






 本文介绍了如何使用麻雀搜索算法SSA优化SVM的超参数,构建适用于多列数据输入、单列数据输出的预测模型。通过详细注释的Matlab代码,用户可以直接应用并评估模型性能。
本文介绍了如何使用麻雀搜索算法SSA优化SVM的超参数,构建适用于多列数据输入、单列数据输出的预测模型。通过详细注释的Matlab代码,用户可以直接应用并评估模型性能。
利用麻雀搜索算法SSA优化SVM的c和g,建立多列数据输入,单列数据输出的拟合预测建模,程序内注释详细,直接替换数据就可以用,可以打印出多个常用的模型评价指标
ID:6235676695227372
Matlab建模

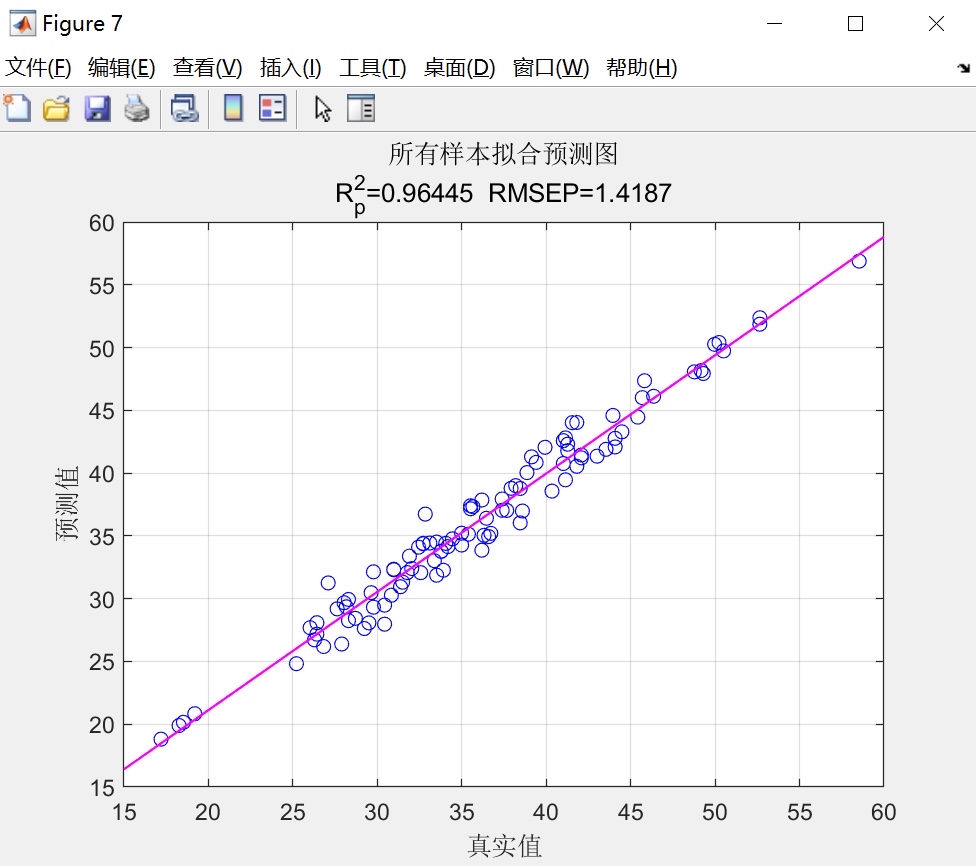
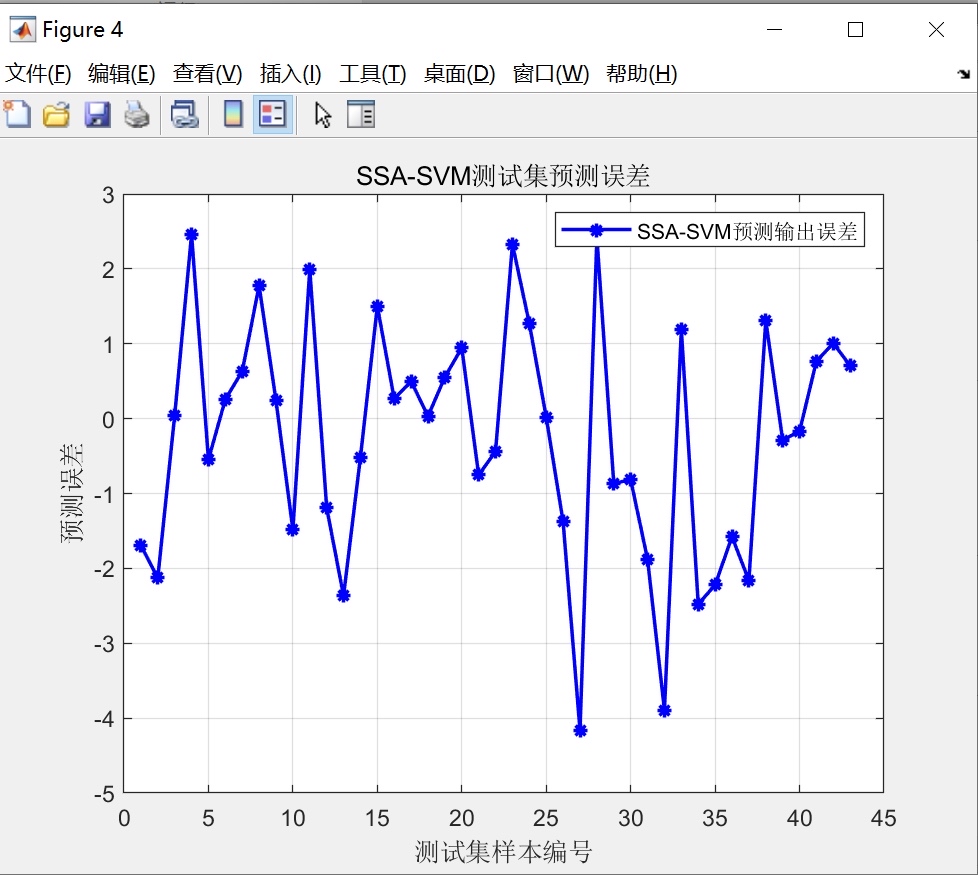
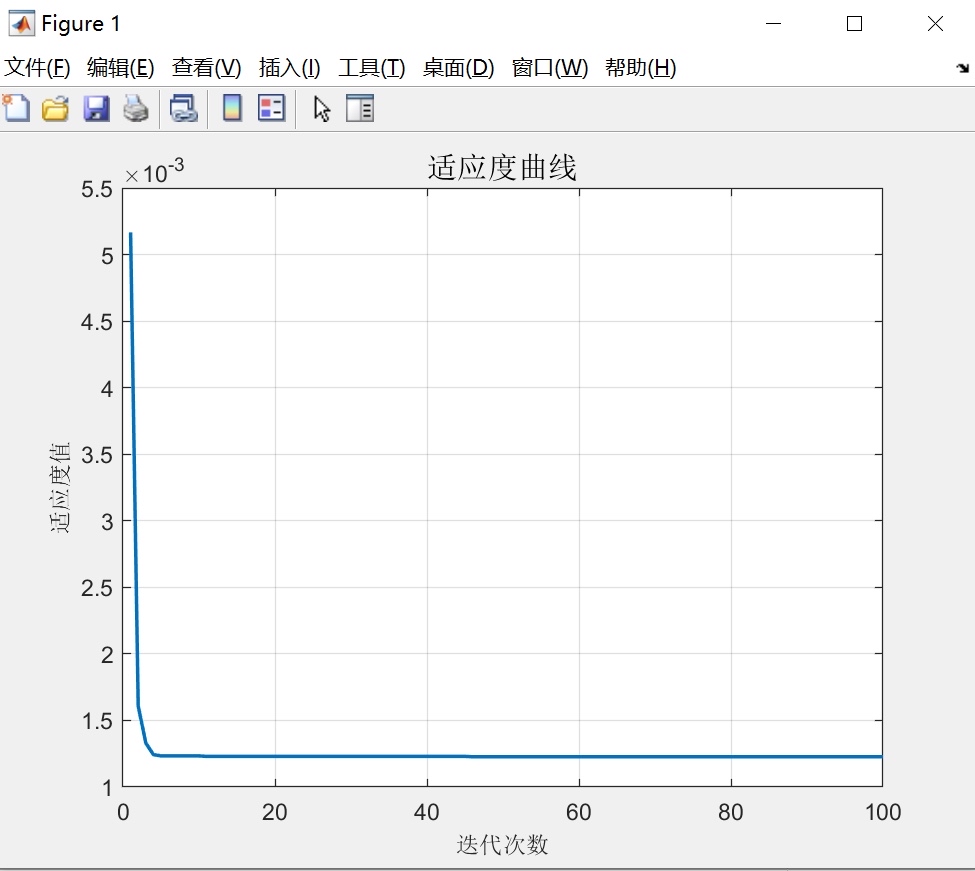
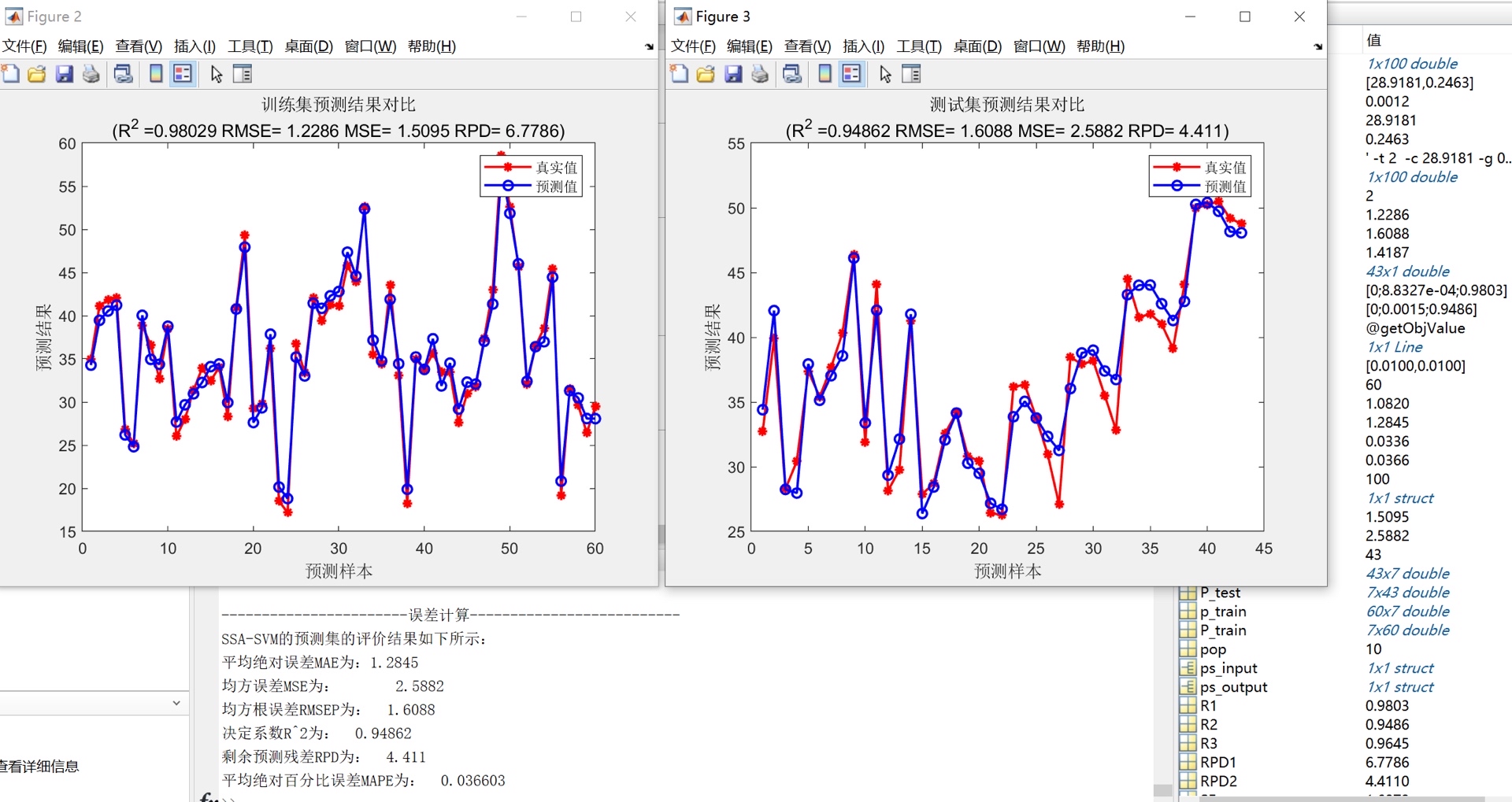
SSA算法被广泛应用于优化问题,并且在缺乏问题先验知识时表现出色。本文将探讨如何利用麻雀搜索算法(SSA)优化支持向量机(SVM)模型中的超参数c和g,以及如何建立多列数据输入、单列数据输出的拟合预测模型。该模型具有直接替换数据即可使用的便利性,并且能够打印出多个常用的模型评价指标。
首先,我们来介绍一下麻雀搜索算法(SSA)。SSA是一种基于麻雀的觅食行为的启发式优化算法,它通过模拟麻雀的觅食过程来搜索最优解。SSA算法具有较好的全局搜索能力和收敛性,因此在求解复杂优化问题时具有一定的优势。在本文中,我们将利用SSA算法来优化SVM模型中的超参数c和g。
SVM是一种常用的机器学习算法,它在分类和回归问题中表现出色。然而,SVM模型的性能很大程度上依赖于超参数c和g的选择。在传统的SVM中,超参数的选择通常是通过网格搜索等方法来确定的,这种方法的缺点是计算量大且耗时。我们通过引入SSA算法来优化超参数的选择,可以大大提高SVM模型的性能。
接下来,我们将建立多列数据输入、单列数据输出的拟合预测模型。在实际应用中,我们通常需要建立一个能够根据输入数据预测输出数据的模型。传统的拟合预测模型通常只能处理单个输入和输出变量,而在实际问题中,往往涉及多个输入变量和一个输出变量。为了建立多列数据输入、单列数据输出的模型,我们需要对输入数据进行适当的处理。
在建立模型之前,我们需要确保程序内的注释详细,使得使用者能够理解每一步的操作。同时,我们还要提供清晰简洁的代码,让使用者可以直接替换数据并使用该模型。不仅如此,我们还要为使用者提供多个常用的模型评价指标,以便他们可以对模型的性能进行准确评估。
综上所述,本文以SSA算法为基础,通过优化SVM模型的超参数c和g,并建立多列数据输入、单列数据输出的拟合预测模型。通过详细的注释和清晰简洁的代码,该模型具有便利性和实用性,并能打印出多个常用的模型评价指标。通过这些工作,我们希望能够为程序员社区的读者提供一个实实在在的技术分析文章,帮助他们在实际问题中应用SSA算法优化SVM模型,并建立拟合预测模型。
以上相关代码,程序地址:http://coupd.cn/676695227372.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









