






文章目录
- 更新时间:2022-11-18,更新内容:统计求和、流量排序
- 前言
- MapReduce流程解析
- MapReduce案例-WordCount
- MapReduce-分区
- MapReduce-排序和序列化
- MapReduce-规约(Combiner)
- MapReduce综合案例-统计求和
- MapReduce综合案例-流量排序
- MapReduce综合案例-手机号码分区
- MapReduce的运行机制
- MapReduce案例-Reduce端join操作
- MapReduce案例-Map端join操作
- MapReduce案例-求共同好友
- 自定义InputFormat实现小文件合并
- 自定义OutputFormat
- 自定义分组-求TopN
更新时间:2022-11-18,更新内容:统计求和、流量排序
前言
持续更新mapreduce的内容,直到把目录上的内容更新完,如果不忙一天一更。
制作不易,点赞关注加收藏【=v=】
MapReduce流程解析
因为例子更好理解,下面以读取word.txt文件为例,想要了解的更深入请自行搜索,如果觉得难懂请结合案例WordCount进行理解
1.流程解析
-
读取文件
- 使用TextInputFormat方法
- TextInputFormat方法会把文件一行一行的读取,并且转化为<k,v>键值对的形式
- k代表行偏移量,比如:第一行的偏移量是0,第二行的偏移量可能是20
- v代表这一行的内容
- 如果使用TextOutputFormat读取word.txt的内容,最终结果应该是3个<k1,v1>键值对
- 注意:有多少个<k1,v1>键值对就会执行多少次map逻辑(代码)
- 使用TextInputFormat方法
-
map阶段
- 需要自己编写代码,将<k1,v1>转成<k2,v2>
-
shuffle阶段
- 包括四个小阶段分别是:分区、排序、规约、分组
- 简单的理解,shuffle阶段就是把<k2,v2>==>新<k2,v2>
- 注意:如果不编写shuffl阶段的代码,会执行默认的shuffle,也就是按照键值对中k的值进行分组分组
-
reduce阶段
- 需要自己编写代码,将<k2,v2>==><k3,v3>
-
输出文件
-
使用TextOutputForamat方法
-
TextInputFormat方法会按照每个<k3,v3>键值对为一行,输出到结果文件中
流程图

-
MapReduce案例-WordCount
1.流程图

2.流程解析
-
读取文件
- 使用TextInputFormat方法
- 因为TextInputFormat方法会把文件一行一行的读取,并且把每一行变成<k,v>键值对的形式,所以<k1,v1>是<0,hadoop,mapreduce,spark>,k1是0,v1是hadoop,mapreduce,spark。
- 第二行、第三行的数据也是<k1,v1>,也是上面这种形式
-
map阶段
-
<k1,v1>经过map阶段,将会被执行的map逻辑(代码)变成<k2,v2>,k2是单词,v2是1。
-
<k2,v2>==<hadoop,1>
<mapreduce,1>
<spark,1>
<hadoop,1>
…
-
-
shuffle阶段
-
因为没有编写shuffle阶段的代码,所以会按照默认shuffle处理<k2,v2>
-
默认:也就是默认分组,会按照k进行分组,得到 新<k2,v2>,新<k2,v2>中v2为一个集合,里面存储相同k的v值
-
<k2,v2>=>新<k2,v2>
-
新<k2,v2>==<hadoop,<1,1,1>>
<mapreduce,<1,1,1>>
<spark,<1,1,1>>
-
-
reduce阶段
-
新<k2,v2>经过reduce阶段,执行reduce逻辑(代码),变为<k3,v3>
-
<k3,v3>==<hadoop,3>
<mapreduce,3>
<spark,3>
-
-
输出文件
- 使用TextOutputFormat方法
- TextOutputFormat方法:每执行一次reduce逻辑就会写出一行,按照reduce逻辑定义的输出数据形式写入结果文件中。
3.代码编写
3.1map逻辑
-
MyMapper是自定义类,需要继承Mapper类
- Mapper<LongWritable, Text,Text,LongWritable>
- LongWritable是k1的类型
- Text是v1的类型
- Text是k2的类型
- LongWritable是v2的类型
- Mapper<LongWritable, Text,Text,LongWritable>
-
重写map方法,实现逻辑,一个<k1,v2>键值对会执行一次map方法
-
map方法中
- key对应k1的值,也就是偏移量
- value对应v1的值,也就是hadoop,mapReduce,spark
-
value.toString().split(“,”),把value类型转换为字符串并且按照逗号分隔返回一个字符串数组
-
for循环遍历字符串数组中的值,也就是单词,把每个单词都写出,v的值为1
-
写入上下文输出<k2,v2>
-
经过map逻辑得出,<k2,v2>==<hadoop,1>
<mapreduce,1>
<spark,1>
<hadoop,1>
…
-
//map逻辑
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
//重写map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
for (String word : split) {
//写入上下文
context.write(new Text(word),new LongWritable(1));
}
}
}
3.2reduce逻辑
-
MyReducer是自定义类,继承Reducer类
-
Reducer<Text,LongWritable,Text, NullWritable>
- Text对应k2的类型
- LongWritable对应v2的类型
- Text对应k3的类型
- NullWritable对应v3的类型
-
重写reduce方法,实现逻辑,一个新<k2,v2>键值对会执行一次reduce方法
-
reduce方法中
- key对应新k2的值,也就是单词
- values对应新v2的值,也就是集合<1,1,1>
-
遍历集合<1,1,1>,并把集合中的元素累加
-
写入上下文输出<k3,v3>
-
经过reduce逻辑得出,<k3,v3>==<hadoop,3>
<mapreduce,3>
<spark,3>
-
//reduce逻辑
public static class MyReducer extends Reducer<Text,LongWritable,Text, NullWritable>{
//重写reduce逻辑
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//单词个数
long sum = 0;
for (LongWritable value : values) {
//求集合中1的个数
sum +=value.get();
}
//写入上下文(结果文件)
context.write(new Text(key.toString()+","+sum),NullWritable.get());
}
}
3.3主函数
主函数中
- Configuration conf = new Configuration();
Job job = Job.getInstance(conf, “WordCount”);
job.setJarByClass(WordCount.class);- WordCount是主类名
- 设置输入方法和路径
- 设置map类,分别设置了自定义map类和输出的k2,v2类型
- 设置reduce类,分别设置了自定义reduce类和输出的k3,v3类型
- 判断输出路径是否存在,如果存在则删除
- 通过FileSystem获取文件系统对象,通过这个对像判断输出路径是否存在,存在则删除
- 设置输出方法和路径
//主函数
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
//设置输出方法和路径
job.setInputFormatClass(TextInputFormat.class);
//本地路径
TextInputFormat.addInputPath(job, new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\data\\word.txt"));
//设置map类
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce类
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//判断输出路径是否存在,如果存在则删除
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\output");
if (fileSystem.exists(path)){
fileSystem.delete(path, true);
}
//设置输出方法和路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, path);
job.waitForCompletion(true);
3.4完整代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class WordCount {
//map逻辑
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
//重写map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
for (String word : split) {
//写入上下文
context.write(new Text(word),new LongWritable(1));
}
}
}
//默认shuffle
//reduce逻辑
public static class MyReducer extends Reducer<Text,LongWritable,Text, NullWritable>{
//重写reduce逻辑
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//单词个数
long sum = 0;
for (LongWritable value : values) {
//求集合中1的个数
sum +=value.get();
}
//写入上下文(结果文件)
context.write(new Text(key.toString()+","+sum),NullWritable.get());
}
}
//主函数
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
//设置输入方法和路径
job.setInputFormatClass(TextInputFormat.class);
//本地路径
TextInputFormat.addInputPath(job, new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\data\\word.txt"));
//设置map类
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce类
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//判断输出路径是否存在,如果存在则删除
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\output");
if (fileSystem.exists(path)){
fileSystem.delete(path, true);
}
//设置输出方法和路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, path);
job.waitForCompletion(true);
}
}
MapReduce-分区
1.流程图

2.流程解析
-
读取文件
- 方法:TextInputFormat
-
map阶段
-
将<k1,v1>==><k2,v2>
-
<k2,v2>==<20,null>
<15,null>
<13,null>
-
-
shuffle阶段
- 进行分区
- 制定分区规则:大于15为0分区,小等于15为1分区
-
reduce阶段
-
将shuffle阶段的新<k2,v2>==><k3,v3>
-
<k3,v3>==<20,null>
<15,null>
<13,null>
-
reduece阶段对键值对的值没做什么改变
-
3.代码编写
3.1map逻辑
这里的map逻辑很简单不做过多描述,如果看不懂,建议多看看对WordCount做出的解析。
//map
public static class MyMapper extends Mapper<LongWritable, Text,Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(new Text(value.toString()), NullWritable.get());
}
}
3.2分区逻辑
- 首先自定义类,继承Partitioner类
- Partitioner<Text,NullWritable>
- Text对应k2的类型
- NullWritable对应v2的1类型
- int num = Integer.parseInt(text.toString());
- 将Text类型转为Int类型
- return 0;
- 标记为0分区
- return 1;
- 标记为1分区
//分区
public static class MyPartitioner extends Partitioner<Text,NullWritable>{
@Override
public int getPartition(Text text, NullWritable nullWritable, int numPartitions) {
int num = Integer.parseInt(text.toString());
if (num > 15) return 0;
else return 1;
}
}
3.3reduce逻辑
这里的reduce逻辑很简单不做过多描述。
//reduce
public static class MyReducer extends Reducer<Text,NullWritable,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
3.4主函数
- 主函数的内容需要重新设置map、reduce的输出键值对类型
- 需要设置分区类
- job.setPartitionerClass(MyPartitioner.class);
- 需要设置reduceTask个数,因为要输出到两个结果文件
- job.setNumReduceTasks(2);
- 除了路径需要根据自己的情况来设置,还有上面需要变动的内容,其他地方基本没有改变
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Partition");
job.setJarByClass(Partition.class);
//输出
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\data\\partition.csv"));
//map
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//分区
job.setPartitionerClass(MyPartitioner.class);
//设置reduceTask
job.setNumReduceTasks(2);
//reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//输出
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\output");
if (fileSystem.exists(path)) fileSystem.delete(path, true);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, path);
job.waitForCompletion(true);
}
3.5完整代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
/*需求
详细数据参见partition.csv 这个文本文件,其中第六个字段表示开奖结果数值,现在需求将15以上的结果以及15以下的结果进行分开成两个文件进行保存
* */
public class Partition {
//map
public static class MyMapper extends Mapper<LongWritable, Text,Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(new Text(value.toString()), NullWritable.get());
}
}
//分区
public static class MyPartitioner extends Partitioner<Text,NullWritable>{
@Override
public int getPartition(Text text, NullWritable nullWritable, int numPartitions) {
int num = Integer.parseInt(text.toString());
if (num > 15) return 0;
else return 1;
}
}
//reduce
public static class MyReducer extends Reducer<Text,NullWritable,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Partition");
job.setJarByClass(Partition.class);
//输出
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("file:///G:\\data\\data.csv"));
//map
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//分区
job.setPartitionerClass(MyPartitioner.class);
//设置reduceTask
job.setNumReduceTasks(2);
//reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//输出
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path("file:///G:\\output");
if (fileSystem.exists(path)) fileSystem.delete(path, true);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, path);
job.waitForCompletion(true);
}
}
MapReduce-排序和序列化
排序理解很简单,就是按照某种规则进行升/降进行排序。
可以简单的理解为,把对象以流的形式输入,叫做序列化。把对象以流的形式输出,叫做反序列化。
1.流程图

2.流程解析
-
输入
-
map逻辑
-
用自定义类SortBean封装字母、数字
-
<k2,v2>==<SortBean(a,1)>
…
-
-
自定义类SortBean
- 实现WritableComparable接口
- 重写方法
- 新<k2,v2>==按照排序规则排序后的键值对<SortBean(a,1),null>
-
reduce阶段
-
<k3,v3>==<SortBean(a,1),null>
…
-
-
输出
3.代码编写
因为逻辑map和reduce逻辑太过简单这里就不浪费篇幅了
自定义排序类也比较简答注释足以,直接上代码
3.1完整代码
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class SortBean implements WritableComparable<SortBean> {
private String word;
private int num ;
//构造方法
//有参和无参都要有
public SortBean() {
}
public SortBean(String word, int num) {
this.word = word;
this.num = num;
}
//重写toString
//定义输出规则
@Override
public String toString() {
return word + "\t"+ num ;
}
//定义排序规则
@Override
public int compareTo(SortBean o) {
//1.按照字母排序
//字符串的方法:compareTo会按照字典顺序给字母排序,返回一个数值
int i = this.word.compareTo(o.word);
//如果i==0,代表字母相同
if (i==0){
//升序排序,反过来写就是降序排序
return this.num - o.num;
}
return i;
}
//序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(word);
dataOutput.writeInt(num);
}
//反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.word = dataInput.readUTF();
this.num = dataInput.readInt();
}
}
import mapreduceTest.sort.SortBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class Sort {
//map
public static class MyMapper extends Mapper<LongWritable, Text,SortBean, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, SortBean, NullWritable>.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
//获取字母
String word = split[0];
//获取数字
int num = Integer.parseInt(split[1]);
//封装
SortBean sortBean = new SortBean(word, num);
//写入上下文
context.write(sortBean, NullWritable.get());
}
}
//排序不需要写逻辑,只需要写自定义排序的类
//reduce
public static class MyReducer extends Reducer<SortBean,NullWritable,SortBean,NullWritable>{
@Override
protected void reduce(SortBean key, Iterable<NullWritable> values, Reducer<SortBean, NullWritable, SortBean, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Sort.class);
job.setInputFormatClass(TextInputFormat.class);
//本地运行
TextInputFormat.addInputPath(job, new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\data\\sort.txt"));
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(SortBean.class);
job.setOutputValueClass(NullWritable.class);
//分区、排序、规约、分组
//排序不需要job设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(SortBean.class);
job.setOutputValueClass(NullWritable.class);
FileSystem fileSystem = FileSystem.get(new Configuration());
Path path = new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\output");
if ((fileSystem).exists(path)){
fileSystem.delete(path, true);
}
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, path);
job.waitForCompletion(true);
}
}
MapReduce-规约(Combiner)
Combiner的作用就是对map端的输出先做一次合并,以减少map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段。
1.流程图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fvXKsOJy-1667306033472)(G:\Desktop\A编程自学笔记\MapReduce\CSDN\combiner.png)]
2.流程解析
- 输出
- map阶段,和单词统计的逻辑一样
- 规约(Combiner)
- 需要继承类Reducer类,其实规约就是相当于把放在Reduce阶段执行的逻辑,放在了shuffle阶段以此来减少网络IO
- reduce阶段,把规约后的数据输出
3.代码编写
3.1规约逻辑
- 自定义类MyCombiner,继承Reducer类
//combiner
public static class MyCombiner extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0 ;
for (LongWritable value : values) {
long num = value.get();
sum +=num;
}
context.write(new Text(key), new LongWritable(sum));
}
}
- job任务需要添加:job.setCombinerClass(MyCombiner)
3.2完整代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class Combiner {
//map逻辑
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//切分单词
String[] split = value.toString().split(",");
for (String s : split) {
context.write(new Text(s), new LongWritable(1));
}
}
}
//combiner
public static class MyCombiner extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0 ;
for (LongWritable value : values) {
long num = value.get();
sum +=num;
}
context.write(new Text(key), new LongWritable(sum));
}
}
//reduce
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//遍历集合,其实集合中只有一个元素,但是因为是迭代器类型所以还是需要遍历
for (LongWritable value : values) {
context.write(new Text(key), value);
}
}
}
//
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//如果打包运行出错,则需要加该配置
job.setJarByClass(Combiner.class);
//配置job对象(八个步骤)
//1.指定文件读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, new Path("file:///G:\\word.txt"));
//2.指定map阶段的处理方式和输出的数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//3. 4. 5. 6. 是shuffle阶段的分区、排序、规约、分组,使用默认方式。
//规约
job.setCombinerClass(MyCombiner.class);
//7.指定reduce阶段的处理方式和输出的数据类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//8.指定输出文件的方式和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
//判断输出路径是否存在,如果存在则删除,
//获取FileSystem
FileSystem fileSystem = FileSystem.get(new Configuration());
Path path = new Path("file:///G:\\output");
//判断路径是否存在,如果存在则删除
if (fileSystem.exists(path)){
fileSystem.delete(path, true);
}
TextOutputFormat.setOutputPath(job, path);
//等待任务结束
job.waitForCompletion(true);
}
}
MapReduce综合案例-统计求和
需求:统计求和
-
任务:统计每个手机号的上行数据包总和,下行数据包总和,上行总流量之和,下行总流量之和。
- 部分数据

--------数据解释:从左到右
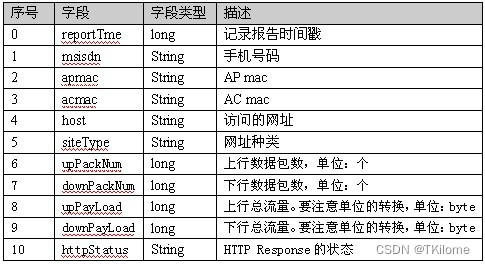
- 部分数据
-
分析:
- 以手机号码作为key值,上行数据包,下行数据包,上行总流量,下行总流量四个字段作为value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输入
-
完整代码
-
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException; /** * 统计求和 */ public class CountSum { //map //手机号作为key输出。 //上行数据包总和,下行数据包总和,上行总流量之和,下行总流量之和作为value输出 public static class MyMapper extends Mapper<LongWritable, Text,Text,Text>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { //因为每条数据都是按照\t分开的,按照\t切分 String[] split = value.toString().split("\t"); //手机号 String num = split[1]; //上行数据包总和,下行数据包总和,上行总流量之和,下行总流量之和 String upPackNUm = split[6]; String downPackNum = split[7]; String upPayLoad = split[8]; String downPayLoad = split[9]; //写入上下文 context.write(new Text(num), new Text(upPackNUm+","+downPackNum+","+upPayLoad+","+downPayLoad)); } } //reduce //默认按key分组将,所以直接将v2集合中的元素进行求和 public static class MyReducer extends Reducer<Text,Text,Text, NullWritable>{ @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { //上行数据包总和,下行数据包总和,上行总流量之和,下行总流量之和,之和 double upPackNUm_sum = 0.0; double downPackNum_sum = 0.0; double upPayLoad_sum = 0.0; double downPayLoad_sum = 0.0; for (Text value : values) { String[] split = value.toString().split(","); upPackNUm_sum += Double.parseDouble(split[0]); downPackNum_sum += Double.parseDouble(split[1]); upPayLoad_sum += Double.parseDouble(split[2]); downPayLoad_sum += Double.parseDouble(split[3]); } context.write(new Text(key.toString()+","+upPackNUm_sum+","+downPackNum_sum+","+upPayLoad_sum+","+downPayLoad_sum),NullWritable.get() ); } } public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf,"CountSum"); job.setJarByClass(CountSum.class); //1.输入 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job, new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\data\\data_flow.dat")); //2.map job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //3.reduce job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //4.输出 //判断输出路径是否存在 FileSystem fileSystem = FileSystem.get(conf); Path path = new Path("G:\\Desktop\\A编程自学笔记\\MapReduce\\output"); if (fileSystem.exists(path)) fileSystem.delete(path, true); job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job, path); //设置等待 job.waitForCompletion(true); } }
-
MapReduce综合案例-流量排序
需求:上行流量倒序排序(递减排序)
-
任务:以统计求和的输出文件为输入文件,进行排序输出。
-
分析:自定义FlowBean,参数为上行流量,以FlowBean为map输出的key,以手机号作为Map输出的value。
-
完整代码
-
排序类
-
import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 上行流量排序规则 */ public class FlowSortBean implements WritableComparable<FlowSortBean> { private double upPayLoad; public FlowSortBean() { } @Override public String toString() { return "" + upPayLoad ; } public FlowSortBean(double upPayLoad) { this.upPayLoad = upPayLoad; } @Override public int compareTo(FlowSortBean o) { //降序 return (int) (o.upPayLoad - this.upPayLoad); } @Override public void write(DataOutput out) throws IOException { out.writeDouble(upPayLoad); } @Override public void readFields(DataInput in) throws IOException { this.upPayLoad = in.readDouble(); } }
-
-
逻辑类
-
import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 上行流量排序规则 */ public class FlowSortBean implements WritableComparable<FlowSortBean> { private double upPayLoad; public FlowSortBean() { } @Override public String toString() { return "" + upPayLoad ; } public FlowSortBean(double upPayLoad) { this.upPayLoad = upPayLoad; } @Override public int compareTo(FlowSortBean o) { //降序 return (int) (o.upPayLoad - this.upPayLoad); } @Override public void write(DataOutput out) throws IOException { out.writeDouble(upPayLoad); } @Override public void readFields(DataInput in) throws IOException { this.upPayLoad = in.readDouble(); } }
-
-
MapReduce综合案例-手机号码分区
需求:手机号码分区
-
任务:在统计求和的输出的基础上,继续完善,将不同的手机号分到不同的数据文件的当中去。
-
分析:需要自定义分区来实现,这里我们自定义来模拟分区,将以下数字开头的手机号进行分开。
-
完整代码
-
分区:
-
* 135 开头数据到一个分区文件 * 136 开头数据到一个分区文件 * 137 开头数据到一个分区文件 * 其他的手机号为另一个分区
-
-
代码
-
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException; /** * 手机号分区 * 按照统计求和中输出的结果,进行分区 * 分区规则: * 135 开头数据到一个分区文件 * 136 开头数据到一个分区文件 * 137 开头数据到一个分区文件 * 其他的手机号为另一个分区 */ public class PhoneNumberPartition { //map public static class MyMapper extends Mapper<LongWritable, Text,Text,NullWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(value,NullWritable.get()); } } //partition public static class MyPartitioner extends Partitioner<Text,NullWritable>{ @Override public int getPartition(Text text, NullWritable nullWritable, int numPartitions) { String[] split = text.toString().split(","); //手机号 String num = split[0]; //分区规则 if (num.startsWith("135")) { return 0; }else if (num.startsWith("136")){ return 1; }else if (num.startsWith("137")){ return 2; }else { return 3; } } } //reduce public static class MyReducer extends Reducer<Text,NullWritable,Text,NullWritable>{ @Override protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "PhoneNumberPartition"); //输入 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job, new Path("file:///G:\\Desktop\\A编程自学笔记\\MapReduce\\data\\need2data")); //map job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); //partition job.setPartitionerClass(MyPartitioner.class); //需要设置reduceTask的个数,因为它对应着结果文件的个数。 job.setNumReduceTasks(4); //reduce job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //输出 //判断输出路径是否存在 FileSystem fileSystem = FileSystem.get(conf); Path path = new Path("G:\\Desktop\\A编程自学笔记\\MapReduce\\output"); if (fileSystem.exists(path)) fileSystem.delete(path, true); job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job, path); //设置等待 job.waitForCompletion(true); } }
-
-















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









