







Java NIO中的Buffer用于和NIO通道进行交互。数据是从通道读入缓冲区,从缓冲区写入到通道中的。缓冲区本质上是一块固定大小的内存,其作用是一个存储器或运输器。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
1、缓冲区基础
理论上,Buffer是经过包装后的数组,而Buffer提供了一组通用api对这个数组进行操作。
1.1、属性:
容量(Capacity)
缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定,并且永远不能被改变。
上界(Limit)
缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数。
位置(Position)
下一个要被读或写的元素的索引。位置会自动由相应的get( )和put( )函数更新。
标记(Mark)
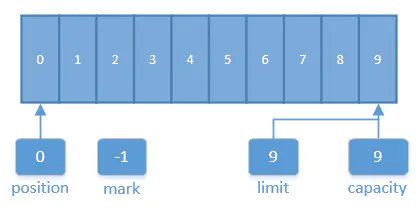
一个备忘位置。调用mark( )来设定mark = postion。调用reset( )设定position = mark。标记在设定前是未定义的(undefined)。这四个属性之间总是遵循以下关系: 0 <= mark <= position <= limit <= capacity 让我们来看看这些属性在实际应用中的一些例子。下图展示了一个新创建的容量为10的ByteBuffer逻辑视图。
ByteBuffer逻辑视图.png
位置被设置为0,而且容量和上界被设置为9,超过缓冲区能容纳的最后一个字节,标记初始未定义(-1),当缓冲区创建完毕,则容量就不变,而其他属性随读写等操作改变。
1.2、缓存区API
public final int capacity( ) :返回缓冲区的容量
public final int position( ) :返回缓冲区的位置
public final Buffer position (int newPosition):设置缓冲区的位置
public final int limit( ) :返回缓冲区的上界
public final Buffer limit (int newLimit) :设置缓冲区的上界
public final Buffer mark( ) :设置缓冲区的标记
public final Buffer reset( ) :将缓冲区的位置重置为标记的位置
public final Buffer clear( ) :清除缓冲区
public final Buffer flip( ) :反转缓冲区
public final Buffer rewind( ) :重绕缓冲区
public final int remaining( ) :返回当为位置与上界之间的元素数
public final boolean hasRemaining( ) :缓存的位置与上界之间是否还有元素
public abstract boolean isReadOnly( ):缓冲区是否为只读缓冲区
1.3、存取
Buffer提供了一组获取缓冲区的api:
public abstract byte get( ):获取缓冲区当前位置上的字节,然后增加位置;
public abstract byte get (int index):获取指定索引中的字节;
public abstract ByteBuffer put (byte b):将字节写入当前位置的缓冲区中,并增加位置;
public abstract ByteBuffer put (int index, byte b):将自己写入给定位置的缓冲区中;
Get和put可以是相对的或者是绝对的。在前面的程序列表中,相对方案是不带有索引参数的函数。当相对函数被调用时,位置在返回时前进一。如果位置前进过多,相对运算就会抛出异常。对于put(),如果运算会导致位置超出上界,就会抛出BufferOverflowException异常。对于get(),如果位置不小于上界,就会抛出BufferUnderflowException异常。绝对存取不会影响缓冲区的位置属性,但是如果您所提供的索引超出范围(负数或不小于上界),也将抛出IndexOutOfBoundsException异常。
1.4、翻转
我们已经写满了缓冲区,现在我们必须准备将其清空。我们想把这个缓冲区传递给一个通道,以使内容能被全部写出。但如果通道现在在缓冲区上执行get(),那么它将从我们刚刚插入的有用数据之外取出未定义数据。如果我们将位置值重新设为0,通道就会从正确位置开始获取,但是它是怎样知道何时到达我们所插入数据末端的呢?这就是上界属性被引入的目的。上界属性指明了缓冲区有效内容的末端。我们需要将上界属性设置为当前位置,然后将位置重置为0。
我们可以人工用下面的代码实现: buffer.limit(buffer.position()).position(0);
但这种从填充到释放状态的缓冲区翻转是API设计者预先设计好的,他们为我们提供了一个非常便利的函数: Buffer.flip();
Flip()函数将一个能够继续添加数据元素的填充状态的缓冲区翻转成一个准备读出元素的释放状态。
翻转前:

翻转前缓冲区视图.png
翻转后:
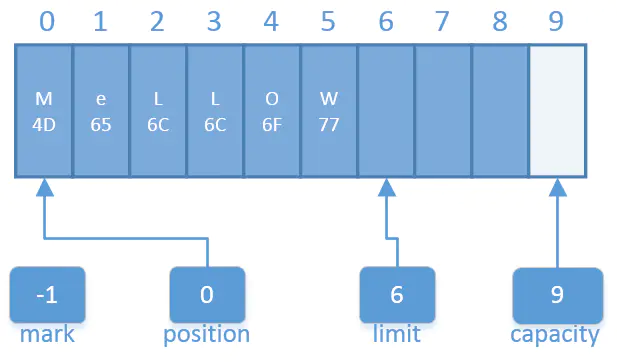
翻转后缓冲区视图.png
flip()源码如下:
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
Rewind()函数与flip()相似,但不影响上界属性。它只是将位置值设回0。您可以使用rewind()后退,重读已经被翻转的缓冲区中的数据。
rewind()源码如下:
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
1.5、释放
如果您接收到一个在别处被填满的缓冲区,您可能需要在检索内容之前将其翻转。例如,如果一个通道的read()操作完成,而您想要查看被通道放入缓冲区内的数据,那么您需要在调用get()之前翻转缓冲区。通道对象在缓冲区上调用put()增加数据;put和read可以随意混合使用。
布尔函数hasRemaining()会在释放缓冲区时告诉您是否已经达到缓冲区的上界。以下是一种将数据元素从缓冲区释放到一个数组的方法。
for (int i = 0; buffer.hasRemaining( ), i++) {
myByteArray [i] = buffer.get( );
}
作为选择,remaining()函数将告知您从当前位置到上界还剩余的元素数目。如果您对缓冲区有专门的控制,这种方法会更高效,因为上界不会在每次循环重复时都被检查。
缓冲区并不是多线程安全的。如果您想以多线程同时存取特定的缓冲区,您需要在存取缓冲区之前进行同步。
一旦缓冲区对象完成填充并释放,它就可以被重新使用了。Clear()函数将缓冲区重置为空状态。它并不改变缓冲区中的任何数据元素,而是仅仅将上界设为容量的值,并把位置设回0。
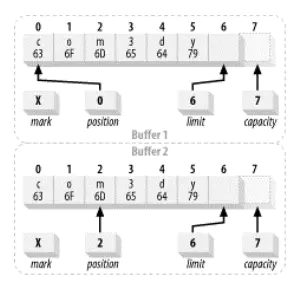
1.6 、压缩
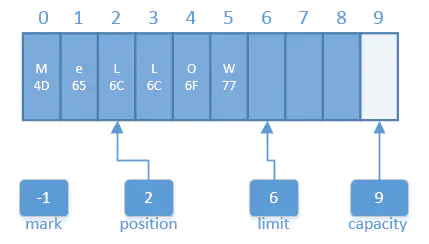
有时,您可能只想从缓冲区中释放一部分数据,而不是全部,然后重新填充。为了实现这一点,未读的数据元素需要下移以使第一个元素索引为0。尽管重复这样做会效率低下,但这有时非常必要,而API对此为您提供了一个compact()函数。这一缓冲区工具在复制数据时要比您使用get()和put()函数高效得多。所以当您需要时,请使用compact()。
compact()之前的缓冲区:
compact()之前缓冲区视图.png
compact()之后的缓冲区:
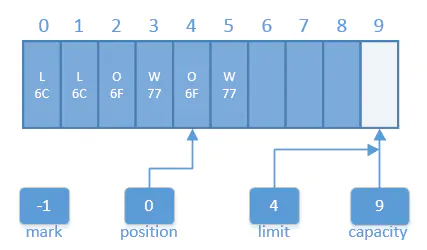
compact之后缓冲区视图.png
- 这里发生了几件事。您会看到数据元素2-5被复制到0-3位置。位置4和5不受影响,但现在正在或已经超出了当前位置,因此是“死的”。它们可以被之后的put()调用重写。
- 位置已经被设为被复制的数据元素的数目。也就是说,缓冲区现在被定位在缓冲区中最后一个“存活”元素后插入数据的位置。
- 上界属性被设置为容量的值,因此缓冲区可以被再次填满。
- 调用compact()的作用是丢弃已经释放的数据,保留未释放的数据,并使缓冲区对重新填充容量准备就绪。
您可以用这种 类似于先入先出(FIFO)队列的方式使用缓冲区。当然也存在更高效的算法(缓冲区移位并不是一个处理队列的非常高效的方法)。但是压缩对于使缓冲区与您从端口中读入的数据(包)逻辑块流的同步来说也许是一种便利的方法。
1.7、标记
标记,使缓冲区能够记住一个位置并在之后将其返回。缓冲区的标记在mark( )函数被调用之前是未定义的,调用时标记被设为当前位置的值。reset( )函数将位置设为当前的标记值。如果标记值未定义,调用reset( )将导致InvalidMarkException异常。一些缓冲区函数会抛弃已经设定的标记(rewind( ),clear( ),以及flip( )总是抛弃标记)。如果新设定的值比当前的标记小,调用limit( )或position( )带有索引参数的版本会抛弃标记。
1.8、比较
有时候比较两个缓冲区所包含的数据是很有必要的。所有的缓冲区都提供了一个常规的equals( )函数用以测试两个缓冲区的是否相等,以及一个compareTo( )函数用以比较缓冲区。
public boolean equals (Object ob)
public int compareTo (Object ob)
如果每个缓冲区中剩余的内容相同,那么equals( )函数将返回true,否则返回false。因为这个测试是用于严格的相等而且是可换向的。前面的程序清单中的缓冲区名称可以颠倒,并会产生相同的结果。
两个缓冲区被认为相等的充要条件是:
- 两个对象类型相同。包含不同数据类型的buffer永远不会相等,而且buffer绝不会等于非buffer对象。
- 两个对象都剩余同样数量的元素。Buffer的容量不需要相同,而且缓冲区中剩余数据的索引也不必相同。但每个缓冲区中剩余元素的数目(从位置到上界)必须相同。
- 在每个缓冲区中应被Get()函数返回的剩余数据元素序列必须一致。
如果不满足以上任意条件,就会返回false。
相等的缓冲区:
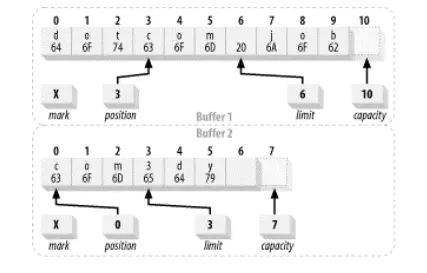
相等的缓冲区.png
不等的缓冲区:
不等的缓冲区.png
缓冲区也支持用compareTo( )函数以词典顺序进行比较。这一函数在缓冲区参数小于,等于,或者大于引用compareTo( )的对象实例时,分别返回一个负整数,0和正整数。这些就是所有典型的缓冲区所实现的java.lang.Comparable接口语义。这意味着缓冲区数组可以通过调用java.util.Arrays.sort()函数按照它们的内容进行排序。
与equals( )相似,compareTo( )不允许不同对象间进行比较。但compareTo( )更为严格:如果您传递一个类型错误的对象,它会抛出ClassCastException异常,但equals( )只会返回false。
比较是针对每个缓冲区内剩余数据进行的,与它们在equals( )中的方式相同,直到不相等的元素被发现或者到达缓冲区的上界。如果一个缓冲区在不相等元素发现前已经被耗尽,较短的缓冲区被认为是小于较长的缓冲区。不像equals( ),compareTo( )不可交换:顺序问题。
1.9、批量移动
buffer API提供了向缓冲区内外批量移动数据元素的函数:
public CharBuffer get (char [] dst) :
public CharBuffer get (char [] dst, int offset, int length)
public final CharBuffer put (char、[] src)
public CharBuffer put (char [] src, int offset, int length)
public CharBuffer put (CharBuffer src)
public final CharBuffer put (String src)
public CharBuffer put (String src, int start, int end)
有两种形式的get( )可供从缓冲区到数组进行的数据复制使用。第一种形式只将一个数组作为参数,将一个缓冲区释放到给定的数组。第二种形式使用offset和length参数来指定目标数组的子区间。这些批量移动的合成效果与前文所讨论的循环是相同的,但是这些方法可能高效得多,因为这种缓冲区实现能够利用本地代码或其他的优化来移动数据。
如果您所要求的数量的数据不能被传送,那么不会有数据被传递,缓冲区的状态保持不变,同时抛出BufferUnderflowException异常。因此当您传入一个数组并且没有指定长度,您就相当于要求整个数组被填充。如果缓冲区中的数据不够完全填满数组,您会得到一个异常。这意味着如果您想将一个小型缓冲区传入一个大型数组,您需要明确地指定缓冲区中剩余的数据长度。
对于以下几种情况的数据复制会发生异常:
- 如果你所要求的数量的数据不能被传送,那么不会有数据被传递,缓冲区的状态保持不变,同时抛出BufferUnderflowException异常。
- 如果缓冲区中的数据不够完全填满数组,你会得到一个异常。这意味着如果你想将一个小型缓冲区传入一个大型数组,你需要明确地指定缓冲区中剩余的数据长度。
2、创建缓冲区
public static CharBuffer allocate (int capacity):创建容量为capacity的缓冲区
public static CharBuffer wrap (char [] array) :将array数组包装成缓冲区
public static CharBuffer wrap (char [] array, int offset, int length) :将array包装为缓冲区,position=offset,limit=lenth
public final boolean hasArray( ) :判断缓冲区底层实现是否为数组
public final char [] array( ) :返回缓冲中的数组
public final int arrayOffset( ) :返回缓冲区数据在数组中存储的开始位置的偏移量;
新的缓冲区是由分配或包装操作创建的。分配操作创建一个缓冲区对象并分配一个私有的空间来储存容量大小的数据元素。包装操作创建一个缓冲区对象但是不分配任何空间来储存数据元素。它使用您所提供的数组作为存储空间来储存缓冲区中的数据元素。
要分配一个容量为100个char变量的Charbuffer:
CharBuffer charBuffer = CharBuffer.allocate (100);
这段代码隐含地从堆空间中分配了一个char型数组作为备份存储器来储存100个char变量。
如果您想提供您自己的数组用做缓冲区的备份存储器,请调用wrap()函数:
char [] myArray = new char [100]; CharBuffer charbuffer = CharBuffer.wrap (myArray);
这段代码构造了一个新的缓冲区对象,但数据元素会存在于数组中。这意味着通过调用put()函数造成的对缓冲区的改动会直接影响这个数组,而且对这个数组的任何改动也会对这个缓冲区对象可见。带有offset和length作为参数的wrap()函数版本则会 构造一个按照您提供的offset和length参数值初始化位置和上界的缓冲区。
通过allocate()或者wrap()函数创建的缓冲区通常都是间接的。间接的缓冲区使用备份数组,像我们之前讨论的,您可以通过上面列出的API函数获得对这些数组的存取权。Boolean型函数hasArray()告诉您这个缓冲区是否有一个可存取的备份数组。如果这个函数的返回true,array()函数会返回这个缓冲区对象所使用的数组存储空间的引用。
如果hasArray()函数返回false,不要调用array()函数或者arrayOffset()函数。如果您这样做了您会得到一个UnsupportedOperationException异常。如果一个缓冲区是只读的,它的备份数组将会是超出上界的,即使一个数组对象被提供给wrap()函数。调用array()函数或者arrayOffset()会抛出一个ReadOnlyBufferException异常,来阻止您得到存取权来修改只读缓冲区的内容。如果您通过其它的方式获得了对备份数组的存取权限,对这个数组的修改也会直接影响到这个只读缓冲区。
最后一个函数,arrayOffset(),返回缓冲区数据在数组中存储的开始位置的偏移量(从数组头0开始计算)。如果您使用了带有三个参数的版本的wrap()函数来创建一个缓冲区,对于这个缓冲区,arrayOffset()会一直返回0,像我们之前讨论的那样。然而,如果您切分了由一个数组提供存储的缓冲区,得到的缓冲区可能会有一个非0的数组偏移量。这个数组偏移量和缓冲区容量值会告诉您数组中哪些元素是被缓冲区使用的。
3、复制缓冲区
缓冲区不限于管理数组中的外部数据,它们也能管理其他缓冲区中的外部数据。当一个管理其他缓冲器所包含的数据元素的缓冲器被创建时,这个缓冲器被称为视图缓冲器。
视图存储器总是通过调用已存在的存储器实例中的函数来创建。使用已存在的存储器实例中的工厂方法意味着视图对象为原始存储器的你部实现细节私有。数据元素可以直接存取,无论它们是存储在数组中还是以一些其他的方式,而不需经过原始缓冲区对象的 get()/put() API。如果原始缓冲区是直接缓冲区,该缓冲区(视图缓冲区)的视图会具有同样的效率优势。
public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable {
public abstract CharBuffer duplicate( );
public abstract CharBuffer asReadOnlyBuffer( );
public abstract CharBuffer slice( );
}
Duplicate():
Duplicate()函数创建了一个与原始缓冲区相似的新缓冲区。两个缓冲区共享数据元素,拥有同样的容量,但每个缓冲区拥有各自的位置,上界和标记属性。对一个缓冲区内的数据元素所做的改变会反映在另外一个缓冲区上。这一副本缓冲区具有与原始缓冲区同样的数据视图。如果原始的缓冲区为只读,或者为直接缓冲区,新的缓冲区将继承这些属性。
asReadOnlyBuffer():
asReadOnlyBuffer() 函数来生成一个只读的缓冲区视图。这与duplicate() 相同,除了这个新的缓冲区不允许使用 put(),并且其 isReadOnly() 函数将会返回true。
如果一个只读的缓冲区与一个可写的缓冲区共享数据,或者有包装好的备份数组,那么对这个可写的缓冲区或直接对这个数组的改变将反映在所有关联的缓冲区上,包括只读缓冲区。
slice():
分割缓冲区与复制相似,但 slice() 创建一个从原始缓冲区的当前 position 开始的新缓冲区,并且其容量是原始缓冲区的剩余元素数量(limit - position)。这个新缓冲区与原始缓冲区共享一段数据元素子序列。分割出来的缓冲区也会继承只读和直接属性。slice() 分割缓冲区:
4、字节缓冲区
4.1、字节缓冲区
ByteBuffer 只是 Buffer 的一个子类,但字节缓冲区有字节的独特之处。字节缓冲区跟其他缓冲区类型最明显的不同在于,它可以成为通道所执行的 I/O 的源头或目标,后面你会发现通道只接收 ByteBuffer 作为参数。
字节是操作系统及其 I/O 设备使用的基本数据类型。当在 JVM 和操作系统间传递数据时,将其他的数据类型拆分成构成它们的字节是十分必要的,系统层次的 I/O 面向字节的性质可以在整个缓冲区的设计以及它们互相配合的服务中感受到。同时,操作系统是在内存区域中进行 I/O 操作。这些内存区域,就操作系统方面而言,是相连的字节序列。于是,毫无疑问,只有字节缓冲区有资格参与 I/O 操作。
public abstract class ByteBuffer
extends Buffer implements Comparable {
public static ByteBuffer allocate (int capacity)
public static ByteBuffer allocateDirect (int capacity)
public abstract boolean isDirect( );
public static ByteBuffer wrap (byte[] array, int offset, int length)
public static ByteBuffer wrap (byte[] array)
public abstract ByteBuffer duplicate( );
public abstract ByteBuffer asReadOnlyBuffer( );
public abstract ByteBuffer slice( );
public final boolean hasArray( )
public final byte [] array( )
public final int arrayOffset( )
public abstract byte get( );
public abstract byte get (int index);
public ByteBuffer get (byte[] dst, int offset, int length)
public ByteBuffer get (byte[] dst, int offset, int length)
public abstract ByteBuffer put (byte b);
public abstract ByteBuffer put (int index, byte b);
public ByteBuffer put (ByteBuffer src)
public ByteBuffer put (byte[] src, int offset, int length)
public final ByteBuffer put (byte[] src)
public final ByteOrder order( )
public final ByteBuffer order (ByteOrder bo)
public abstract CharBuffer asCharBuffer( );
public abstract ShortBuffer asShortBuffer( );
public abstract IntBuffer asIntBuffer( );
public abstract LongBuffer asLongBuffer( );
public abstract FloatBuffer asFloatBuffer( );
public abstract DoubleBuffer asDoubleBuffer( );
public abstract char getChar( );
public abstract char getChar (int index);
public abstract ByteBuffer putChar (char value);
public abstract ByteBuffer putChar (int index, char value);
public abstract short getShort( );
public abstract short getShort (int index);
public abstract ByteBuffer putShort (short value);
public abstract ByteBuffer putShort (int index, short value);
public abstract int getInt( );
public abstract int getInt (int index);
public abstract ByteBuffer putInt (int value);
public abstract ByteBuffer putInt (int index, int value);
public abstract long getLong( );
public abstract long getLong (int index);
public abstract ByteBuffer putLong (long value);
public abstract ByteBuffer putLong (int index, long value);
public abstract float getFloat( );
public abstract float getFloat (int index);
public abstract ByteBuffer putFloat (float value);
public abstract ByteBuffer putFloat (int index, float value);
public abstract double getDouble( );
public abstract double getDouble (int index);
public abstract ByteBuffer putDouble (double value);
public abstract ByteBuffer putDouble (int index, double value);
public abstract ByteBuffer compact( );
public boolean equals (Object ob)
public int compareTo (Object ob)
public String toString( ) public int hashCode( )
}
多字节数值被存储在内存中的方式一般被称为 endian-ness(字节顺序)。如果数字数值的最高字节 - big end(大端),位于低位地址(即 big end 先写入内存,先写入的内存的地址是低位的,后写入内存的地址是高位的),那么系统就是大端字节顺序。如果最低字节最先保存在内存中,那么系统就是小端字节顺序。
ByteBuffer类有所不同:默认字节顺序总是ByteBuffer.BIG_ENDIAN,无论系统的固有字节顺序是什么。Java的默认字节顺序是大端字节顺序,这允许类文件等以及串行化的对象可以在任何JVM中工作。如果固有硬件字节顺序是小端,这会有性能隐患。在使用固有硬件字节顺序时,将ByteBuffer的内容当作其他数据类型存取(很快就会讨论到)很可能高效得多。
ByteBuffer的字符顺序设定可以随时通过调用以ByteOrder.BIG_ENDIAN或ByteOrder.LITTL_ENDIAN为参数的order()函数来改变。
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public final ByteOrder order( )
public final ByteBuffer order (ByteOrder bo)
}
如果一个缓冲区被创建为一个ByteBuffer对象的视图,那么order()返回的数值就是视图被创建时其创建源头的ByteBuffer的字节顺序设定。视图的字节顺序设定在创建后不能被改变,而且如果原始的字节缓冲区的字节顺序在之后被改变,它也不会受到影响。
4.2、直接缓冲区
内核空间(与之相对的是用户空间,如 JVM)是操作系统所在区域,它能与设备控制器(硬件)通讯,控制着用户区域进程(如 JVM)的运行状态。最重要的是,所有的 I/O 都直接(物理内存)或间接(虚拟内存)通过内核空间。
当进程(如 JVM)请求 I/O 操作的时候,它执行一个系统调用将控制权移交给内核。当内核以这种方式被调用,它随即采取任何必要步骤,找到进程所需数据,并把数据传送到用户空间你的指定缓冲区。内核试图对数据进行高速缓存或预读取,因此进程所需数据可能已经在内核空间里了。如果是这样,该数据只需简单地拷贝出来即可。如果数据不在内核空间,则进程被挂起,内核着手把数据读进内存。
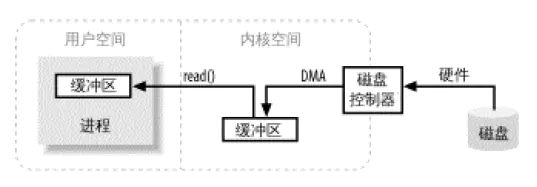
缓冲区操作.png
从图中你可能会觉得,把数据从内核空间拷贝到用户空间似乎有些多余。为什么不直接让磁盘控制器把数据送到用户空间的缓冲区呢?首先,硬件通常不能直接访问用户空间。其次,像磁盘这样基于块存储的硬件设备操作的是固定大小的数据块,而用户进程请求的可能是任意大小的或非对齐的数据块。在数据往来于用户空间与存储设备的过程中,内核负责数据的分解、再组合工作,因此充当着中间人的角色。
因此,操作系统是在内存区域中进行 I/O 操作。这些内存区域,就操作系统方面而言,是相连的字节序列,这也意味着I/O操作的目标内存区域必须是连续的字节序列。在 JVM中,字节数组可能不会在内存中连续存储(因为 JAVA 有 GC 机制),或者无用存储单元(会被垃圾回收)收集可能随时对其进行移动。
出于这个原因,引入了直接缓冲区的概念。直接字节缓冲区通常是 I/O 操作最好的选择。非直接字节缓冲区(即通过 allocate() 或 wrap() 创建的缓冲区)可以被传递给通道,但是这样可能导致性能损耗。通常非直接缓冲不可能成为一个本地 I/O 操作的目标。
如果你向一个通道中传递一个非直接 ByteBuffer 对象用于写入,通道可能会在每次调用中隐含地进行下面的操作:
- 创建一个临时的直接ByteBuffer对象。
- 将非直接缓冲区的内容复制到临时缓冲中。
- 使用临时缓冲区执行低层次I/O操作。
- 临时缓冲区对象离开作用域,并最终成为被回收的无用数据。
这可能导致缓冲区在每个I/O上复制并产生大量对象,而这种事都是我们极力避免的。不过,依靠工具,事情可以不这么糟糕。运行时间可能会缓存并重新使用直接缓冲区或者执行其他一些聪明的技巧来提高吞吐量。如果您仅仅为一次使用而创建了一个缓冲区,区别并不是很明显。另一方面,如果您将在一段高性能脚本中重复使用缓冲区,分配直接缓冲区并重新使用它们会使您游刃有余。
直接缓冲区时I/O的最佳选择,但可能比创建非直接缓冲区要花费更高的成本。直接缓冲区使用的内存是通过调用本地操作系统方面的代码分配的,绕过了标准JVM堆栈。建立和销毁直接缓冲区会明显比具有堆栈的缓冲区更加破费,这取决于主操作系统以及JVM实现。直接缓冲区的内存区域不受无用存储单元收集支配,因为它们位于标准JVM堆栈之外。
使用直接缓冲区或非直接缓冲区的性能权衡会因JVM,操作系统,以及代码设计而产生巨大差异。通过分配堆栈外的内存,您可以使您的应用程序依赖于JVM未涉及的其它力量。当加入其他的移动部分时,确定您正在达到想要的效果。我以一条旧的软件行业格言建议您:先使其工作,再加快其运行。不要一开始就过多担心优化问题;首先要注重正确性。JVM实现可能会执行缓冲区缓存或其他的优化,5这会在不需要您参与许多不必要工作的情况下为您提供所需的性能。
直接ByteBuffer是通过调用具有所需容量的ByteBuffer.allocateDirect()函数产生的,就像我们之前所涉及的allocate()函数一样。注意用一个wrap()函数所创建的被包装的缓冲区总是非直接的。
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public static ByteBuffer allocate (int capacity)
public static ByteBuffer allocateDirect (int capacity)
public abstract boolean isDirect( );
}
所有的缓冲区都提供了一个叫做isDirect()的boolean函数,来测试特定缓冲区是否为直接缓冲区。虽然ByteBuffer是唯一可以被直接分配的类型,但如果基础缓冲区是一个直接ByteBuffer,对于非字节视图缓冲区,isDirect()可以是true。
4.3、视图缓冲区
视图缓冲区通过已存在的缓冲区对象实例的工厂方法来创建。这种视图对象维护它自己的属性,容量,位置,上界和标记,但是和原来的缓冲区共享数据元素。但是ByteBuffer类允许创建视图来将byte型缓冲区字节数据映射为其它的原始数据类型。例如,asLongBuffer()函数创建一个将八个字节型数据当成一个long型数据来存取的视图缓冲区。
下面列出的每一个工厂方法都在原有的ByteBuffer对象上创建一个视图缓冲区。调用其中的任何一个方法都会创建对应的缓冲区类型,这个缓冲区是基础缓冲区的一个切分,由基础缓冲区的位置和上界决定。新的缓冲区的容量是字节缓冲区中存在的元素数量除以视图类型中组成一个数据类型的字节数。在切分中任一个超过上界的元素对于这个视图缓冲区都是不可见的。视图缓冲区的第一个元素从创建它的ByteBuffer对象的位置开始(positon()函数的返回值)。具有能被自然数整除的数据元素个数的视图缓冲区是一种较好的实现。
public abstract class ByteBuffer
extends Buffer implements Comparable {
// This is a partial API listing
public abstract CharBuffer asCharBuffer( );
public abstract ShortBuffer asShortBuffer( );
public abstract IntBuffer asIntBuffer( );
public abstract LongBuffer asLongBuffer( );
public abstract FloatBuffer asFloatBuffer( );
public abstract DoubleBuffer asDoubleBuffer( );
}
一旦您得到了视图缓冲区,您可以用duplicate(),slice()和asReadOnlyBuffer()函数创建进一步的子视图。
无论何时一个视图缓冲区存取一个ByteBuffer的基础字节,这些字节都会根据这个视图缓冲区的字节顺序设定被包装成一个数据元素。当一个视图缓冲区被创建时,视图创建的同时它也继承了基础ByteBuffer对象的字节顺序设定。这个视图的字节排序不能再被修改。
当直接从byte型缓冲区中采集数据时,视图换冲突拥有提高效率的潜能。如果这个视图的字节顺序和本地机器硬件的字节顺序一致,低等级的(相对于高级语言而言)语言的代码可以直接存取缓冲区中的数据值,而不是通过比特数据的包装和解包装过程来完成。
4.4、数据元素视图
ByteBuffer类提供了一个不太重要的机制来以多字节数据类型的形式存取byte数据组。ByteBuffer类为每一种原始数据类型提供了存取的和转化的方法:
public abstract class ByteBuffer extends Buffer implements Comparable {
public abstract char getChar( );
public abstract char getChar (int index);
public abstract short getShort( );
public abstract short getShort (int index);
public abstract int getInt( );
public abstract int getInt (int index);
public abstract long getLong( );
public abstract long getLong (int index);
public abstract float getFloat( );
public abstract float getFloat (int index);
public abstract double getDouble( );
public abstract double getDouble (int index);
public abstract ByteBuffer putChar (char value);
public abstract ByteBuffer putChar (int index, char value);
public abstract ByteBuffer putShort (short value);
public abstract ByteBuffer putShort (int index, short value);
public abstract ByteBuffer putInt (int value);
public abstract ByteBuffer putInt (int index, int value);
public abstract ByteBuffer putLong (long value);
public abstract ByteBuffer putLong (int index, long value);
public abstract ByteBuffer putFloat (float value);
public abstract ByteBuffer putFloat (int index, float value);
public abstract ByteBuffer putDouble (double value);
public abstract ByteBuffer putDouble (int index, double value);
}
这些函数从当前位置开始存取ByteBuffer的字节数据,就好像一个数据元素被存储在那里一样。根据这个缓冲区的当前的有效的字节顺序,这些字节数据会被排列或打乱成需要的原始数据类型。
这段代码:
int value = buffer.getInt( );
会返回一个由缓冲区中位置1-4的byte数据值组成的int型变量的值。实际的返回值取决于缓冲区的当前的比特排序(byte-order)设置。更具体的写法是:
int value = buffer.order (ByteOrder.BIG_ENDIAN).getInt( );
这将会返回值0x3BC5315E,同时:
int value = buffer.order (ByteOrder.LITTLE_ENDIAN).getInt( );
返回值0x5E31C53B。
这些函数返回的元素不需要被任何特定模块界限所限制6。数值将会从以缓冲区的当前位置开始的字节缓冲区中取出并组合,无论字组是否对齐。这样的做法是低效的,但是它允许对一个字节流中的数据进行随机的放置。对于从二进制文件数据或者包装数据成特定平台的格式或者导出到外部的系统,这将是非常有用的。
Put函数提供与get相反的操作。原始数据的值会根据字节顺序被分拆成一个个byte数据。如果存储这些字节数据的空间不够,会抛出BufferOverflowException。每一个函数都有重载的和无参数的形式。重载的函数对位置属性加上特定的字节数。然后无参数的形式则不改变位置属性。
5、Buffer类继承关系

作者:桥头放牛娃
链接:https://www.jianshu.com/p/49d20a7547f6
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 5703
5703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









