFlow = in.readLong();
downFlow = in.readLong();
flowSum = in.readLong();
}
public String toString()
{
return upFlow+"\t"+downFlow+"\t"+flowSum;
}
}
package com.appache.partitioner;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, FlowBean>
{
@Override
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String line = v1.toString();//拿到日志中的一行数据
String[] splited = line.split("\t");//切分各个字段
//获取我们所需要的字段
String msisdn = splited[1];//手机号 k2
FlowBean flowData = new FlowBean(splited[8],splited[9]);//<100,200>
context.write(new Text(msisdn), flowData);
}
}
package com.appache.partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text,FlowBean> //分区<18330267966,{100,200}>
{
@Override
public int getPartition(Text k2, FlowBean v2, int numPartitions)
{
String tele = k2.toString();
if(tele.length() == 11)
return 0; //手机号的信息输出到0区
else
return 1; //非手机号的信息输出到1区
}
}
package com.appache.partitioner;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text, FlowBean, Text, FlowBean>
{
@Override
protected void reduce(Text k2, Iterable<FlowBean> v2s,Context context)throws IOException, InterruptedException
{
long upFlow = 0L;
long downFlow = 0L;
long flowSum = 0L;
for(FlowBean v2: v2s)
{
upFlow += v2.getupFlow();
downFlow += v2.getdownFlow();
flowSum += v2.getflowSum();
}
context.write(k2, new FlowBean(upFlow+"",downFlow+"")); //将数据输出到指定的文件当中
}
}
运行结果:
| 6、MR程序的优化方式2---自定义排序 |

业务描述:
对于上面业务得到的统计结果:

先按照总流量由低到高排序,在总流量相同的情况下,按照下行流量和从低到高排序:
实例代码:
package com.appache.sort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class FlowCount
{
public static String path1 = "hdfs://hadoop:9000/flowCount.txt";
public static String path2 = "hdfs://hadoop:9000/dirout/";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://hadoop:9000/");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = new Job(conf, "FlowCount");
job.setJarByClass(FlowCount.class);
//编写驱动
FileInputFormat.setInputPaths(job,new Path(path1)); //输入文件的路径
job.setInputFormatClass(TextInputFormat.class);//<k1,v1>
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(NullWritable.class);
//shuffle优化阶段
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(FlowBean.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,new Path(path2));
job.waitForCompletion(true);
//查看运行结果:
FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop:9000/dirout/part-r-00000"));
IOUtils.copyBytes(fr,System.out,1024,true);
}
}
package com.appache.sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean>
{
private String msisdn; //获取我们所需要的字段
private long upFlow;
private long downFlow;
private long flowSum;
public FlowBean(){}
public FlowBean(String msisdn,String upFlow,String downFlow,String flowSum)
{
this.msisdn = msisdn;
this.upFlow = Long.parseLong(upFlow);
this.downFlow = Long.parseLong(downFlow);
this.flowSum = Long.parseLong(flowSum); //通过构造函数自动求取总流量
}
public String getMsisdn()
{
return msisdn;
}
public long getUpFlow()
{
return upFlow;
}
public long getDownFlow()
{
return downFlow;
}
public long getFlowSum()
{
return flowSum;
}
@Override //所谓序列化就是将对象写到字节输出流当中
public void write(DataOutput out) throws IOException
{
out.writeUTF(msisdn);
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(flowSum);
}
@Override //所谓反序列化就是将对象从输入流当中给读取出来
public void readFields(DataInput in) throws IOException
{
this.msisdn = in.readUTF();
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.flowSum = in.readLong();
}
@Override //指定比较的标准
public int compareTo(FlowBean obj)
{
if(this.flowSum == obj.flowSum)
return (int)(obj.downFlow - this.downFlow); //下行流量由高到底
else
return (int)(this.flowSum - obj.flowSum); //总流量由低到高
}
public String toString()
{
return this.msisdn+"\t"+this.upFlow+"\t"+this.downFlow+"\t"+this.flowSum;
}
}
package com.appache.sort;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable>
{
@Override
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
//拿到日志中的一行数据
String line = v1.toString();
//切分各个字段
String[] splited = line.split("\t");
//获取我们所需要的字段---并用FlowBean存储我们所需要的字段
FlowBean flowdata = new FlowBean(splited[0],splited[1],splited[2],splited[3]);
context.write(flowdata, NullWritable.get()); //<{18330267966,100,200},null>
}
}
package com.appache.sort;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<FlowBean, NullWritable, FlowBean, NullWritable>
{
@Override
protected void reduce(FlowBean k2, Iterable<NullWritable> v2s,Context context)throws IOException, InterruptedException
{
for(NullWritable v2:v2s)
{
context.write(k2, NullWritable.get());
}
}
}
运行结果:
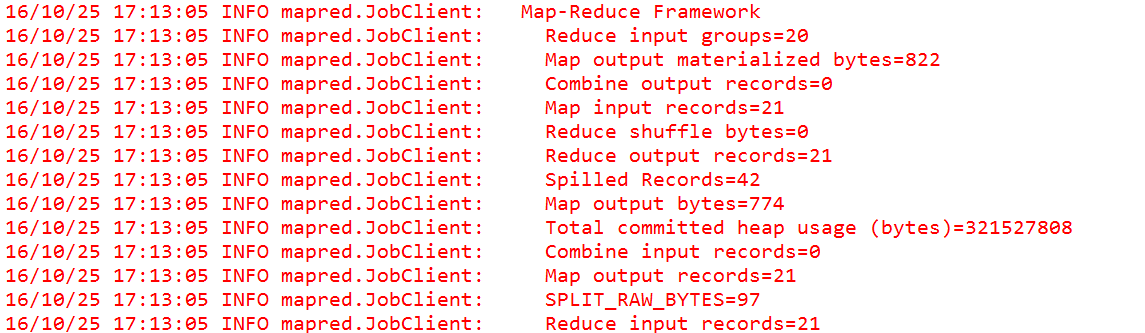

| 7、MR程序的优化方式3---本地归并Combiner |

具体业务描述:对于上面的电信数据,统计同一个用户的上行总流量和,下行总流量和以及上下总流量和,代码中要求加入本地归并优化方式:
代码示例:
package com.appache.celephone3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class FlowCount
{
public static String path1 = "hdfs://hadoop:9000/dir/flowdata.txt";
public static String path2 = "hdfs://hadoop:9000/dirout/";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://hadoop:9000/");
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = new Job(conf,"FlowCount");
job.setJarByClass(FlowCount.class);
//编写驱动
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//加入本地归并优化方式:
job.setCombinerClass(MyReducer.class);
job.setNumReduceTasks(2);
//shuffle洗牌阶段
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
//将任务提交给JobTracker
job.waitForCompletion(true);
//查看程序的运行结果
FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop:9000/dirout/part-r-00000"));
IOUtils.copyBytes(fr,System.out,1024,true);
}
}
package com.appache.celephone3;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, Text>
{
@Override
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String line = v1.toString();//拿到日志中的一行数据
String[] splited = line.split("\t");//切分各个字段
//获取我们所需要的字段
String msisdn = splited[1];
String upFlow = splited[8];
String downFlow = splited[9];
long flowsum = Long.parseLong(upFlow) + Long.parseLong(downFlow);
context.write(new Text(msisdn), new Text(upFlow+"\t"+downFlow+"\t"+String.valueOf(flowsum)));
}
}
package com.appache.celephone3;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text k2, Iterable<Text> v2s,Context context)throws IOException, InterruptedException
{
long upFlowSum = 0L;
long downFlowSum = 0L;
long FlowSum = 0L;
for(Text v2:v2s)
{
String[] splited = v2.toString().split("\t");
upFlowSum += Long.parseLong(splited[0]);
downFlowSum += Long.parseLong(splited[1]);
FlowSum += Long.parseLong(splited[2]);
}
String data = String.valueOf(upFlowSum)+"\t"+String.valueOf(downFlowSum)+"\t"+String.valueOf(FlowSum);
context.write(k2,new Text(data));
}
}
运行结果:
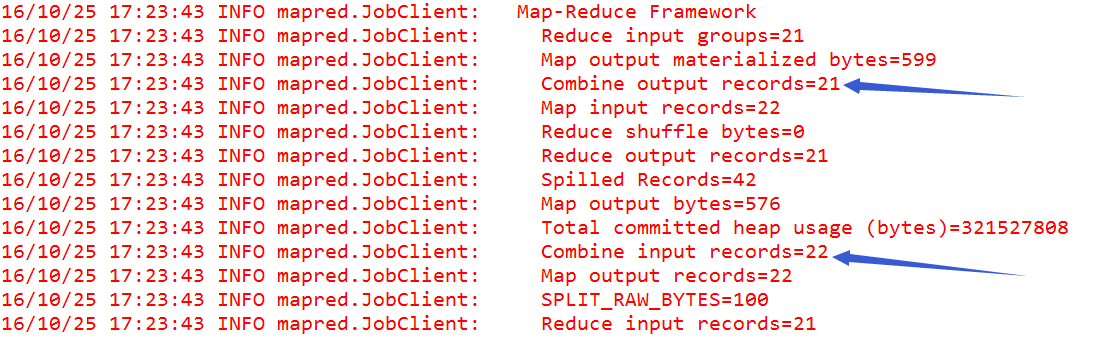

| 8、MR程序的优化方式4---自定义计数器 |

| 9、如何用MR实现某个业务的方式总结 |

对于文章的内容,如有问题,欢迎留言指正!















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











