







RAG 是什么
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的技术方案
RAG 技术就像给 AI 装上了「实时百科大脑」,通过先查资料后回答的机制,让 AI 摆脱传统模型的”知识遗忘”困境
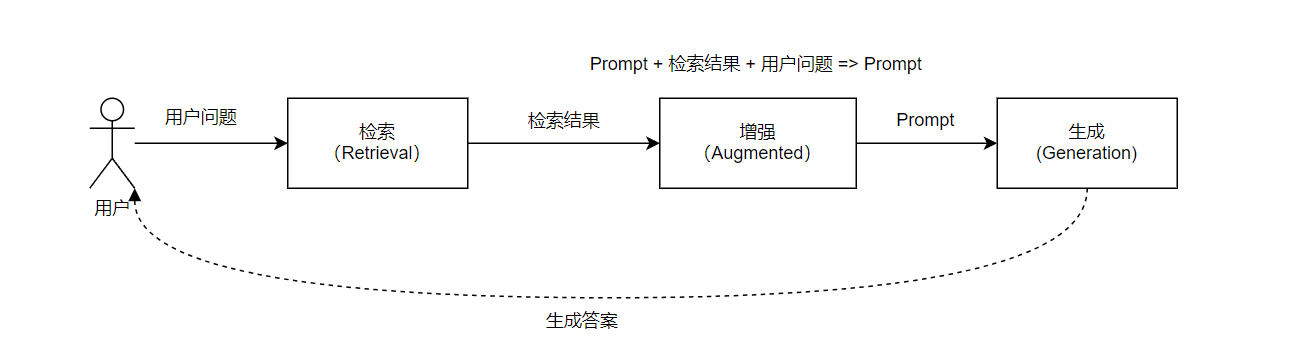
主要核心流程分为:
- 检索(Retrieval):基于用户的输入,从外部知识库(数据库、文档、网页)中检索与查询相关的文本片段,通常使用向量化表示和向量数据库进行语义匹配。
- 生成(Generation): 将用户查询与检索到的内容作为上下文输入给 LLM(如 GPT、DeepSeek 等),由模型输出最终回答。
RAG 解决了什么问题
- 知识更新滞后
LLM 是离线训练的,一旦训练完成后,它们无法获取新的信息,因此,它们无法回答训练数据时间点之后发生的事件,比如“今天的最新新闻”
- 幻觉现象
大语言模型(LLM) 的回答是根据已有的 训练数据 和概率预测得出来的,当面对没有在训练中见过的问题时,模型可能会“编造”看似合理但实际上不准确或虚构的内容
RAG 是如何解决这些问题的?
RAG 将信息检索与语言生成相结合,在回答问题时,首先从外部知识库(如网页、数据库、文档等)中检索相关信息,再基于这些信息生成回答。这样一来:
- 即使模型本身不包含最新知识,也能通过检索获取最新内容
- 回答更加有依据,减少“编答案”的幻觉现象
RAG 流程
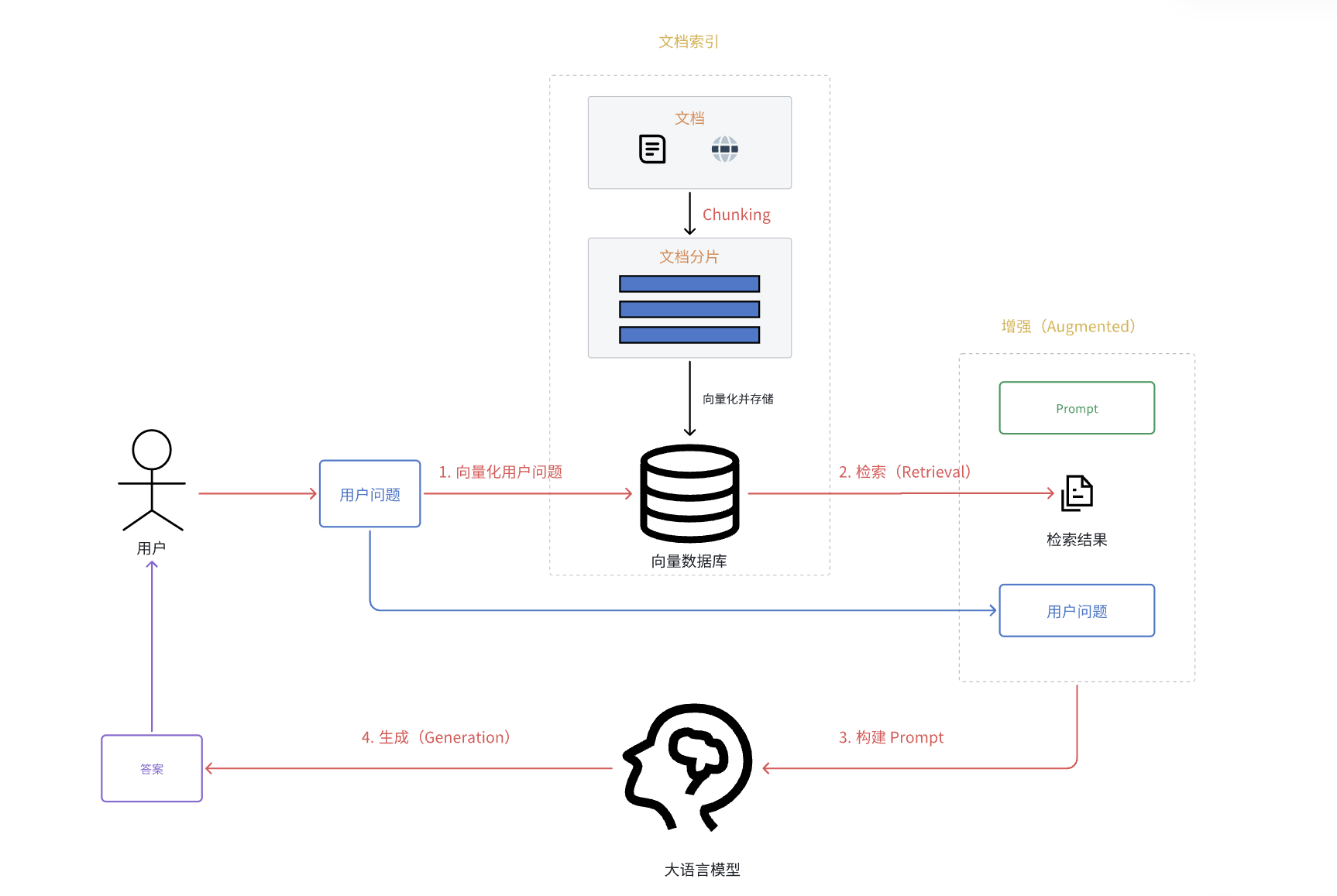
文档索引
在 RAG 中,文档索引 是整个流程的基础环节之一,将文档(word,excel,PDF,Markdown 等)根据一定的规则容划分为文本块(chunk),然后通过 Embedding 模型将文本块转换为向量并存入向量数据库中
文档索引的目的是为了实现高效、准确的信息检索,为后续的大语言模型生成提供可靠的上下文支持。
步骤
- 向量化用户问题:将 用户问题 用相同的 Embedding 模型转换为向量,用以检索相关知识分片
- 检索(Retrieval):通过向量数据库一系列高效的数学计算 (如余弦相似度、欧氏距离等),检索出语义相似度最高的几个知识分片(Top_k)
- 构建 Prompt :将 Prompt + 检索结果+ 用户问题 构建成完整的 Prompt
- 生成(Generation):大语言模型再根据这个 Prompt 生成结果
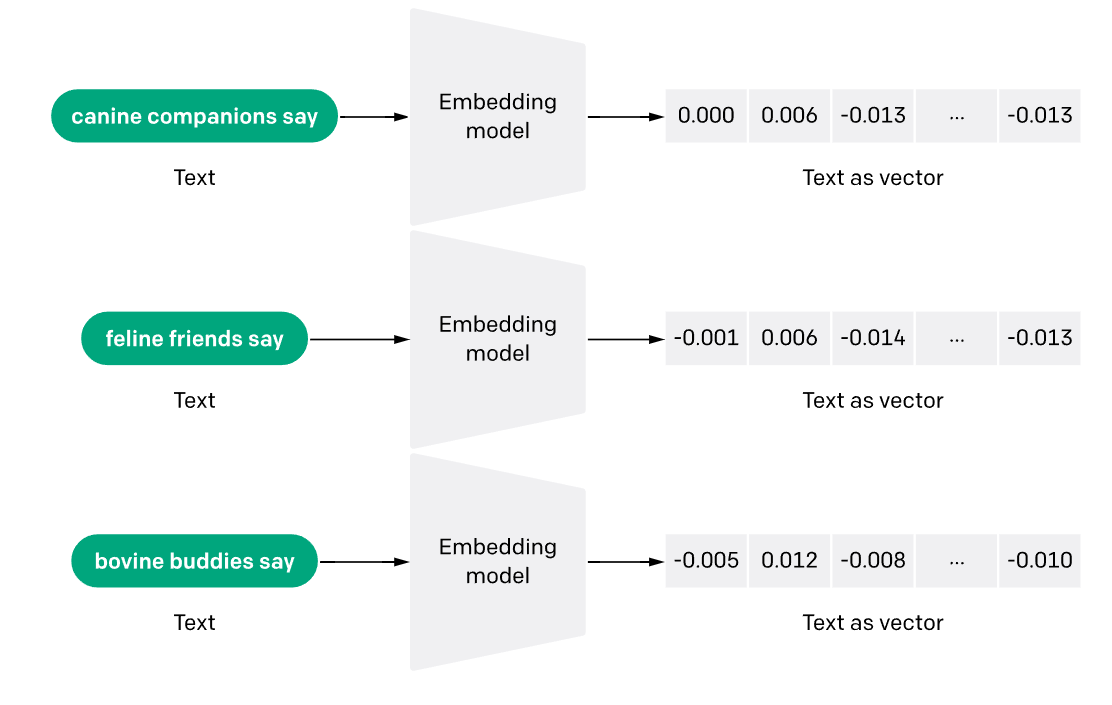
Embedding 模型是什么?
Embedding 是一种将文字序列(如词、句子或文档)转换为向量表示(固定维度的向量)的技术
模型目标:使得具有相似语义的文字序列对应的向量尽可能接近(即相似度高),而语义不同的文字序列对应的向量尽可能远离(即相似度低)
作用:通过数学计算向量之间的距离,快速检索出相似度最高的文字序列


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









