







推荐阅读:https://mp.weixin.qq.com/s/PZB8eVuem5CfEc29g86_-Q
冒泡排序
冒泡排序要对一个列表多次重复遍历。它要比较相邻的两项,并且交换顺序排错的项。每对 列表实行一次遍历,就有一个最大项排在了正确的位置。大体上讲,列表的每一个数据项都会在 其相应的位置 “冒泡”。如果列表有 n 项,第一次遍历就要比较 n-1 对数据。需要注意,一旦列表中最大(按照规定的原则定义大小)的数据是所比较的数据对中的一个,它就会沿着列表一直后移,直到这次遍历结束。
# 冒泡排序
def bubbleSort(arr):
'''for n in range(len(arr)):
for i in range(0,len(arr)-n-1): # 注意len()-n-1, -1,因为会取到i+1'''
for k in range(len(arr)-1, 0, -1):
isSorted = True
for i in range(0, k):
if arr[i+1] < arr[i]:
arr[i] , arr[i+1] = arr[i+1], arr[i]
isSorted = False
if isSorted:
break
return arr
如果冒泡排序一次遍历后没有交换元素,说明已经是有序的了,最优时间复杂度为O(n)
选择排序
选择排序的思路是这样的:首先,找到数组中最小的元素,拎出来,将它和数组的第一个元素交换位置,第二步,在剩下的元素中继续寻找最小的元素,拎出来,和数组的第二个元素交换位置,如此循环,直到整个数组排序完成。
选择排序提高了冒泡排序的性能,它每遍历一次列表只交换一次数据,即进行一次遍历时找到最大的项,完成遍历后,再把它换到正确的位置。和冒泡排序一样,第一次遍历后,最大的数据项就已归位,第二次遍历使次大项归位。这个过程持续进行,一共需要 n-1 次遍历来排好 n 个数据,因为最后一个数据必须在第 n-1 次遍历之后才能归位。
# 选择排序
def selectionSort(arr):
for k in range(len(arr)-1,0,-1):
maxindex = 0
for i in range(0, k+1): # k+1,+1,+1,取到k
if arr[i] > arr[maxindex]:
maxindex = i
arr[maxindex], arr[k] = arr[k], arr[maxindex]
return arr
插入排序
插入排序总是保持一个位置靠前的 已排好的子表,然后每一个新的数据项被 “插入” 到前边的子表里,排好的子表增加一项。我们认为只含有一个数据项的列表是已经排好的。每排后面一个数据(从 1 开始到 n-1),这 个的数据会和已排好子表中的数据比较。比较时,我们把之前已经排好的列表中比这个数据大的移到它的右边。当子表数据小于当前数据,或者当前数据已经和子表的所有数据比较了时,就可以在此处插入当前数据项。
#插入排序
def InsertSort(arr):
for i in range(len(arr)):
currentValue = arr[i]
position = i # 记录插入位置
'''for j in range(i, -1, -1): # 从选定元素位置开始向前遍历到0为止, 这行代码在数列很大的时候,会不停的新建列表,这会损害性能
if j > 0 and arr[j-1] > currentValue: #当前元素不是第一个元素,且排好序的最后一个元素大于当前元素,则后移
arr[j] = arr[j-1] # 把大于选定值的数字向后移动
else:
position = j #记录插入位置,无论是中间break,还是顺序后移直到j=0,break
break'''
while position > 0 and arr[position-1] > currentValue: # 当子表数据小于当前数据,或者当前数据已经和子表的所有数据比较了时,就可以在此处插入当前数据项
arr[position] = arr[position-1] # 把之前已经排好的列表中比这个数据大的移到它的右边
position -= 1
arr[position] = currentValue
return arr
希尔排序
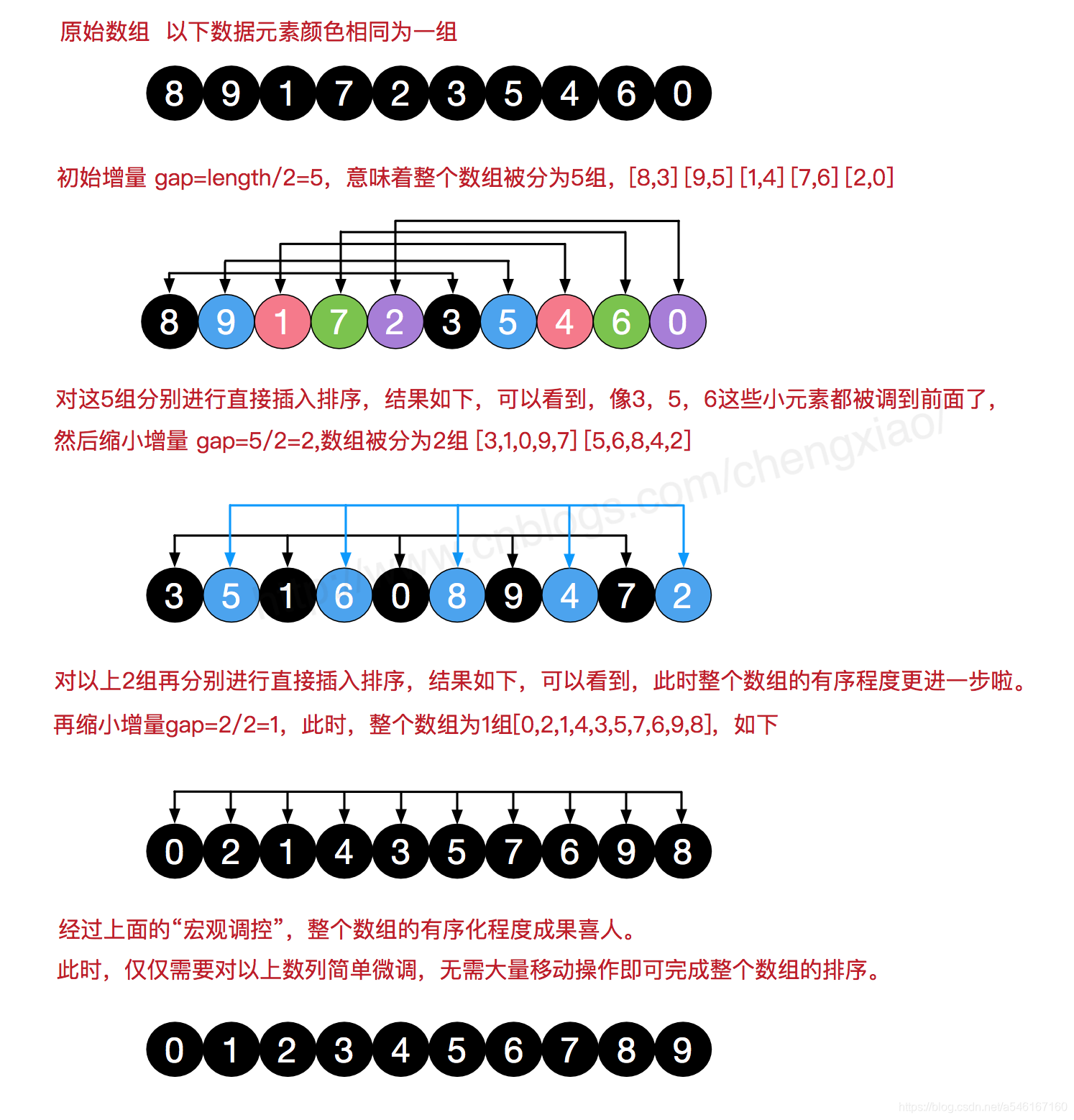
希尔排序确定一个划分列表的增量 “i”,这个i更准确地说,是划分的间隔。然后把每间隔为i的所有元素选出来组成子列表,然后对每个子序列进行插入排序,最后当 i=1 时,对整体进行一次直接插入排序。
# 希尔排序
def shellSort(arr):
n = len(arr)
gap = n//2 # ‘//’无论是否整除返回的都是 int ,而且是去尾整除
while gap > 0:
for i in range(gap): # gap为几就分成几组子序列
for j in range(i+gap, n, gap): # 对每个子序列插入排序
pos = j
currentValue = arr[j]
while(pos > i and currentValue < arr[pos-gap]):
arr[pos] = arr[pos-gap] # 插入排序,把之前已经排好的列表中比这个数据大的移到它的右边
pos -= gap # 以gap向前遍历
arr[pos] = currentValue
gap //= 2
return arr
归并排序
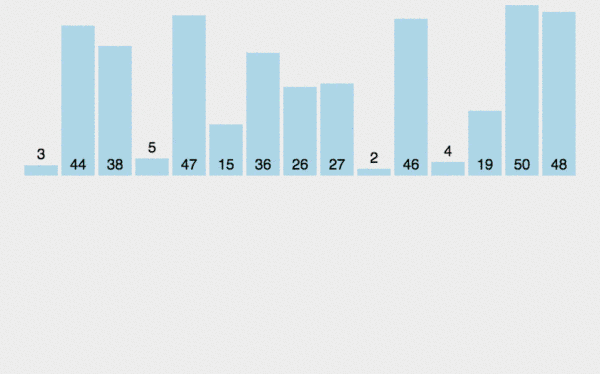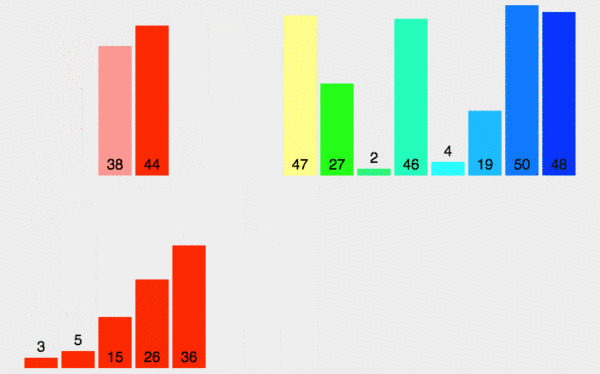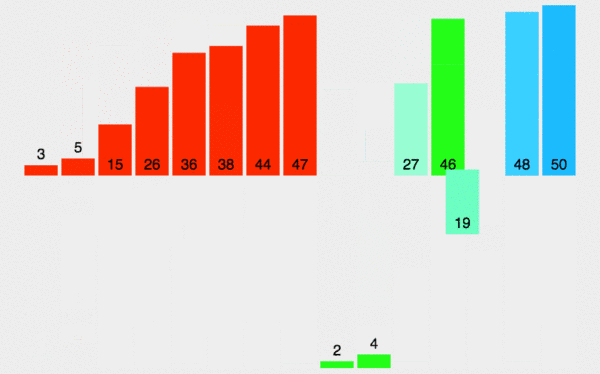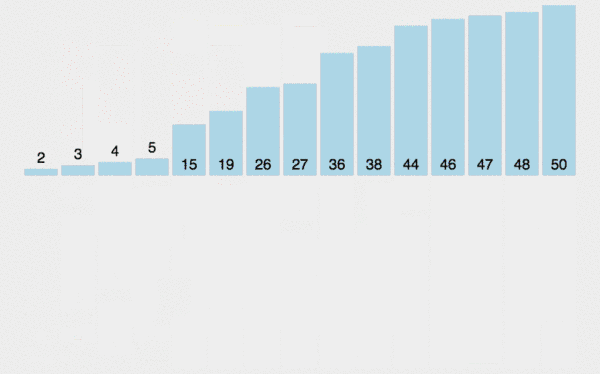
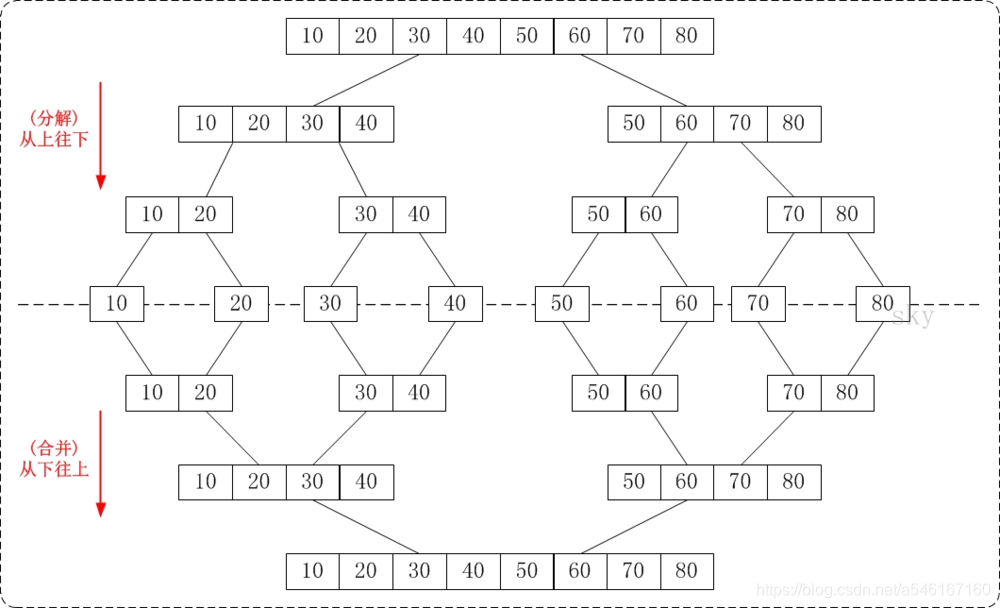
归并排序分治法,首先让数组中的每一个数单独成为长度为1的区间,然后两两一组有序合并,得到长度为2的有序区间,依次进行,直到合成整个区间。
- 递归实现,
-
如果给的数组只有一个元素的话,直接返回(也就是递归到最底层的一个情况)
-
把整个数组分为尽可能相等的两个子数组
-
对于两个子数组分别进行归并排序
-
把排好序的两个数组按大小组合成新的有序的序列
# 归并排序
def mergeSort(arr):
n = len(arr)
if n <= 1:
return arr
n = n//2
sub1 = mergeSort(arr[:n])
sub2 = mergeSort(arr[n:])
return merge(sub1, sub2)
# 合并两个有序数组
def merge(sub1, sub2):
n1 = len(sub1)
n2 = len(sub2)
i = 0
j = 0
merge = []
while i < n1 and j < n2:
if sub1[i] < sub2[j]:
merge.append(sub1[i])
i += 1
else:
merge.append(sub2[j])
j += 1
# 没复制完的
while i < n1:
merge.append(sub1[i])
i += 1
while j < n2:
merge.append(sub2[j])
j += 1
return merge
- 非递归实现
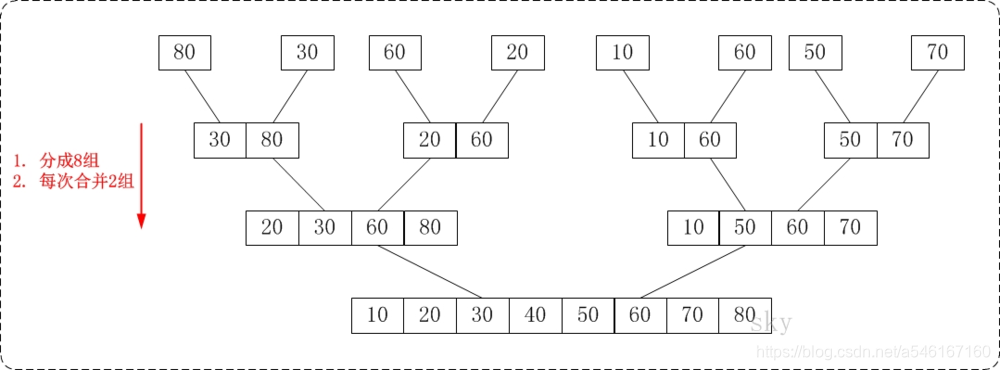
自底向上,从最小子问题开始一步一步解决,直到复杂的问题。
# 非递归的归并排序
def MergeSort(arr):
n = len(arr)
size = 1 # 表示每一步要归并的数组的长度
m = []
while size <= n:
for i in range(0, n-size, size+size):
m = merge(arr[i: i+size], arr[i+size: min(i+size+size, n)]) # min(i+size+size, n)为了最后一组数组可能不够全
arr[i: min(i+size+size, n)] = m[:] # 把merge得到的结果赋值给原始数组
size += size # 数组长度每次乘二
return arr
- 时间复杂度分析
- 总时间=分解时间+解决问题时间+合并时间。
- 分解时间就是把一个待排序序列分解成两序列,时间为一常数,时间复杂度o(1).
- 解决问题时间是两个递归式,把一个规模为n的问题分成两个规模分别为n/2的子问题,时间为2T(n/2).
- 合并时间复杂度为o(n)
- 总时间T(n) = 2T(n/2) + o(n).
- 归并排序每次会把当前的序列一分为二,然后两部分各自排好序之后再合并,可以用二叉树来理解,每一层的总计算量是O(n),总的层数是O(logn)的,所以总的复杂度是o(nlogn)。上面的递归式解出来也是o(nlogn)。
- 此外在最坏、最佳、平均情况下归并排序时间复杂度均为o(nlogn).从合并过程中可以看出合并排序稳定。
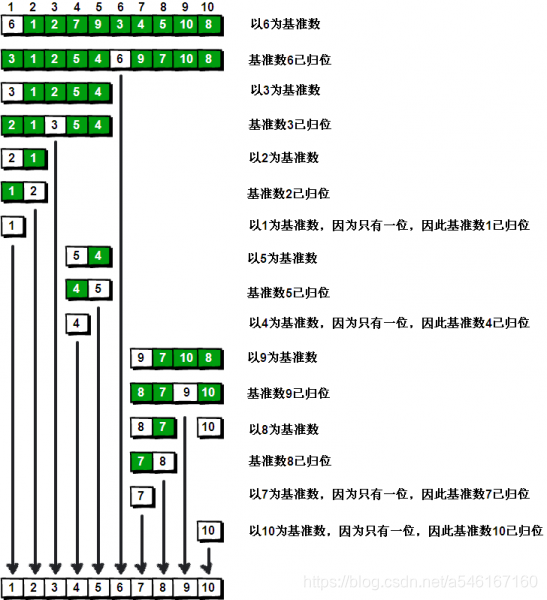
快速排序
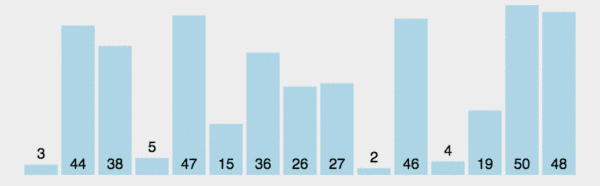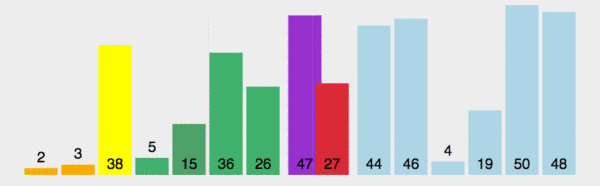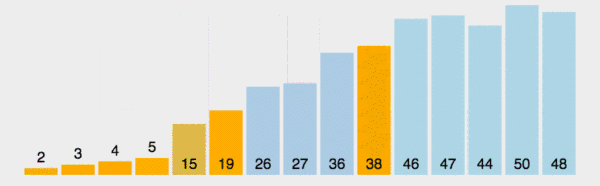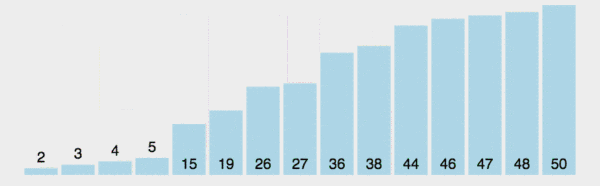
在数组中随机选一个数(默认数组首个元素),数组中小于等于此数的放在左边,大于此数的放在右边,再对数组两边递归调用快速排序,重复这个过程。
# 快速排序
def quickSort(arr):
return qsort(arr, 0, len(arr)-1)
def qsort(arr, left, right):
if left >= right: # 递归结束条件,当区间里只有一个元素时,不用排序直接返回
return
k = arr[left] # 基准数
i = left
j = right
while i != j:
while arr[j] > k and i < j: # 顺序很重要,要先从右边开始找(最后交换基准时换过去的数要保证比基准小,因为基准选取数组第一个数,在小数堆中) (保证和基准数交换的数小于基准数,因为交换后该数在左边。)
j -= 1
while arr[i] <= k and i < j:
i += 1
if i < j:
arr[i], arr[j] = arr[j], arr[i]
# 将基准数归位
arr[left], arr[i] = arr[i], arr[left]
qsort(arr, left, i-1) # 递归左边
qsort(arr, i+1, right) # 递归右边
return arr
堆排序

最大堆的定义:
- 最大堆中的最大元素值出现在根结点(堆顶)
- 堆中每个父节点的元素值都大于等于其孩子结点
先按数组元素顺序建立最大堆,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
- 二叉堆的最后一个非叶子节点的索引是len(arr) / 2 - 1
- 节点下标为 i, 左孩子则为2 * i + 1, 右孩子下标则为2 * i + 2
例子
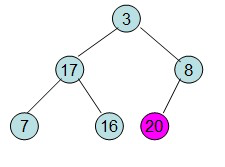
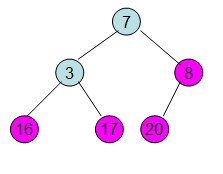
给定一个列表array=[16,7,3,20,17,8],对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到

然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:
第一步: 初始化大顶堆(从最后一个有子节点的节点开始往上调整最大堆)
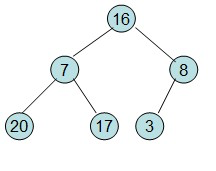
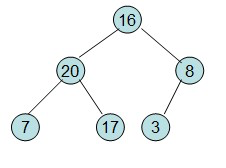
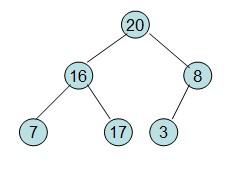
20和16交换后导致16不满足堆的性质,因此需重新调整
这样就得到了初始堆。
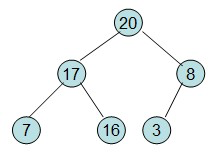
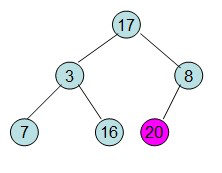
第二步: 堆顶元素R[0]与最后一个元素R[n-1]交换,交换后堆长度减一
即每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。有了初始堆之后就可以进行排序了。
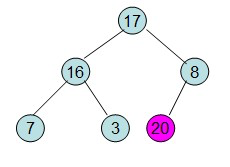
第三步: 重新调整堆。此时3位于堆顶不满堆的性质,则需调整继续调整( 从顶点开始往下调整)
重复上面的步骤:
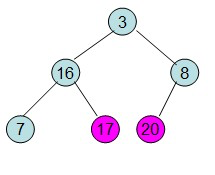

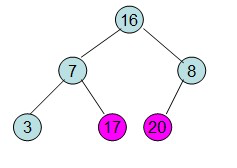
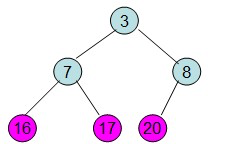
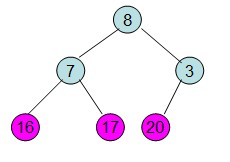
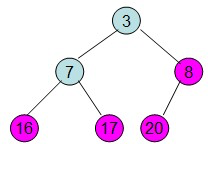

堆排序的过程
第一步: 初始化建立大顶堆, 从下往上建立,从最后一个非子节点开始往上调整; 起始节点索引值n/2-1 ~ 0,最后排序节点索引值n(n为数组总长度)
第二步: 依次交换堆顶和堆底, 并把交换后的堆底保留, 只排列剩余的堆, 从上往下建立; 起始节点索引值0,最后排序节点索引值n-1 ~ 0
不管是初始大顶堆的从下往上调整,还是堆顶堆尾元素交换,每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换,交换之后都可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整。在算法中是用一个while循环来实现的,只要小于最后排序节点索引值,则继续调整。
# 堆排序
def heapSort(arr):
# 初始建最大堆
makeHeap(arr,len(arr))
for i in range(len(arr)-1, -1, -1):
arr[i], arr[0] = arr[0], arr[i]
adjustDown(arr,0,i)
return arr
def makeHeap(arr,n): # n表示所有要排序的节点个数
for i in range(len(arr)//2-1, -1, -1): # i表示节点的索引号,从最后一个非叶子节点,从下到上,从右到左,调整堆
adjustDown(arr,i,n)
def adjustDown(arr,i,n): # n表示所有要排序的节点个数
# 当列表第一个是以下标0开始,节点下标为i,左孩子则为2*i+1,右孩子下标则为2*i+2;
j = 2*i+1
while j < n:
if j+1 < n and arr[j] < arr[j+1]: # 找出较大的子节点
j += 1
if arr[i] > arr[j]:
break
arr[i], arr[j] = arr[j], arr[i]
i = j # 交换之后以交换子结点为根的堆可能不是大顶堆,需重新调整
j = 2*i + 1
计数排序
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键,存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
计数排序需要根据原始数列的取值范围,创建一个统计数组,用来统计原始数列中每一个可能的整数值所出现的次数。
原始数列中的整数值,和统计数组的下标是一一对应的,以数列的最小值作为偏移量。比如原始数列的最小值是90, 那么整数95对应的统计数组下标就是 95-90 = 5。
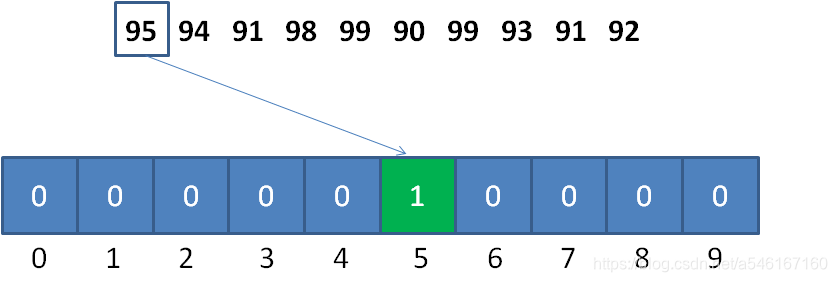
- 计数排序基本步骤
1,找出数组里面的最大值和最小值
2,求出每个元素出现的词频(count)
3,遍历词频数组求和
4,反向遍历原始数组,进行目标数组填充,填充后的数组再遍历就是有序的。
遍历一次得到元素的最小值和最大值,然后构造空间范围可以优化为,max-min+1,此外在实现的时候,对于原数组统计词频的时候,使用的每个元素减去min之后的值,这样能保证结果落在词频数组的范围之内,最后,为了保证排序算法的稳定性,我们需要对词频进行一次sum操作,从1开始,把每个位置的词频设置为当前的元素的词频+前一个元素的词频,这个值就代表了其在原数组里面应该出现的位置,接着我们倒序遍历原始数组,这样就能保证稳定性。
- 局限性
1.当数列最大最小值差距过大时,并不适用计数排序。
比如给定20个随机整数,范围在0到1亿之间,这时候如果使用计数排序,需要创建长度1亿的数组。不但严重浪费空间,而且时间复杂度也随之升高。
2.当数列元素不是整数,并不适用计数排序。
如果数列中的元素都是小数,比如25.213,或是0.00000001这样子,则无法创建对应的统计数组。这样显然无法进行计数排序。
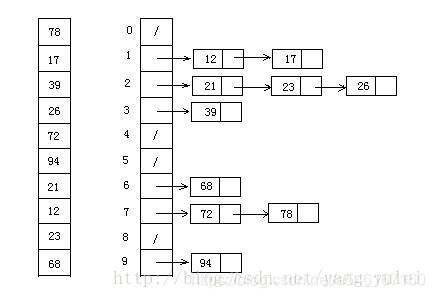
桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。
- 设置一个定量的数组当作空桶;
- 遍历输入数据,并且把数据一个一个放到对应的桶里去;
- 对每个不是空的桶进行排序;
- 从不是空的桶里把排好序的数据拼接起来。
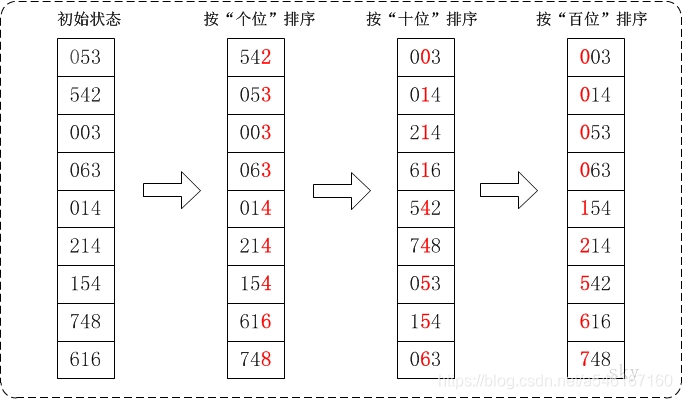
基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。排序过程是将所有待比较数值统一为同样的数位长度,数位较短的数前面补零,然后从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
- 取得数组中的最大数,并取得位数;
- arr为原始数组,从最低位开始取每个位组成radix数组;
- 对radix进行计数排序(利用计数排序适用于小范围数的特点);
总结
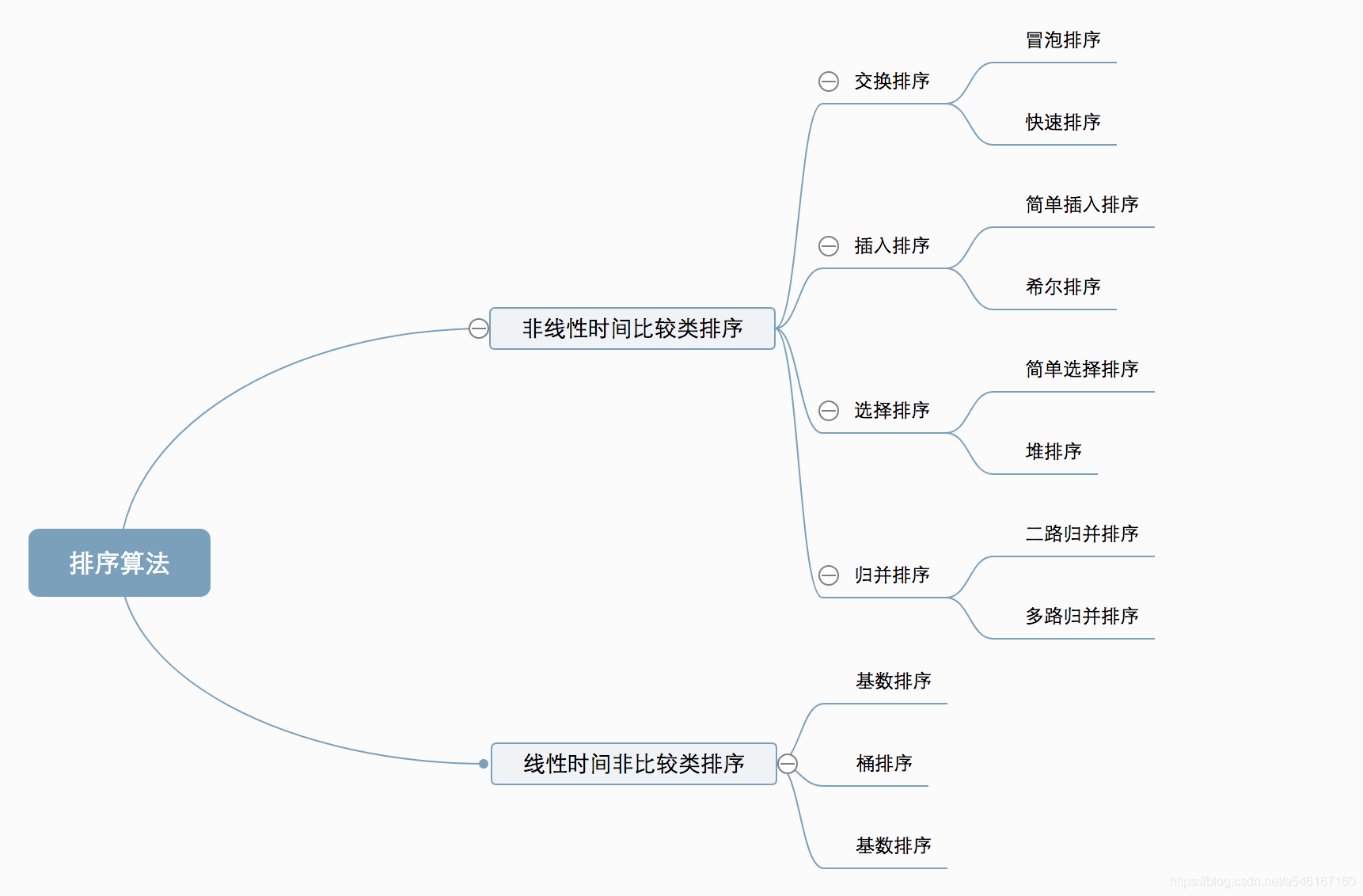
排序算法可以分为两大类:
非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
-
排序算法的性质
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。 -
比较
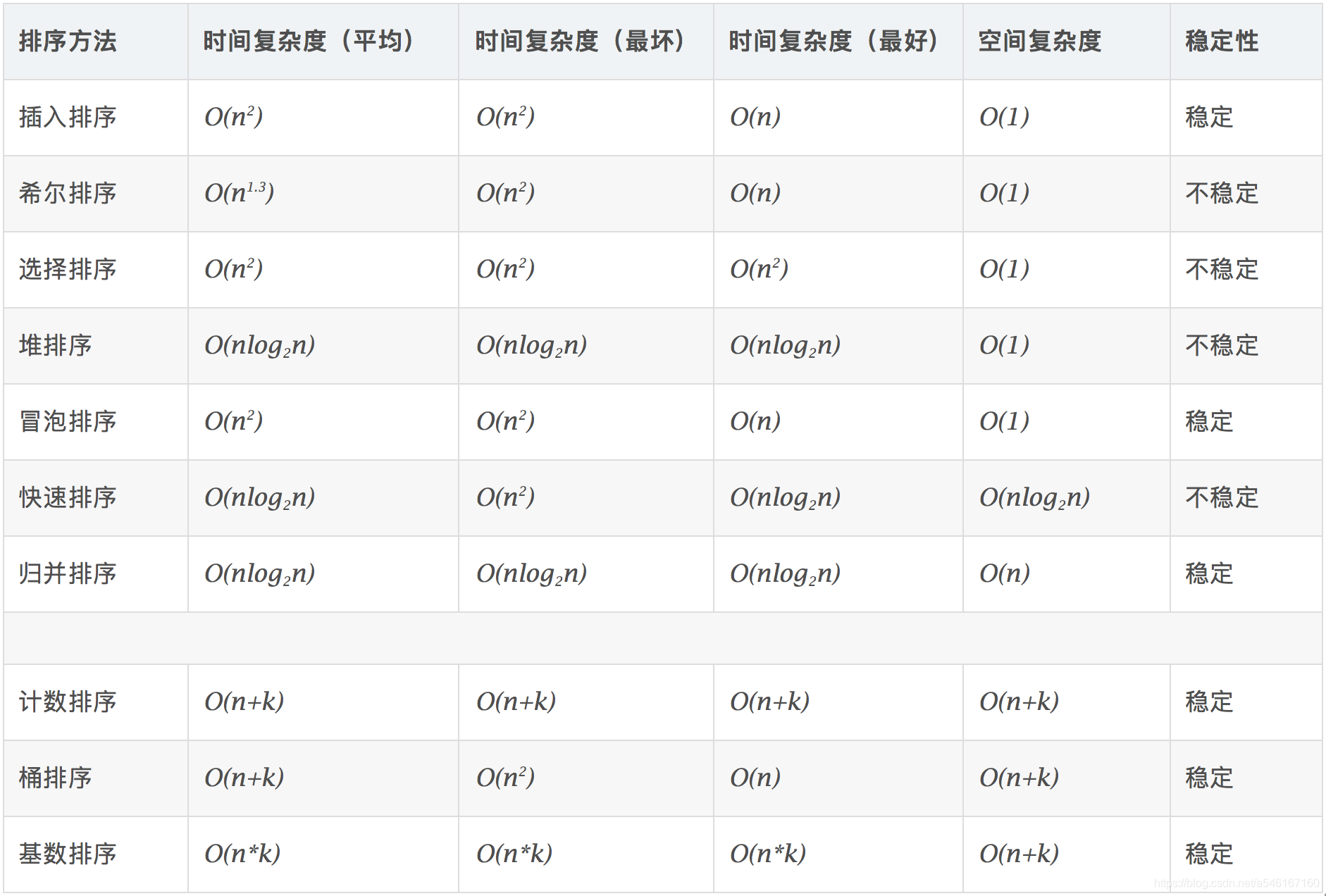
基数排序时间复杂度为O(n*k),其中n为数据个数,k为数据位数。 -
时间复杂度记忆-
冒泡、选择、直接 排序需要两个for循环,每次只关注一个元素,平均时间复杂度为O(n2)(一遍找元素O(n),一遍找位置O(n))
快速、归并、希尔、堆基于二分思想,log以2为底,平均时间复杂度为O(nlogn)(一遍找元素O(n),一遍找位置O(logn)) -
稳定性记忆 - 不稳定的算法“快希选堆”
动图来源:https://zhuanlan.zhihu.com/p/40695917
堆排序参考:https://www.cnblogs.com/0zcl/p/6737944.html
计数排序参考:https://m.wang1314.com/doc/webapp/topic/20305858.html
计数排序漫画:https://mp.weixin.qq.com/s/WGqndkwLlzyVOHOdGK7X4Q
算法比较来源:https://www.cnblogs.com/onepixel/articles/7674659.html#!comments















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









