







本篇参考自rapheal的【算法入门】广度/宽度优先搜索(BFS),觉得写得超级赞,大家去他那里相信会有很多收获。
基本简介:
每次将集合中的元素经过一些改动,分层生成当前状态的子状态(通常还删除父情况),添加到集合(队列)中,以实现遍历或搜索等目的的算法。一般可以用它做什么呢?一个最直观经典的例子就是走迷宫,我们从起点开始,找出到终点的最短路程,很多最短路径算法就是基于广度优先的思想成立的。
据图说明:
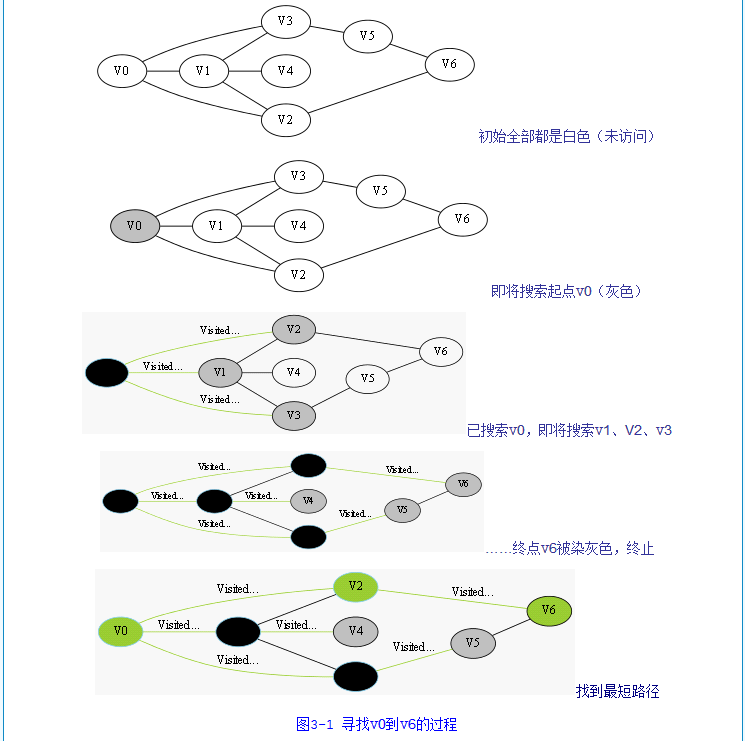
由图我们可以清晰的看到整个搜索的流程:
- 起初所有节点都是白色
- 把v0加入队列,变成灰色
- 扫描所有灰色点(队列),未发现终点v6
- 将v0所能达到的白色节点v2,v1,v3变成灰色,并将v0变成黑色(表示已搜索过)
- 将v2抽出,其能达到的白色节点v6变为灰色,再扫描所有灰色节点,发现终点v6,终止搜索(先抽v1也是一样,反正是同一层次,只是多重复一轮,一般就按照放入队列的先后抽)
- 将搜索到的路径变为绿色,即为最短路径
核心代码:
/**
- 广度优先搜索
- #include<queue> 头文件
- @param Vs 起点
- @param Vd 终点
*/
bool BFS(Node& Vs, Node& Vd){
queue<Node> Q;
Node Vn, Vw;
int i;
//初始状态将起点放进队列Q
Q.push(Vs);
visit[Vs.x][Vs.y] = true;//设置节点已经访问过了!也可以用hash(Vw) = true;
while (!Q.empty()){//队列不为空,继续搜索!
//取出队列的头Vn
Vn = Q.front();
//从队列中移除
Q.pop();
while(Vw = Vn通过某规则能够到达的节点){
//可以在这里加路径,即沿着边走的方法
if (Vw == Vd){//找到终点了!
//把路径记录,这里没给出解法
return true;//返回
}
if (isValid(Vw) && !visit[Vw]){
//Vw是一个合法的节点并且为白色节点
Q.push(Vw);//加入队列Q
visit[Vw.x][Vw.y] = true;//设置节点颜色。也可以hash(Vw) = true;
}
}
}
return false;//无解
}附加:
队列(先进先出):
优先队列的创建
#include <queue>
/*priority_queue<Type,Comp,Container> q; //后两者是可选的,默认使用<比较,vector容器*/
queue<node> q;//一般直接这样写,上行那个我不懂
//支持以下几种操作:
q.empty() const;//判断是否为空
q.push(vn);//进队列尾
q.pop();//让头节点出队列
vn=q.front();//抽出队列头
TYPE& top();
size_type size() const;一般队列有下面几个操作:
- void InitQueue(Queue *Q) ——初始化队列
- void EnQueue(Queue *Q, int key) ——让key进队列
- int DeQueue(Queue *Q) ——让头节点出队列
- int IsQueueEmpty(Queue *Q) ——判断队列是否为空
- int IsQueueFull(Queue *Q) ——判断队列是否已满
typedef struct queue
{
int queuesize; //数组的大小
int head, tail; //队列的头和尾下标
int *q; //数组头指针
}Queue;栈(后进先出):
栈的逻辑结构:假设一个栈S中的元素为an,an-1,..,a1,则称a1为栈底元素,an为栈顶元 素。栈中的元素按a1 ,a2,..,an-1,an的次序进栈。在任何时候,出栈的元素都是栈顶元素。换句话说,栈的修改是按后进先出的原则进行的
//暂时我还只接触到了这些:
#include<stack>
stack<node> s;//新建栈
s.push(vn);//从栈头插入
s.empty();//判断队列是否为空
vn=s.top();//抽出栈头
s.pop();//移除栈头
//下面的比较高大上,我不懂。。。
//头文件:sqstack.h,包含定义顺序栈数据结构的代码、宏定义、要实现算法的函数的声明
#ifndef SQSTACK_H_INCLUDED
#define SQSTACK_H_INCLUDED
#define MaxSize 100
typedef char ElemType;
typedef struct
{
ElemType data[MaxSize];
int top; //栈指针
} SqStack; //顺序栈类型定义
void InitStack(SqStack *&s); //初始化栈
void DestroyStack(SqStack *&s); //销毁栈
bool StackEmpty(SqStack *s); //栈是否为空
int StackLength(SqStack *s); //返回栈中元素个数——栈长度
bool Push(SqStack *&s,ElemType e); //入栈
bool Pop(SqStack *&s,ElemType &e); //出栈
bool GetTop(SqStack *s,ElemType &e); //取栈顶数据元素
void DispStack(SqStack *s); //输出栈 “容器”vector:
它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库。vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vector是一个能够存放任意类型的动态数组,能够增加和压缩数据。
//暂时只用到这些
#include<vector>
vector<node> v;
v.push_back(vn);//在尾部加入一个数据。
v.empty();//判断容器是否为空。
v.size();//返回容器中实际数据的个数。
v.pop_back();//删除最后一个数据
v.clear();//移除容器中所有数据。
v.front();//传回第一个数据。
v.back();//传回最后一个数据,不检查这个数据是否存在。














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









