






目录
1 概述
缓存是什么?
维基词典将缓存定义为未来需要的、可快速检索的内容的存储。缓存是临时数据的集合,这些数据要么是位于其他地方的数据的副本,要么是计算的结果。缓存中已有的数据可以重复访问,且时间和资源成本极低。
为什么需要缓存?
- 减少重复计算
- 提升服务吞吐
- 降低底层数据系统负载
有哪些常见缓存方案?
- 分布式 (Memcache/Redis/Tair)
- 本地 (纯内存/内存+磁盘)
一些相关术语和概念
- 缓存命中,即对于给定key,从缓存中能取到合法数据条目,衡量缓存是否高效的最重要指标就是缓存命中率;
- 热数据,对于大多数程序,数据访问往往都呈现2/8规则,总有少部分数据会被频繁访问,这部分数据成为热数据;
- 驱逐,缓存中能存放的元素数量总是有限的,当容量满时,新元素的加入意味着老元素需要被驱逐。驱逐策略很大程度上影响着缓存命中率,常见的策略有FIFO/LRU/LFU;
2 Guava Cache
Guava Cache的设计类似于ConcurrentHashMap,功能全面,使用简单。常见的使用场景是作为ConcurrentHashMap的替代品,即 当你需要一个支持淘汰能力的ConcurrentHashMap时,可以简单的使用Guava Cache来代替。
- 支持LRU的淘汰策略,但不支持自定义策略;
- 按元素插入时间或访问时间做淘汰;
- 指定最大容量;
- 移除事件监听;
- LoadingCache,即指定元素加载逻辑;
简单示例
Cache<String, Object> cache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(60, TimeUnit.SECONDS)
.build();
3 Caffeine
Caffeine可以被看做Guava的升级版,它实现了非常高性能的读写接口,且提供的W-TinyLFU淘汰算法可以带来更高的缓存命中率。Spring5 开始Caffeine代替了Guava作为默认Cache实现。
3.1 使用接口
在接口层面,Caffeine基本兼容了Guava的用法。
Cache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(60, TimeUnit.SECONDS)
.build();3.2 实现架构

3.3 关于性能
性能上,关键的设计是顺序访问队列、异步化读写,分层时间轮、代码生成等。具体见:Design zh CN · ben-manes/caffeine Wiki · GitHub
以下是Caffeine官方给出的,与ConcurrentHashMap/Guava Cache的性能对比。Caffeine的读写性能要远好于Guava,甚至超过不带缓存特性的ConcurrentHashMap。
读 (100%)
在这个基准测试中, 8 线程对一个配置了最大容量的缓存进行并发读。
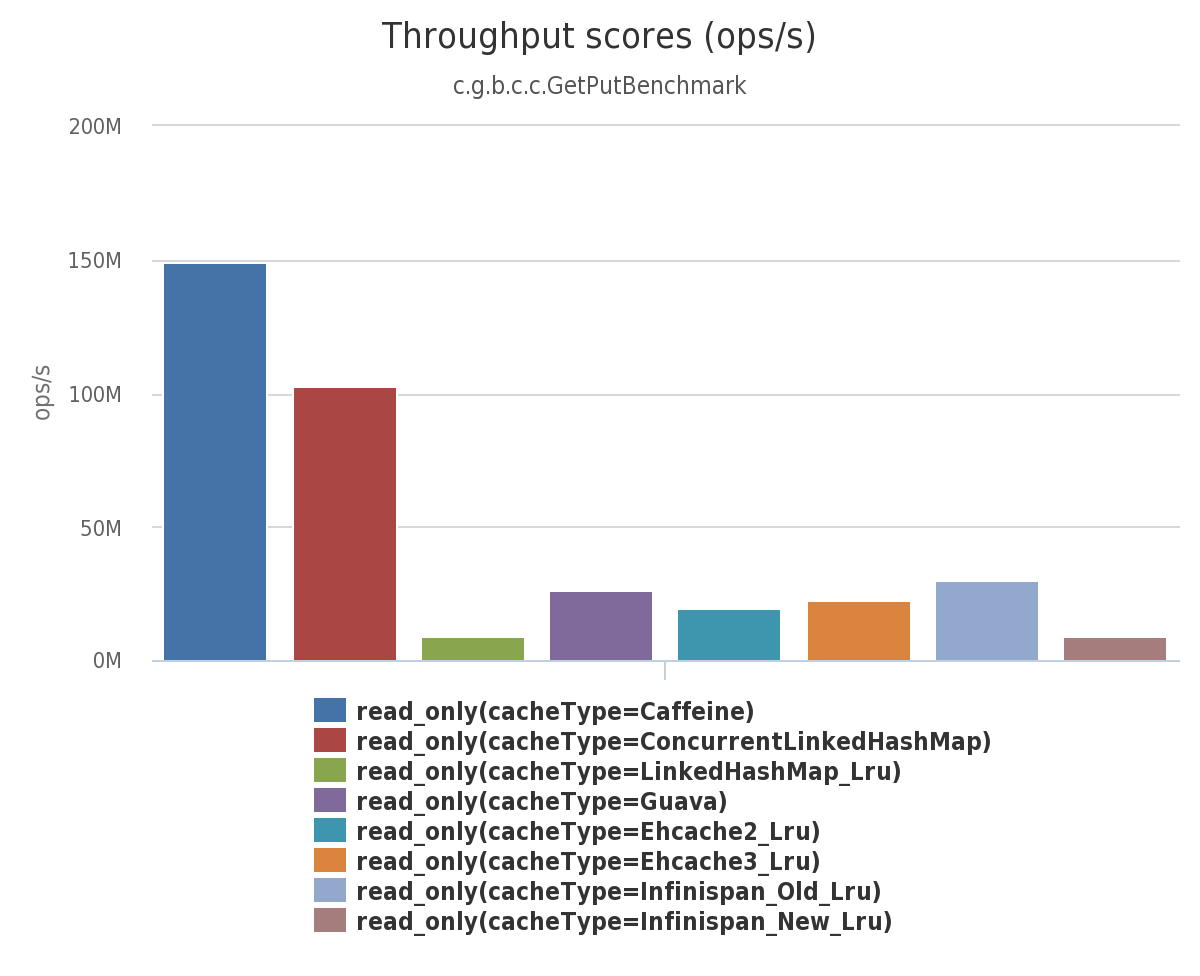
读 (75%) / 写 (25%)
在这个基准测试 中,对一个配置了最大容量的缓存,6 线程 进行并发读,2 线程进行并发写。

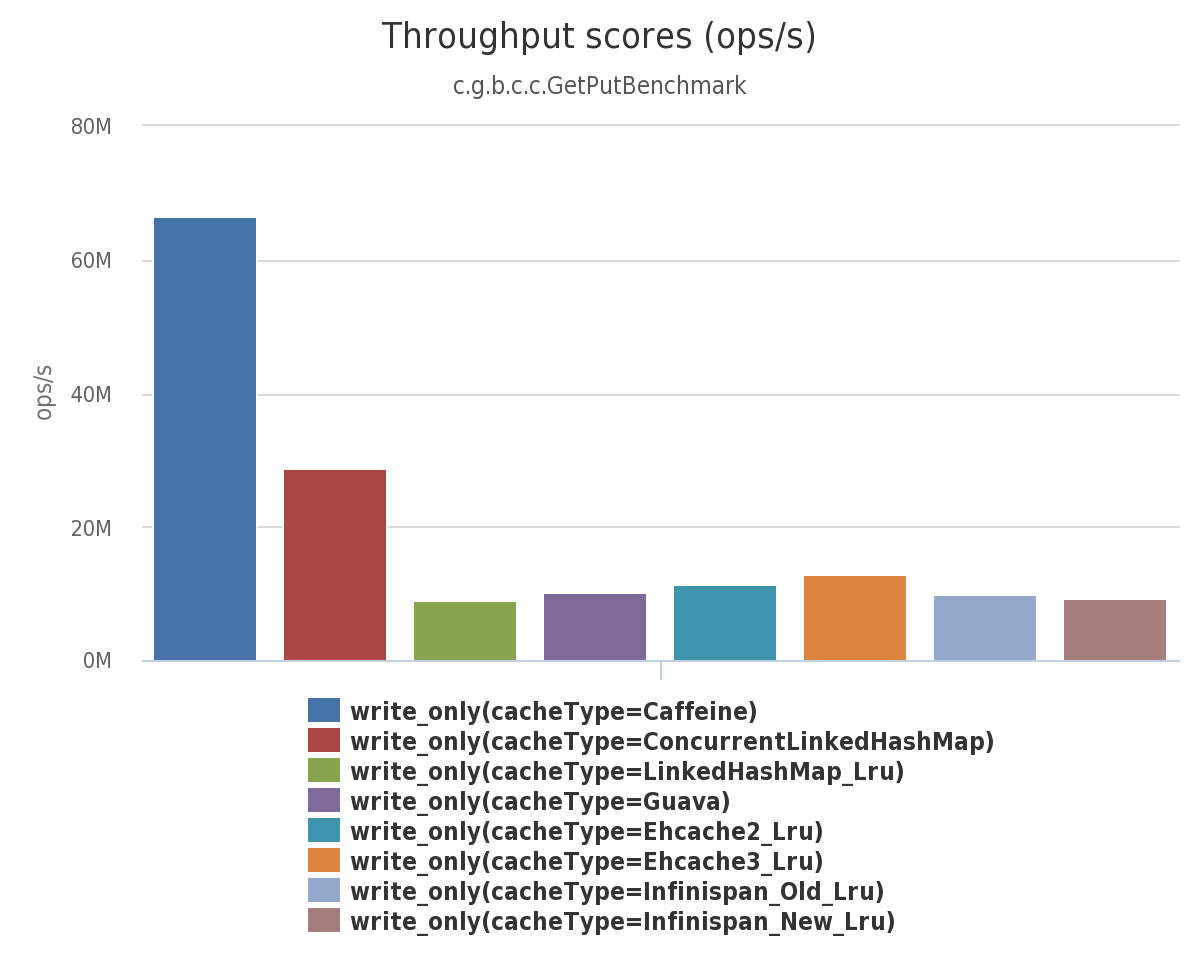
写 (100%)
在这个基准测试 中,8 线程对一个配置了最大容量的缓存进行并发写。
3.4 关于命中率
Caffeine 使用l Window TinyLfu策略因为其高命中率和更低的内存开销。W-TinyLFU是基于LFU演进的算法,解决了LFU无法处理历史高频数据可能占据缓存坑位的问题。
CountMin Sketch --减小计数器空间占用
CountMin Sketch使用了一个二维数组(实现上是个long一维数组)和多个hash函数,来近似的记录每个key的访问频率,思想类似布隆过滤器。

如图所示,当某个key被访问时,会根据预先定义的4个hash函数,找到数组中的四个位置,并更新其中的值。这4个值中的最小值,即被视为此key的访问频率。
之所以使用4个hash方法、并取最小值作为频率,是为了减少hash冲突导致某些实际访问频率低,但和某个热点key hash冲突 的key会被误当做热点key的情况。
保鲜机制
如果计数器中的记录的访问次数永远只增不减,会使得老数据永远被保留,而新的热点数据还没等到频率增加就被淘汰。TinyLFU采用的机制是,当CountMin Sketch中记录的频率总和大于缓存最大数量的10倍时,对整个Sketch中的所有值做重置。所谓重置,具体是对所有记录的频率除2。
TinyLFU

TinyLFU作为其他缓存(如LRU)的前置,当新数据进入缓存前,会使用其CountMin Sketch中记录的频率数据,和原有缓存中被淘汰的数据进行PK,胜利者写入缓存。
W-TinyLFU

W-TinyLFU在TinyLFU的基础上,增加了前置的Window Cache,目的是解决突发性热点数据的保留问题。Window Cache本身基于LRU,新数据首先会写入它,LRU的结构使得哪怕是新出现的热点数据,也不会被淘汰。另外一方面,Window Cache的初始大小仅为总缓存大小的1%,也不破坏整体的LFU设计。
从Window cache淘汰的数据,会再进入到TinyLFU中进行判断,和从MainCache淘汰下来的数据进行PK,胜利者写回MainCache,失败者则被彻底淘汰。
MainCache,还分为Probation segment和protected segment,设计类似JVM的新生代和老年代,新数据会被首先写入Probation segment,当Probation segment的数据被再次访问时,会被移到protected segment中。
4 Ehcache
Ehcache 是一个开源的、基于标准的,健壮、可靠、快速、简单、轻量级的java分布式缓存,支持与其他框架的集成,是Hibernate默认的CacheProvider。同时也实现了JSR107的规范,是Jcache的一种实现。
不同于Guava和Caffeine的纯内存设计,Ehcache支持多种介质:堆、堆外、磁盘、分布式,且支持多层组合。

4.1 简单示例
// CacheManager
CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.with(CacheManagerBuilder.persistence(new File(getPath())))
.build();
cacheManager.init();
// ResourcePools
ResourcePools resourcePools = ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(5000, EntryUnit.ENTRIES)
.offheap(40, MemoryUnit.MB)
.disk(10, MemoryUnit.GB)
.build();
CacheConfiguration<String, Object> cacheConfiguration = CacheConfigurationBuilder.newCacheConfigurationBuilder(String.class, Object.class, resourcePools)
.withExpiry(ExpiryPolicyBuilder.timeToLiveExpiration(Duration.ofHours(1)))
.build();
// 创建Cache
Ehcache<String, Object> myCache = (Ehcache<String, Object>) cacheManager.createCache(physicalTblName, cacheConfiguration);
4.2 读写链路


多层架构下,put时,数据首先写入权威层(即磁盘),并且将其他层的缓存值失效;get时,会从上而下依次尝试取数,直到下降至权威层,从下层取到数据后,再将数据放入上层。
由于每次put都会访问磁盘,设计一个高效的序列化器是比较重要的,否则性能会比较差。
5 对比总结
| Guava Cache | Caffeine | Ehcache | |
| 读写性能 | 一般 | 很好 | 好 |
| 命中率 | 中 | 高 | 中 |
| 驱逐策略 | LRU | W-TinyLFU | LRU/LFU/FIFO |
| 分布式 | 不支持 | 不支持 | 支持 |
| 磁盘 | 不支持 | 不支持 | 支持 |
| 易用性 | 好 | 好 | 较好 |
参考
Home zh CN · ben-manes/caffeine Wiki · GitHub















 2503
2503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









