






目录
0 Overview
强化学习(reinforcement learning,RL)是一个比较热门的领域,关注于智能体(Agent)与环境(Environment)的交互,从中获取最大化的奖励(Reward)。RL在机器人等领域研究广泛。区别于有监督和无监督的学习方法,RL面对的数据通常是具有序列关系的样本,比如时间序列、动作序列。
这是一个系列的学习笔记,主要根据《蘑菇书 Easy RL》(https://github.com/datawhalechina/easy-rl)进行学习,算是个人的一个学习经验总结。
1 RL概况
1.1 RL定义
RL关注于Agent和Environment的交互,在交互中,Environment会给出一个状态State,Agent根据这个State会给出一个动作Action,Environment则根据这个Action给出下一步的State和一个奖励值Reward,然后智能体Agent的目标最大化这个Reward,或者说Reward的累加和,或者说期望。
具体地,如下图所示,Agent和Environment不断交互,最终达到某种条件。
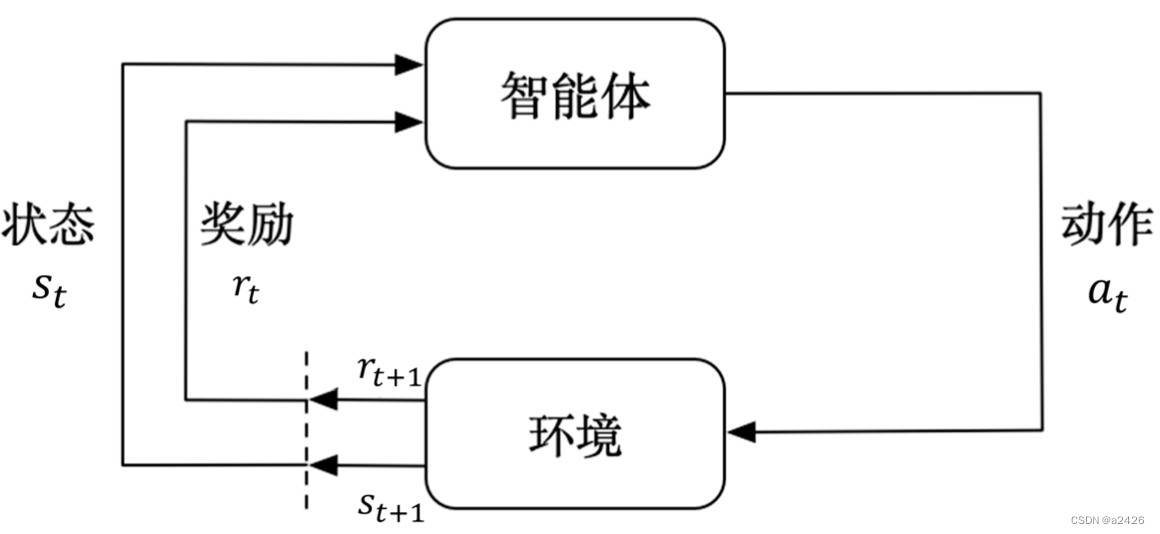
对于智能体Agent来说,它每次与Environment交互得到的就是一个观测,是一个轨迹(trajectory),也就是状态State和动作Action的序列。
深度强化学习(deep reinforcemet learning): 深度学习DL+强化学习RL。传统的早期的RL称为标准强化学习。深度强化学习利用神经网络,将特征工程和处理模型合二为一,组建端到端(End-to-End)的强化学习模型。比如标准RL中往往需要人为设计很多特征,用这些特征作为环境给出的state,然后才给Agent进行分析,而深度RL则可以用神经网络优化这一步骤。
强化学习不同于有监督和无监督学习:
- RL输入的样本是序列数据,样本之间是有关联的,不同于传统方法是独立同分布数据(IID)。
- 数据没有标签,Agent并不知道什么是最正确的动作,只能通过不断试错来发现最有奖励的动作Action,同一个Action在不同的时候Reward也不一致。
- 奖励是延迟的,当前的动作对之后的多个步骤的奖励都有影响,短期奖励和长期奖励可能存在冲突。比如,下棋,最终的奖励就是fail or win,但是当前这一步如何走?这个奖励如何与最后的输赢扯上关系,是需要研究的。
1.2 RL中的建模问题
Environment & State
RL中,Agent从Environment中获得State和Reward,这是一个观测,但是理论上,“State”是对整个世界的描述,Agent观测的State可能并不完备,比如其中只有部分特征,是对整个世界的部分描述。因此,设环境内部的状态为,Agent观测到的状态为
。
- 如果
,则称这个环境是完全可观测的(fully observed),此时RL通常被建模成一个马尔可夫决策过程(Markov decision process,MDP)的问题。
- 如果
,称这个环境是部分可观测的(partially observed)。 在这种情况下,强化学习通常被建模成部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP)的问题。POMDP是马尔可夫决策过程的一种泛化。 其依然具有马尔可夫性质,但是假设智能体无法感知环境的状态,只能知道部分观测值。比如在自动驾驶中,智能体只能感知传感器采集的有限的环境信息。部分可观测马尔可夫决 策过程可以用一个七元组描述:(S,A,T,R,Ω,O,γ)。其中 S 表示状态空间,为隐变量,A 为动作空间, T (s′|s, a) 为状态转移概率,R 为奖励函数,Ω(o|s, a) 为观测概率,O 为观测空间,γ 为折扣因子。
Action
动作空间(Action space),Agent采取的Action可以分为有限和无限。比如,机器人的移动如果只有上下左右四个方向,则为有限,如果可以360度转向移动,则为无限。因此,可以分为离散动作空间(discrete action space)和连续动作空间(continuous action space)。
Agent
一个智能体可能有如下组成:一是根据策略(policy),直接根据输入的状态直接选取下一步的动作;二是根据价值函数(value function),评估智能体进入某个状态后,可以对后面的奖励带来多大的影响,价值函数值越大,说明智能体进入这个状态越有利;三是Model,根据前两步直接决定下一步的状态和当前步骤的奖励,这其实就是环境的功能。
- 策略(policy),将输入的State变为动作,有两种:1)随机性策略(stochastic policy)就是下一步的动作是随机,比如0.7往左,0.3往右;2)确定性策略(deterministic policy)就是智能体直接采取最有可能的动作。
- 价值函数(value function),是对未来奖励的预测,如Q函数。如下图定义,未来可以获得奖励的期望取决于当前的状态和当前的动作。
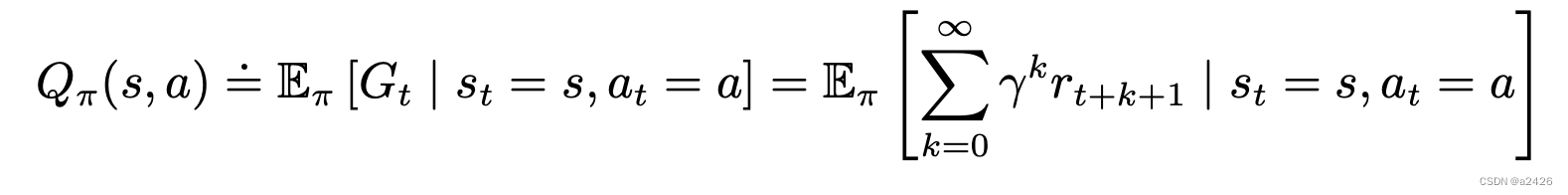
基于上面两步,构建model,决定下一步的状态,其由状态转移概率和奖励函数组成。
状态转移概率:
![]()
奖励函数:是指我们在当前状态采取了某个动作,可以得到多大的奖励。
![]()
当我们有了策略、价值函数和模型 3 个组成部分后,就形成了一个马尔可夫决策过程(Markov de-
cision process)。
RL学习方法可以分为基于策略的方法(policy-based RL)和基于价值的方法(value-based RL),以及二者的结合。
对应的,基于价值的智能体(value-based agent) 显式地学习价值函数,隐式地学习它的策略。策略是其从学到的价值函数里面推算出来的。基于策略的智能体(policy-based agent)直接学习策略,我们给它一个状态,它就会输出对应动作的概率。基于策略的智能体并没有学习价值函数。把基于价值的智能体和基于策略的智能体结合起来就有了演员-评论员智能体(actor-critic agent)。这一类智能体把策略和价值函数都学习了,然后通过两者的交互得到最佳的动作。
具体应用,value-based的RL方法有Q-learning,Sarsa等。policy-based的RL方法有策略梯度算法。
In addition,可以通过智能体到底有没有学习环境模型来对智能体进行分类。有模型(model-based) 强化学习智能体,它通过学习状态的转移来采取动作。免模型(model-free)强化学习智能体,它没有去直接估计状态的转移,也没有得到环境的具体转移变量,它通过学习价值函数和策略函数进行决策。免模型强化学习智能体的模型里面没有环境转移的模型。
简单地说,
- model-free RL方法,更加简单直观,不对真实环境进行建模,Agent只在真实环境中通过一定的策略来执行动作,等待奖励R和状态S,然后根据这些反馈信息来更新动作策略,这样反复迭代直到学习到最优策略。优点是泛化性更强,直接与真实环境交互,能更好学习环境特征。缺点是数据驱动,需要大量数据采样训练。
- model-based RL方法,相比model-free仅仅多出一个步骤,即对真实环境进行建模。优点是可以在一定程度上缓解训练数据匮乏的问题,因为智能体可以在虚拟世界中进行训练。缺点是泛化性不如model-free,因为虚拟世界与真实环境之间可能还有差异,这限制了泛化性。
总的来说,RL中的Agent组成如下所示。
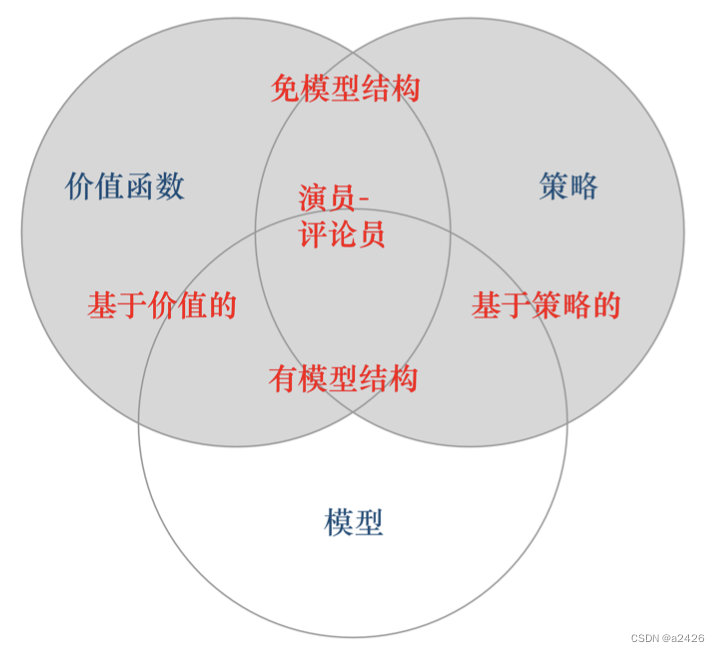
目前大部分深度RL方法都是model-free RL。所有的RL均可以model-free。而如果一个Agent执行动作前,看是否能对下一步的状态和奖励进行预测, 如果能,就能够对环境进行建模,从而可以采用有模型学习。
2 RL实践(python)
可以使用 Python 和深度学习的一些包来实现强化学习算法。现在有很多深度学习的包可以使用,比如 PyTorch、TensorFlow、Keras。
OpenAI 的 Gym 库是一个环境仿 真库,里面包含很多现有的环境。针对不同的场景,可以选择不同的环境。Gym 库有对应的官方文档(https://gym.openai.com/docs/),读者可以阅读文档来学习 Gym 库。
- 离散控制场景(输出的动作是可数的,比如 Pong 游戏中输出的向上或向下动作)一般使用雅达利环境评估。
- 连续控制场景(输出的动作是不可数的,比如机器人走路时不仅有方向,还有角度,角度就是不可数的,是一个连续的量)。一般使用 MuJoCo 环境评估。Gym Retro 是对 Gym 环境的进一步扩展,包含更多的游戏。
安装Gym
pip install gym
# 使用jupyter运行时,还需要安装pygame
pip install pygameGym中的环境:查看当前 Gym 库已经注册了哪些环境,可以使用以下代码。
from gym import envs
env_specs = envs.registry.values()
envs_ids = [env_spec.id for env_spec in env_specs]
print(envs_ids)
# 结果
###
['CartPole-v0', 'CartPole-v1', 'MountainCar-v0', 'MountainCarContinuous-v0', 'Pendulum-v1', 'Acrobot-v1', 'LunarLander-v2', 'LunarLanderContinuous-v2', 'BipedalWalker-v3', 'BipedalWalkerHardcore-v3', 'CarRacing-v1', 'CarRacingDomainRandomize-v1', 'CarRacingDiscrete-v1', 'CarRacingDomainRandomizeDiscrete-v1', 'Blackjack-v1', 'FrozenLake-v1', 'FrozenLake8x8-v1', 'CliffWalking-v0', 'Taxi-v3', 'Reacher-v2', 'Reacher-v4', 'Pusher-v2', 'Pusher-v4', 'InvertedPendulum-v2', 'InvertedPendulum-v4', 'InvertedDoublePendulum-v2', 'InvertedDoublePendulum-v4', 'HalfCheetah-v2', 'HalfCheetah-v3', 'HalfCheetah-v4', 'Hopper-v2', 'Hopper-v3', 'Hopper-v4', 'Swimmer-v2', 'Swimmer-v3', 'Swimmer-v4', 'Walker2d-v2', 'Walker2d-v3', 'Walker2d-v4', 'Ant-v2', 'Ant-v3', 'Ant-v4', 'Humanoid-v2', 'Humanoid-v3', 'Humanoid-v4', 'HumanoidStandup-v2', 'HumanoidStandup-v4']
###每个环境都定义了自己的观测空间和动作空间。环境 env 的观测空间用 env.observation_space 表示, 动作空间用 env.action_space 表示。观测空间和动作空间既可以是离散空间(取值是有限个离散的值),也可以是连续空间(取值是连续的值)。在 Gym 库中,一般离散空间用gym.spaces.Discrete 类表示,连续空间用 gym.spaces.Box 类表示。
例如,环境 MountainCar-v0 的观测空间是 Box(2,),表示观测可以用 2 个 float 值表示;环境 MountainCar- v0 的动作空间是 Discrete(3),表示动作取值自 0,1,2。对于离散空间,Discrete 类实例的成员 n 表示有几 个可能的取值;对于连续空间,Box 类实例的成员 low 和 high 表示每个浮点数的取值范围。(Demo 如下,MountainCar-v0)
import gym
env = gym.make('MountainCar-v0')
print('观测空间 = {}'.format(env.observation_space))
print('动作空间 = {}'.format(env.action_space))
print('观测范围 = {} ~ {}'.format(env.observation_space.low, env.observation_space.high))
print('动作数 = {}'.format(env.action_space.n))
# 输出,由输出可知,观测空间是形状为 (2,) 的浮点型 np.array,动作空间是取 0,1,2 的 int 型数值。
观测空间 = Box([-1.2 -0.07], [0.6 0.07], (2,), float32)
动作空间 = Discrete(3)
观测范围 = [-1.2 -0.07] ~ [0.6 0.07]
动作数 = 3基本运行:
import gym # 导入 Gym 的 Python 接口环境包
env = gym.make('CartPole-v0') # 构建实验环境
env.reset() # 重置一个回合
for _ in range(1000):
env.render() # 显示图形界面
action = env.action_space.sample() # 从动作空间中随机选取一个动作
env.step(action) # 用于提交动作,括号内是具体的动作
env.close() # 关闭环境
运行界面如下
这里有一个智能体类BespokeAgent的实现。
Easy-RL-KeyNote/Easy-RL 01 BespokeAgent.ipynb at main · BitBrave/Easy-RL-KeyNote · GitHub
总结
对 Gym 库的用法进行总结:
- env=gym.make(环境名),取出环境
- env.reset(),初始化环境
- env.step(动作),执行一步环境
- env.render(),显示环境
- env.close(),关闭环境。
3 RL应用
RL在很多领域都可以应用,尤其是自动化,机器人与环境的交互天然适合于RL。此外,像针对序列数据的学习,比如网络中针对流量进行在线的实时分类,对于每个flow进行监控,实时给出异常分数。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









