







在不同的mysql引擎中,count的处理机制不同。
select count(*) from tb_name- MyISAM中,没有where条件的count(*)语句会直接返回结果,因为myisam中直接存有这个表的总记录数。但如果带有where条件,那么处理时间也会变长。
- Innodb中,执行起来时间就会比较长了,它会把记录一行行读出来,然后去计数处理。
为什么如此优秀的Innodb需要一行行累加,而没有像Myisam一样做个总行数记录呢?
对于诸如 之类的事务性存储引擎 InnoDB,存储准确的行数是有问题的。多个事务可能同时发生,每个事务都可能影响计数。
InnoDB不会保留表中的内部行数,因为并发事务可能同时 “看到”不同数量的行。因此,SELECT COUNT(*) 语句只计算对当前事务可见的行。
(摘自mysql8.0官方文档(翻译后),这其中也是有解决办法的,估计是综合考虑后做出的取舍吧)
各种count操作哪个效率更高?
由于实际开发中基本都基于innodb,所以以下分析也是基于innodb展开的。
并且是不带有where子句的。
先来看下count()的定义:
返回由语句检索的行中非NULL 值 的数量的计数。结果是一个 值
再来看下各个count的执行过程:
count(主键id)
InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 mysql server 层。server 层拿到 id 后,判断是不可能为空的,就按行计数。(server层:mysql里的server层:包括分析器、优化器、执行器等)
count(1)
InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
count(字段)
- 如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;
- 如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
count(*)
在 MySQL 5.7.18 之前,通过扫描聚集索引来处理count(*)。
从 MySQL 5.7.18 开始, 通过遍历最小的可用二级索引来处理count(*),除非索引或优化器提示指示优化器使用不同的索引。如果二级索引不存在,则扫描聚集索引。(聚集索引叶子节点存放记录的完整数据,二级索引的B+树是非聚集索引,在叶子节点只存放了主键id,所以遍历最小的二级索引效率会更高一些)
mysql8.0官方文档介绍说,InnoDB以同样的方式处理SELECT COUNT(*)和SELECT COUNT(1) 操作。没有性能差异。
所以结论是:按照效率排序的话,count(字段)<count(主键 id)<count(1)=count(*),所以我建议你,尽量使用 count(*)或count(1)。
实践出真知
为了放大查询的差异,selet查询了数据量为2650万的表,查询耗时如下图所示。可以看到count(*)和count(1)是接近的,其他两种方式都比较慢。
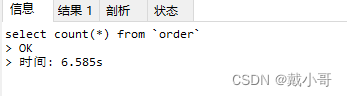
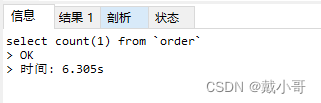
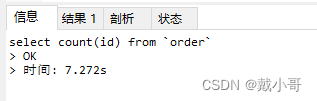
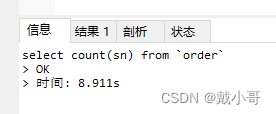
大表如何快速统计总行数?
如果使用innodb,通过count来查,等待时间比较久,如果业务要求比较高,可能不太合适。
我这边推荐自建一张计数表,每次插入或删除操作时更新计数表数据,然后查询某表总行数,通过查询计数表即可。
- 如何保证计数准确性?
在插入或删除操作时,利用事务,同步更新计数操作,保证插入或删除的时候,计数也会同时被更新。
- 如何计数表记录避免高并发锁等待?
根据业务实际需求,我们可以对于同一个表,建立多条计数记录,获取总数时,我们根据相关记录求和即可。如果业务有需求,还可以根据业务分类计数,这样还能方便快速统计某个分类业务中有多少数据。














 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









