









一、基本使用
以2.4.1 release版本为例—kafka_2.11-2.4.1.tgz,其中2.11是scala的版本,2.4.1是kafka的版本
0.准备
Kafka运行在JVM上,因此需要先安装JDK
Kafka依赖zookeeper,因此需要先安装并启动zookeeper(不安装也可,Kafka中会自带zookeeper,推荐自行安装)
1.下载解压
解压完成后,可以使用bin目录下的脚本对Kafka进行下列操作,此处略过。
2.修改配置config/server.properties
修改broker.id、listeners、log.dir、zookeeper.connect等参数
#broker.id属性在kafka集群中必须要是唯一
broker.id=0
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://localhost:9092
#kafka的消息存储文件
log.dir=/usr/local/data/kafka-logs
#kafka连接zookeeper的地址,如果zookeeper是集群,那么多个地址用逗号隔开:localhost:2181,localhost:2182,localhost:2183
zookeeper.connect=localhost:2181
3.启动/停止服务
启动Kafka之前保证zookeeper是启动状态;启动成功后zookeeper目录下应该有kafka相关节点
脚本:bin/kafka-server-start.sh bin/kafka-server-stop.sh
4.创建/删除/查看主题
脚本:bin/kafka-topics.sh
5.发送消息
kafka自带了一个producer命令客户端
脚本:bin/kafka-console-producer.sh
6.消费消息/查看消费组/查看消费组的消费偏移量
kafka自带了一个consumer命令客户端
脚本:bin/kafka-console-consumer.sh
查看消费组的消费偏移量

输出内容的解释:
- current-offset:当前消费组的已消费偏移量
- log-end-offset:主题对应分区消息的结束偏移量(HW)
- lag:当前消费组未消费的消息数
二、集群搭建
1.另启动2个broker实例,修改配置文件核心配置
2.想把多个broker组成一个集群,使其互相之间能够感知到,只需要把zookeeper配置为相同地址即可,不再赘述。这样启动Kafka时就会自动识别相互之间的关系从而组成集群。
3.创建一个新的topic,副本数设置为3,分区数设置为2,此时查看topic的情况如下:

输出内容的解释:
- Leader:负责给定partition的所有读写请求,同一个主题不同分区leader副本一般不一样(容灾)
- Replicas:表示某个partition在哪几个broker上存在备份。无论该节点是否存活都会列出。
- Isr:是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
4.此时kill掉id为1的broker(作为分区0的leader,测试容错性),然后再次查看topic情况如下:

此时分区0的Leader已经变成了broker 0;Replicas没有变化;但是在Isr中,已经没有了1,因为1已经挂掉。
Leader的选举就是从Isr中进行。
集群中的Leader处理所在partition所有的读写请求,而followers被动复制leader的结果,不提供读写(主要是为了保证多副本数据与消费的一致性)。如果这个Leader失效了,其中的一个follower将会自动的变成新的Leader。这里所谓的Leader,并不指某一台机器是Leader(例如zookeeper集群那种),而是针对某一个partition。
Kafka集群本身算是无状态,关键信息都记录在zookeeper中,从而方便水平扩容。
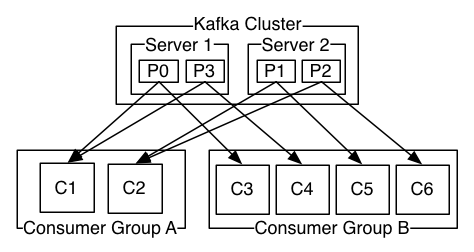
consumer group中的consumer数量不能比一个Topic中的partition数量多,否则多出来的consumer消费不到消息。因为一个partition同一个时刻在一个consumer group中只能有一个consumer在消费。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。如果有在总体上保证消费顺序的需求,那么可以通过将topic的partition数量设置为1,将consumer group中的consumer 数量也设置为1,但是这样会影响性能,很少使用。
三、Java客户端访问
引入maven依赖,版本一般与Kafka服务端版本一致
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
消息生产者代码
public class MsgProducer {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//初始化配置
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092,localhost:9093,localhost:9094");
props.put(ProducerConfig.ACKS_CONFIG, "1");
props.put(ProducerConfig.RETRIES_CONFIG, 3);
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//创建消息生产者,并指定配置信息
Producer<String, String> producer = new KafkaProducer<>(props);
//发送消息
for (int i = 0; i < 100; i++)
//异步发送消息,指定分区
//producer.send(new ProducerRecord<String, String>("my-topic", 0,Integer.toString(i), Integer.toString(i)));
//异步发送消息,未指定分区,具体发送的分区计算公式:hash(key)%partitionNum
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
//同步发送消息,等待消息发送成功的同步阻塞方法
//RecordMetadata metadata = producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i))).get();
//关闭生产者
producer.close();
}
}
生产者主要配置参数说明:
BOOTSTRAP_SERVERS_CONFIG:访问的Kafka服务端地址;
ACKS_CONFIG:发出消息持久化机制,包括all, -1, 0, 1,默认值为1;
RETRIES_CONFIG:重试机制,次;
RETRY_BACKOFF_MS_CONFIG:重试间隔设置,毫秒;
BUFFER_MEMORY_CONFIG:设置发送消息的本地缓冲区,如果设置了该缓冲区,消息会先发送到本地缓冲区,可以提高消息发送性能,默认值是33554432,即32MB;
BATCH_SIZE_CONFIG:kafka本地线程会从缓冲区取数据,批量发送到broker,设置批量发送消息的大小,默认值是16384,即16kb,就是说一个batch满了16kb就发送出去;
LINGER_MS_CONFIG:默认值是0,意思就是消息必须立即被发送,一般设置10毫秒左右,就是说这个消息发送完后会进入本地的一个batch,如果10毫秒内这个batch满了,16kb就会随batch一起被发送出去;如果10毫秒内batch没满,那么也必须把消息发送出去;
KEY_SERIALIZER_CLASS_CONFIG:发送的key从字符串序列化为字节数组;
VALUE_SERIALIZER_CLASS_CONFIG:发送消息value从字符串序列化为字节数组;
关于更多Kafka生产者的相关配置,参考官方文档:https://kafka.apache.org/documentation/#producerconfigs
消息消费者代码
public class MsgConsumer {
private final static String TOPIC_NAME = "my-topic";
public static void main(String[] args) {
//初始化配置
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092,localhost:9093,localhost:9094");
props.put(ConsumerConfig.GROUP_ID_CONFIG, “testGroup”);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//创建消息消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
// 订阅主题,不指定分区
//consumer.subscribe(Arrays.asList(TOPIC_NAME));
// 订阅主题,指定分区
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//回溯消费,需要先assign
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//指定offset消费,需要先assign
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);
//从指定时间点开始消费
List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME);
//从1小时前开始消费
long fetchDataTime = new Date().getTime() - 1000 * 60 * 60;
Map<TopicPartition, Long> map = new HashMap<>();
for (PartitionInfo par : topicPartitions) {
map.put(new TopicPartition(topicName, par.partition()), fetchDataTime);
}
//找指定时间起点的消息的offset
Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
if (key == null || value == null) continue;
Long offset = value.offset();
System.out.println("partition-" + key.partition() + "|offset-" + offset);
System.out.println();
//根据消费里的timestamp确定offset
if (value != null) {
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);
}
}
while (true) {
//消费消息,poll拉取消息的长轮询,1秒钟之内反复去服务端拉取消息,1秒钟结束还没有拉取到消息就结束
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(),record.offset(), record.key(), record.value());
}
//批量处理完一次性手动提交offset,也可以每处理一条消息提交一次
if (records.count() > 0) {
// 手动同步提交offset
consumer.commitSync();
// 手动异步提交offset
/*
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
...
}
});*/
}
}
}
}
消费者主要配置参数说明:
BOOTSTRAP_SERVERS_CONFIG:访问的Kafka服务端地址;
GROUP_ID_CONFIG:消费分组名;
ENABLE_AUTO_COMMIT_CONFIG:是否自动提交offset,默认值为true;
AUTO_COMMIT_INTERVAL_MS_CONFIG: 自动提交offset的间隔时间;
AUTO_OFFSET_RESET_CONFIG:指定新的消费组offset的消费方式,包括latest,earliest,默认值为latest;
HEARTBEAT_INTERVAL_MS_CONFIG:consumer给broker发送心跳的间隔时间,默认值为3000ms;
SESSION_TIMEOUT_MS_CONFIG:如果一个consumer两次发送心跳的间隔超过设置时间,服务端broker就认为他故障了,会将其踢出消费组;
MAX_POLL_RECORDS_CONFIG:一次poll最大拉取消息的条数,默认值为500;
MAX_POLL_INTERVAL_MS_CONFIG:如果一个consumer两次poll操作间隔超过了设置时间,服务端broker就会认为这个consumer处理能力太弱,会将其踢出消费组;
KEY_DESERIALIZER_CLASS_CONFIG:发送的key反序列化
VALUE_DESERIALIZER_CLASS_CONFIG:发送的valve反序列化
关于更多Kafka消费者的相关配置,参考官方文档:https://kafka.apache.org/documentation/#consumerconfigs
四、Kafka + Spring Boot
引入spring boot kafka依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
application.yml
server:
port: 8080
spring:
kafka:
bootstrap-servers: localhost:9092,localhost:9093,localhost:9094
producer: # 生产者相关配置,同Java代码
retries: 3
batch-size: 16384
buffer-memory: 33554432
acks: 1
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # 消费者相关配置,同Java代码
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# RECORD:当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# BATCH:当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# TIME:当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# COUNT:当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT_TIME:TIME、COUNT有一个条件满足时提交
# MANUAL:当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL_IMMEDIATE:手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
ack-mode: manual_immediate
消息生产者代码
@RestController
public class KafkaController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/send")
public void send() {
kafkaTemplate.send("my-topic", 0, "key", "this is a msg value");
}
}
消息消费者代码
@Component
public class MyConsumer {
/**
* @KafkaListener(groupId = "testGroup", topicPartitions = {
* @TopicPartition(topic = "topic1", partitions = {"0", "1"}),
* @TopicPartition(topic = "topic2", partitions = "0",
* partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))
* },concurrency = "6")
* concurrency就是同组下的消费者个数
* @param record
*/
@KafkaListener(topics = "my-topic",groupId = "Group")
public void listenGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//手动提交offset
ack.acknowledge();
}
//配置多个消费组
@KafkaListener(topics = "my-topic",groupId = "Group2")
public void listenGroup2(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
ack.acknowledge();
}
}















 1204
1204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









