







bugs或者异常?基于序列挖掘的无线传感网程序调试技术。
论文提出了一种基于序列挖掘的WSNs调试技术(迭代式),这个技术命名为vPST-SVM,很显然这个调试技术实现的话是基于两个理论模型
1、一个是vPST,矢量化概率后缀树,要了解vPST就设计到解决简单模式匹配技术的后缀字典树、然后解决后缀字典树深度以及存储空间问题衍生出的后缀树,然后为后缀树结点添加搜索概率形成概率后缀树,最后对概率后缀树矢量化形成矢量化概率后缀树。vPST的作用是从传感网程序运行流中有效地提取和存储序列化信息,并以简单的矢量化的后缀树这一数据结构的形式表示该序列化信息。
2、另一个模型是SVM,支持向量机,支持向量机是一种分类算法,将WSN程序的执行流分成两类,一类是程序的正常执行行为,另一类的话是可能含有bug的异常程序执行行为,它有一个离群值作为异常程序执行行为的检测指标,离群值越大表示含有bug的可能性越高。
论文的贡献:
1、将PST模型扩展成vPST,vPST数据结构提取和存储的程序执行刘序列信息更有利如SVN分类算法;
2、提出了vPST-SVM调试技术,又利于发现传感网程序中的瞬态bug。
论文参考
1、Dustminer + Sentomist
Abstract
- 传感网程序由于它的分布式结构、高并发、资源有限等这些特点,很容易出现bug。
- 论文提出了一种基于序列挖掘的WSNs调试技术(迭代式)。实现步骤为:
1、首先,论文了设计了一种数据结构:vPST,矢量化概率后缀树,它能从传感网程序运行流中有效地提取和存储序列化信息,并以简单的矢量化的后缀树这一数据结构的形式表示该序列化信息。
2、之后,通过对vPST和SVM的集成(支持向量机:对于线性和非线性数据分类的一种健壮和通用的分类算法)构建了一种新的传感网调试技术:vPST-SVM。
3、验证vPST-SVM调试技术的有效性、灵活性和通用性(2 LiteOS + 1 TinyOS)
一、Introduction
- 由于传感网分布式结构、高并发性和资源有限这些特点,传感网程序会有很多bug。而且这些bug调试起来也很困难:上下文相关 + 事件驱动 + 事件触发 + 瞬态错误 + 不可再现性。
论文提出了一种灵活和通用的调试技术,这种调试技术基于序列化数据分析和异常检测技术。这一调试技术基于两种理论方法:矢量化概率后缀树模型和支持向量机模型。
1、原始的PST模型是一个的概率模型,它能从传感网程序运行流中有效地提取和存储序列化信息,并以简单的后缀树这一数据结构的形式表示该序列化信息。
2、SVM是对于线性和非线性数据的一种健壮和通用的分类算法。
3、将PST扩展成vPST,将程序运行流的序列化信息以矢量化的数据结构表示出来更有利于SVM的分类。论文贡献:
1、将PST模型扩展成了vPST
2、提出了vPST-SVM检测技术
二、相关工作
传感网程序中的比较复杂的bug,譬如说由数据竞争,或者不正确的并发控制导致的bug。
基于数据挖掘技术的WSNs程序的bug检测工具:
1. 基于高频模式挖掘技术的Dustminer;
2. Sentomist
三、vPST-SVM异常检测技术
矢量概率后缀树(vPST)
1. 用传统的PST模型采用数理统计的的方法来分析不同的PST序列的子序列来计算源序列的相似度是不准确的。
2. 论文提出了扩展的PST:vPST。
1、相关概念介绍:模式匹配 + 后缀字典树 + 后缀树 + 概率后缀树 + 矢量化概率后缀树
2、vPST的构造:以指定的深度构造好PST后,通过连接每一个节点的概率矢量形成vPST。
3. vPST的优点:
1、跟PST一样都能保存好子序列信息和完整的序列信息,而且数据结构更简单;
2、SVM分析矢量后缀树比分析后缀树更简单;
3、分析子序列的相似性同时也会分析完整序列的相似性;
vPST-SVM迭代调试技术
- vPST-SVM:在vPST上集成了SVM,vPST-SVM的调试过程如下:
1、从可能含有错误的程序的收集WSNs的程序运行流;
2、从收集的程序运行流序列中构造PST数据结构;
3、矢量化PST,构造成vPST数据结构;
4、在vPST基础上应用SVM计算的异常指数,获取异常指数最高的序列;
5、检测异常指数最高的序列是否含有bug;
6、修复异常,返回执行步骤1;
7、没有检测到bug,则停止; - vPST深度的选择问题:
1、vPST的深度是一个很重要的参数,为了有效检测bug,这个参数要求能自适应调整;
2、对于复杂bug增加深度;简单bug则减少深度;(计算规模会随着深度增加而指数增长)
3、合理的调试深度:不大于5 - 迭代的复杂性:
System design and implementation
- 要检查的程序:程序员根据经验判断出很容易出错的代码块(称之为热点);
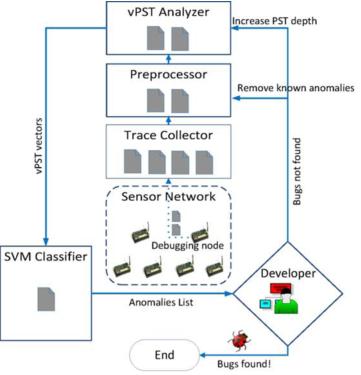
- vPST-SVM调试器的组成结构:程序运行流控制器(前端) + 预处理器 + vPST分析器 + SVM分类器(这三个处于后端)
1、程序运行流控制器:负责生成和收集热点程序的程序执行流;
2、预处理器:过滤噪音和其它干扰数据、压缩原始数据操作;减少数据维度;
3、 vPST分析器:遍历所有手机的程序运行流和从中提取序列特征。
4、SVM分类器:对程序执行流的vPST进行分类得到最可能含有程序bug的片段; - 各个组件的具体实现:
1、程序流控制器:在LiteOS和TinyOS传感网操作系统上构建了轻量级的程序执行流子系统
2、vPST分析器 :c++实现的PST的构造 + vPST的实现
3、SVM:SVM系统库。
五、CASE STUDIES
1、案例一:LiteOS程序的变量溢出bug
场景描述:
1、多个LiteOS发送节点向一个接收节点发送数据包;
2、接收节点成功接收到数据之后,向发送节点返回一个ACK确认号。接收节点收到ACK确认号后才发送新的数据包;否则从新发送原数据。
3、发送方会重复发送相同的数据包;而接收方则会把相同数据包丢弃掉。实现代码:
/* sender node */
while(1)
{...
if(AckReceived && !MsgSent) {
...
lib_radio_send_msg(...);
}else if(!AckReceived && MsgSent) {
lib_radio_receive_timed( ... );
// Bug #1
PacketID=256*Buffer[I]+Buffer[0];
}
}
}- bug触发:
代码PacketID=256*Buffer[1]+Buffer[0]中,PacketID和数组Buffer是16位,而常亮256为8位。因此在计算256*Buffer[1]时是16位与8位的混合数据计算。当Buffer[1]变成3或者更大数的时候,会发生变量溢出,PacketID值不会超过512,因此接收方会误认为该数据包是已经接收到的数据包而丢弃。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









