






ps:之前研究了使用itext html转PDF 对中文和css的支持不很好,果然Google了一把,发现flying-saucer-pdf这个效果好,研究了一下果然行,运用到项目中基本上能满足需求。
1、pom.xml 文件
1 1 <dependency> 2 2 <groupId>com.itextpdf</groupId> 3 3 <artifactId>itextpdf</artifactId> 4 4 <version>5.5.13</version> 5 5 </dependency> 6 6 <dependency> 7 7 <groupId>com.itextpdf.tool</groupId> 8 8 <artifactId>xmlworker</artifactId> 9 9 <version>5.5.13</version> 10 10 </dependency> 11 11 <dependency> 12 12 <groupId>com.itextpdf</groupId> 13 13 <artifactId>itext-asian</artifactId> 14 14 <version>5.2.0</version> 15 15 </dependency> 16 16 <dependency> 17 17 <groupId>org.xhtmlrenderer</groupId> 18 18 <artifactId>flying-saucer-pdf</artifactId> 19 19 <version>9.0.3</version> 20 20 </dependency>
2、代码
package pdf.kit; import com.itextpdf.text.*; import com.itextpdf.text.pdf.BaseFont; import com.itextpdf.text.pdf.PdfWriter; import com.itextpdf.tool.xml.Pipeline; import com.itextpdf.tool.xml.XMLWorker; import com.itextpdf.tool.xml.XMLWorkerFontProvider; import com.itextpdf.tool.xml.XMLWorkerHelper; import com.itextpdf.tool.xml.html.CssAppliers; import com.itextpdf.tool.xml.html.CssAppliersImpl; import com.itextpdf.tool.xml.html.Tags; import com.itextpdf.tool.xml.net.FileRetrieve; import com.itextpdf.tool.xml.net.ReadingProcessor; import com.itextpdf.tool.xml.parser.XMLParser; import com.itextpdf.tool.xml.pipeline.css.CSSResolver; import com.itextpdf.tool.xml.pipeline.css.CssResolverPipeline; import com.itextpdf.tool.xml.pipeline.end.PdfWriterPipeline; import com.itextpdf.tool.xml.pipeline.html.*; import org.apache.commons.io.FileUtils; import org.apache.commons.lang.StringUtils; import org.xhtmlrenderer.pdf.ITextFontResolver; import org.xhtmlrenderer.pdf.ITextRenderer; import java.io.*; import java.net.HttpURLConnection; import java.net.URL; import java.nio.charset.Charset; /** * html 转换成 pdf */ public class ParseHtmlTable { public static final String pdfDestPath = "C:/Users/xxx-b/Desktop/pdf/"; public static final String htmlPath = "D:\\3-workspace\\pdf-test\\src\\test\\resources\\templates\\test.html"; public static void main(String[] args) throws IOException, DocumentException { String pdfName = "test.pdf"; ParseHtmlTable parseHtmlTable = new ParseHtmlTable(); String htmlStr = FileUtils.readFileToString(new File(htmlPath)); parseHtmlTable.html2pdf(htmlStr,pdfName ,"C:\\Windows\\Fonts"); } public void html2pdf(String html, String pdfName, String fontDir) { try { ByteArrayOutputStream os = new ByteArrayOutputStream(); ITextRenderer renderer = new ITextRenderer(); ITextFontResolver fontResolver = (ITextFontResolver) renderer.getSharedContext().getFontResolver(); //添加字体库 begin File f = new File(fontDir); if (f.isDirectory()) { File[] files = f.listFiles(new FilenameFilter() { public boolean accept(File dir, String name) { String lower = name.toLowerCase(); return lower.endsWith(".otf") || lower.endsWith(".ttf") || lower.endsWith(".ttc"); } }); for (int i = 0; i < files.length; i++) { fontResolver.addFont(files[i].getAbsolutePath(), BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); } } //添加字体库end renderer.setDocumentFromString(html); renderer.layout(); renderer.createPDF(os); renderer.finishPDF(); byte[] buff = os.toByteArray(); //保存到磁盘上 FileUtil.byte2File(buff,pdfDestPath,pdfName); } catch (Exception e) { e.printStackTrace(); } } }
FileUtil.java
package pdf.kit; import java.io.*; public class FileUtil { /** * 获得指定文件的byte数组 * * @param filePath 文件绝对路径 * @return */ public static byte[] file2Byte(String filePath) { ByteArrayOutputStream bos = null; BufferedInputStream in = null; try { File file = new File(filePath); if (!file.exists()) { throw new FileNotFoundException("file not exists"); } bos = new ByteArrayOutputStream((int) file.length()); in = new BufferedInputStream(new FileInputStream(file)); int buf_size = 1024; byte[] buffer = new byte[buf_size]; int len = 0; while (-1 != (len = in.read(buffer, 0, buf_size))) { bos.write(buffer, 0, len); } return bos.toByteArray(); } catch (Exception e) { System.out.println(e.getMessage()); e.printStackTrace(); return null; } finally { try { if (in != null) { in.close(); } if (bos != null) { bos.close(); } } catch (Exception e) { System.out.println(e.getMessage()); e.printStackTrace(); } } } /** * 根据byte数组,生成文件 * * @param bfile 文件数组 * @param filePath 文件存放路径 * @param fileName 文件名称 */ public static void byte2File(byte[] bfile, String filePath, String fileName) { BufferedOutputStream bos = null; FileOutputStream fos = null; File file = null; try { File dir = new File(filePath); if (!dir.exists() && !dir.isDirectory()) {//判断文件目录是否存在 dir.mkdirs(); } file = new File(filePath + fileName); fos = new FileOutputStream(file); bos = new BufferedOutputStream(fos); bos.write(bfile); } catch (Exception e) { System.out.println(e.getMessage()); e.printStackTrace(); } finally { try { if (bos != null) { bos.close(); } if (fos != null) { fos.close(); } } catch (Exception e) { System.out.println(e.getMessage()); e.printStackTrace(); } } } }
3.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <style type="text/css"> *{ padding: 0; margin: 0; color: #000; font-family:Microsoft YaHei } </style> </head> <body screen_capture_injected="true" ryt11773="1"> <p> <span style="font-size:12.0pt; font-family:MS Mincho">長空</span> <span style="font-size:12.0pt; font-family:Times New Roman,serif">(Broken Sword),</span> <span style="font-size:12.0pt; font-family:MS Mincho">秦王殘劍</span> <span style="font-size:12.0pt; font-family:Times New Roman,serif">(Flying Snow),</span> <span style="font-size:12.0pt; font-family:MS Mincho">飛雪</span> <span style="font-size:12.0pt; font-family:Times New Roman,serif">(Moon), </span> <span style="font-size:12.0pt; font-family:MS Mincho">如月</span> <span style="font-size:12.0pt; font-family:Times New Roman,serif">(the King), and</span> <span style="font-size:12.0pt; font-family:MS Mincho">秦王</span> <span style="font-size:12.0pt; font-family:Times New Roman,serif">(Sky).</span> </p> <p>选中<input type="checkbox" value="1" disabled="disabled" checked="checked"/></p> <br/> <textarea rows="11" cols="10" disabled="disabled"> adfadfadfadfa </textarea> </body> </html>
4、pdf结果
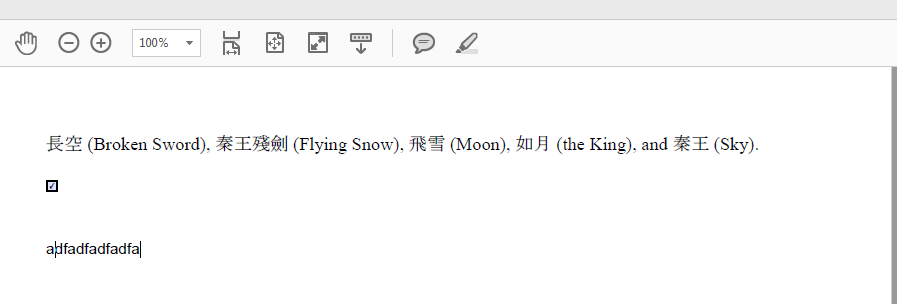
5、一些总结
1、模板的要求: html的格式要求符合xml格式,必须要有闭合标签。
2、字体的支持: font-family:Microsoft YaHei ,html中定义字体,程序中一定要导入想匹配的格式,才能有效。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









