






一.本人认为系统内最复杂最核心的是,查票和订票子系统。
以下为设计的数据结构
列车信息表
|列车号|沿路站点|站点权重值|发车时间|
|列车号|沿路站点|站点权重值|发车时间|
------------------------------------
D123 | A | 1 |8:00 |
D123 | B | 2 |9:00 |
D123 | C | 3 |10:00 |
D123 | D | 4 |12:00 |
车票信息表
|列车号|座位号 |始发站点|始发站点权重值|下车站点|下车站点权重值|
|列车号|座位号 |始发站点|始发站点权重值|下车站点|下车站点权重值|
---------------------------------------------------------------------
D123 | 3A13 | A | 1 | B | 2 |
D123 | 3A10 | C | 3 | D | 4 |
数据结构说明:列车信息表 是基础信息表,数据基本是预设定的。
车票信息表(每一行数据就代表一张票) 预设定是空表,当用户购票成功,就插入一条新数据。
查票业务逻辑:
入参: 当前时间 出发站点 下车站点
结果:查询出满足条件的所有列车 ---》进而查询出 每辆列车满足条件的座位有多少个(即票)。
sql演示代码:
1.查询出所有不满足条件的座位(直接查询满足条件的座位,是一个sql难以做到的)
select
列车号,座位号 from 车票信息表 where (出发站点>
始发站点权重值 and 出发站点 <
下车站点权重值) or ( 下车站点 >
始发站点权重值 and 下车站点 <
下车站点权重值)
2.再把上面的查询结果和列车信息表求余,即可得出可以卖的座位(票)。
二.
12306系统架构建议
客户体检查,无非不外乎2种情况。
1.服务器压力大。
2.网络拥堵。
只针对
12306系统进行单纯单点的分布式集群部署,远远不能满足需求。就算服务器扛得住压力,全国的流量也会造成网络拥堵。
解决办法(关键是如何分流):
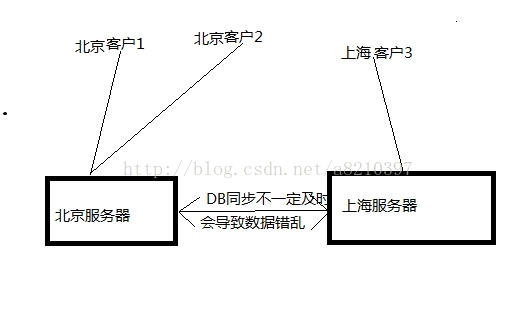
1.针对不同地域,进行地理位置上的分布式部署(不可行)。(优点:确实能有效分流,缺点:不同地理位置的系统数据同步,会成为大问题,不能保证订票系统及时性。)
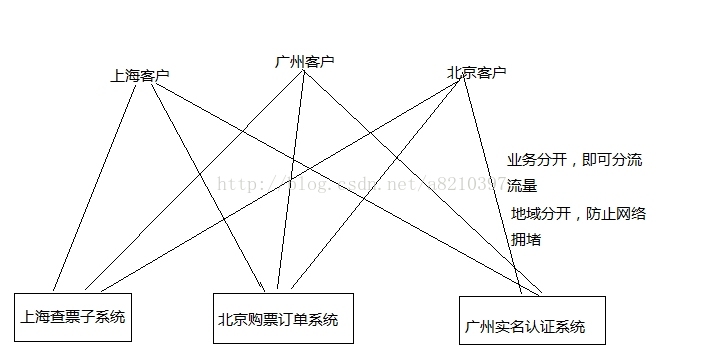
2.对系统业务进行分割,并将分割后的子系统,部署在不同的地理位置上。
优点:业务拆分后可以,有效的分流流量,并且不需要进行数据同步,提高健壮性 容灾性。
缺点:管理运营成本提高,有配套的后台管理系统即可解决。
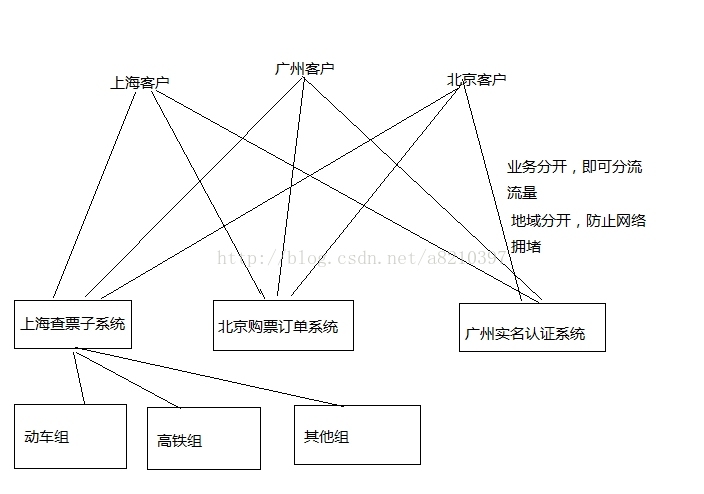
就算是在订票子系统内,还可以进行适当的业务分割,比如:对所有列车进行分割,动车组--映射到--》abc.com服务器 高铁组--映射到--》def.com服务器,以此类推,即可进一步分流繁忙的订票子系统。
子系统内,业务再分割:
3.如果以上都解决不了,对实时性要求不高的子系统可以将上述2者综合反复叠加使用,就可以把系统架设成逻辑上的格子状,并使用集群服务器或者引进处理能力超强的硬件。















 4714
4714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









