






今天我们讲的是Python的实战练习:爬取电影天堂的磁力链接。
关注公众号【老夫撸代码】回复【python01】获取python交流QQ群相关信息。
关注老夫的宝子们都知道,老夫业余时间撸了一个电影网站,主要是用Laravel搭建的,里面的数据就是用Python爬取的某个电影天堂网站资源。
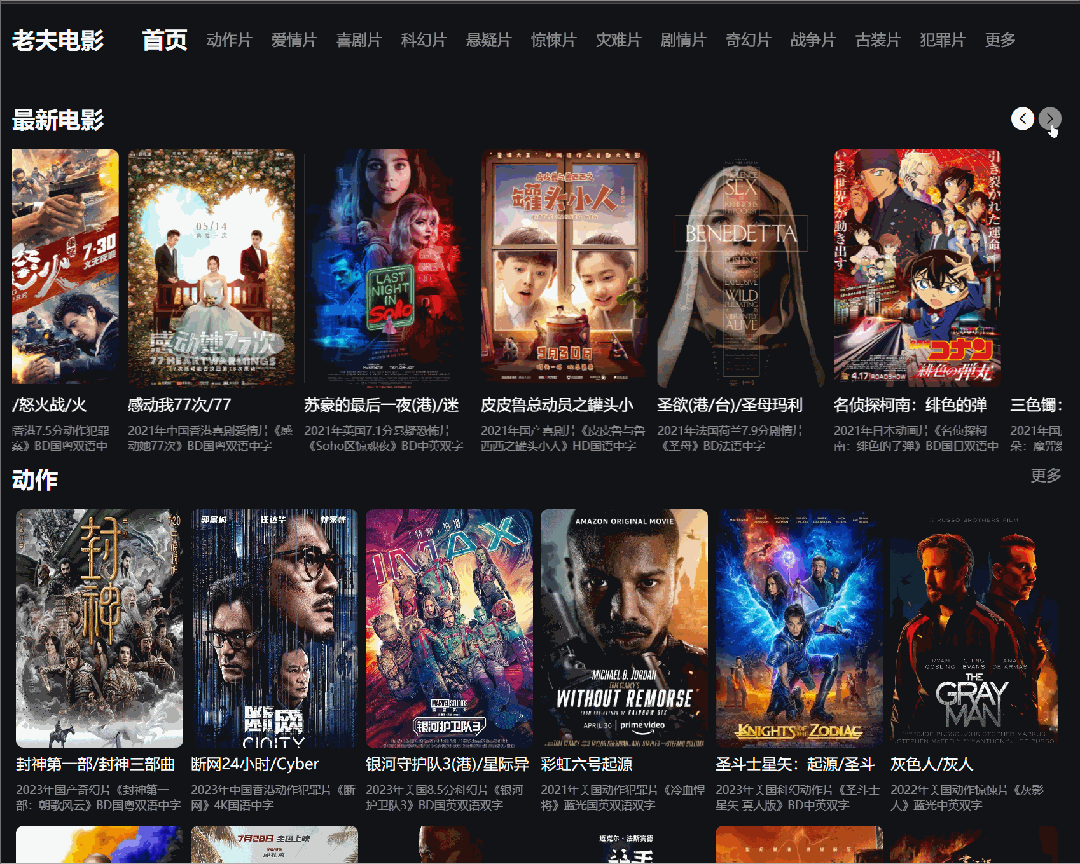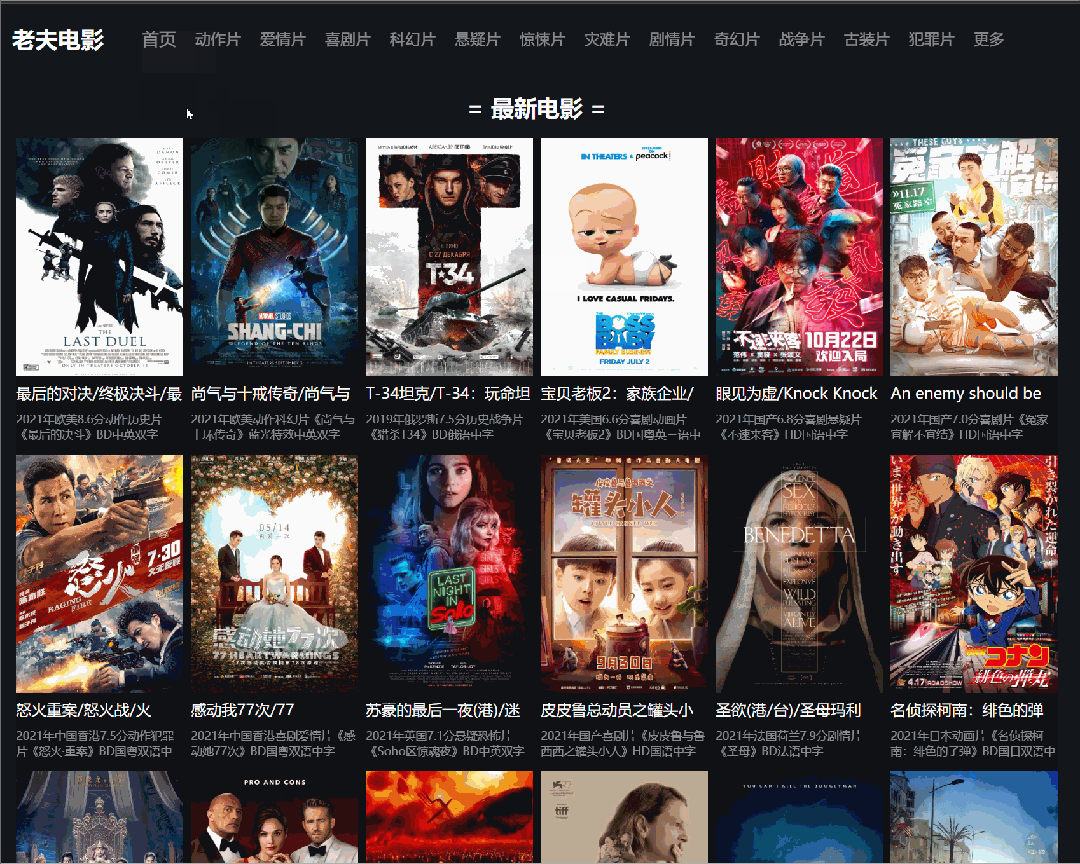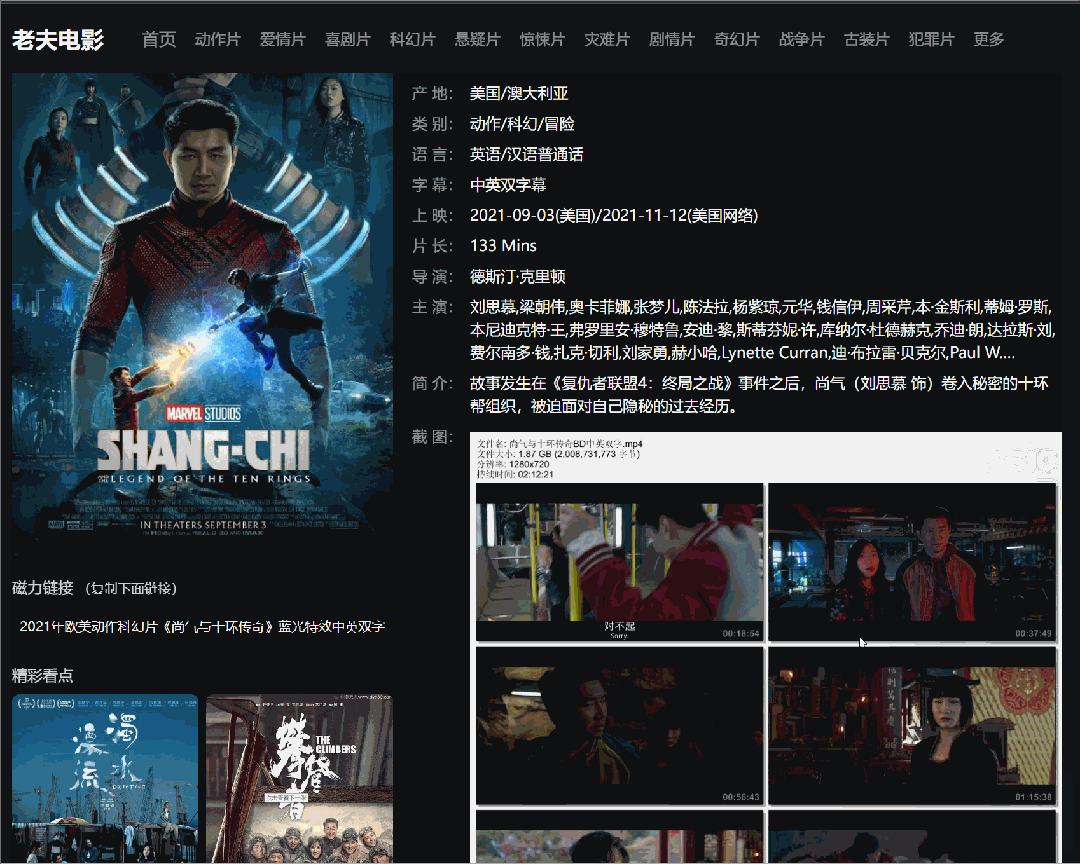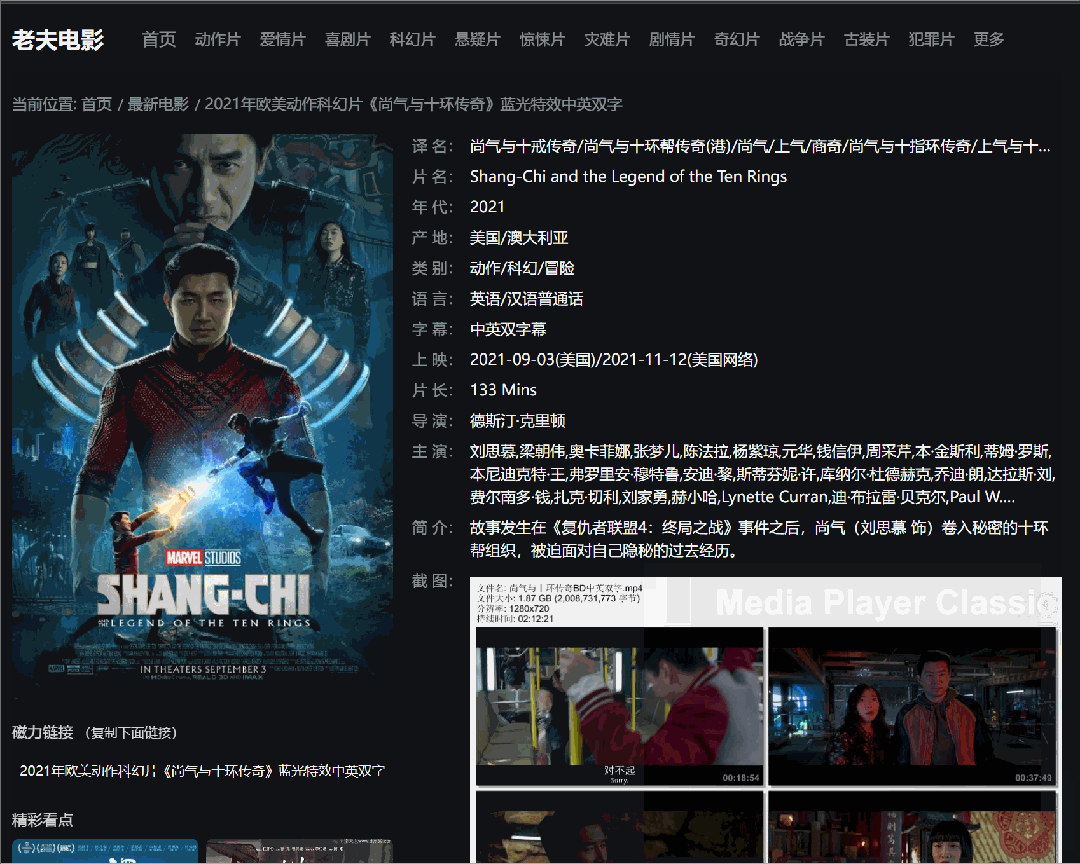
在我们明确了业务需求后,主要分为以下三个步骤。
1、目标网站分析
首先,我们需要寻找适合爬虫的网站。
目前一般网站的技术架构分为以下几类:
-
前后端分离的网站
这类型网站主要是用 vue 或者 react 进行前端构建,后端使用java 或者 php 提供接口,为了便于SEO优化,可能会采用ssr进行服务端渲染。本质还是返回给前端一个完整的html页面。
-
cms网站
此类型网站本质还是返回给前端一个html页面,不同的是需要模板语言做支持,比如wordpress、织梦、帝国等等建站工具
-
js动态加载的网站
这类型的网站的一个特点是返回给前端也是一个html页面,而数据是放到 js 的全局变量里面,然后再通过操作dom把数据渲染出来。
总之,技术千变万化,我们需要透过现象看到本质,俗话说:你有张良计,我有过墙梯。
我们在百度随便搜索“电影天堂”这几个关键字的时候会显示一堆资源站,随便选一个网站,参照上面的技术架构分类进行判断。
这里老夫选择了这个网站:
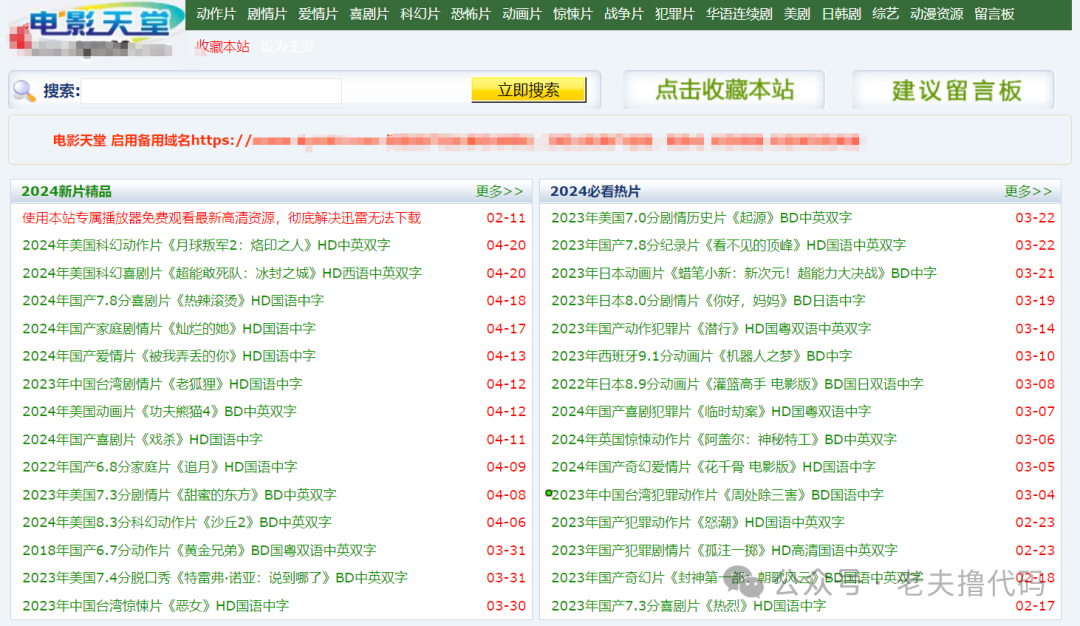
F12看下源码结构,发现是直接输出网页的形式,也就是第2种方式,这是最适合爬虫爬取的数据结构。

2、技术架构
通过分析整个网站的网页结构,我们可以先从导航栏入手。

一般网站设计的基本结构是列表页 + 详情页。这里列表页就是每个电影的分类,详情页就是列表页种具体的某个电影的页面。
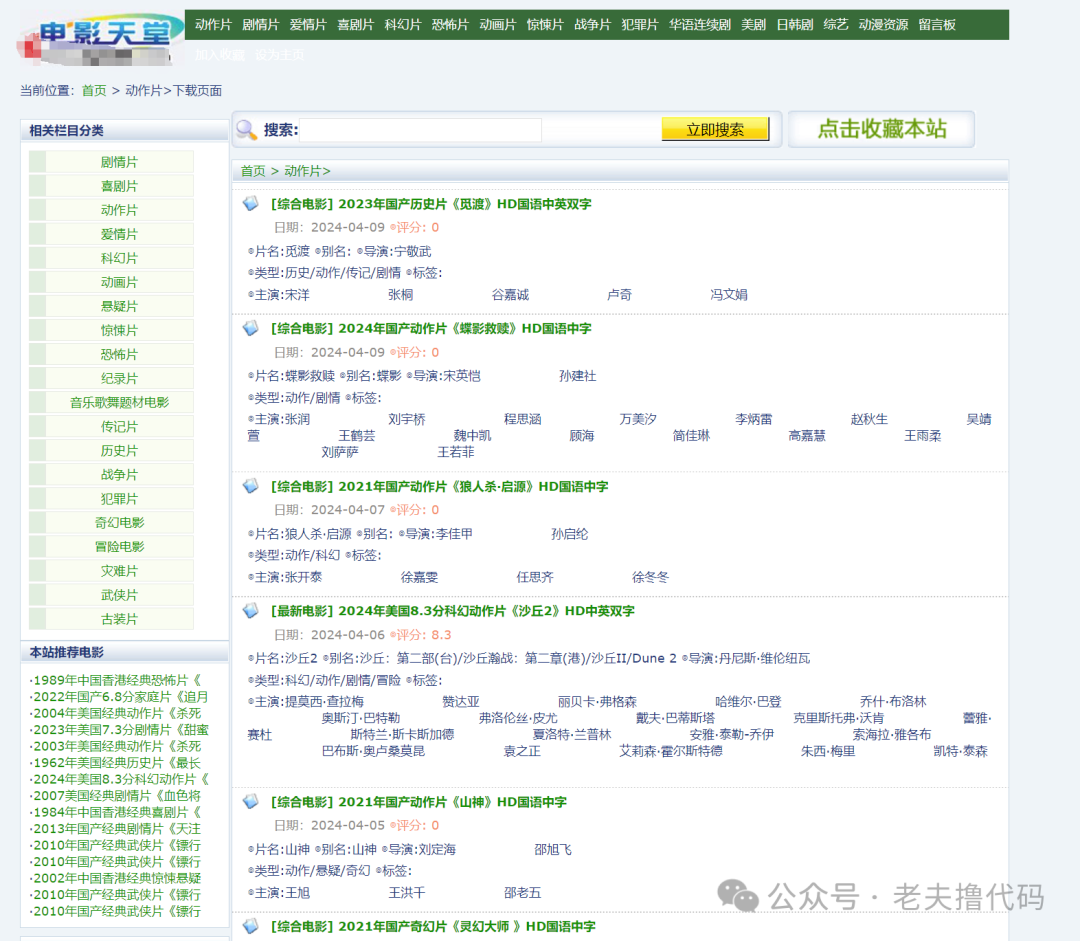
(列表页)
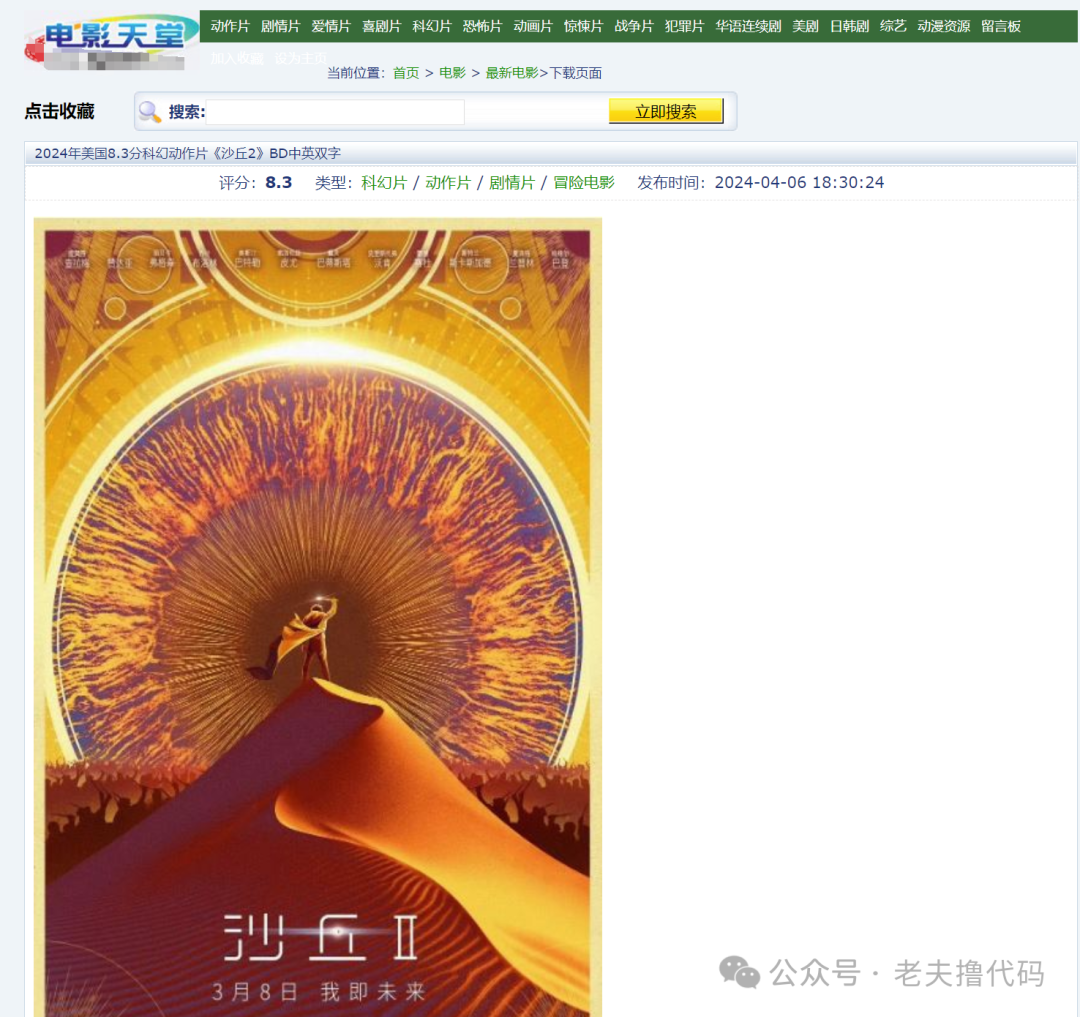
(详情页)
因此我们可以初步确定爬取的思路:
1、先爬取所有的列表页的列表数据
2、然后再进入详情页爬取资源链接
这里我们可以这样设计,把所有电影资源分类下的列表页的url保存到本地,然后通过加载本地的列表url去爬取详情页资源,这样设计的理由:
1、在开发的过程中防止爬虫出现问题,大量请求到对方服务器,造成对方服务器过载而宕机。虽然说互联网的资源大家都有平等共享的权利,但是我们开发爬虫的时候也要注意职业操守,尽可能不要给对方服务器造成损失,如果后果很严重的话可能要被请去喝茶的,切记!切记!切记!
2、保持到本地的资源文件,对于下一步操作可以省略网络请求的那一环境,可以让你爬虫的速度更快。
3、整个过程做成异步操作进行解耦,如果在爬取列表页后马上去爬取详情页,整个过程任何一个环境出现问题,需要整个程序排查。
ps: 可以进一步优化,把列表页的整个内容都保存到本地,然后依次加载本地页面即可访问到详情页。
3、编码阶段
方便确定后,我们还是采用Python的Scrapy框架来做爬虫。
首先是环境搭建,我们用虚拟环境来构建python的运行环境。
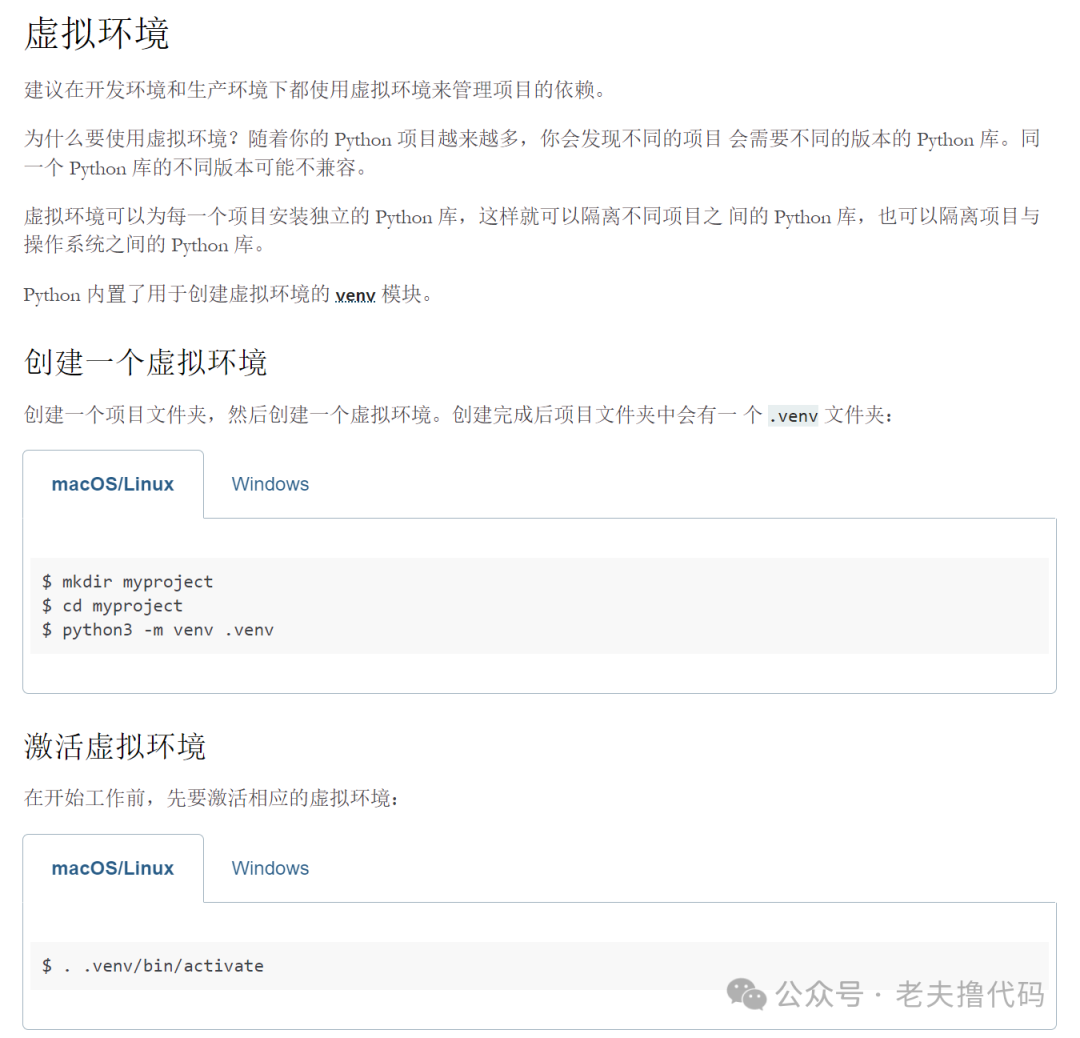
其次:构建两个spider,一个是爬取列表数据,一个是爬取详情数据。
列表spider主要是把列表页的链接保存到一个allUrl.txt的文件中,方便后续详情页爬取。
class myspider(scrapy.Spider):name = 'msp'domain = 'https://www.XXXXXXX.com'def start_requests(self):urls = ['/html/gndy/dyzz/index.html']for url in urls:yield scrapy.Request(url=self.domain+url, callback=self.pagelist)def pagelist(self, response):select = response.xpath('//*[@id="header"]/div/div[3]/div[6]/div[2]/div[2]/div[2]/div/select').get()# 所有分页的链接pages = Selector(text=select).css("option").xpath("@value").getall()curr_dir = os.path.dirname(os.path.dirname(os.path.dirname(__file__)))file_path = os.path.join(curr_dir, 'pages/allUrl.txt')with open(file_path,'w') as f:for page in pages:f.write(self.domain + page+"\n")
详情页spider主要是加载本地的列表数据文件,然后加载列表数据进行详情页的爬取。
class DetailSpider(scrapy.Spider):domain = "https://www.XXXXXXX.com"name = 'dmsp'def start_requests(self):curr_dir = os.path.dirname(os.path.dirname(os.path.dirname(__file__)))file_path = os.path.join(curr_dir, 'pages/allUrl.txt')start_urls = []with open(file_path, 'r') as f:urls = f.readlines()for url in urls:start_urls.append(url[0:-1])currUrl = start_urls[22]yield SplashRequest(url=currUrl, callback=self.parseList, args={'wait': 10},endpoint='render.html')def parseList(self,response):# logging.info("parseList response: %s ", response.text)urlSel = response.xpath('//div[@class="co_content8"]/ul//a').getall()detailUrls = []for url in urlSel:obj = {}obj['url'] = self.domain + Selector(text=url).xpath('//@href').get()obj['title'] = Selector(text=url).xpath('//text()').get()detailUrls.append(obj)logger.info("detailUrls: %s ",detailUrls)for detailUrl in detailUrls:logger.info("当前url: %s",detailUrl['url'])yield SplashRequest(url=detailUrl['url'], callback=self.parseDetail,args={'wait': 10},endpoint='render.html')# yield SplashRequest(url=detailUrls[0]['url'], callback=self.parseDetail,args={'wait': 10},endpoint='render.html')def parseDetail(self,response):image_urls = []title = response.xpath('//div[@class="title_all"]//h1/text()').get()ul = response.xpath("//div[@class='co_content8']//ul")cover = ul.xpath("//div[@id='Zoom']/img[1]/@src").get()screenshots = ul.xpath("//div[@id='Zoom']/img[2]/@src").get()image_urls.append(cover)image_urls.append(screenshots)zoom = ul.xpath(".//div[@id='Zoom']/text()").getall()magnet = response.xpath("//div[@id='downlist']//a/text()").get()_list = [x.strip() for x in zoom ]_list1 = [x for x in _list if x != '' ]_list2 = [x.replace('\u3000','aaa') for x in _list1]logging.info("_list2: %s ", _list2)item = MyspiderItem()item['image_urls'] = image_urlsitem['title'] = title #标题import datetimeitem['id_uuid'] = genUUid()item['createtime'] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") #更新时间_protagonist_index = 0_introduction_index = 0for _item in _list2:if _item.find('◎译') != -1:item['movie_name_zh'] = self.splitList(_item)elif _item.find('◎片aaaaaa名') != -1:item['movie_name_en'] = self.splitList(_item)elif _item.find('◎年') != -1:item['movie_year'] = self.splitList(_item)elif _item.find('◎产') != -1:item['movie_places'] = self.splitList(_item)elif _item.find('◎类') != -1:item['movie_type'] = self.splitList(_item)elif _item.find('◎语') != -1:item['movie_lanage'] = self.splitList(_item)elif _item.find('◎字') != -1:item['movie_subtitle'] = self.splitList(_item)elif _item.find('◎上映日期') != -1:item['release_date'] = self.splitList(_item)elif _item.find('◎文件格式') != -1:item['file_form'] = self.splitList(_item)elif _item.find('◎视频尺寸') != -1:item['video_size'] = self.splitList(_item)elif _item.find('◎文件大小') != -1:item['file_size'] = self.splitList(_item)elif _item.find('◎片aaaaaa长') != -1:item['movie_time'] = self.splitList(_item)elif _item.find('◎导') != -1:item['direct'] = self.splitList(_item)elif _item.find('◎主') != -1:item['protagonist'] = self.splitList(_item)_protagonist_index = _list2.index(_item)elif _item.find('◎简') != -1:_introduction_index = _list2.index(_item)item['isDownload'] = 0protagonist = item['protagonist']for po in _list2[_protagonist_index+1:_introduction_index]:protagonist += "," + poitem['protagonist'] = protagonistitem['introduction'] = _list2[_introduction_index+1]item['downloadUrl'] = magnetlogger.info("item: %s ", item)yield itemdef splitList(self,item):return item.split("aaa")[-1]
由于此网站做了反爬机制,导致爬取的过程中偶尔会只返回一个js文件,所以这里老夫在docker容器里面跑了一个Splash镜像,实际上爬虫访问的页面是Splash返回的页面。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









