






自我总结-KMP算法
发表博客的起先目的是记录自己所学的(其实大部分学习源还是网上的各种各样的资源),表达得可能不是很准确。–算了,反正也没人看。或许有人看呢?(目瞪口呆)
- 什么是KMP算法?算法解决的问题是?
- 问题解决的暴力方式
- 暴力方式下的思考与KMP算法的诞生
- KMP算法的核心数据结构-next数组
- 什么是next数组
- 如何计算next数组
1. 什么是KMP算法?算法解决的问题是?
KMP算法是用于解决快速寻找字符串匹配问题(即关键字搜索)
这里有两个概念,待匹配字符串(称为母串)和关键字串(子串)
注:为什么叫KMP算法?因为该算法是由D.E.Knuth与V.R.Pratt和J.H.Morris同时发现
2. 问题解决的暴力方式
好的算法也是由低级解决策略一步一步优化而成的。
先按照自己的思路,看看字符串匹配应该如何解决。
最容易想到的一种策略如下:
用i和j分别记录当前正在匹配的母串(P)下标和子串(T)下标
①.当P[i]==T[j]时,
if(j到达T的末位时){
宣布匹配结束(P[i-j]~P[i]与T匹配);//congratulation
}else{
j++;
}
if(i到达P的末位时){
T还没到末位,P就到末位,说明匹配失败
}else{
i++;
}②.当P[i]!=T[j]时,
j=0;//子串回到最初的起点
i=i-j+1;//母串回到最初的起点进一图示如下:
图一
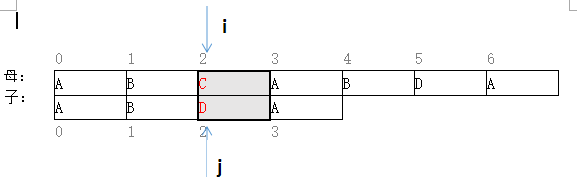
起点:P[0]~T[0]
不同点:P[2]~T[2]
->新起点:P[i-j+1]=P[1]~T[0]
3.暴力方式下的思考与KMP算法的诞生
暴力方式的基本思路是:好,匹配就匹配;匹配失败我就会到让母串之前匹配的起点加一,子串重回起点,重新开始匹配。绝不放过任何一个母串字符
但事实上,当匹配到P[i]!=T[j]时,至少我们可以肯定P[i-j]~P[i-1]==T[0]~T[j-1]。(亲爱的KMP算法来了)如果T是一个对称度很高的字符串,那么完全没有必要将P回退到起点进一,完全可以利用对称性,将j设置到某个合适的位置即可。(如果没有对称性,更可跳过更多冗余的字符判断,如图一和图四)
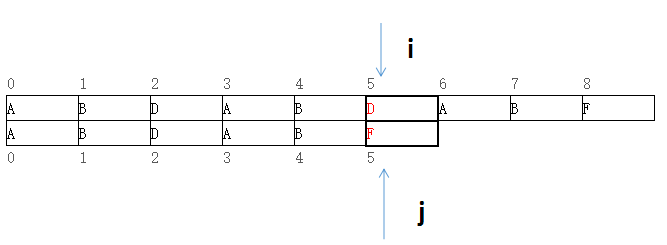
图示如下:
图二
图三
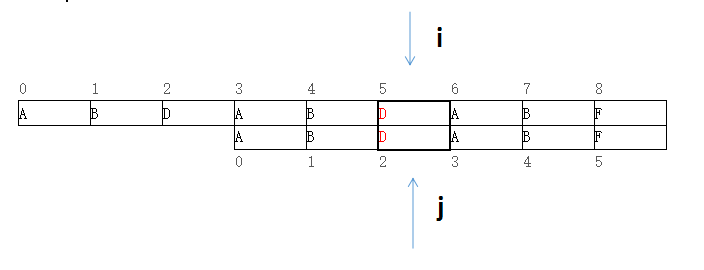
当图二P[i=5]!=T[j=5]时,只要将j设为2即可
回头说说图一,当图一P[i=2]!=T[j=2]时,只要将j设为0即可,如图四
图四
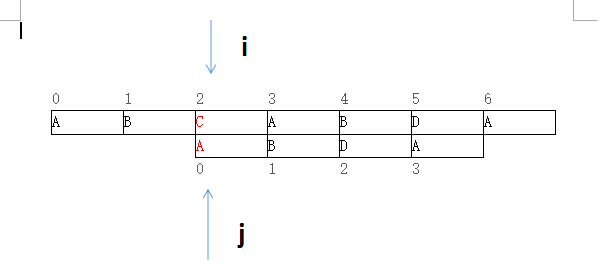
那么问题来了,什么位置才是合适的,如果匹配到P[i]!=T[j]时,j应该等于多少?这个问题引出了KMP算法的核心数据结构,next数组
4. KMP算法的核心数据结构-next数组
4.1 什么是next数组
next数组是相对于匹配子串而言的,体现了匹配子串的对称性。
假设T[0~7],则next[5]则说明,当匹配到j=5时,若匹配不成功,j应该移动到next[5]
4.2 如何计算next数组
先下一个“定论”或者说是假设:next[j]的值与next[j-1]相关。
为什么?做个比较肤浅的回答。因为当匹配子串在j处匹配不成功时,j的下个位置看的是谁的情况?其实,看的是j之前字符串,而不是j的本身
再说一个可能表达起来不是很直观的我的个人观点:next数组是一种链式关系的体现(实际计算next数组时,可能就会有这种感受)
前面的假设是为了解释为什么会使用数学归纳法来计算next数组,如果一开始秒想到数学归纳法,前面的假设可以完全忽略。
数学归纳法计算next数组:
首先,来看一下最简单的情况。j=0时,next[j]是多少?
由于j=0时,说明已经是匹配子串的第一字符,连第一个字符都不匹配,那么i应该+1,j还是应该为0,->将next[0]设为-1来表达这种情况(这是比较特殊的情况)
那j=1时呢?
第二个字符不匹配,那只能那第一个字符来匹配看看咯,next[1]=0
当j=k时,假设next[k-1]=w已经知道:
while(w!=-1){
if(T[w]==T[k-1]){
next[k]=w+1;
break;
}else{
w=next[w];
}
}
if(w==-1)
next[k]=0;图待上
实例待上
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









