










###线性回归
1.什么是线性回归?
线性回归是用来确定两种变量之间的依赖关系,表达式为:
- 单变量线性回归:
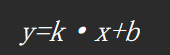
- 多变量线性回归:
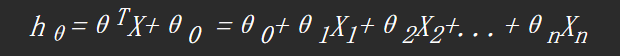
- 多项式回归
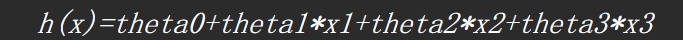
这里我们在数据集里以波士顿房价作为举例
数据集共有506个样本,13个属性
2.数据集的导入:
做线性回归之前一般先对数据进行导入以及预处理!!!
from sklearn.linear_model import LinearRegression #导入线性回归
"""导入数据分割"""
from sklearn.model_selection import train_test_split
小提琴图

小提琴图中间的黑色粗条用来显示四分位数。黑色粗条中间的白点表示中 位数,粗条的顶边和底边分别表示上四分位数和下四分位数,通过边的位置所对应的y轴的数值就可以看到四分位数的值。 由黑色粗条延伸出的黑细线表示95%的置信区间。
2.概率密度信息
从小提琴图的外形可以看到任意位置的数据密度,实际上就是旋转了90度的密度图。 小提琴图越宽,表示密度越大。 可以展示出数据的多个峰值。
记录于:
2021.11.02.20:40
reshape函数
reshape函数用于数组的转换,一般的使用方法是arrange(n).reshape(a,b)
这里arrange函数为生成数组的函数。比如np.arrange(100)就是生成0到99的数组,
他的用法和那个range里的很相似,但是有所区别,range使用也是range(start,end,步长),
但是呢,range是返回一个list对象,而不是返回一个数组,因此用了numpy库的话,arrange()
使用就最合适不过了!以下举例大家看一下 :
import numpy as np
A=np.arange(1,100,0.6)
print(A)
结果
[ 1. 1.6 2.2 2.8 3.4 4. 4.6 5.2 5.8 6.4 7. 7.6 8.2 8.8
9.4 10. 10.6 11.2 11.8 12.4 13. 13.6 14.2 14.8 15.4 16. 16.6 17.2
17.8 18.4 19. 19.6 20.2 20.8 21.4 22. 22.6 23.2 23.8 24.4 25. 25.6
26.2 26.8 27.4 28. 28.6 29.2 29.8 30.4 31. 31.6 32.2 32.8 33.4 34.
34.6 35.2 35.8 36.4 37. 37.6 38.2 38.8 39.4 40. 40.6 41.2 41.8 42.4
43. 43.6 44.2 44.8 45.4 46. 46.6 47.2 47.8 48.4 49. 49.6 50.2 50.8
51.4 52. 52.6 53.2 53.8 54.4 55. 55.6 56.2 56.8 57.4 58. 58.6 59.2
59.8 60.4 61. 61.6 62.2 62.8 63.4 64. 64.6 65.2 65.8 66.4 67. 67.6
68.2 68.8 69.4 70. 70.6 71.2 71.8 72.4 73. 73.6 74.2 74.8 75.4 76.
76.6 77.2 77.8 78.4 79. 79.6 80.2 80.8 81.4 82. 82.6 83.2 83.8 84.4
85. 85.6 86.2 86.8 87.4 88. 88.6 89.2 89.8 90.4 91. 91.6 92.2 92.8
93.4 94. 94.6 95.2 95.8 96.4 97. 97.6 98.2 98.8 99.4]
import sklearn.model_selection import train_test_split
这一句话导入train_test_split的包,这是数据分割的一个包
1.有什么用呢?
数据分割可以对数据进行任意分割,在以后我们研究大数据时候,当我们建立一个模型去使用时候,
数据就需要进行测试模型的准确度,为了体现整体数据都要适合此模型,数据就需要随机进行验证,比如100个数据,我们每次
分别抽取80个随机数据作为训练集,另外20个进行验证集,那么数据分割就很有用!
具体我们来看一下有什么用?
# 首先生成一个1~20以内的两列数据矩阵
import numpy as np
A=np.arange(1,21).reshape(-1,2)
结果
[[ 1 2]
[ 3 4]
[ 5 6]
[ 7 8]
[ 9 10]
[11 12]
[13 14]
[15 16]
[17 18]
[19 20]]
# //好嘞,对数据进行分割:
import numpy as np
A=np.arange(1,21).reshape(-1,2)
B=np.arange(21,41).reshape(-1,2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(A, B, test_size=0.25, random_state=0)
print(x_train)
print(x_test)
print(y_train)
print(y_test)
结果

注意:
test_size:0.25 分割比例random_tate=0设置随机状态
3.建立线性模型,训练数据,产生训练参数
from sklearn.linear_model import LinearRegression
import numpy as np
A=np.arange(1,21).reshape(-1,2)
B=np.arange(21,41).reshape(-1,2)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(A, B, test_size=0.25, random_state=0)
# 建立线性回归模型
lr=LinearRegression()
lr.fit(x_train,y_train)
y_hat = lr.predict(x_test)
print('参数:',lr.coef_)
# print('截距:',lr.intercept_)
print('实际值:',y_test[:2])
print('测试值:',y_hat[:2])
print('训练值R^2:',lr.score(x_train, y_train))
print('测试值R^2:',lr.score(x_test, y_test))















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









