







 本文深入探讨RNNLM(循环神经网络语言模型)的源码,结合多种扩展阅读材料,包括大型神经网络语言模型的训练策略、基于神经网络的统计语言模型以及长期依赖学习的挑战。通过这些资源,读者可以更好地理解RNNLM在自然语言处理中的应用和挑战。
本文深入探讨RNNLM(循环神经网络语言模型)的源码,结合多种扩展阅读材料,包括大型神经网络语言模型的训练策略、基于神经网络的统计语言模型以及长期依赖学习的挑战。通过这些资源,读者可以更好地理解RNNLM在自然语言处理中的应用和挑战。
系列前言
参考文献:
- RNNLM - Recurrent Neural Network Language Modeling Toolkit(点此阅读)
- Recurrent neural network based language model(点此阅读)
- EXTENSIONS OF RECURRENT NEURAL NETWORK LANGUAGE MODEL(点此阅读)
- Strategies for Training Large Scale Neural Network Language Models(点此阅读)
- STATISTICAL LANGUAGE MODELS BASED ON NEURAL NETWORKS(点此阅读)
- A guide to recurrent neural networks and backpropagation(点此阅读)
- A Neural Probabilistic Language Model(点此阅读)
- Learning Long-Term Dependencies with Gradient Descent is Difficult(点此阅读)
- Can Artificial Neural Networks Learn Language Models?(点此阅读)
这篇主要介绍一个网络前向计算的函数,内容量也挺大的。在此之前,解释一下rnn的输出层分解,和从神经网络的角度去看最大熵模型。先看一下原论文中最"标准"的rnn结构,这个结构是最原始的,后面会有系列的扩展,详见参考文献的第3篇。
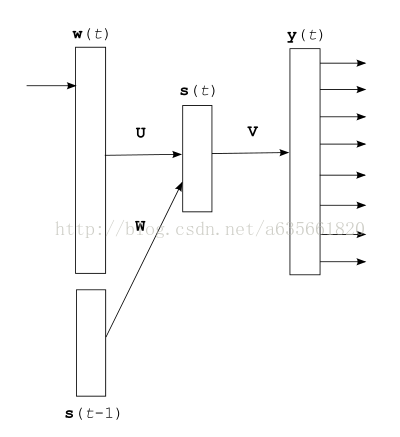
上图是最原始的循环神经网络的结构,关于它的前向计算和学习算法我在rnnlm原理以及bptt数学推导这篇文章有详细的写过。简要在写一下。上面这个网络的输出层有|V|维,在整个前向计算完毕后,我们得到的结果就是预测词的概率分布,即yt = P(wt+1 | wt,st-1), wt+1是要预测的词.
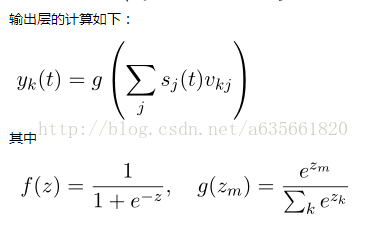
这是我从前篇文章截图来的,由于网络输出层部分计算量很大,特别是当|V|很大时,计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









