







Hystrix是什么?

Hystrix 能使你的系统在出现依赖服务失效的时候,通过隔离系统所依赖的服务,防止服务级联失败,同时提供失败回退机制,更优雅地应对失效,并使你的系统能更快地从异常中恢复。
Hystrix能做什么?
- 在通过第三方客户端访问(通常是通过网络)依赖服务出现高延迟或者失败时,为系统提供保护和控制
- 在分布式系统中防止级联失败
- 快速失败(Fail fast)同时能快速恢复
- 提供失败回退(Fallback)和优雅的服务降级机制
- 提供近实时的监控、报警和运维控制手段
Hystrix设计原则?
- 防止单个依赖耗尽容器(例如 Tomcat)内所有用户线程
- 降低系统负载,对无法及时处理的请求快速失败(fail fast)而不是排队
- 提供失败回退,以在必要时让失效对用户透明化
- 使用隔离机制(例如『舱壁』/『泳道』模式,熔断器模式等)降低依赖服务对整个系统的影响
- 针对系统服务的度量、监控和报警,提供优化以满足近实时性的要求
- 在 Hystrix 绝大部分需要动态调整配置并快速部署到所有应用方面,提供优化以满足快速恢复的要求
- 能保护应用不受依赖服务的整个执行过程中失败的影响,而不仅仅是网络请求
Hystrix实现原理-命令模式
- 将所有请求外部系统(或者叫依赖服务)的逻辑封装到 HystrixCommand或者HystrixObservableCommand(依赖RxJava)对象中
- Run()方法为要实现的业务逻辑,这些逻辑将会在独立的线程中被执行当请求依赖服务时出现拒绝服务、超时或者短路(多个依赖服务顺序请求,前面的依赖服务请求失败,则后面的请求不会发出)时,执行该依赖服务的失败回退逻辑(Fallback)
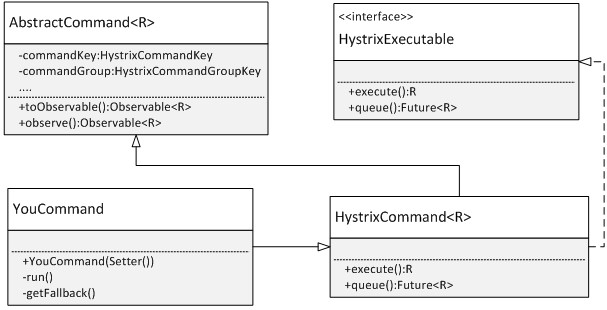
Hystrix实现原理-舱壁模式
货船为了进行防止漏水和火灾的扩散,会将货仓分隔为多个,当发生灾害时,将所在货仓进行隔离就可以降低整艘船的风险。
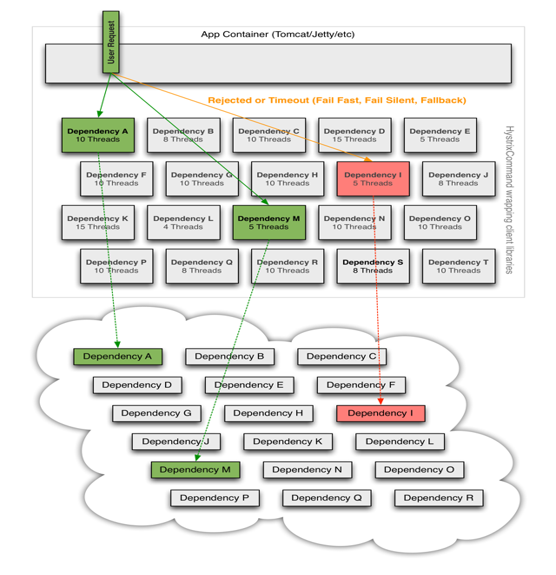
Hystrix实现原理-隔离策略
- 应用在复杂的分布式结构中,可能会依赖许多其他的服务,并且这些服务都不可避免地有失效的可能。如果一个应用没有与依赖服务的失效隔离开来,那么它将有可能因为依赖服务的失效而失效。
- Hystrix将货仓模式运用到了服务调用者上。为每一个依赖服务维护一个线程池(或者信号量),当线程池占满,该依赖服务将会立即拒绝服务而不是排队等待。
- 每个依赖服务都被隔离开来,Hystrix 会严格控制其对资源的占用,并在任何失效发生时,执行失败回退逻辑。
Hystrix实现原理-观察者模式
- Hystrix通过观察者模式对服务进行状态监听。
每个任务都包含有一个对应的Metrics,所有Metrics都由一个ConcurrentHashMap来进行维护,Key是CommandKey.name()
在任务的不同阶段会往Metrics中写入不同的信息,Metrics会对统计到的历史信息进行统计汇总,供熔断器以及Dashboard监控时使用。
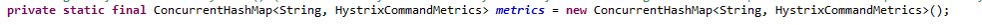
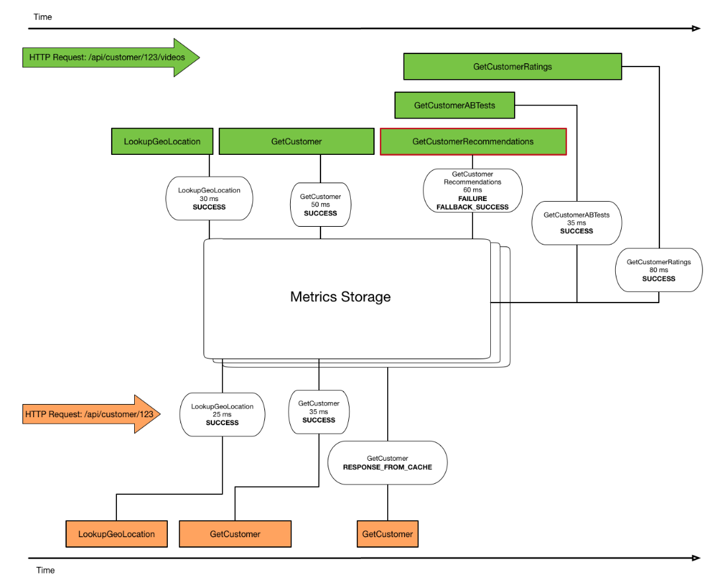
Metrics
- Metrics内部又包含了许多内部用来管理各种状态的类,所有的状态都是由这些类管理的
各种状态的内部也是用ConcurrentHashMap来进行维护的
如:HealthCountsStream是用来统计任务失败率的一个类
而每个状态管理类内部又包含了各自的真实转态信息
如HealthCountsStream保存的信息的一部分如下:
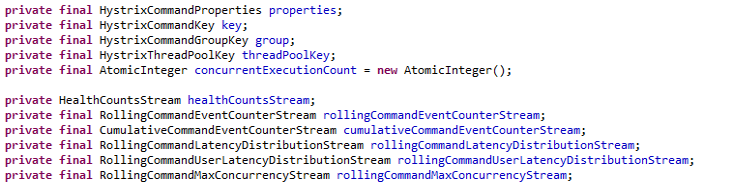


Metrics如何统计
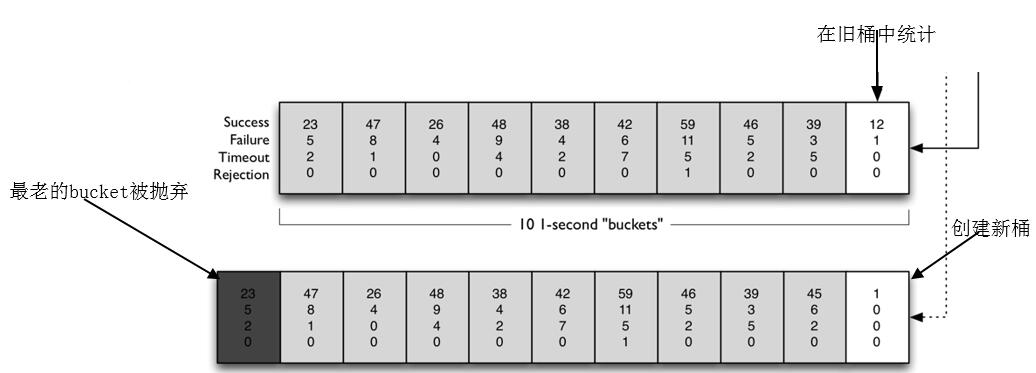
Metrics在统计各种状态时,时运用滑动窗口思想进行统计的,在一个滑动窗口时间中又划分了若干个Bucket(滑动窗口时间与Bucket成整数倍关系),滑动窗口的移动是以Bucket为单位进行滑动的。
如:HealthCounts 记录的是一个Buckets的监控状态,Buckets为一个滑动窗口的一小部分,如果一个滑动窗口时间为 t ,Bucket数量为 n,那么每t/n秒将新建一个HealthCounts对象。
Hystrix实现原理-熔断机制
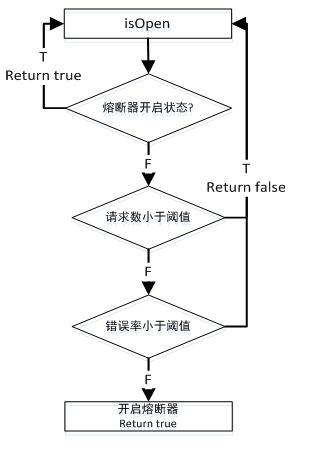
- 熔断是参考电路而产生的一种保护性机制,即系统中如果存在某个服务失败率过高时,将开启熔断器,对于后续的调用,不在继续请求服务,而是进行Fallback操作。
熔断所依靠的数据即是Metrics中的HealthCount所统计的错误率。
一个命令的调用过程如图所示:
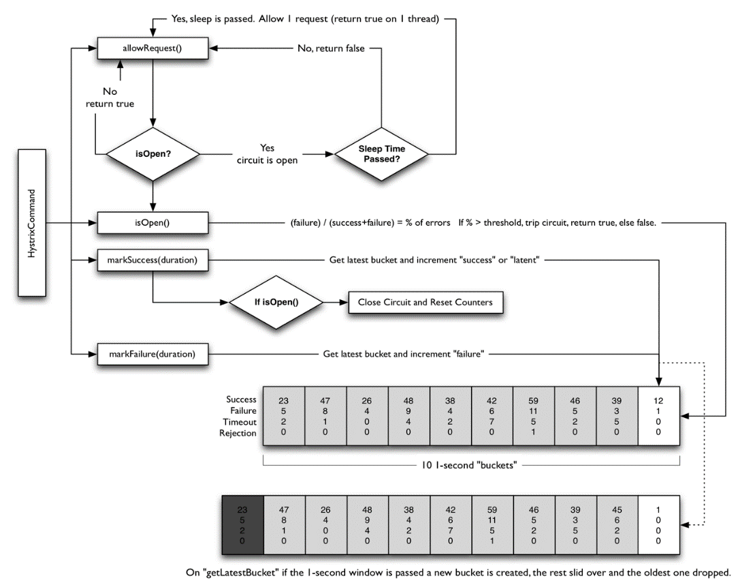
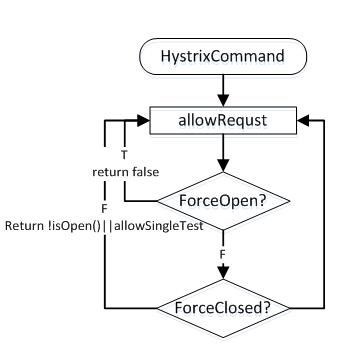
熔断器的判断流程:
1.一个命令执行前会先运行allowRequest()函数。
allowRequest()函数内部为:
- 先查看熔断器是否强制开启(ForceOpen()),如果开启则拒绝
- 再查看熔断器是否强制关闭(ForceClosed()),如果强制关闭则允许Request,否则进一步判断
- 先做isOpen(),判断熔断器是否开启,如果开启则拒绝访问,如果开启则进一步判断
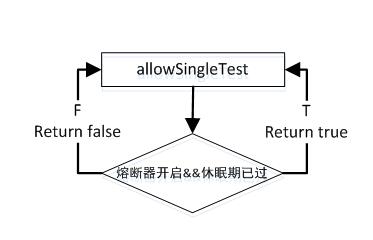
- 再做allowSingleTest(),熔断器休眠期过后,允许且只允许一个请求,如果这个请求正确执行,则熔断器关闭,如果执行失败,则熔断器再次开启,进入新的熔断周期。
如何判断超时
在运行对应的command时,Hystrix会注册一个Timer到一个定时线程池中,当超时后会启用一个HystrixTimer线程来终止的执行。


线程池的管理是用ThreadPoolExecutor来实现的,当线程池和阻塞队列都满后会抛出RejectedExecutionException,捕获该异常并进行相应状态的处理。

Note:除此之外由程序错误导致的异常,断路器打开都可以导致任务失败进入Fallback
失败降级
Hystrix提供了失败降级策略,当命令执行失败时,Hystrix 将会执行失败回退逻辑。失败回退逻辑包含了通用的回应信息,这些回应从内存缓存中或者其他固定逻辑中得到,而不应有任何的网络依赖。
如果一定要在失败回退逻辑中包含网络请求,必须将这些网络请求包装在另一个 HystrixCommand 或 HystrixObservableCommand 中。
失败降级也有频率限时,如果同一fallback短时间请求过大,则会抛出拒绝异常。
缓存机制
除了第一次请求需要真正访问依赖服务以外,后续请求全部从缓存中获取,可以保证在同一个用户请求内,不会出现依赖服务返回不同的回应的情况,且避免了不必要的线程执行。
缓存在命令内部,且有一个ConcurrentHashMap进行管理

使用缓存需要重写父类的getCacheKey方法
配置
Command
设置隔离策略
execution.isolation.strategy = THREAD
设置超时时间
execution.isolation.thread.timeoutInMilliseconds = 1000
信号量隔离策略设置最大并发请求数(仅在信号量隔离策略下生效)
execution.isolation.semaphore.maxConcurrentRequests = 10
设置最大Fallback数量
fallback.isolation.semaphore.maxConcurrentRequests = 10
设置熔断器滑动窗口最小任务
circuitBreaker.requestVolumeThreshold = 20
设置熔断器持续时间
circuitBreaker.sleepWindowInMilliseconds = 5000
设置触发熔断器的失败任务阈值(百分比)
circuitBreaker.errorThresholdPercentage = 50
设置Metrics监视器的范围时间(过去多少ms内)
metrics.rollingStats.timeInMilliseconds = 10000
设置监视器内桶的数量(将监视器范围划分为若干块)
metrics.rollingStats.numBuckets= 10
ThreadPool
设置线程池容量
coreSize = 10
设置阻塞队列长度(优先级高于queueSizeRejectionThreshold,且一旦初始化就不能更改 )
maxQueueSize = -1
动态设置阻塞队列长度
queueSizeRejectionThreshold = 5
空闲线程存活时间
keepAliveTimeMinutes= 1
线程池监控窗口时间范围(10s内)
metrics.rollingStats.timeInMilliseconds = 10000
设置线程池监控滑动窗口的桶数量
metrics.rollingStats.numBuckets = 500
Note:窗口时间必须为桶数量的整数倍,否则会抛出异常
Dashboard
1.Hystrix 自带了一个dashboard,用来监控熔断信息.
2.Dashboard可以监测哪些数据?
3.使用turbine可以监控集群.

使用Turbine聚合的服务器集群

遇到问题
压测过不了,提高阻塞队列和线程池无效,增加fallback容量解决。
fallback.isolation.semaphore.maxConcurrentRequests = 100















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









