







conbine1

每次循环调用函数求向量长度,做多次无用功
conbine2

优化:只求一次向量长度
效率提升。
conbine3

减小函数调用,直接通过地址计算得到下一个累乘值
效率略微下降,因为现代处理器能够预测索引是在界内的,高度可预测(不怎么懂,书上P379)
-O1

-O2

O2比O1少了个每次重新从寄存器里面读dest值的过程。
conbine4

减小不必要的内存引用,因为dest的位置可能在向量中,所以conbine3不能自动优化成conbine4的样子。
conbine5

少了一半的循环开销
conbine6

对于整数类型,conbine5可通过编译器优化为conbine6的类型,因为对于整数类型,执行顺序无关,可并行执行
而对于浮点数,不能。
conbine7

conbin5的另外一种优化形式,将与acc结果无关的数据挑出来,可与acc乘法并行计算。但要自行承担可能浮点数乘法顺序不一样带来的后果。
最后终极优化
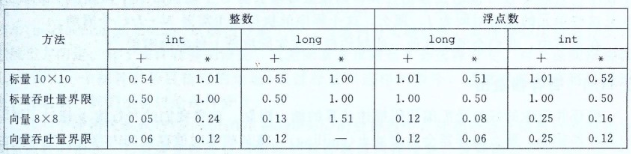
利用AVX向量指令,因为一个YMM寄存器32字节,可存放8个32位数据,或者4个64位数据,可用一条指令处理多个数据,除开长整数乘法代码,能够带来4倍或者8倍的速度提升。
有什么问题欢迎在评论区留言讨论!















 42
42











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









