







Selenium提供了八种定位元素方式
- id
id定位:通过元素的id属性来定位元素,HTML规定id属性在整个HTML文档中必须是唯一的。
需求:驱动谷歌浏览器 打开谷歌浏览器 搜索框输入“温州图书馆”
id定位方法
find_element_by_id(id) #id参数表示的是id的属性值
案例实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:驱动谷歌浏览器,打开百度搜索页, 搜索框输入“温州图书馆”
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 搜狗浏览页
driver.get("https://www.baidu.com")
# 定位搜索框 id 输入“温州读书馆”
driver.find_element_by_id("kw").send_keys("温州图书馆")- name
name定位:通过name属性进行定位,name属性可以重复
定位方法
find_element_by_name(name) # name 参数表示的是name的属性值
案例实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:驱动谷歌浏览器,打开百度搜索页, 搜索框输入“温州图书馆”
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 搜狗浏览页
driver.get("https://www.baidu.com")
# 定位搜索框 name 输入“温州图书馆”
driver.find_element_by_name("wd").send_keys("温州图书馆")- class_name
通过元素的class 属性值进行元素定位 class 属性值是可重复的
定位方法
find_element_by_class_name(class_name) #class_name 参数表示的是class的其中一个属性值
案例实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:驱动谷歌浏览器,打开百度搜索页, 搜索框输入“温州图书馆”
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 搜狗浏览页
driver.get("https://www.baidu.com")
# 定位搜索框 class_name 输入“温州图书馆”
driver.find_element_by_class_name("s_ipt").send_keys("温州图书馆")
- tag_name
通过标签名称进行定位,在同一个html页面当中,相同标签会有很多
如果有重复的标签,定位到元素默认都是第一个标签
定位方法:
find_element_by_tag_name(tag_name) # tag_name表示的是元素的标签名称。
代码实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:驱动谷歌浏览器,打开搜狗搜索页, 搜索框输入“温州图书馆”
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 搜狗浏览页
driver.get("https://www.sogou.com/")
print(driver.find_element_by_tag_name("li").text)
driver.find_element_by_tag_name("input").send_keys("温州图书馆")- link_text
通过超链接的全部文本信息进行元素定位,主要用来定位a标签
定位方法
find_element_by_link_text(link_text) #link_text 参数代表的是a标签的全部文本内容
代码实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:驱动谷歌浏览器,打开搜狗搜索页, 通过link-text的方法点击微信超链接
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 搜狗浏览页
driver.get("https://www.sogou.com/")
driver.find_element_by_link_text("微信").click()
- partial_link_text
通过超链接的局部文本信息进行元素定位,主要用来定位a标签
定位方法
find_element_by_partial_link_text(partial_link_text)
partial_link_text 表示的是a标签的局部文本内容
案例实现:
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:驱动谷歌浏览器,打开搜狗搜索页, 通过超链接的局部文本信息进行元素定位,通过信
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 搜狗浏览页
driver.get("https://www.sogou.com/")
driver.find_element_by_partial_link_text("信").click()
- 定位一组元素
定位一组元素的方法
find_elements_by_tag_name(tag_name)
案例实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位一组元素返回的值是一个列表
可以通过下标来使用列表中的元素,下标是从0开始
需求 通过li标签定位一组元素,通过索引方法对知乎链接点击
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 搜狗浏览页
driver.get("https://www.sogou.com/")
els = driver.find_elements_by_tag_name('li')
for i in els:
print(i.text)
#通过下角标找到知乎
els[2].click()
- xpath定位
XPath即为XML Path的简称,它是一门在XML文档中查找元素信息的语言
HTML可以看做是XML的一种实现,所以Selenium用户可以使用这种强大的语言在Web应用中的定位元素
定位思路:
路径-定位
利用元素属性-定位
层级与属性结合-定位
定位方法:
driver.find_element_by_xpath(xpath)
路径定位
绝对路径:从最外层元素到指定元素之间所有经过元素层级的路径
1.绝对路径以/html根节点开始,使用/来分隔元素层级
如:/html/body/div/fieldset/p[1]/input
案例实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 淘宝
driver.get("https://www.taobao.com/")
driver.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div/div[1]/form/div[3]/input').send_keys("平衡車")
2. 相对路径:匹配任意层级的元素,不限制元素的位置
1) 相对路径以//开始
2)格式://input
要确保该元素在页面中是唯一的
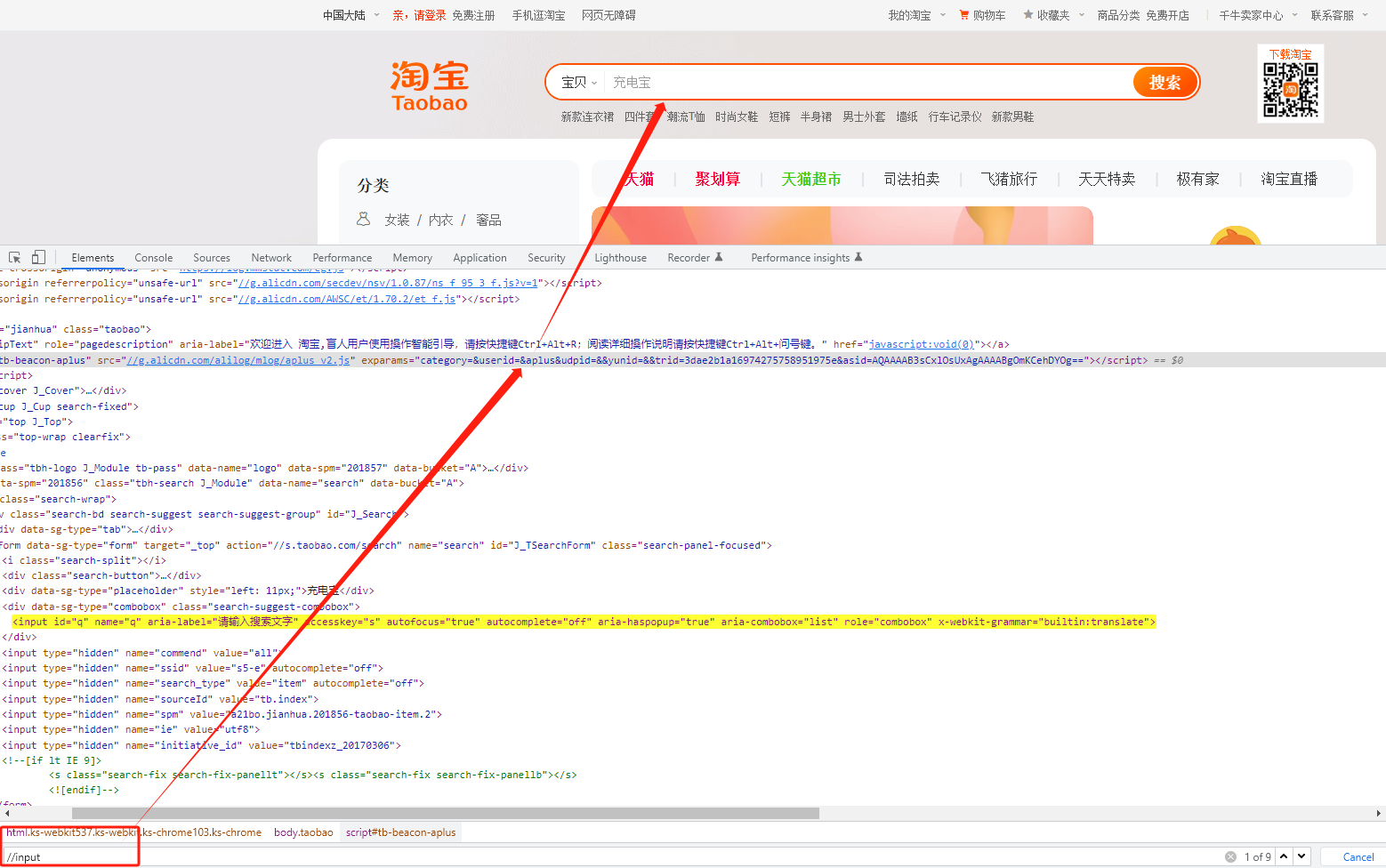
案例实现
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 淘宝
driver.get("https://www.taobao.com/")
driver.find_element_by_xpath('//input').send_keys("平衡車")
利用元素属性定位
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 淘宝
driver.get("https://www.taobao.com/")
driver.find_element_by_xpath('//input[@id="q"]').send_keys("平衡车")
利用层级和属性相结合
同级节点或是兄弟节点 父级节点
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 百度
driver.get("https://www.baidu.com/")
driver.find_element_by_xpath('//form[@id="form"]/span/input').send_keys("平衡车")
xpath扩展
一个/是绝对路径,从根元素开始
两个//是相对路径,递归查找所有子孙
一个.是当前层,两个..是上一层
@表示取属性
[]叫谓语,里面跟的是查询条件
条件支持算术运算+,-,*,/,>,<,条件支持逻辑运算 and or
取文本值用text(),不加@因为它是个函数
常用函数:
contains(属性名或者节点名,文本值)
text()是取文本值,也可以当做一个查询条件
last() 取末尾,倒数第二last()-1
starts-with()表示以**开头,写法是括号加两个入参
not(),表示否定,把内容全包进去
count(),取节点或属性个数

1.选取第一本书的定价
//book[1]/price
2.选取最后一本书的作者
//book[last()]/author
3.选取定价在30到40之间的书的标题
//book[price>30 and price<40]/title
4.选取 作者多于一个的书的标题
//book[count(author)>1]/title
5.选取 分类不是web且价格低于40的书的作者
//book[@category!='web' and price<40]/author
6.选取 标题名称包含X的所有书的定价值
//title[contains(title,x)]/../price/text()
7.选取单个作者 且分类是WEB的书的出版年分值
//book[count(author)=1 and @category='web']/year/text()
8.选取多个作者且标题以X开头的书的定价
//book[start-with(title,'x') and cout(author)>1]/price/text()
9.选取 分类是web 且作者不包括James的所有书的标题
//book[@category='web' and not(contains(author,'James'))]- css定位
css是一种语言,它用来描述HTML元素的显示样式
在CSS中,选择器是一种模式,用于选择需要添加样式的元素
在Selenium中也可以使用这种选择器来定位元素
提示:
CSS定位比XPath定位的速度快
定位思路
id选择器
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框 ID定位选择器
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 百度
driver.get("https://www.baidu.com/")
driver.find_element_by_css_selector('#kw').send_keys("平衡车")
class选择器
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框 class选择器
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 百度
driver.get("https://www.baidu.com/")
driver.find_element_by_css_selector('.s_ipt').send_keys("平衡车")
属性选择器
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 百度
driver.get("https://www.baidu.com/")
driver.find_element_by_css_selector('[class="s_ipt"]').send_keys("平衡车")层级选择器
# -*- coding: utf-8 -*-
"""
@Time : 2023/10/16 9:37
@Author : 娜年花开
@File : 1.py
@Desc : 需求:定位搜索框
"""
# 导包
from selenium import webdriver
import time
# 实例化谷歌浏览器
driver = webdriver.Chrome()
time.sleep(2)
# 打开 百度
driver.get("https://www.baidu.com/")
driver.find_element_by_css_selector('form[id="form"] > span > input').send_keys("平衡车")
















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









