







浏览器开发者工具就是给专业的WEB应用和网站开发人员使用的工具,包含了对HTML查看和编辑JavaScript控制台网络状况监视等功能,是开发JavaScript CSS HTML 和Ajax的得力助手。
作用:快速定位元素,查看元素信息。
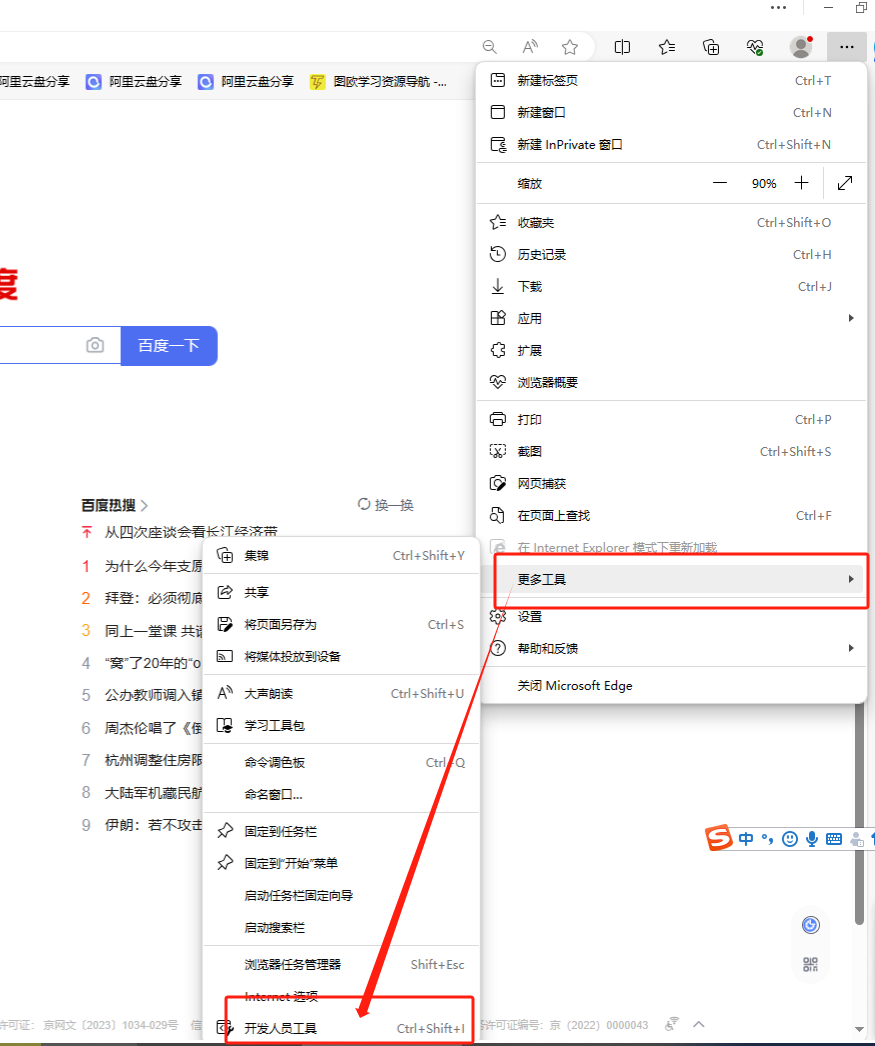
快捷键:一般在Windows系统上打开浏览器开发者工具 ——按F12
谷歌浏览器:在页面上点击右键选择“检查”
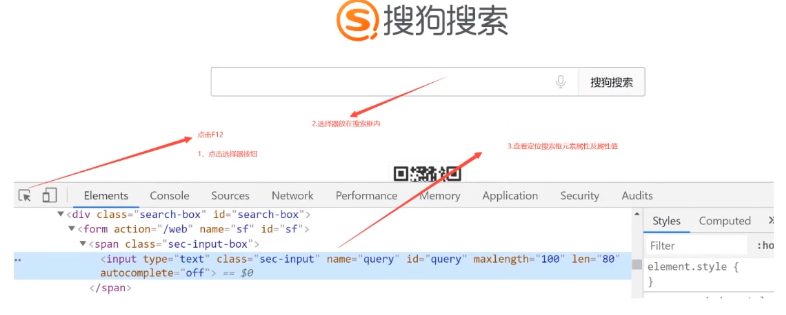
如何进行元素定位
元素定位:通过元素的信息或元素层级结构来定位元素的。
- 元素的信息:指元素的标签名以及元素的属性 id class name
- 元素的层级结构:指元素之间相互嵌套的层级结构。
1. 查看器
查看器工具允许您查看当前正在检查的网页的HTML, CSS。使用它,您可以检查页面上的每个元素应用了哪些CSS。它还允许您预览即时更改的HTML和CSS反映在浏览器中。这些更改不是永久性的,刷新浏览器窗口后会重新设置。
2. 控制台
控制台用于调试网页源代码中的JavaScript。控制台窗口充当我们的调试窗口,允许我们处理没有按预期工作的JavaScript。它允许您对当前加载在浏览器中的页面运行代码块或单行JavaScript。控制台报告浏览器在试图执行代码时遇到的错误。
3.调试器(Firefox)
Sources/Debugger UI面板监视JavaScript代码,并允许您设置断点和监视变量的值。断点设置在代码中我们希望暂停执行周期并调试或识别执行问题的地方。使用这个面板,可以调试JavaScript。
3.网络监控
Network面板用于确保正在下载或上传的所有资源都按预期完成。它使我们能够查看页面加载时发出的网络请求。它告诉我们每个请求需要多长时间,以及每个请求的详细信息。监控器在加载时是空的,在监控器打开时,一旦执行任何操作,就会创建日志。
4. 性能工具
性能在运行时记录,并告知页面在运行时的表现,而不是加载时的表现。该工具可以大致了解站点的总体响应能力有多好。它还可以衡量网站的JavaScript和布局性能。该工具创建一个记录/配置文件,在一段时间内的网站,该工具使运行。一个概述是使用RAIL模型创建的,列出了渲染网站所做的浏览器活动的所有框架。
5. 可访问性检查
该工具提供了一种访问重要信息的方法,这些信息通常通过当前视图页面上的辅助技术堆栈暴露在辅助技术堆栈中。它允许检查哪些元素缺失或需要注意
















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









