






看过一些视频,与自己买过的书对照发现内容并不一致,于是产生了疑惑。我们不妨先来看看一张来自视频的截图:

里边提到,当SQL使用覆盖索引时,不支持ICP。然而在书《MySQL是怎样运行的》中第120页提到提示框中提到索引下推的含义。如果说覆盖索引指的是查询语句中的搜索列和条件列都被二级索引覆盖即可,不考虑查询语句本身是否遵循最左前缀法则,那么:
覆盖索引理应该使用到了ICP。
我们事先准备一张表:text
text里面存放了大量的虚拟数据,格式统一
我们先来看看这种text表长啥样:
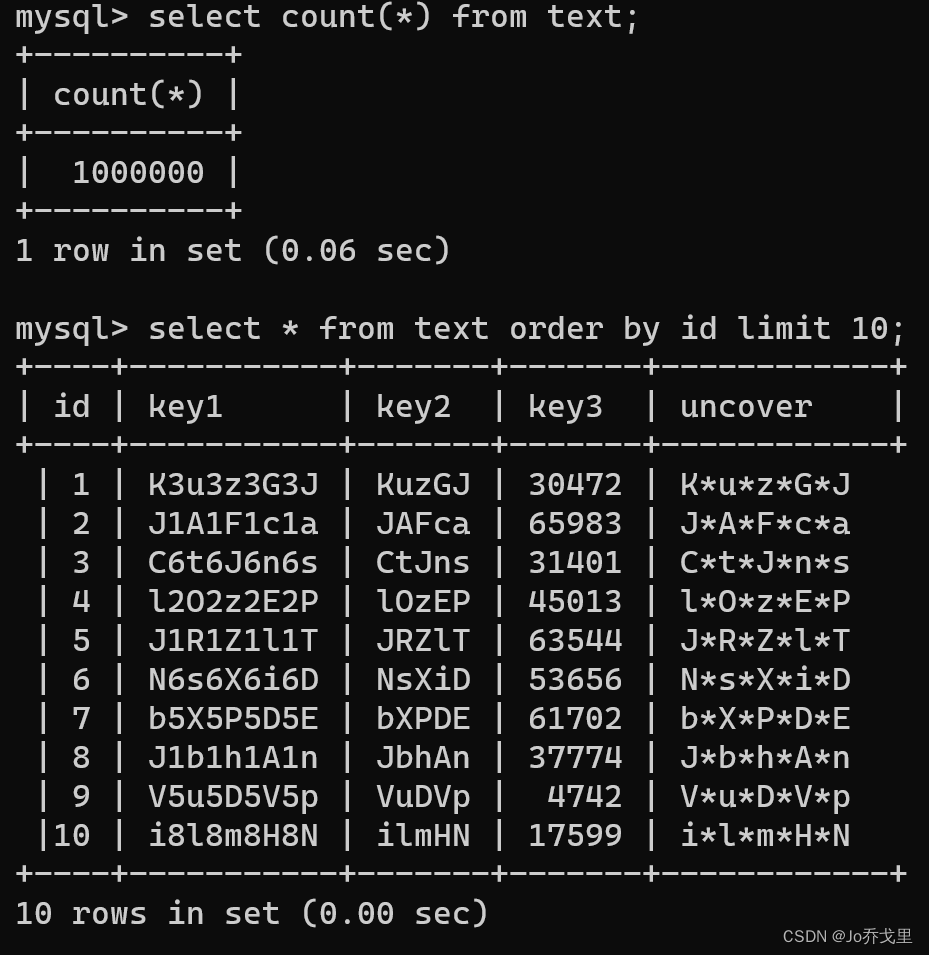
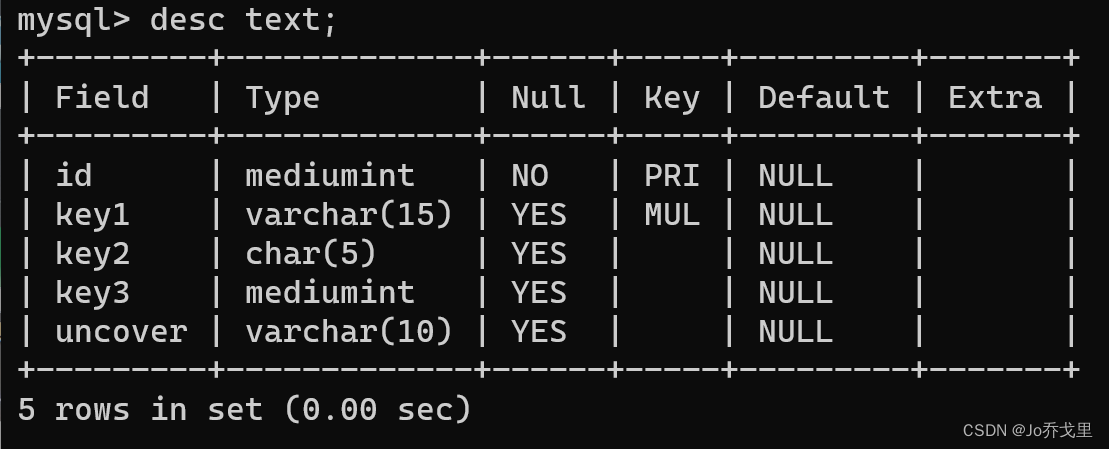
我们为key1,key2,key3列建立了联合索引,特别让uncover列没有被联合索引覆盖
我们先来看看执行计划,对于使用覆盖索引的查询语句,是否认定为ICP:

注意到Extra列中并未提示使用ICP(没有Using index condition的提示) 。这是否意味着,覆盖索引就是没用到ICP?
我们不妨从效率的角度进行比较
ICP的开关:
set optimizer_switch = 'index_condition_pushdown=on/off'
我们先来将此开关关闭:

再执行这样一条使用覆盖索引的查询语句;
为避免缓冲池的影响,特地执行三次

确定使用了联合索引 ,搜索时间平均约为0.375s
我们将刚才的开关打开:

同样执行上述的查询语句三次:

确定使用了联合索引,搜索时间明显缩短,平均为0.357秒
如果将数据量进一步扩大,这种差距只会更明显,可见覆盖索引【好吧,这里其实是我认定的覆盖索引】也是使用到了ICP的,但并不被执行计划认定为使用了ICP
我们将上述查询语句的搜索列换成*,即将uncover列加上,此时就会发现:

Extra列显示用到了ICP!
经过简单的推理,不难得到执行计划认为的ICP是:
该查询语句使用ICP可能减少回表,但是不能避免回表。覆盖索引使用ICP避免了回表,因此不被执行计划认定为ICP!
那么,使用ICP是不是只有好处呢?我们翻阅资料发现并非如此!
我们来看一份资料: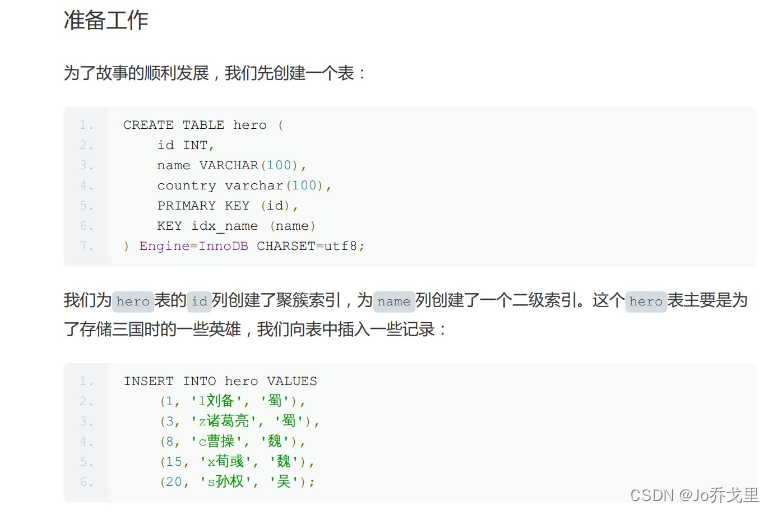

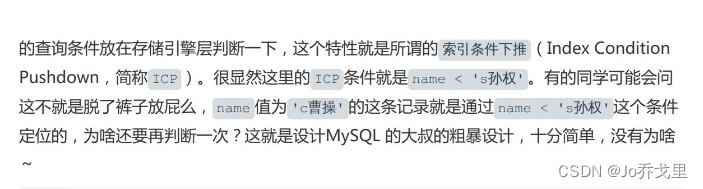
关键看最后一部分内容,我们大概能理解ICP的执行原理。原来,没有ICP时,server层让存储引擎每判断完一个name值满足条件的记录后,就直接回表;但有了ICP,存储引擎就要好好‘反思’一下搜索列中有没有漏网之鱼,可以直接在二级索引中判断完再回表。结果!反而又多判断一次name列的值是否满足条件!
为了验证这个结论,我们执行如下两条查询语句:
结论我就直接给出来了,感兴趣可以自己去实验

到此,关于ICP的理解就到此结束,特别送上我的总结:

🤪🤪多多的点赞,冲冲冲!















 1322
1322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









