








文本文件
打开文件
-
语法:
open(file[mode=type,encoding=编码]),打开文件,返回一个文件对象-
file,待操作的文件,不能传入一个目录
-
mode=type,指定打开文件的方式,默认为只读模式
- r,只读,如果指定的文件不存在,提示错误
- w,覆盖写入,如果指定的文件的文件不存在,系统会自动创建该文件
- a,追加写入,如果指定的文件的文件不存在,系统会自动创建该文件
- b,表示二进制,一般用于图片类文件操作
-
encoding=编码,指定打开文件的编码方式
-
-
返回文件对象的常用方法
- closed,检查文件是否为关闭状态,如果是返回True,否则返回False
- close(),关闭文件
读文件
- 需要使用只读方式打开文件
- read(),将文件的所有内容读取到一个字符串中
- readline(),逐行读取文件内容,每调用一次读取一行,将读取的内容保存在字符串中
- readlines(),将文件的所有内容读取到一个列表中,文件中的每一行内容保存为一个字符串,作为列表的一个元素
写文件
- 需要使用w或者a方式打开文件
- write(s),将一个字符串写入文件
- writelines(iter),将一个可迭代对象所有元素写入文件
例1:在一个文件中保存有学生的信息,内容如下,要求统计出每个学生的总成绩并添加到文件中
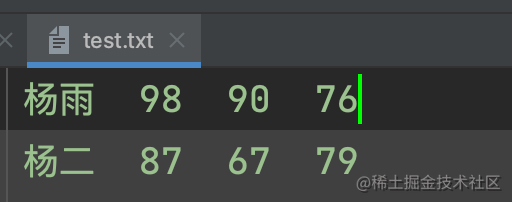
# 读取每个学生的成绩信息
f = open('./test.txt',mode='r')
info = f.readlines() # ['杨雨 98 90 76\n', '杨二 87 67 79']
f.close()
new = [] # 保存处理后的成绩信息
# 分别计算每个学生的总分,并添加到列表中
for i in info:
tmp = i.strip().split() # ['杨雨', '98', '90', '76']
# print(tmp)
s = int(tmp[1])+int(tmp[2])+int(tmp[3]) # 计算总分
tmp.append(str(s)) # ['杨雨', '98', '90', '76', '264']
# print(tmp)
new.append('\t'.join(tmp)+'\n') # ['杨雨\t98\t90\t76\t264\n', '杨二\t87\t67\t79\t233\n']
# print(new)
# 将处理后的数据写入文件
with open('./test.txt','w') as f: # with语句,实现自动关闭文件
f.writelines(new)
Excel文件
读文件
-
安装模块:
xlrd,读取xls格式文件内容 -
pip install xlrd
使用步骤
-
打开文件:
open_workbook(file),返回一个文件对象 -
获取指定的sheet
-
sheets(),返回文件中所有的sheet对象 -
sheet_names(),返回文件中所有的sheet名称 -
sheet_by_name(name),通过名称获取sheet -
sheet_by_index(index),通过索引获取sheet
-
-
获取数据
-
行
nrows,返回行数row_values(n),获取指定行数据
-
列
ncols,返回列数col_values(n),取指定列的数据
-
单元格
cell_values(row,col),获取指定单元格数据
-
例:
import xlrd
wb = xlrd.open_workbook('/Users/my/Desktop/ttt.xls') # 打开文件
print(wb.sheet_names())
sh = wb.sheet_by_name('a2') # 获取指定sheet
print(sh.nrows) # 获取行数
print(sh.ncols) # 获取列数
print(sh.row_values(3)) # 获取指定行数据
print(sh.col_values(2)) # 获取指定列数据
for i in range(sh.nrows):
print(sh.row_values(i))
print(sh.cell_value(0,0)) # 获取指定单元格数据
写文件
-
写文件
-
模块:xlwt,只能对xls格式文件操作
-
pip install xlwt-
使用步骤:
- 创建工作簿:
bk = Workbook(),返一个对象 - 创建工作表:
sh = bk.add_sheet(名称) - 写入数据:
sh.write(row,col,value) - 保存工作簿:
bk.save(path)
- 创建工作簿:
-
例
import xlwt
bk = xlwt.Workbook(encoding='utf8') # 创建工作簿
sh = bk.add_sheet('用户信息') # 添加工作表
sh.write(0,0,'账号') # 写入信息
sh.write(0,1,'密码')
sh.write(0,2,'姓名')
sh.write(0,3,'余额')
info = [['1001','123123','张三',2000],
['1002','123123','张四',2000],
['1003','123123','张无',2000],
['1004','123123','张期',2000]]
for i in range(1,len(info)+1):
for j in range(len(info[i-1])):
sh.write(i,j,info[i-1][j])
bk.save('/Users/my/Desktop/account.xls') # 保存
xlsx文件读写
-
模块:openpyxl,实现对xlsx格式文件的读写操作
-
方法
-
创建工作簿:
wb = openpyxl.Workbook() -
创建工作表:
sh = wb.create_sheet('名称',索引) -
加载文件:
wb = openpyxl.load_workbook(path) -
获取工作表名称:
sheetnames -
获取工作表:
wb.get_sheet_by_name(名称) -
获取内容:
sh.cell('A1').value,获取单元格A1的内容sh['A1':'D6'],获取A1到D6间的所有内容sh[1],获取第一行内容sh[1:3],获取第一行到第三行的内容sh['A'],获取第一列内容
-
写入数据:
sh.cell(单元格).value = 'xxx' -
保存:
wb.save(path)
-
csv文件
-
操作csv格式文件
-
模块:csv,内置模块
-
使用步骤:
-
读取文件
- 打开文件:
with open(file) as f: csv.reader(f),返回一个对象,将文件中每一行的内容读取到一个列表中
- 打开文件:
-
import csv
with open('/Users/my/Desktop/account.csv') as f:
r = csv.reader(f) # 读取文件内容
print(list(r)) # 使用list方法将csv对象转换为列表
# [['账号', '密码', '姓名', '余额'], ['1001', '123123', '张三', '2000']]
csv.DictWriter(f,fieldnames=fn),返回一个writer对象,用于写入字典
import csv
with open('/Users/my/Desktop/account.csv') as f:
r = csv.DictReader(f) # 读取文件内容
print(list(r)) # 使用list方法将csv对象转换为列表
# [{'账号': '1001', '密码': '123123', '姓名': '张三', '余额': '2000'}]
写文件
-
打开文件:
with open(file,'a'/'w',neline='') as f:- 以
a或者w方式打开文件 neline='',用于消除空行
- 以
-
csv.writer(f),返回一个writer对象,用于写入列表
import csv
with open('/Users/my/Desktop/account.csv','a',newline='') as f:
t = csv.writer(f)
t.writerow(['1006', '123456', '王五', '2000'])
csv.DictReader(f),返回一个对象,将文件中每一行的内容读取到一个字典中
import csv
with open('/Users/my/Desktop/account.csv','a',newline='') as f:
fn = ['账号', '密码', '姓名', '余额'] # 表头
t = csv.DictWriter(f,fieldnames=fn) # 创建writer对象,指定表头
# 写入数据
t.writerow({'账号': '1007', '密码': '123123', '姓名': '赵静宇', '余额': '2000'})
















 2082
2082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











