







在实验楼上学习了一些MySQL,常用的查询可能够了,来分享笔记。
绿色表示助记或者自己特别探索过的地方
where 的用法:
WHERE
(条件1)
AND
(条件2,比如:
age<=45
)
OR
(条件3,比如:
phone like ‘1101%’
)
AND
(条件4,比如:
name not in (‘ben’,‘jack’,‘anna’)
)like和通配符:
一起使用,通配符_代表一个字符,%代表不定个
排序:
(一般放在最后)
ORDER BY salary DESC;约束:
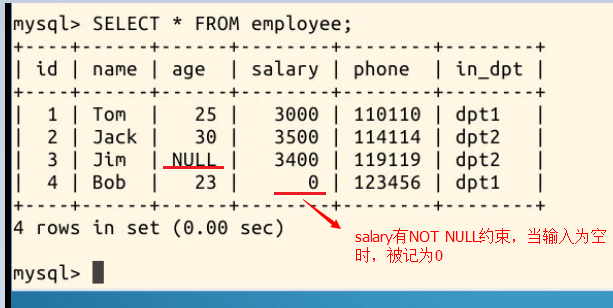
只要在添加列的时候加上约束条件即可,比如 not null(自动把空值变为0)
内置函数:
AVG(salary) AS avg_salary
IN:
in的基础用法是作为where的条件(具体见上)
作为引申,用in来做子查询嵌套
select IN (select...)隐式连接:
(默认就是隐式,就是内链接,隐式是我自己加上去的两个字,因为代码中没有join关键字,我一开始还不明白为什么叫连接)
select <span style="background-color: rgb(51, 255, 51);">想要的列,顺序没关系</span>
from <span style="background-color: rgb(51, 255, 51);">来自的表,顺序没关系</span>
where <span style="background-color: rgb(51, 255, 51);">两个表按照各自哪个列对应起来</span>
(eg:employee的in_dpt连接department的dpt_name,
就是employee.in_dpt = department.dpt_name)
order by 按照什么列排个序吧;显式链接:
(在表之间加入 join关键字,在where换成on,从而也可以实现两种外连接(用得比较少):左join和右join)
用上面一样的做例子:
select 想要的列,顺序没关系
from 来自的表,顺序没关系(employee <span style="color:#ff0000;">JOIN</span> project)
<span style="color:#ff0000;">ON </span>两个表按照各自哪个列对应起来
(eg:employee的in_dpt连接department的dpt_name,
就是employee.in_dpt = department.dpt_name)
order by 按照什么列排个序吧;最好都在列名前面加上表名,用点隔开:
Posts.AnswerCount
ALTER (更改):
ALTER TABLE
表名字
操作( 想做的操作,比如 ADD COLUMN(可以简化为ADD) ,RENAME,DROP,CHANGE)
对象(操作对象,比如列名字,表名字)
附加选项(如果是增加列的话,可以在这里写约束和数据类型,还可以加上FIRST让这列变成第一列)
;
SELECT DISTINCT 语句:
SELECT DISTINCT 列名 FROM 表名
这样就可以把提取出来的列名中重复的项去掉
UNION:
用select选取两个列标签相同的表后,把表上下连接起来
Select A
UNION
Select B
变成:
A
B
并取唯一值(如果A表已经有了,B表就会删掉那个【A表自己的重复值会不会受到影响?】)不想取唯一值的话,用UNION ALL
GROUP BY:
合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句。
因为单纯的SUM(列名)只能求出列总和,但是如果最后加上一句:
GROUP BY 其他列名;
就会把sum的那一列按照group by的那一列的唯一值进行分组并求和
HAVING:
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
比如,用了SUM就不可以用where了,因为sum是放在where前面的语法,但是如果想在sum里面再筛选,除了使用子查询外,还可以在最后加上一句:
HAVING SUM(OrderPrice)>1500
这样就对SUM(OrderPrice)列进行了求和,顺便一提,如果一开始就用as给SUM(OrderPrice)列取了名字,要用新名字
附上SQL写作思路:
无非. 掌握好个顺序,按需要来查询.
select ..where.. group by .. having .. order by
然后,需要引用其他的 表,就做关联或者联合.
然后有什么条件加什么条件, 然后有分组的来统计就分组,
分组后有筛选就用having 来过滤分组后的结果集.
最后,做排序.. over
顺便说说看文档和敲代码:
以前有一段时间我都没有仔细对着代码敲过,因为在实验楼上代码解释结果都有,感觉就没必要
不过最近感觉不是这样的,照做不是目的,而是在知道正确结果和正确输入的情况下,尝试各种自己的发挥和鲁棒,有点像是在做测试,我们已经知道了正确的是什么,而且也要知道错误的是怎样的。
有几段代码,我一开始先看文档,看完了,感觉有点不相信敲下去能学到什么,其实巩固记忆倒是其次,主要是一敲下去就会想:这样敲行不行,表名按顺序好麻烦,不按行不行...这样感觉才能真正学到文档里没有的东西,而且记忆也更深刻了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









