









要了解分布式事务,首先要了解单机事务。要了解单机事务,首先则要了解事务的概念。
事务
任何一个对数据库的操作都是一个事务单元,也可以是多个对数据库的操作的集合。
尽管看起来计算机可以并行处理很多事情,但实际上每个CPU单位时间内只能做一件事,要么读取数据、要么计算数据、要么写入数据,所有的任务都可以看成这三件事的集合。计算机的这种特性引出了一个问题:当多个人去读、算、写操作时,如果不加访问控制,系统势必会产生冲突。而事务相当于在读、算、写操作之外增加了同步的模块,进而保证只有一个线程进入事务当中,而其他线程不会进入。
事务的核心是锁和并发。核心在于保证事务单元之间的happen-before关系,也就是协调好读读,读写,写读,写写之间的关系。
事务的ACID
事务具有四个特征:原子性( Atomicity )、一致性( Consistency )、隔离性( Isolation )和持续性( Durability )。这四个特性简称为 ACID 特性。
其中原子性指的是事务中包含的所有操作要么全做,要么全不做;一致性是指在事务开始以前,数据库处于一致性的状态,事务结束后,数据库也必须处于一致性的状态;隔离性要求系统必须保证事务不受其他并发执行的事务的影响;持久性是指一个事务一旦成功完成,它对数据库的改变必须是永久的,即使是在系统遇到故障的情况下也不会丢失,数据的重要性决定了事务的持久性的重要。
事务的实现方式(2PL)
Two Phase Lock(2PL)是数据库中非常重要的一个概念。
2PL是指所有事务必须分两个阶段对数据项加锁和解锁:
1. 在对任何数据进行读、写操作之前,要申请并获得对该数据的封锁。
2. 每个事务中,所有的封锁请求先于所有的解锁请求。
数据库操作Insert、Update、Delete都是先读再写的操作,例如Insert操作是先读取数据,读取之后判读数据是否存在,如果不存在,则写入该数据,如果数据存在,则返回错误。
理论上,所有被读取的数据都已加锁,不会再被其他人读到,也就是说对数据进行的中间操作状态对所有人都不可见,当所有中间状态完成后,提交操作时,解开锁,此时数据对所有系统可见。通过2PL的方式,我们就可以实现事务。
事务的处理是怎么发展的呢?
串行执行
为了处理事务单元之间的happen-before关系,最简单的方式当然是排队法,也就是串行执行。
一个一个的执行事务,当然就不会出现任何冲突,这是最简单也是很重要的一种事务处理方式。
优势:不需要冲突控制,也不会发生死锁。
劣势:执行速度慢,如果某个事务特别慢则整个执行都会变得非常慢。
排它锁
对于处理不同数据的事务单元,我们理所当然的可以将他们分开。例如,Bob给Smith转账,和Alice给Peter转账。两个事务单元处理的数据并不相同,我们就可以将这两个事务单元并行执行,而不会产生任何的冲突。这就是排它锁。
当然,对于共享数据的处理的事务单元,还是串行执行的。
利用排它锁,我们实现了对于不同数据的事务单元的并行化。
读写锁
虽然排它锁已经进行了一定的并行化。但我们对于事务处理的速度的追求是无止境的。所以,读写锁产生了。
对于读写锁的不同级别,可以分成以下几类:
1.增加读锁和写锁。
如果是一个读事务,我们知道,读事务是一定不会改变数据的,所以,我们可以对读读进行优化,可是使得读读并行。但是,读写,写读,写写都是不能并行的。
这也称为可重复读(Repeatable Read)。
2.增加读锁和写锁,但是读锁可以被写升级成写锁。
这种方法,可以使得不仅读读并行,还能将读写并行,实现了两个关系的并行化。但这也会造成不可重复读。
也称为读已提交(Read Committed)
3.只增加写锁。
只增加写锁,读就不会加锁,所以读操作可以任意的和写操作并行。这就使得写读操作也能并行。但有可能会读到中间数据,也就是会脏读。
这也称为读未提交(Read UnCommitted)
我们可以看得出,后面两种方法对于隔离性,一致性已经不能很好的保证了。所以这就成为了事务的隔离级别。
隔离级别的核心就是以性能为理由,对一致性的破坏。
读写锁的原理就是上面所说。但是仅仅是读写锁的话,虽然能使得一定的并行化,但是会产生一个很严重的问题。那就是死锁的产生。
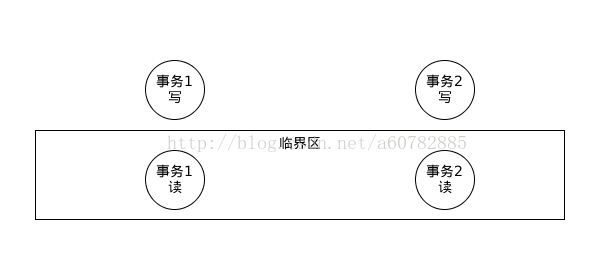
对于这上面这两个事务单元,事务1的写操作等待事务2的读操作完成,而事务2的写操作等待事务1的读操作完成。这就造成了死锁。
为了解决这个办法,可以采用U锁。
U锁也就是更新锁,就是当加锁的时候,如果发现当前事务中包含有写操作,那么就直接加上写锁,而不会先加读锁。这样就可以避免死锁的发生。
但很可惜,现在的数据库的事务,基本都不会采取上面的做法。而是使用快照隔离级别(Snapshot Isolation),也就是MVCC的方式。
MVCC(多版本并发控制)
在最初的数据库事务实现中是不存在MVCC的,它是Oracle在八十年代新加的功能,本质是Copy On Write,也就是每次写都是以重新开始一个新的版本的方式写入数据,因此,数据库中也就包含了之前的所有版本。在数据读的过程中,先申请一个版本号,如果该版本号小于正在写入的版本号,则数据一定可以查询到,无需等到新版本完全写完即可返回查询结果。这种方式可以在读读不阻塞的前提下,实现读写/写读不阻塞,尽可能保证所有的读操作并行,而写操作串行。
也就是说,在MVCC中,写操作是不直接覆盖原本数据的,而是在一个新的版本中写入数据,而读的时候则可以从旧的版本中读取数据。这就实现了除了写写操作之外,其他所有操作的并行化。并且,可以在保持数据一致性的情况下实现并行!!现在的数据库基本都是使用MVCC。
我们这里在看看持久性,在传统中,如何保证持久性的呢?
持久性就是保证数据在commit了之后,持久的保存下来。
这里就需要用到RAID,也就是磁盘阵列。为了保证数据的持久性,我们都需要将数据多存几份吧?
多存几份数据,这又遇到了一个新的问题,就是在同时对多块硬盘的写入需要同时成功或者同时失败,这就是RAID Controller的工作。
并且还会引申出一个问题,如果我们每次commit都直接对磁盘进行操作的话,那么我们就需要对磁盘进行多次的IO操作。
我们知道,一次磁盘IO的最小单位是页。如果我们对同一个页进行多次IO操作,就会造成浪费,所以我们有了以下两种做法:
1.commit之后直接返回。等到内存中攒的数据足够多了之后,再进行真正的持久化。这就节省了很多个IO。
2.将内存中的数据打包再提交到磁盘中。这个方式主要是以组提交的方式实现,commit到达一定数量的时候才会进行返回。
以上所有做的一切,都是为了尽可能的提升并行度。
接下来我们来看一些单机事务典型的异常处理方式:
1.业务属性不匹配
当业务属性不匹配时。例如,如果Bob给Smith转账,可以分成以下几个步骤,查看Bob账号是否有足够的钱,Bob账号扣钱,Smith账号加钱。但是如果在Smith账号加钱的执行过程中,如果发现Smith账号其实并不存在,这就是业务属性不匹配。这种时候,就需要事务的回滚。也就是通过undo日志进行回滚。
2.系统宕机
如果在某个事务在执行到中途的时候,系统突然宕机了。我们就需要对系统进行恢复。这个时候,系统会根据日志进行处理。对于没有commit的事务,全部回滚。对于已经commit的事务,要完成事务。这个时候,系统处于一种recovery模式,这个模式下,恢复是原子性的,不会开放数据对外操作。只有当数据全部恢复了之后,才会开发数据。
事务的调优原则
事务的调优的思路是在不影响业务应用的前提下:
第一,尽可能减少锁的覆盖范围,例如Myisam表锁到Innodb的行锁就是一个减少锁覆盖范围的过程;对于原位锁(排他锁、读写锁等)可变为MVCC多版本(本质仍然是减少锁的范围)。
第二,增加锁上可并行的线程数,例如读锁和写锁的分离,允许并行读取数据。
第三,选择正确锁类型,其中悲观锁适合并发争抢比较严重的场景;乐观锁适合并发争抢不太严重的场景。















 1095
1095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









