






 本文讲述了作者通过Python爬虫技术,使用requests和BeautifulSoup库从www.netbian.com抓取壁纸图片,处理编码问题,解析HTML并下载图片的过程,强调了代码实现和学习中的逐步推进。
本文讲述了作者通过Python爬虫技术,使用requests和BeautifulSoup库从www.netbian.com抓取壁纸图片,处理编码问题,解析HTML并下载图片的过程,强调了代码实现和学习中的逐步推进。
先看效果图:


我这个是爬了三页的壁纸60张。
上代码了。
import requests
import re
import os
from bs4 import BeautifulSoup
count=0
img_path = "./壁纸图片/"#指定保存地址
if not os.path.exists(img_path):
os.mkdir(img_path)
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0",
"Accept":"image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"
}
for num in range(2,5,1):
url=f"http://www.netbian.com/index_{num}.htm"
html=requests.get(url,headers=headers)
html.encoding = "gbk"
print(html.status_code)
if html.ok:
html = html.text
#print(html)
soup = BeautifulSoup(html,'html.parser')
all_list=soup.find(class_="list")
all_img = all_list.find_all("img")
for img in all_img:
src=img['src']
print(src)
count+=1
myimg = requests.get(src)
file_name = f'{img_path}图片{str(count)}.jpg'
# 图片和音乐WB的二进制写入方式
f = open(file_name, "wb")
f.write(myimg.content)
看起来还挺简单的,但是我花了,一下午的时间,去看b站和自己试试。才搞完。效率好低。
上面导入了re的包,我想用re但是我不会经过简单的尝试放弃了。
简单说一下代码吧!!!
1.上面那个头,在我上一篇的爬虫,有该怎么找!!!
2.
count=0
img_path = "./壁纸图片/"#指定保存地址
if not os.path.exists(img_path):
os.mkdir(img_path)这里count是图片名字,img_path是有没有这样一个文件夹,来让我存储我的壁纸。if么有就新建。
3.
for num in range(2,5,1):
url=f"http://www.netbian.com/index_{num}.htm"
html=requests.get(url,headers=headers)
html.encoding = "gbk"
print(html.status_code)这里的gbk我想写一下:
GBK和UTF-8的解码方式——这个就是为了防止乱码


这个是在知乎上找的,very good!
4.
这个就很重要了
html = html.text
#print(html)
soup = BeautifulSoup(html,'html.parser')
all_list=soup.find(class_="list")
all_img = all_list.find_all("img")
for img in all_img:
src=img['src']
print(src)细说吧:
其中这个all_list是找到所有的包含了图片的列表: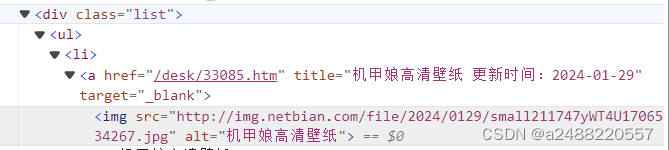
找到之后,再找img的照片
然后找到src后面的网址。
5. 下来这个也重要哈
count+=1
myimg = requests.get(src)
file_name = f'{img_path}图片{str(count)}.jpg'
# 图片和音乐WB的二进制写入方式
f = open(file_name, "wb")
f.write(myimg.content)
请求访问src,然后起个名字,然后wb的写入方式,然后写入文件
到这里了,学习之路任重而道远。过几天读卡器回来了,就可以继续搞k210了加油
爬虫还是得一步一步爬
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









