






网站敏感信息扫描工具,可以检查前端代码中是否包含了内网ip地址、邮箱等敏感信息。
源码地址:SecurityLib/senscan at master · fantasyfanfan/SecurityLib (github.com)
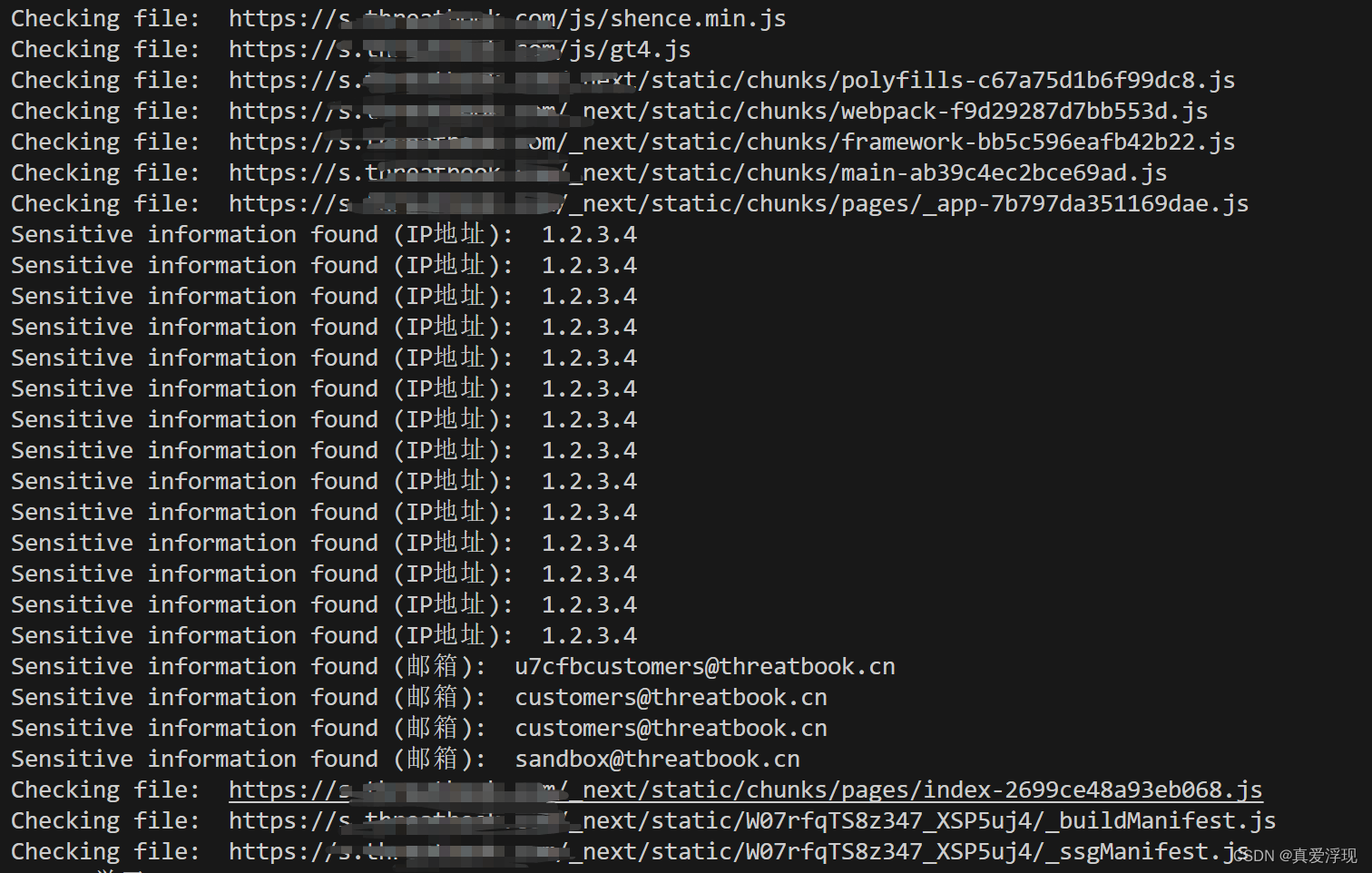
脚本使用 Selenium 和 BeautifulSoup 对一个特定网站进行了网络爬虫操作,从而获取网站的 JavaScript 文件,并在其中寻找可能的敏感信息。脚本的操作步骤如下:
-
设置 Selenium:这个脚本使用了 Firefox 浏览器和 GeckoDriver 作为 Selenium 的驱动。GeckoDriver 是一个代理,它可以在 W3C WebDriver-compatible 浏览器(如 Firefox)之间转发命令。脚本首先指定了 Firefox 浏览器和 GeckoDriver 的路径。
-
获取动态网页源代码:脚本使用 Selenium 打开了一个指定的 URL,然后获取了动态生成的 HTML 源代码。因为这个网页可能使用 JavaScript 动态生成内容,所以需要使用 Selenium 来获取完整的网页源代码。
-
解析 HTML:脚本使用 BeautifulSoup 对获取到的 HTML 源代码进行了解析,找到了所有的
<script>标签,这些标签可能链接到外部的 JavaScript 文件。 -
获取 JavaScript 文件:脚本提取了所有
<script>标签的src属性,得到了所有 JavaScript 文件的 URL。对于相对 URL,脚本使用了urllib.parse.urljoin方法将它们转化为绝对 URL。 -
查找敏感信息:脚本下载了所有的 JavaScript 文件,并在其中寻找匹配预定义正则表达式的文本。这些正则表达式用于匹配可能的敏感信息,例如 IP 地址和电子邮件地址。
这个脚本的主要目标是在 JavaScript 文件中寻找敏感信息。请注意,这种方法可能会引发一些法律和道德问题,因为它可能会获取到不应该被公开的信息。在使用这个脚本之前,你应该确保你有权访问和分析你想要爬取的网站。














 1060
1060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









