







目录
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言
词法分析:
在机器学习中,文本分析的词法分析通常涉及使用统计和机器学习技术来从文本中提取词汇信息,并将文本切分成有意义的词语。这个过程通常被称为分词(tokenization)。以下是一些常见的机器学习方法在文本分析中的词法分析应用:
-
基于统计的分词方法:
- 基于频率统计的方法:根据词在文本中的频率信息,将文本分割成词语。常见的方法包括基于词频的分割、基于字符频率的分割等。
- 基于信息熵的方法:利用信息熵原理,将文本划分成最小熵的词组合。常见的方法包括最大熵模型、信息熵分割等。
-
基于机器学习的分词方法:
- 条件随机场(CRF):CRF是一种序列标注模型,可以将文本分词任务视为一个序列标注问题,通过训练CRF模型来预测每个字符的词边界。
- 隐马尔可夫模型(HMM):HMM也可以用于文本分词,将文本视为一个观测序列,通过训练HMM模型来估计最有可能的词边界。
-
深度学习方法:
- 循环神经网络(RNN)和长短期记忆网络(LSTM):RNN和LSTM是适用于序列数据的深度学习模型,在文本分词中可以用于学习文本序列中的词边界。
- Transformer模型:Transformer是一种基于自注意力机制的深度学习模型,可以学习文本序列中的全局依赖关系,也可以用于文本分词任务。
以上方法都可以应用于文本分析中的词法分析任务,根据任务需求和数据特点选择合适的方法。在实践中,通常需要大量的标注好的训练数据来训练模型,并且需要进行模型选择和调优以获得最佳的性能。
词义消歧:
词义消歧(Word Sense Disambiguation,简称WSD)是自然语言处理和本体论中的一个核心问题。它指的是在特定的语境中,识别出某个歧义词的正确含义。歧义词是指有多个含义的词语,在不同的语境中可能有不同的含义。词义消歧的目的是根据上下文信息,确定出歧义词在特定语境中的具体含义。
解决词义消歧问题的方法多种多样,以下是一些主要方法:
- 利用语境消除歧义:通过给歧义句增设上下文,创设一个具体的语言环境,以消除歧义。例如,“我去上课”可以改为“我去听老师上课”或“我去给学生上课”。
- 换用或添加适当的词语:如果造成歧义的原因是词语的多义性,将容易产生歧义的词语换成意义单一的词语,或添加一些虚词使层次清晰,从而消除歧义。例如,“我要炒肉丝”可以改为“我要去炒肉丝”或“我要吃炒肉丝”。
- 调整词语顺序:有时把句内有关词语的位置改动一下,也可以消除歧义。例如,“这个人谁也不认识”可以改为“谁也不认识这个人”或“这个人不认识谁”。
- 利用语音手段:词语的读音不同,意义就可能不同;语言停顿不同,句义也就不同。因此,可以通过语音手段来消除歧义。
此外,随着技术的发展,词义消歧问题也可以通过机器学习、深度学习等算法进行自动处理。这些方法通常基于大规模的语料库进行训练,学习词语在不同上下文中的含义,并据此进行词义消歧。
总之,词义消歧是自然语言处理领域中的一个重要问题,具有广泛的应用,如机器翻译、问答系统、语音识别、信息检索等。通过提高词义消歧的准确性,可以进一步提高这些应用的性能和效率。
句法分析:
句法分析,它主要对句子或短语的结构进行分析,以确定构成句子的各个词、短语等之间的相互关系以及各自在句子中的作用。这种分析不仅有助于我们理解句子的结构,还能进一步揭示句子所传达的深层含义。
句法分析的过程通常包括对句子成分的识别,如主语、谓语、宾语、定语和状语等。这些成分在句子中扮演着不同的角色,共同构成了句子的完整意义。例如,主语通常表示句子所描述的主体,谓语则描述主语的行为或状态,而宾语则是行为的对象。通过识别这些成分,我们可以更清晰地理解句子的结构和含义。
此外,句法分析还关注句子中词语之间的语法关系。这些关系包括词与词之间的依存关系、句子的层次结构等。通过分析这些关系,我们可以进一步理解句子的语法结构和语义信息。
句法分析在自然语言处理中有广泛的应用。例如,在机器翻译中,句法分析可以帮助系统更好地理解源语言和目标语言之间的语法结构和语义关系,从而提高翻译的质量和准确性。在信息抽取中,句法分析可以帮助确定实体之间的关系,从而提供更准确的信息抽取结果。在问答系统中,句法分析可以帮助系统理解用户提问的句子结构和语法规则,从而更准确地回答用户的问题。
在句法分析领域,有多种方法和技术被用于分析和理解句子的结构。这些方法和技术在不断发展和完善,以应对自然语言处理中的各种挑战。
句法分析常用方法:
- 基于规则的方法:
- 原理:基于规则的方法依赖于语言学家或专家手工编写的语法规则集。这些规则描述了语言中可能的句法结构,并用于指导句法分析的过程。
- 实现过程:分析器会根据这些规则对输入的句子进行匹配和推导,生成符合这些规则的句法结构。通常,这种方法需要构建一个语法规则库,并设计一个解析算法来应用这些规则。
- 移进-归约方法(Shift-Reduce Parsing):
- 原理:移进-归约是自底向上语法分析的一种形式,它使用一个栈来保存文法符号,并用一个输入缓冲区来存放其余符号。在解析过程中,分析器不断地从输入缓冲区中移进符号到栈中,并根据文法规则进行归约操作,即将栈顶的某些符号替换为新的符号。
- 实现过程:分析器从输入句子的第一个词开始,依次移进符号到栈中。当栈顶的符号与输入缓冲区中的符号符合某条归约规则时,就进行归约操作。这个过程一直持续到所有的符号都被处理完,最终栈中剩下的就是句子的句法结构。
- 线图分析法(Chart Parsing):
- 原理:线图分析法是基于CFG(上下文无关文法)规则的分析方法。它使用一组节点和边来表示输入字符串的句法结构。每个节点对应着输入字符串中的一个词或短语,而边则表示这些词或短语之间的关系。
- 实现过程:分析器从输入句子的第一个词开始,逐步构建线图。在构建过程中,分析器会尝试将句子中的词或短语组合成更大的结构,并在线图中添加相应的节点和边。这个过程一直持续到存在一个边可以覆盖线图中所有的节点,这时就得到了句子的句法结构。
- 依存句法分析:
- 原理:依存句法分析基于词语之间的依存关系,即一个词依赖于另一个词而存在。它旨在揭示句子中词语之间的主谓、动宾、定中等关系。
- 实现过程:分析器首先识别出句子中的核心词(通常是主语或谓语),然后找出与核心词有依存关系的词,并确定这些依存关系的类型。这个过程递归地进行,直到所有的词都被处理完,最终形成一个依存关系树。
语义分析:
语言模型的句法分析是利用统计语言模型(如$n$-gram模型)或基于深度学习的语言模型(如循环神经网络、Transformer等)来进行句法分析的一种方法。其原理和分析过程可以概括如下:
-
语言模型简介:
- 语言模型是用来计算一个句子序列在语言中出现的概率的模型。它可以估计一个句子在语言中的流畅度和合理性。传统的语言模型可以基于统计方法(如$n$-gram模型)或基于深度学习方法进行建模。
-
句法分析任务:
- 在句法分析中,我们关注句子中词语之间的句法结构关系,通常表示为一个树状结构,即句法树。句法分析的目标是根据句子中词语的语法属性和上下文信息,构建句子的合理句法树,以表示句子中的语法结构。
-
基于语言模型的句法分析:
- 在基于语言模型的句法分析中,我们利用语言模型来评估不同句法树的合理性,选择最可能的句法树作为最终的分析结果。具体过程如下:
- 句法树构建:首先根据语法规则和词性标注信息构建候选的句法树。这些句法树可能包含不同的句法结构和组合方式。
- 句法树评分:然后利用语言模型来为每个句法树计算一个概率分数,表示句子在语言模型下出现的概率。这个概率分数可以通过统计语言模型(如$n$-gram模型)或基于深度学习的语言模型来计算。
- 选择最优句法树:最后,选择具有最高概率分数的句法树作为最终的句法分析结果。这个过程可以通过搜索算法(如动态规划算法、贪婪搜索算法等)来实现。
- 在基于语言模型的句法分析中,我们利用语言模型来评估不同句法树的合理性,选择最可能的句法树作为最终的分析结果。具体过程如下:
-
基于深度学习的句法分析:
- 近年来,基于深度学习的句法分析方法得到了广泛应用。这些方法通常使用循环神经网络(RNN)、长短期记忆网络(LSTM)、Transformer等模型来建模句子中词语之间的依赖关系,并直接输出句子的句法结构。这种方法不需要显式地构建候选的句法树,而是通过端到端的方式直接学习句法结构。
总的来说,语言模型的句法分析通过利用语言模型评估不同句法结构的合理性,选择最可能的句法结构作为句法分析结果。这种方法结合了语言模型的能力和句法分析的需求,能够在一定程度上提高句法分析的准确性和效率。
文本分析应用
1、文本分类:
基于Python的文本分类实现过程。在这个案例中,我们将使用朴素贝叶斯分类器来对文本进行分类。我们将使用一个名为20 Newsgroups的文本数据集,其中包含20个不同主题的新闻组文章。我们将尝试将这些文章分为不同的主题类别。

设计过程:
数据收集与预处理:
- 我们首先需要从20 Newsgroups数据集中下载数据,并对数据进行预处理。预处理步骤可能包括移除停用词、词干提取、标记化等。
特征提取:
- 我们将文本数据转换为特征向量,以便输入到分类器中进行训练和预测。常用的特征提取方法包括词袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)等。
建立分类器模型:
- 我们将选择朴素贝叶斯分类器作为我们的模型。我们可以使用scikit-learn库中的MultinomialNB来构建朴素贝叶斯分类器。
模型训练:
- 使用训练数据对分类器模型进行训练。
模型评估:
- 使用测试数据对训练好的模型进行评估,计算分类器的准确率、精确率、召回率等指标。
模型应用:
- 最后,我们可以使用训练好的模型来对新的文本进行分类。
代码实现:
# 1. 数据收集与预处理
newsgroups_data = fetch_20newsgroups(subset='all')
X = newsgroups_data.data
y = newsgroups_data.target
# 2. 特征提取
vectorizer = TfidfVectorizer(max_features=6000) # 使用TF-IDF进行特征提取,最多保留5000个特征词
X_vectorized = vectorizer.fit_transform(X)
# 3. 建立分类器模型
classifier = MultinomialNB() # 使用朴素贝叶斯分类器作为模型
# 4. 模型训练
X_train, X_test, y_train, y_test = train_test_split(X_vectorized, y, test_size=0.2, random_state=42) # 将数据划分为训练集和测试集
classifier.fit(X_train, y_train) # 在训练集上训练模型
# 5. 模型评估
y_pred = classifier.predict(X_test) # 在测试集上进行预测
accuracy = accuracy_score(y_test, y_pred) # 计算分类准确率
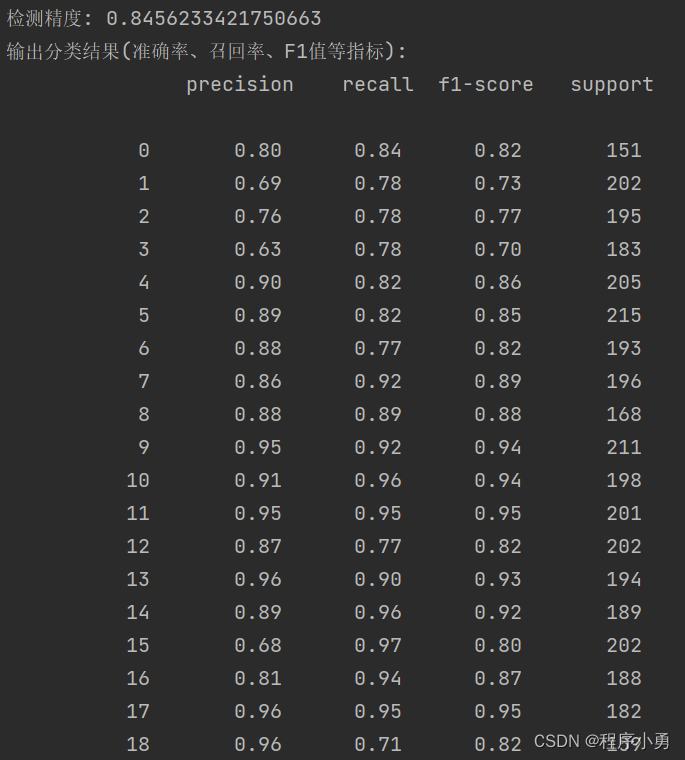
print("检测精度:", accuracy)
print("输出分类结果(准确率、召回率、F1值等指标):\n", classification_report(y_test, y_pred)) # 输出分类报告
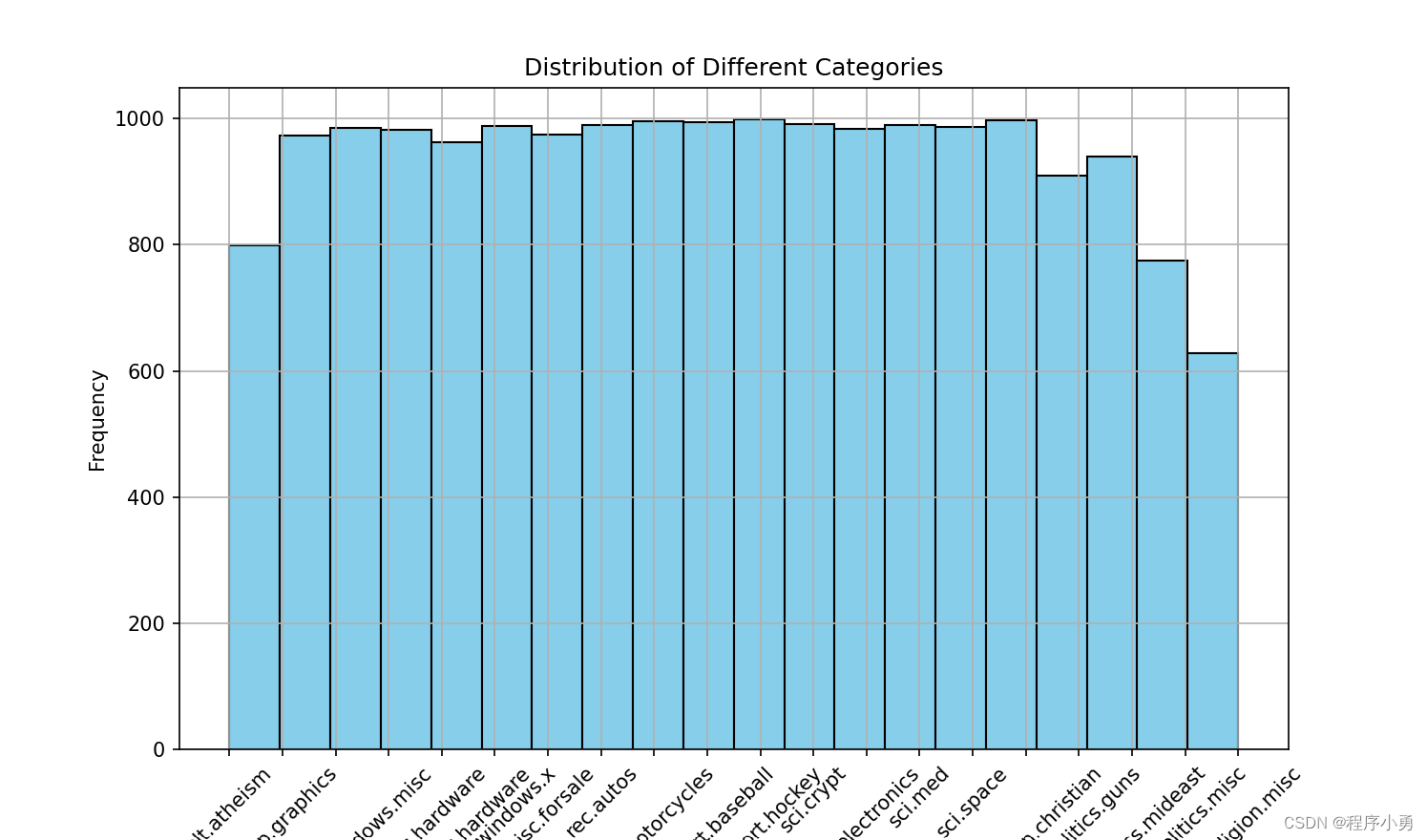
绘制了20 Newsgroups数据集中不同类别的分布情况的直方图,以展示数据集的类别分布情况。接着,它计算了特征提取后的词频信息,选取了前20个TF-IDF值最高的词语,并绘制了词语的TF-IDF值条形图。通过这样的可视化方式,我们可以更好地理解数据集的特征信息和类别分布情况。
plt.figure(figsize=(10, 6))
plt.hist(y, bins=20, color='skyblue', edgecolor='black')
plt.xlabel('Category')
plt.ylabel('Frequency')
plt.title('Distribution of Different Categories')
plt.xticks(range(20), newsgroups_data.target_names, rotation=45)
plt.grid(True)
plt.show()
# 可视化特征提取后的词频信息
feature_names = vectorizer.get_feature_names()
tfidf_values = X_vectorized.toarray().sum(axis=0) # 计算每个词的TF-IDF值总和
sorted_indices = tfidf_values.argsort()[::-1] # 按TF-IDF值排序
top_features = [feature_names[i] for i in sorted_indices[:20]] # 选择前20个TF-IDF值最高的词语
plt.figure(figsize=(10, 6))
plt.barh(range(20), tfidf_values[sorted_indices[:20]], color='skyblue', edgecolor='black')
plt.xlabel('TF-IDF Value')
plt.ylabel('Word')
plt.title('Top 20 Words with Highest TF-IDF Values')
plt.yticks(range(20), top_features)
plt.gca().invert_yaxis() # 反转y轴,使得词频值高的词语在顶部显示
plt.grid(True)
plt.show()完整代码:
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 1. 数据收集与预处理
newsgroups_data = fetch_20newsgroups(subset='all')
X = newsgroups_data.data
y = newsgroups_data.target
# 2. 特征提取
vectorizer = TfidfVectorizer(max_features=6000) # 使用TF-IDF进行特征提取,最多保留5000个特征词
X_vectorized = vectorizer.fit_transform(X)
# 3. 建立分类器模型
classifier = MultinomialNB() # 使用朴素贝叶斯分类器作为模型
# 4. 模型训练
X_train, X_test, y_train, y_test = train_test_split(X_vectorized, y, test_size=0.2, random_state=42) # 将数据划分为训练集和测试集
classifier.fit(X_train, y_train) # 在训练集上训练模型
# 5. 模型评估
y_pred = classifier.predict(X_test) # 在测试集上进行预测
accuracy = accuracy_score(y_test, y_pred) # 计算分类准确率
print("检测精度:", accuracy)
print("输出分类结果(准确率、召回率、F1值等指标):\n", classification_report(y_test, y_pred)) # 输出分类报告
# 6. 模型应用
new_text = ["我喜欢你就像风吹了八千里,不问归期!"]
new_text_vectorized = vectorizer.transform(new_text) # 对新文本进行特征提取
predicted_category = classifier.predict(new_text_vectorized) # 使用训练好的模型进行分类
print("预测类别:", newsgroups_data.target_names[predicted_category[0]]) # 输出预测的类别
# 7. 可视化数据处理结果
# 可视化不同类别的分布情况
plt.figure(figsize=(10, 6))
plt.hist(y, bins=20, color='skyblue', edgecolor='black')
plt.xlabel('Category')
plt.ylabel('Frequency')
plt.title('Distribution of Different Categories')
plt.xticks(range(20), newsgroups_data.target_names, rotation=45)
plt.grid(True)
plt.show()
# 可视化特征提取后的词频信息
feature_names = vectorizer.get_feature_names()
tfidf_values = X_vectorized.toarray().sum(axis=0) # 计算每个词的TF-IDF值总和
sorted_indices = tfidf_values.argsort()[::-1] # 按TF-IDF值排序
top_features = [feature_names[i] for i in sorted_indices[:20]] # 选择前20个TF-IDF值最高的词语
plt.figure(figsize=(10, 6))
plt.barh(range(20), tfidf_values[sorted_indices[:20]], color='skyblue', edgecolor='black')
plt.xlabel('TF-IDF Value')
plt.ylabel('Word')
plt.title('Top 20 Words with Highest TF-IDF Values')
plt.yticks(range(20), top_features)
plt.gca().invert_yaxis() # 反转y轴,使得词频值高的词语在顶部显示
plt.grid(True)
plt.show()
执行结果:检测精度84.6%

 词语的TF-IDF值条形图数据可视化结果
词语的TF-IDF值条形图数据可视化结果
2、情感分析:
基于机器学习的情感分析是一种利用机器学习算法对文本进行情感倾向分析的方法。而SnowNLP是一个功能强大的Python文本处理库,它包含了中文分词、词性标注、情感分析、文本分类等多种功能。结合SnowNLP和机器学习算法,可以构建出高效、准确的情感分析系统。
在使用SnowNLP进行情感分析时,通常需要先对文本进行预处理,包括分词、去除停用词等步骤。然后,可以利用SnowNLP的情感分析功能对文本进行情感打分,或者利用机器学习算法对文本进行情感分类。简单案列:
from snownlp import SnowNLP
# 示例文本
text = "我喜欢你,就像风吹了八千里,不问归期!"
# 初始化SnowNLP对象
s = SnowNLP(text)
# 使用SnowNLP进行情感分析
# sentiments的值域为[0, 1],越接近1情感越积极,越接近0情感越消极
sentiments = s.sentiments
# 输出情感分析结果
if sentiments > 0.5:
print("积极情感")
elif sentiments < 0.5:
print("消极情感")
else:
print("中性情感")使用scikit-learn的朴素贝叶斯分类器结合SnowNLP的文本处理功能进行情感分析:
from snownlp import SnowNLP
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
import pandas as pd
# 假设你有一个CSV文件,其中包含两列:text(文本内容)和label(情感标签,如1表示积极,0表示消极)
data = pd.read_csv('sentiment_data.csv')
# 使用SnowNLP进行分词
data['segmented'] = data['text'].apply(lambda x: ' '.join(SnowNLP(x).words))
# 特征提取:将文本转换为词频向量
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(data['segmented'])
# 情感标签
y = data['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用朴素贝叶斯分类器进行情感分类
clf = MultinomialNB()
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy * 100:.2f}%')总结
今天的学习内容主要围绕机器学习之文本分析的词法分析、句法分析、语义分析展开,分别详细介绍相关概念、定义、原理,以及如何利用机器学习方法实现语言分析。接着我们通过文本分类和情感分析案列实现上述理论内容,基于前面博文提到的贝叶斯网络机器学习方法等。在学习过程中,我们了解到可以使用SnowNLP的内置情感分析功能来预测文本的情感倾向为此,我们学习了如何结合SnowNLP的文本处理功能和scikit-learn等机器学习库来构建基于机器学习的情感分析模型。
总的来说,通过学习和实践,我们对情感分析有了更深入的了解,并掌握了使用SnowNLP和机器学习进行情感分析的基本方法。这将为我们未来的文本处理和分析工作提供有力的支持。
最后,创作不易!非常感谢大家的关注、点赞、收藏、评论啦!谢谢四连哦!好人好运连连,学习进步!工作顺利哦!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











