







什么是模式注解?
以下是官网中对于模式注解(Stereotype Annotations)的解释:
A stereotype annotation is an annotation that is used to declare the role that a component plays within the application. For example, the
@Repositoryannotation in the Spring Framework is a marker for any class that fulfills the role or stereotype of a repository (also known as Data Access Object or DAO).
@Componentis a generic stereotype for any Spring-managed component. Any component annotated with@Componentis a candidate for component scanning. Similarly, any component annotated with an annotation that is itself meta-annotated with@Componentis also a candidate for component scanning. For example,@Serviceis meta-annotated with@Component.Core Spring provides several stereotype annotations out of the box, including but not limited to:
@Component,@Service,@Repository,@Controller,@RestController, and@Configuration.@Repository,@Service, etc. are specializations of@Component.
也就是说,只要是被 @Component 标注或元标注的注解,就叫做模式注解。标注很好理解,那元标注是什么意思呢?元标注就是指被 @Component 标注的注解,比如 @Service, @Repository, @Controller, @RestController, @Configuration 。
模式注解在 Spring 中出现的顺序见下表,从表中我们可以看出 Spring 最先开始支持的并不是 @Component,而是 @Repository,实际上是因为刚开始 @Repository 是由 DDD 中的概念而被提出的,当时还没有模式注解这个概念,等到 Spring 2.5 之后引入了模式注解的概念后,才将 @Repository 也收入了麾下。
| 注解 | 起始版本 |
|---|---|
| @Repository | 2.0 |
| @Component | 2.5 |
| @Service | 2.5 |
| @Controller | 2.5 |
| @Configuration | 3.0 |
模式注解是如何生效的?
既然我们知道了模式注解,那么为什么 Spring 能将这些模式注解进行统一管理呢?它们又是如何加载到 Spring 容器中的?
这时,就要请出我们的大哥 @ComponentScan 了,@ComponentScan 注解的任务就是找到上述分散在各个地方的小弟并将它们装配到 Spring 容器中。不过该注解要等到 Spring 3.1 才出现,在此之前,Spring 使用 XML 配置扫描包路径的方式支持上述模式注解。
那接下来我们就来看下 @ComponentScan 是如何进行扫描并装配的吧。
那我怎么知道这个注解在哪用了或者又在哪读取了呢?Spring 是如何解析的呢?如果我不上网查,怎么从源码中找到?这时候可以使用 IDEA 提供的 Find Usages 快捷键。
我们通过此快捷键找到了 @ComponentScan 在下面这些地方出现过。
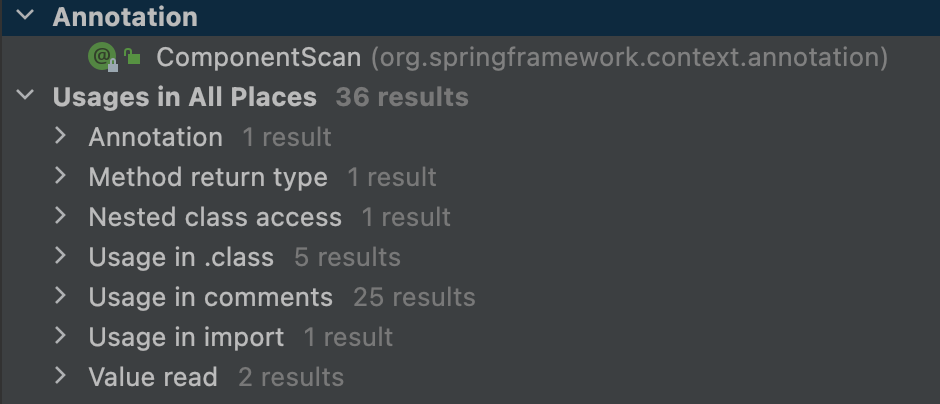
最终,我们定位到下面这两个地方
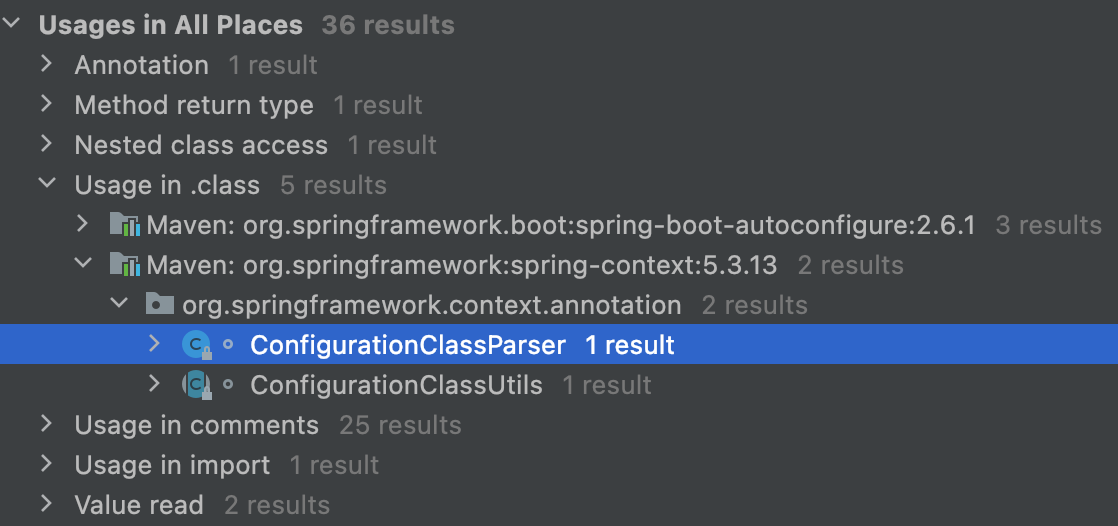
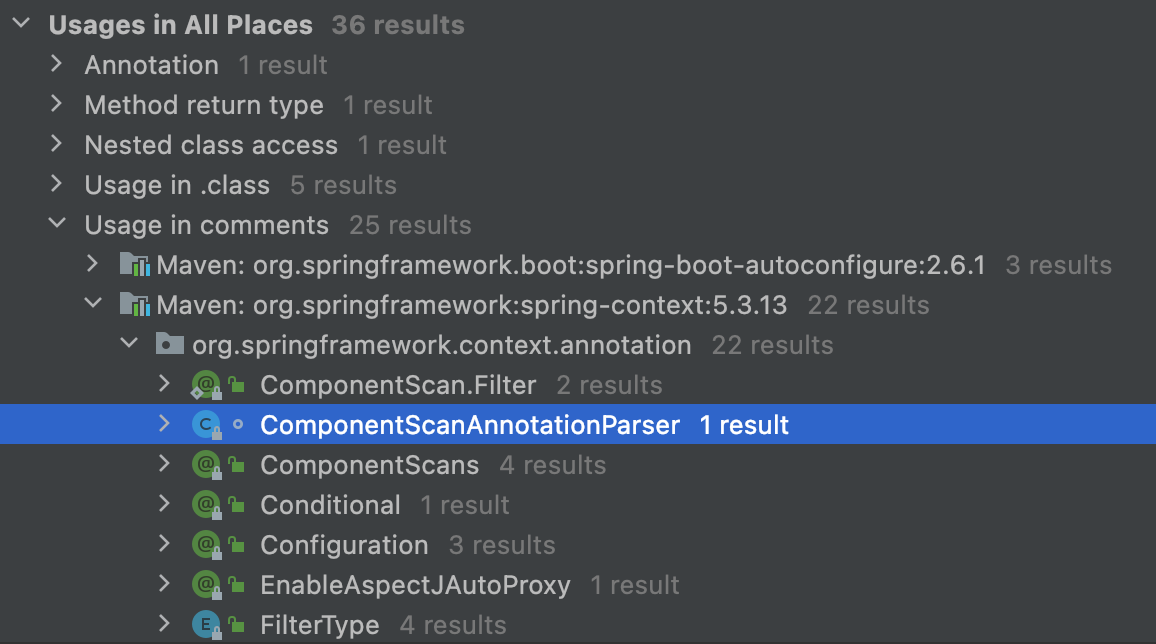
ConfigurationClassParser 这个类从名字看上去是一个配置类解析器,既然在这里出现,说明它和 @ComponentScan有关系;ComponentScanAnnotationParser 这个类从名字看上去就是我们要找的解析器了。
ok,我们点进去看看。
在这个类中,它只有一个 parse 方法,那 parse 方法又是在哪里调用的呢?我们继续对该方法使用 Find Uasge 快捷键,发现调用的地方是在 ConfigurationClassParser#doProcessConfigurationClass 中。
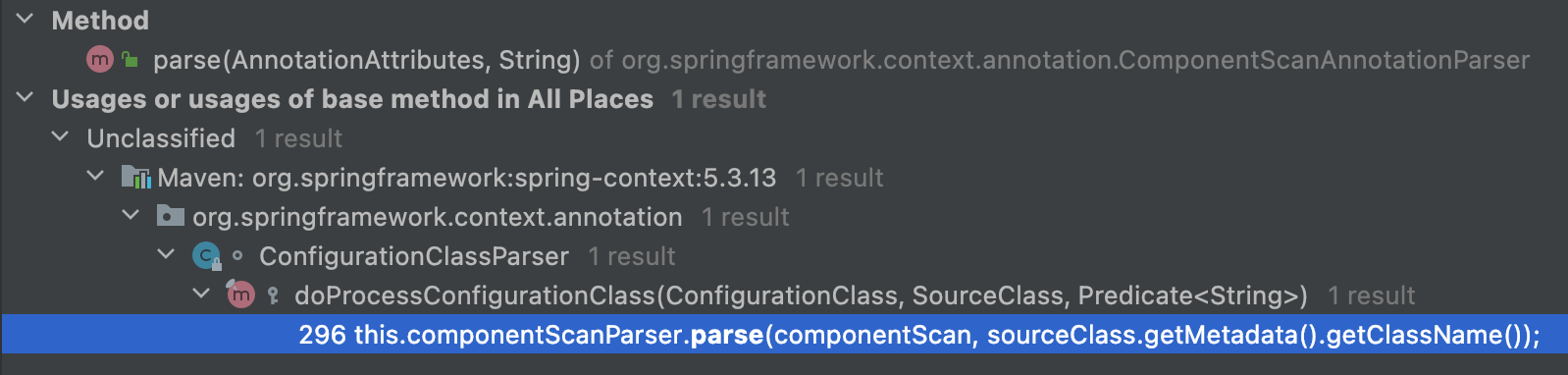
那这么说来,doProcessConfigurationClass 这个方法就是核心了,我们分析下这个方法。
该方法的注释如下:
Apply processing and build a complete ConfigurationClass by reading the annotations, members and methods from the source class. This method can be called multiple times as relevant sources are discovered.
通过从源类中读取注解、成员和方法来应用处理并构建一个完整的 ConfigurationClass。当发现相关来源时,可以多次调用此方法。
从该方法源码的注释中,我们可以发现这个方法主要做以下 8 件事:
-
递归处理被
@Component标注的内部类 -
处理被
@PropertySource标注的类 -
处理被
@ComponentScan标注的类 -
处理被
@Import标注的类 -
处理被
@ImportResource标注的类 -
处理被
@Bean标注的方法 -
处理接口默认方法
-
处理父类
由此看来,这个方法非常重要,不过我们本次只关注它是如何处理被 @ComponentScan 标注的类。以下是此部分代码片段。
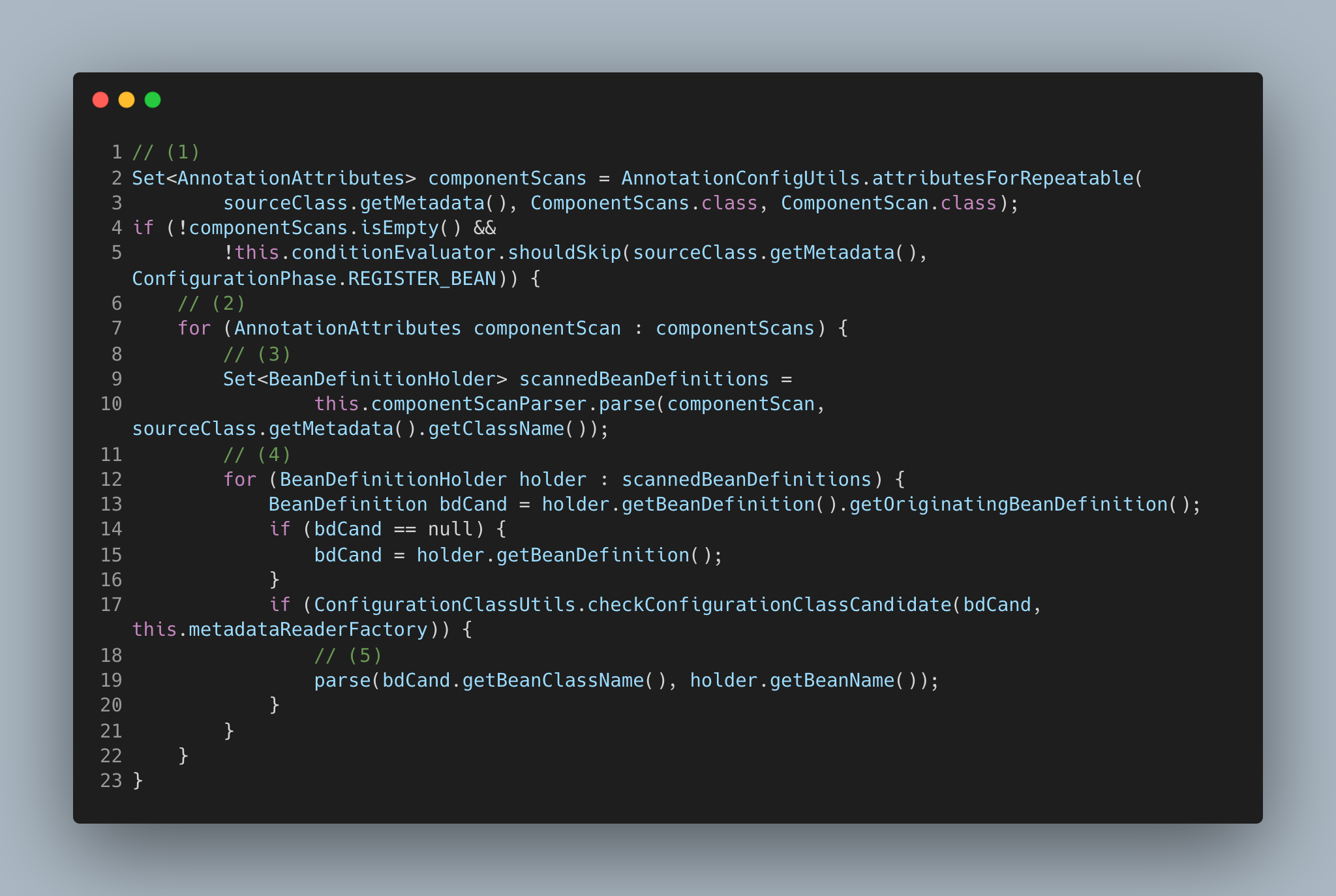
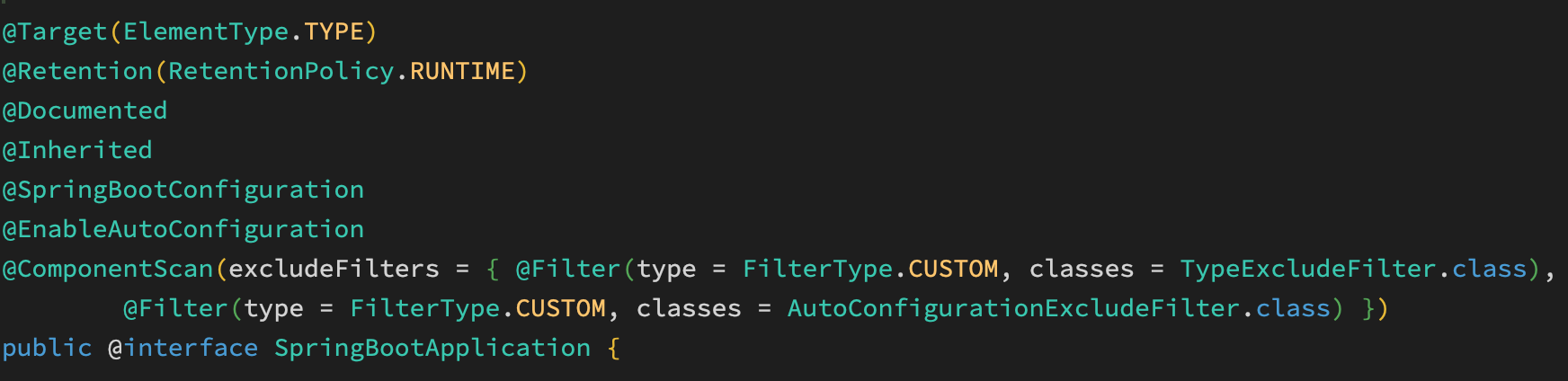
(1)首先通过 AnnotationConfigUtils 获取当前配置类上(在这里我是用 SpringBoot 启动的,所以是启动类)上的 @ComponentScans 和 @ComponentScan 这两个注解信息。
由于 SpringBoot 启动类上标注了@SpringBootApplication,该注解又标注了 @ComponentScan,所以最终可以获取到。
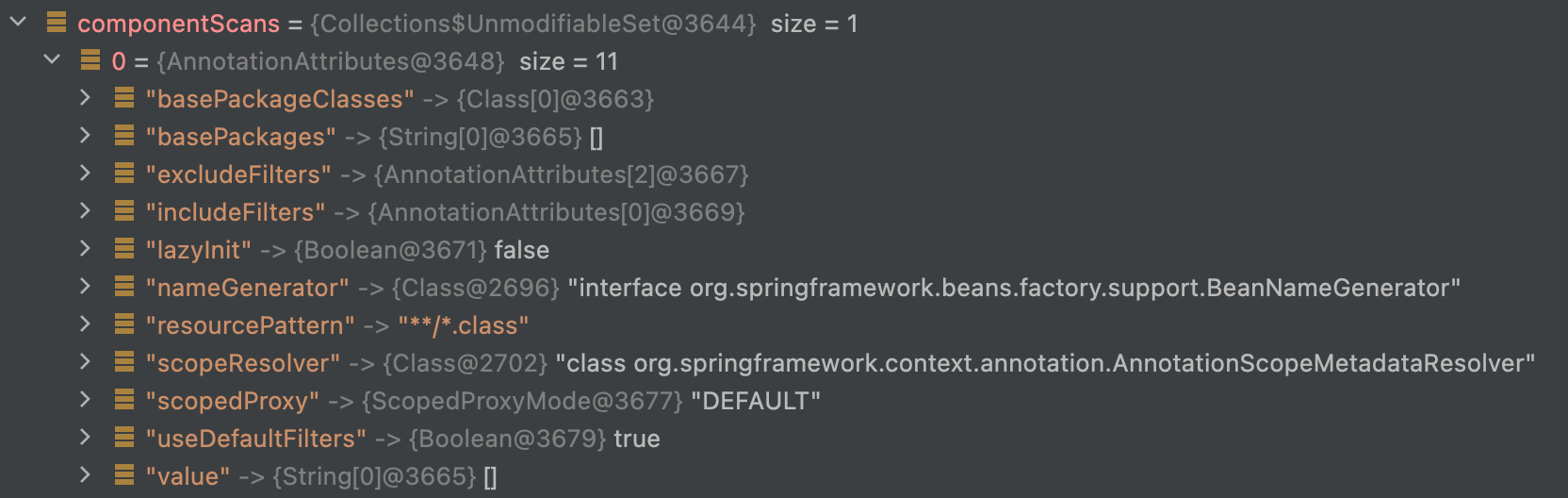
(2)接着 for 循环遍历获取到的 componentScans,由于找到了一个,所以会执行一次。我们可以看下 ComponentScan 注解信息被解析了什么?从代码中可以看到,实际上这里的 componentScans 是 AnnotationAttributes 类型的集合,AnnotationAttributes 类信息如下:
public class AnnotationAttributes extends LinkedHashMap<String, Object>
也就是说,最终将 @ComponentScan 中的每个属性和值变成了键值对,在我的代码中(SpringBoot 默认配置)如下:
(3)调用 ComponentScanAnnotationParser#parse 执行解析。那它又是怎么解析的呢?
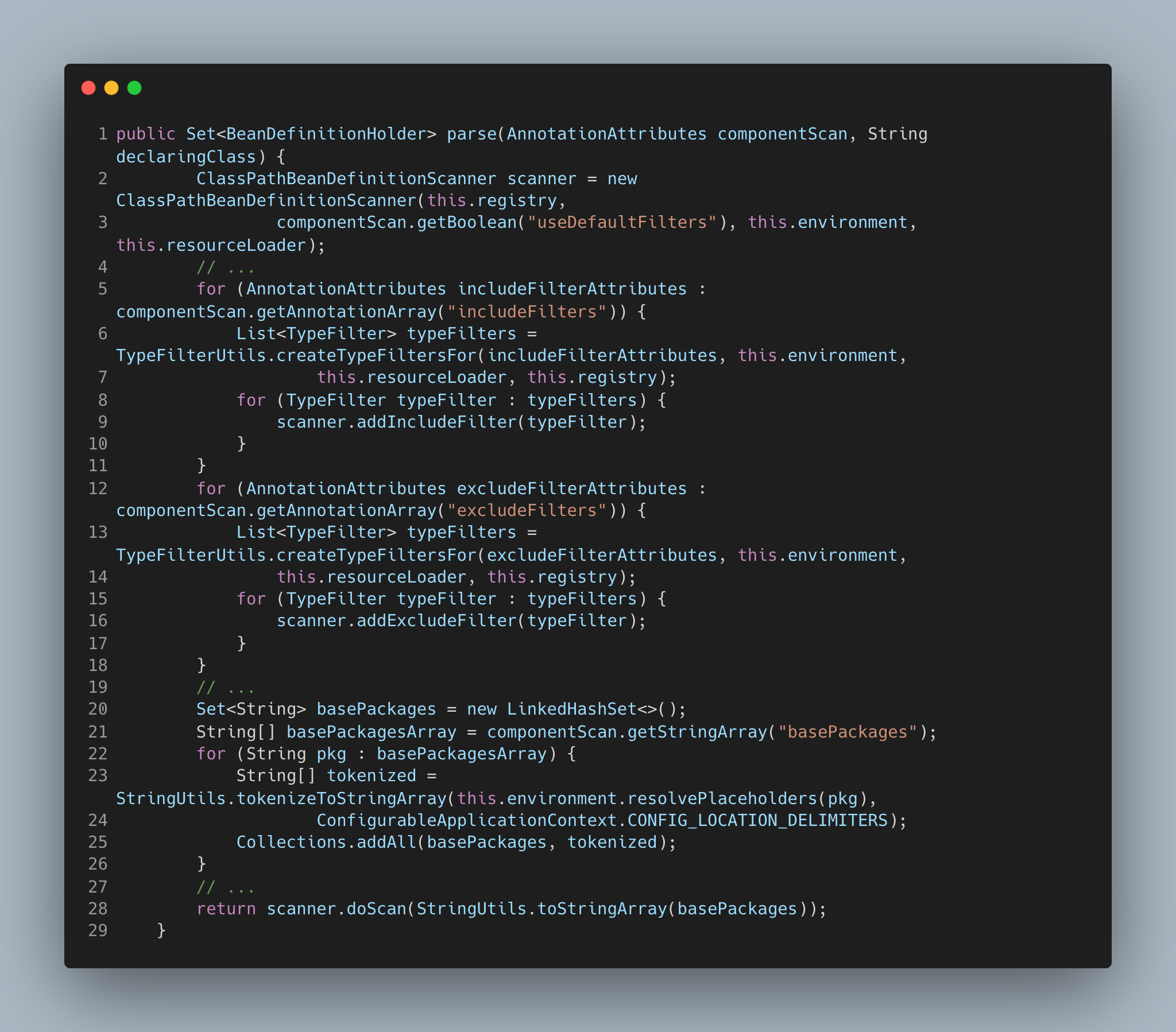
从代码中,我们可以很清晰的看出整个方法就是在不断从 componentScan 中根据属性获取对应值,然后将值设置到 ClassPathBeanDefinitionScanner 中,最终调用 ClassPathBeanDefinitionScanner#doScan 方法。
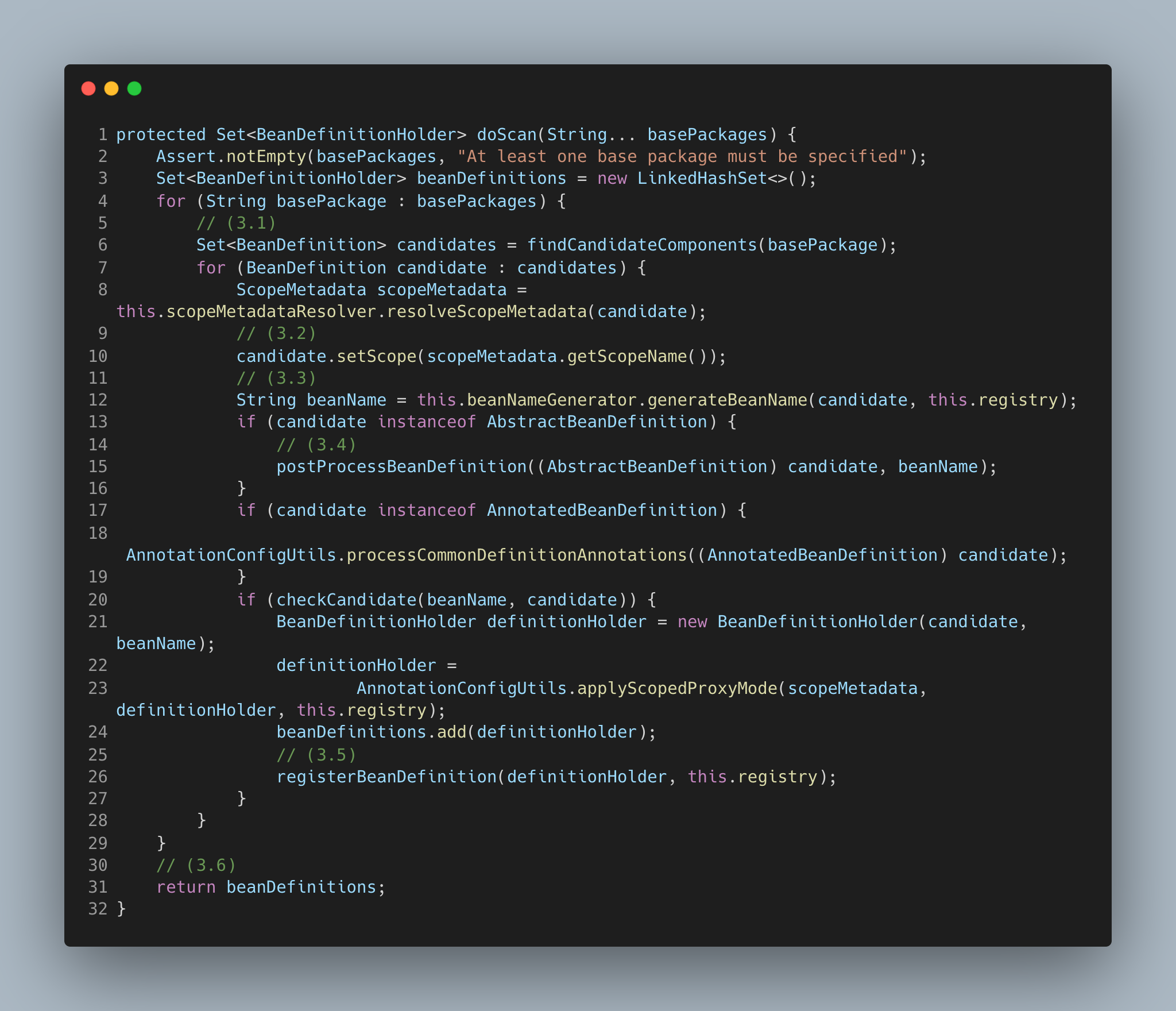
(3.1)findCandidateComponents 方法获取所有被模式注解标注的类并解析成 BeanDefinition;
(3.2)设置 bean 的 scope;
(3.3)生成 beanName;
(3.4)执行 BeanDefinition 阶段的后置处理;
(3.5)注册 BeanDefinition;
(3.6)返回 BeanDefinitionHolder,holder 不仅持有 BeanDefinition,还持有 bean 名称和别名。
我们回到最初的 doProcessConfigurationClass 方法中
(4)按理说此时已经完成了全部工作,但是为什么还有一个 for 循环呢?我们想下,如果这个类的父类也被模式注解标注了呢?你可还没注册它父亲呢吧?
(5)parse 方法递归解析这些类的父类,进行上述同样的步骤。
OK,到此为止,我们基本上明白了模式注解是如何被 Spring 识别并解析的。
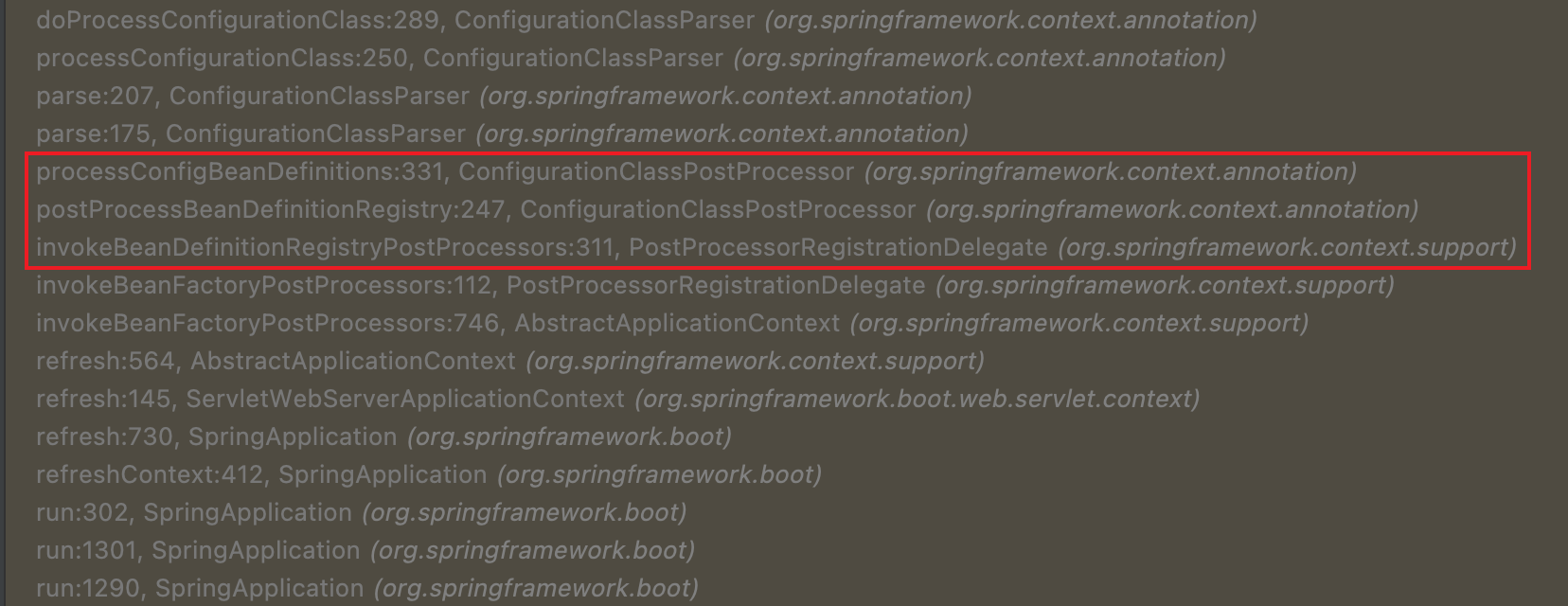
实际上,我们从调用栈中可以看出,这个解析过程是发生在 Bean 信息注册阶段,该阶段会调用实现了 BeanDefinitionRegistryPostProcessor 接口的类,ConfigurationClassPostProcessor 就是其中之一。最终 ConfigurationClassPostProcessor 会创建一个 ConfigurationClassParser 的实例来解析配置类。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









