







核心内容:
1、RDD的一个实战案例
OK,今天是2016年12月4日了,12月份注定不会太轻松,很多事情就像是多线程一样并行的进行执行,好的,进入本次博客的正题!
RDD本身有3种操作方式:
①基本的Transformation(数据状态的转换即所谓的算子)
如:map、flatMap、textFile等等。
②Action(触发具体的Job,获得相应的结果)
如:reduce、collect、foreach、saveAsTextFile等
注意:在《深入理解Spark》这本书中的145页介绍reduceByKey是action,而非transformation,但是王家林老师介绍的时候说reduceByKey是transformation。呵呵!!这个问题看来还得实际操作:
scala> val lineCounts = lineCount.reduceByKey(_+_)
lineCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[7] at reduceByKey at <console>:31浏览器页面此时什么也没有:

结论:reduceByKey是transformation,而非action!,王家林老师是对的!
③Controller(对性能和容错方面的支持:Persist(cache是persist的一种特殊情况)和CheckPoint)
总结:Transformation级别的RDD的特点就是lazy,使用Transformation只是代表对数据操作的一种标记,但是并不会真正的执行具体的操作,仅仅是算法的一种描述;只有遇到Action的时候或者遇到CheckPoint的时候RDD才会真正的执行操作,才会真正的触发我们的Job。
好的,接下来为RDD具体的案例操作:统计文件word.txt中相同行的个数。(Spark程序的编程无非就是创建RDD、转化已有的RDD、通过RDD获取最终的结果)
word.txt中具体的文件内容:
Hello Spark Hello Scala
Hello Hadoop
Hello Hbase
Spark Hadoop
Java Spark
Hello Hadoop
Hello Hbase直接上代码:
package com.appache.spark.app
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hp on 2016/12/4.
* 统计文件中相同行的个数---呵呵,和相同单词出现总的次数是一样的
*/
object TextLines
{
def main(args: Array[String]): Unit =
{
val conf = new SparkConf()
conf.setAppName("TextLines")
conf.setMaster("local")
//SparkContext是通往Spark的唯一入口
val sc = new SparkContext(conf)
val lines:RDD[String] = sc.textFile("C:\\word.txt")
val lineCount:RDD[(String,Int)] = lines.map(line=>(line,1))
val lineCounts:RDD[(String,Int)] = lineCount.reduceByKey(_+_)
//输出最终结果
lineCounts.collect.foreach(linenum=>println(linenum._1+"\t"+linenum._2))
sc.stop()
}
}运行结果:
Hello Hbase 2
Java Spark 1
Spark Hadoop 1
Hello Spark Hello Scala 1
Hello Hadoop 2其实如果WordCounts程序基础扎实的话,这个程序的编写并没有什么难度,万变不离其宗嘛!
程序当中的部分说明:
sc.textFile的含义:通过HadoopRDD以及MapPartitionsRDD获取文件中的每一行文本的内容。
HadoopRDD的具体作用:HadoopRDD获取输入文件的路径,并将输入文件在逻辑上切分成若干个split数据片,并提供RecordReader的实现类,将输入文件按照一定的规则解析成键值对。随后textFile内部的map函数的MapPartitionsRDD去key留value。
map的含义:将每一行变成行的内容与1构成的Tuple(元组)
reduceByKey的含义:累加求和
collect的含义:collect将集群中各个节点上的结果汇总过来,变成最终的结果,如果不用collect的话,结果是分布在各个节点上的,所以必须用collect将结果汇集到Driver上面。
好了,接下来我们通过交互式命令详细的解释这个程序:
scala> val lines = sc.textFile("/word.txt")
scala> val lineCount = lines.map(line=>(line,1))
scala> val lineCounts = lineCount.reduceByKey(_+_) //reduceByKey的第二个参数决定了第一个阶段每一个任务的分区
scala> lineCounts.saveAsTextFile("/dir1/")查看运行结果:
[root@hadoop11 ~]# hadoop fs -cat /dir1/part-00000
(Spark Hadoop ,1)
[root@hadoop11 ~]# hadoop fs -cat /dir1/part-00001
(Hello Hbase,2)
(Java Spark,1)
(Hello Spark Hello Scala,1)
(Hello Hadoop,2)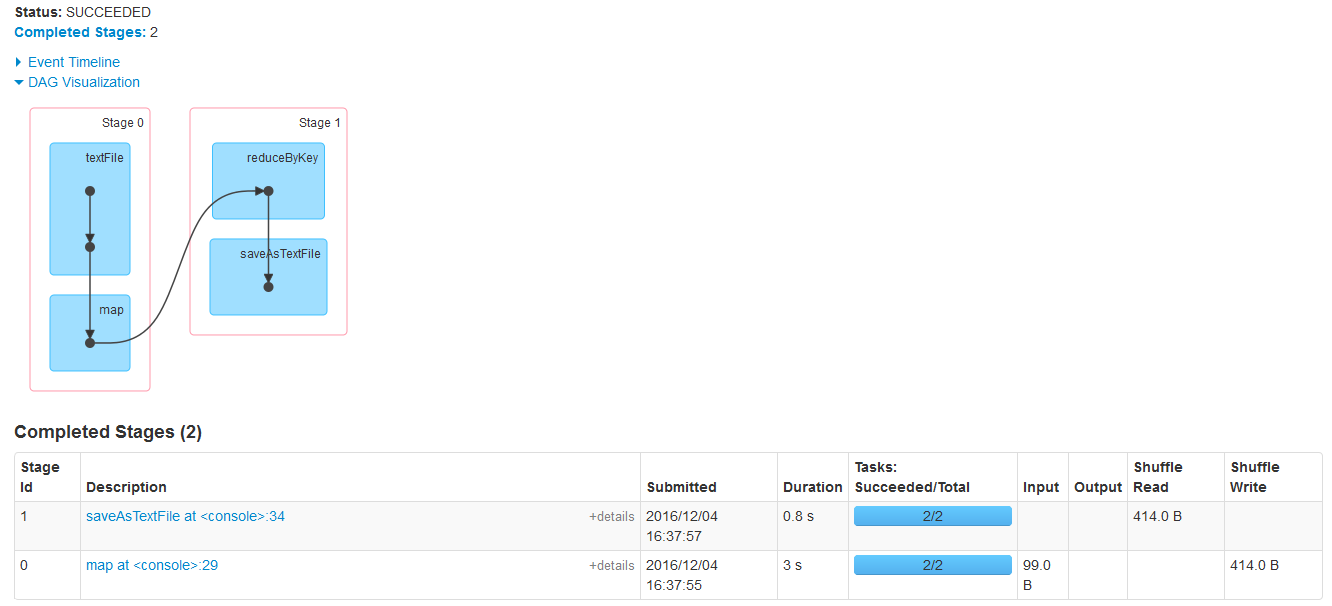
从DAG图中我们可以看出,在第0个阶段含有2个任务,在第一个阶段含有2个阶段。
所以,呵呵,具体的运行流程肯定是这样的:
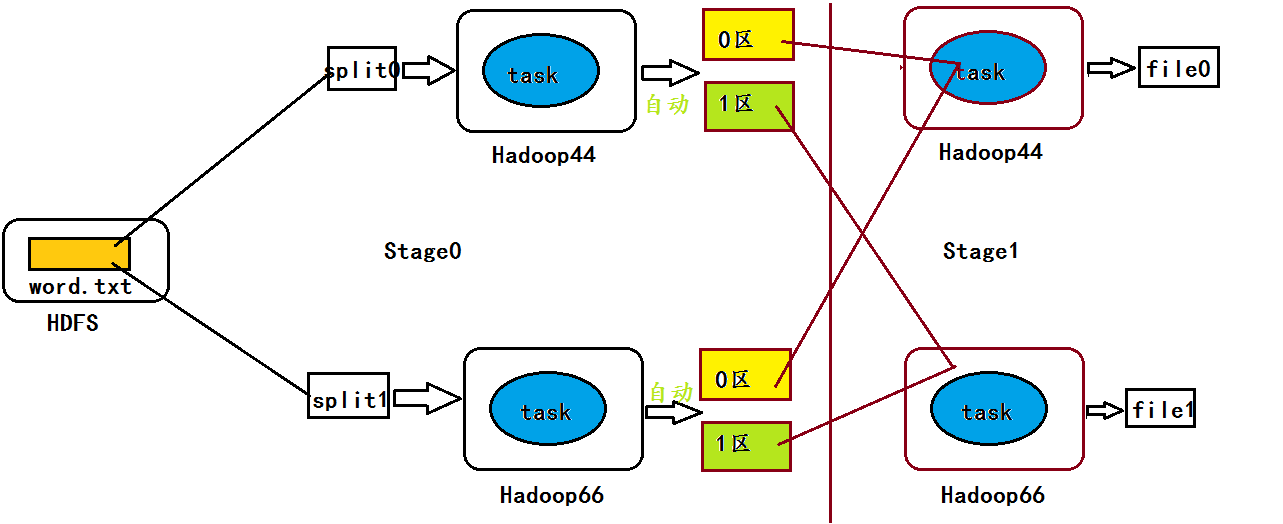
推断:在第0个Stage的末尾端,每个task任务按照Hash数值进行了自动分区,从而导致输出文件有两个。
接下来我想自己控制一下数据流程图:(呵呵,试一下)
运行代码:
scala> val lines = sc.textFile("/word.txt",1) //将输入文件只切分为一个split数据片
scala> val lineCount = lines.map(line=>(line,1))
scala> val lineCounts = lineCount.reduceByKey(_+_,1) //1在这里表示不按Hash值分区了,所有结果只划分为一个区
scala> lineCounts.saveAsTextFile("/dir1/")查看运行结果:
[root@hadoop11 ~]# hadoop fs -lsr /dir2
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 3 root supergroup 0 2016-12-04 17:16 /dir2/_SUCCESS
-rw-r--r-- 3 root supergroup 94 2016-12-04 17:16 /dir2/part-00000
[root@hadoop11 ~]# hadoop fs -cat /dir2/part-00000
(Hello Hbase,2)
(Java Spark,1)
(Spark Hadoop ,1)
(Hello Spark Hello Scala,1)
(Hello Hadoop,2)在看一下日志:
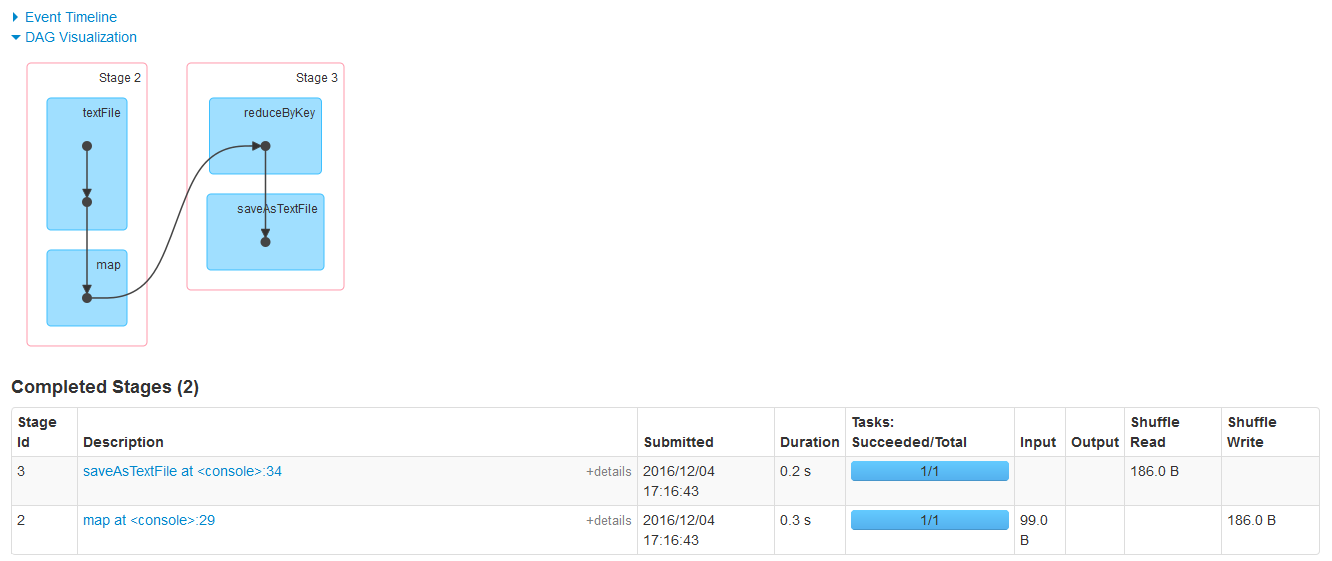
呵呵,一切都在自己的控制中。
Hadoop中的定律在Spark当中是适合的:每一个Mapper任务的分支数量=分区的数量=Reducer任务的数量=输出文件的数量
在Spark当中可以通过:textFile(输入文件转化为多少个split)与reduceByKey(指定每一个Mapper任务的分支数量)来决定任务Task的并发数量。
最后在说一句:Reducer任务的数据来源有两种方式:从本地磁盘读取+通过网络从多个Mapper任务端远程拷贝过来;Shuffle会产生新的Stage,Action会触发新的JOb
OK,继续努力!
















 9919
9919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











