






mybatis-plus
开篇:
简介:
MyBatis Plus (简称 MP) 是一款持久层框架,说白话就是一款操作数据库的框架。它是一个 MyBatis 的增强工具,就像 iPhone手机一般都有个 plus 版本一样,它在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
Mybatis Plus 特性:
**1、无侵入:**只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
**2、损耗小:**启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
**3、强大的 CRUD 操作:**内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
**4、支持 Lambda 形式调用:**通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
**5、支持主键自动生成:**支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
**6、支持 ActiveRecord 模式:**支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
**7、支持自定义全局通用操作:**支持全局通用方法注入( Write once, use anywhere )
**8、内置代码生成器:**采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
**9、内置分页插件:**基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
**10、分页插件支持多种数据库:**支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
**11、内置性能分析插件:**可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
**12、内置全局拦截插件:**提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
框架结构:
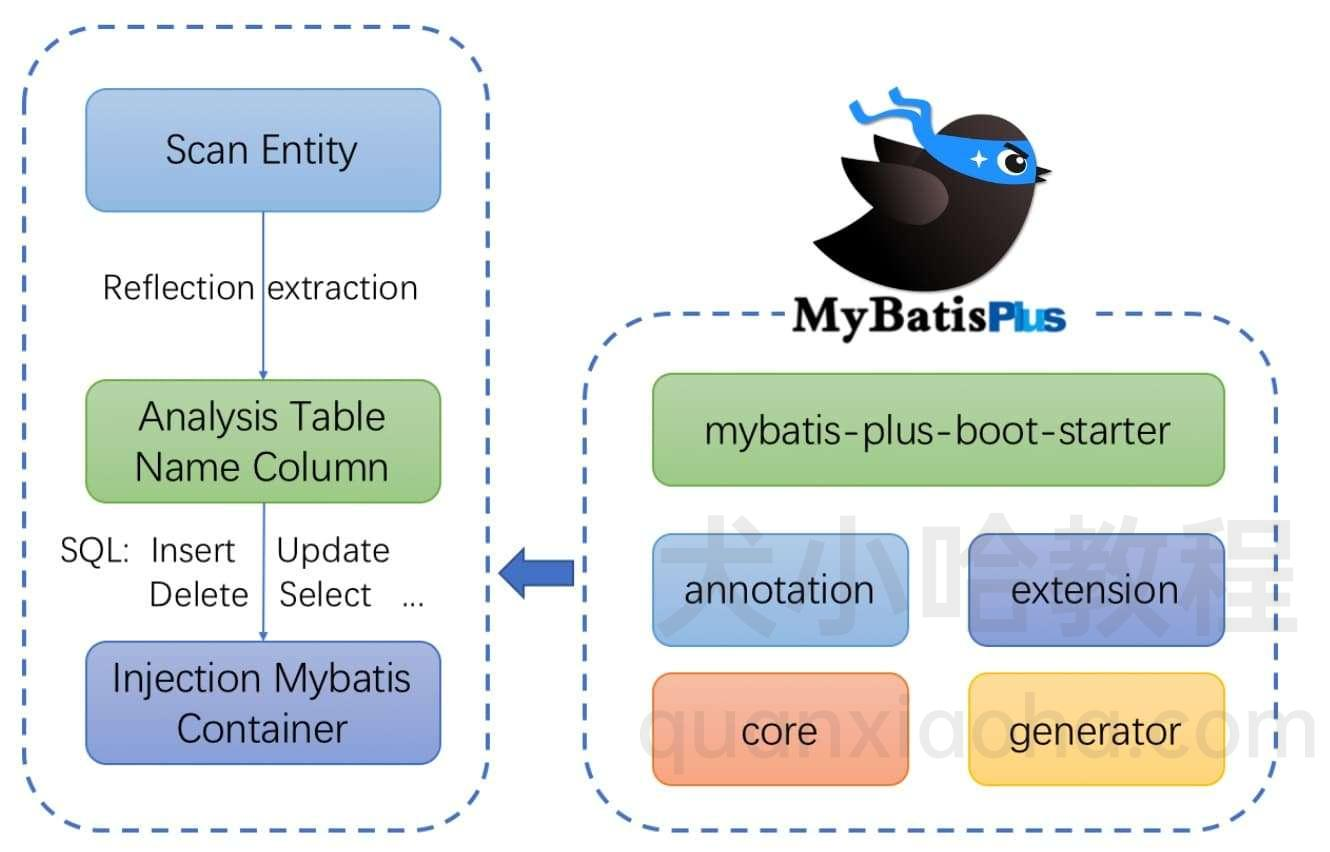
1、快速开始
2、新建测试库与表
新建一个名为 test 的测试数据库,并创建一张用户表,Schema 建表脚本如下:
DROP TABLE IF EXISTS t_user;
CREATE TABLE `t_user` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男',
PRIMARY KEY (`id`)
) COMMENT = '用户表';
3、新建 Spring Boot 示例项目
数据库准备好了,我们来新建一个 Spring Boot 示例项目,用来讲解如何使用 Mybatis Plus,先放一张示例项目目录结构截图:
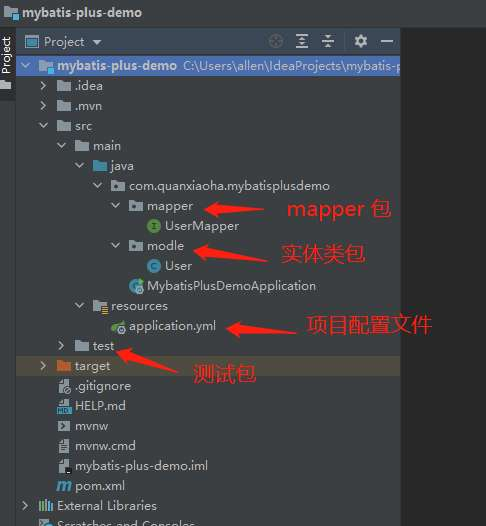
4、添加 Mybatis Plus 依赖
在 pom.xml 文件中添加以下依赖:
<!-- mybatis-plus 依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<!-- 单元测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- lombok 依赖(免写 setXXX/getXXX 方法) -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
</dependency>
<!-- mysql 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
5、添加配置
# 数据库配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8
username: root
password: xxxx
然后,在项目根目录下新建一个 config 包,并创建 MybatisPlusConfig 配置类:
@Configuration
@MapperScan("com.yichat.mybatisplusdemo.mapper")
public class MybatisPlusConfig {
}
6、添加实体类
@Data
@Builder
@TableName("t_user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
@TableField(value = "name")
private String name;
@TableField(value = "age")
private Integer age;
@TableField(value = "gender")
private Integer gender;
}
@TableName(“t_user”) 注解用于指定表名;
@TableId(type = IdType.AUTO) 注解指定了字段 id 为表的主键,同时指定主键为自增类型。
@TableField(value = “name”)该实体类的属性与表中value字段符合的相对应
7、添加 Mapper 类
在项目根目录下创建 mapper 包,并新建 UserMapper 接口,同时继承自 BaseMapper, 代码如下:
public interface UserMapper extends BaseMapper<User> {
}
BaseMapper 接口由 Mybatis Plus 提供,封装了一些常用的 CRUD 操作,使得我们无需像 Mybatis 那样编写 xml 文件,就拥有了基本的 CRUD 功能,点击 BaseMapper 接口,源码如下:
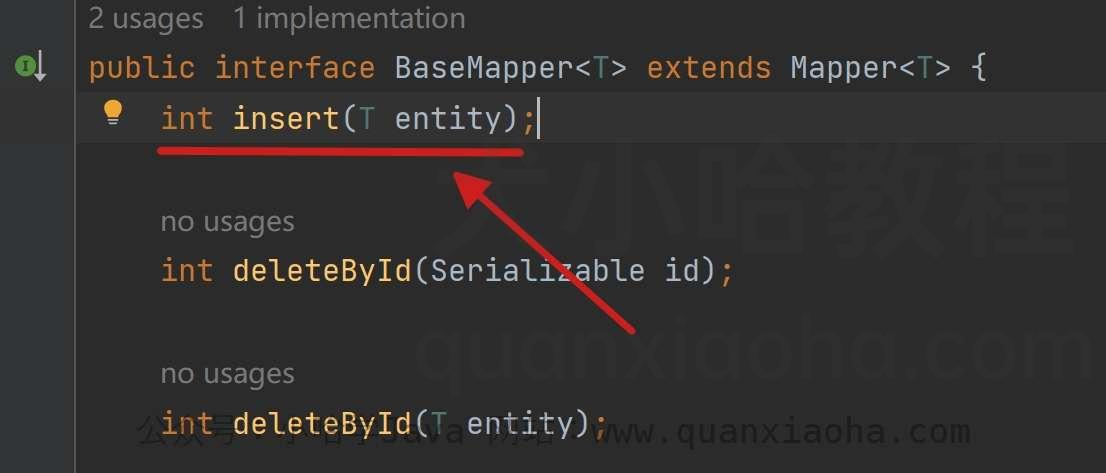
public interface BaseMapper<T> extends Mapper<T> {
// 新增数据
int insert(T entity);
// 根据 ID 删除
int deleteById(Serializable id);
// 删除数据
int deleteByMap(@Param("cm") Map<String, Object> columnMap);
// 删除数据
int delete(@Param("ew") Wrapper<T> queryWrapper);
// 根据 ID 批量删除数据
int deleteBatchIds(@Param("coll") Collection<? extends Serializable> idList);
// 根据 ID 更新
int updateById(@Param("et") T entity);
// 更新数据
int update(@Param("et") T entity, @Param("ew") Wrapper<T> updateWrapper);
// 根据 ID 查询
T selectById(Serializable id);
// 根据 ID 批量查询
List<T> selectBatchIds(@Param("coll") Collection<? extends Serializable> idList);
// 查询数据
List<T> selectByMap(@Param("cm") Map<String, Object> columnMap);
// 查询一条数据
T selectOne(@Param("ew") Wrapper<T> queryWrapper);
// 查询记录总数
Integer selectCount(@Param("ew") Wrapper<T> queryWrapper);
// 查询多条数据
List<T> selectList(@Param("ew") Wrapper<T> queryWrapper);
// 查询多条数据
List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> queryWrapper);
// 查询多条数据
List<Object> selectObjs(@Param("ew") Wrapper<T> queryWrapper);
// 分页查询
<E extends IPage<T>> E selectPage(E page, @Param("ew") Wrapper<T> queryWrapper);
// 分页查询
<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param("ew") Wrapper<T> queryWrapper);
}
8、简单的 CRUD
@SpringBootTest
class MybatisPlusBaseMapperTests {
@Autowired
private UserMapper userMapper;
/**
* 查询数据
*/
@Test
public void testSelectUser() {
System.out.println(("----- 开始测试 mybatis-plus 查询数据 ------"));
// selectList() 方法的参数为 mybatis-plus 内置的条件封装器 Wrapper,这里不填写表示无任何条件,全量查询
List<User> userList = userMapper.selectList(null);
userList.forEach(System.out::println);
}
/**
* 新增一条数据
*/
@Test
public void testInsertUser() {
System.out.println(("----- 开始测试 mybatis-plus 插入数据 ------"));
User user = User.builder()
.name("测试")
.age(30)
.gender(1)
.build();
userMapper.insert(user);
}
/**
* 删除数据
*/
@Test
public void testDeleteUser() {
System.out.println(("----- 开始测试 mybatis-plus 删除数据 ------"));
// 根据主键删除记录
userMapper.deleteById(1);
// 根据主键批量删除记录
userMapper.deleteBatchIds(Arrays.asList(1, 2));
}
/**
* 更新数据
*/
@Test
public void testUpdateUser() {
System.out.println(("----- 开始测试 mybatis-plus 更新数据 ------"));
User user = User.builder()
.id(1L)
.name("测试")
.build();
userMapper.updateById(user);
}
}
Mybatis Plus 打印 SQL 语句(包含执行耗时)
我们已经使用 Mybatis Plus 对数据库进行了最简单的 CRUD 操作,但是在实际项目中,增删改查操作会更加复杂,接下来,我们将更加深入的学习 Mybatis Plus 的增删改查。
在这之前呢,我们先配置一下 Mybatis Plus 打印 SQL 功能(包括执行耗时),以方便我们更直观的学习 CRUD, 一方面可以了解到每个操作都具体执行的什么 SQL 语句, 另一方面通过打印执行耗时,也可以规避一些慢 SQL,提前做好优化。
1、引入依赖
<dependency>
<groupId>p6spy</groupId>
<artifactId>p6spy</artifactId>
<version>最新版本</version>
</dependency>
2、添加配置
2.1 第一步:修改 application.yml 配置文件:
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:mysql://127.0.0.1:3306/test?characterEncoding=utf-8
注意:
driver-class-name 用 p6spy 提供的驱动类;
url 前缀为 jdbc:p6spy 跟着冒号,后面对应数据库连接地址;
2.2 第二步:添加 p6spy 配置文件
然后在 resources 目录下添加 spy.properties 配置文件:
配置文件内容如下:
#3.2.1以上使用
modulelist=com.baomidou.mybatisplus.extension.p6spy.MybatisPlusLogFactory,com.p6spy.engine.outage.P6OutageFactory
#3.2.1以下使用或者不配置
#modulelist=com.p6spy.engine.logging.P6LogFactory,com.p6spy.engine.outage.P6OutageFactory
# 自定义日志打印
logMessageFormat=com.baomidou.mybatisplus.extension.p6spy.P6SpyLogger
#日志输出到控制台
appender=com.baomidou.mybatisplus.extension.p6spy.StdoutLogger
# 使用日志系统记录 sql
#appender=com.p6spy.engine.spy.appender.Slf4JLogger
# 设置 p6spy driver 代理
deregisterdrivers=true
# 取消JDBC URL前缀
useprefix=true
# 配置记录 Log 例外,可去掉的结果集有error,info,batch,debug,statement,commit,rollback,result,resultset.
excludecategories=info,debug,result,commit,resultset
# 日期格式
dateformat=yyyy-MM-dd HH:mm:ss
# 实际驱动可多个
#driverlist=org.h2.Driver
# 是否开启慢SQL记录
outagedetection=true
# 慢SQL记录标准 2 秒
outagedetectioninterval=2
3、看看打印效果
配置添加完成后,单元测试执行一条插入语句:
@Test
void testInsertUser() {
System.out.println(("----- 开始测试 mybatis-plus 插入数据 ------"));
User user = User.builder()
.name("测试")
.age(30)
.gender(1)
.build();
userMapper.insert(user);
}
执行之后可以看到完整的打印了执行语句
增删改查
1、新增数据
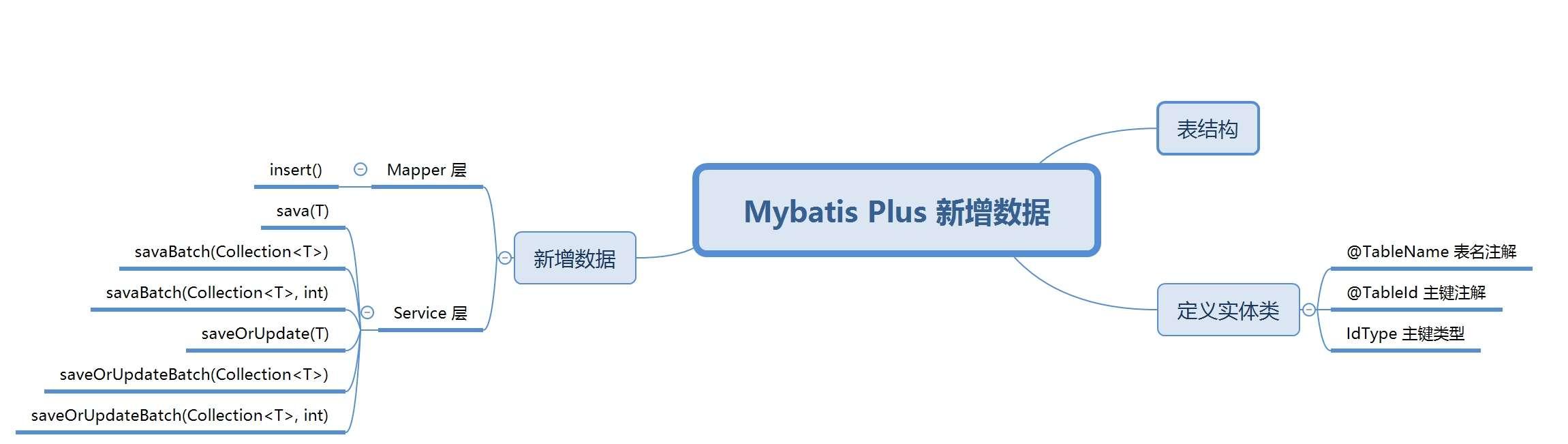
1.1 表结构
DROP TABLE IF EXISTS t_user;
CREATE TABLE `t_user` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男',
PRIMARY KEY (`id`)
) COMMENT = '用户表';
1.2 定义实体类
@Data
@TableName("t_user")
public class User {
/**
* 主键 ID, @TableId 注解定义字段为表的主键,type 表示主键类型,IdType.AUTO 表示随着数据库 ID 自增
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
}
@TableName 表名注解
作用:标识实体类对应的表。
TIP :
当实体类名称和实际表名一致时,如实体名为 User, 表名为 user ,可不用添加该注解,Mybatis Plus 会自动识别并映射到该表。
当实体类名称和实际表名不一致时,如实体名为 User, 表名为 t_user,需手动添加该注解,并填写实际表名称。
@TableId 主键注解
作用:声明实体类中的主键对应的字段。
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 主键字段名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType 主键类型
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(默认) |
| INPUT | 插入数据前,需自行设置主键的值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID (默认 default 方法) |
| 分布式全局唯一 ID 长整型类型 (推荐使用 ASSIGN_ID) | |
| 32 位 UUID 字符串 (推荐使用 ASSIGN_UUID) | |
| 分布式全局唯一 ID 字符串类型 (推荐使用 ASSIGN_ID) |
新增数据
测试表准备好后,我们准备开始演示新增数据。实际上,Mybatis Plus 对 Mapper 层和 Service 层都将常见的增删改查操作都封装好了,只需简单的继承,即可轻松搞定对数据的增删改查,本文重点讲解新增数据这块。
Mapper 层:
public interface UserMapper extends BaseMapper<User> {
}
然后,注入 Mapper :
@Autowired
private UserMapper userMapper;
BaseMapper 提供的新增方法仅一个 insert() 方法:
我们通过它测试一下添加数据,并获取主键 ID :
User user = new User();
user.setName(“测试”);
user.setAge(30);
user.setGender(1);
userMapper.insert(user);
// 获取插入数据的主键 ID
Long id = user.getId();
System.out.println(“id:” + id);
Service 层:
Mybatis Plus 同样也封装了通用的 Service 层 CRUD 操作,并且提供了更丰富的方法。接下来,我们上手看 Service 层的代码结构,如下图:
先定义 UserService 接口 ,让其继承自 IService:
public interface UserService extends IService<User> {
}
再定义实现类 UserServiceImpl,让其继承自 ServiceImpl, 同时实现 UserService 接口,这样就可以让 UserService 拥有了基础通用的 CRUD 功能,当然,实际开发中,业务会更加复杂,就需要向 IService 接口自定义方法并实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
注入 UserService :
@Autowired
private UserService userService;
与 Mapper 层不同的是,Service 层的新增方法均以 save 开头,并且功能更丰富,来看看都提供了哪些方法:
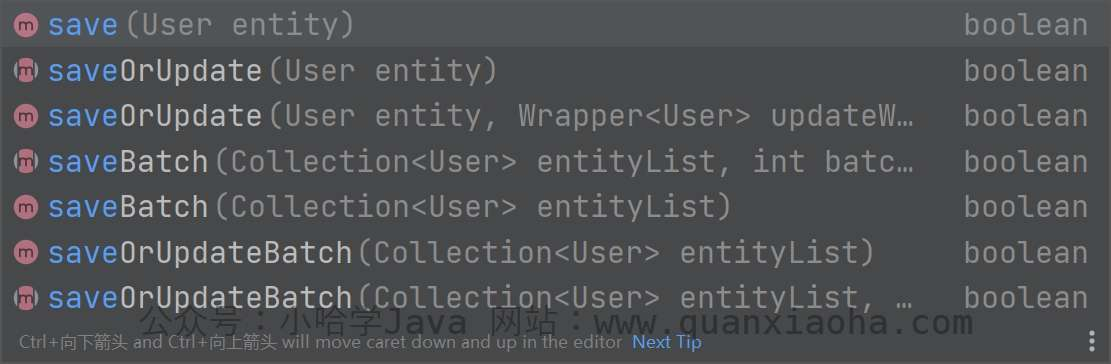
简单解释下每个方法的作用,以作了解:
// 新增数据
sava(T) : boolean
// 伪批量插入,实际上是通过 for 循环一条一条的插入
savaBatch(Collection<T>) : boolean
// 伪批量插入,int 表示批量提交数,默认为 1000
savaBatch(Collection<T>, int) : boolean
// 新增或更新(单条数据)
saveOrUpdate(T) : boolean
// 批量新增或更新
saveOrUpdateBatch(Collection<T>) : boolean
// 批量新增或更新(可指定批量提交数)
saveOrUpdateBatch(Collection<T>, int) : boolean
sava(T)
// 新增数据
// 实际执行 SQL : INSERT INTO user ( name, age, gender ) VALUES ( '测试', 30, 1 )
User user = new User();
user.setName("测试");
user.setAge(30);
user.setGender(1);
boolean isSuccess = userService.save(user);
// 返回主键ID
Long id = user.getId();
System.out.println("isSuccess:" + isSuccess);
System.out.println("主键 ID: " + id);
savaBatch(Collection)
伪批量插入,注意,命名虽然包含了批量的意思,但这不是真的批量插入,不信的话,我们来实际测试一下:
// 批量插入
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setName("测试" + i);
user.setAge(i);
user.setGender(1);
users.add(user);
}
boolean isSuccess = userService.saveBatch(users);
System.out.println("isSuccess:" + isSuccess);
这里的批量插入并不是 insert into user (xxx) values (xxx),(xxx),(xxx) 这种批量形式,还是一条一条插入的。
批量新增源码分析
我们来看下源码, 内部的saveBatch() 方法默认的批量提交阀值参数,数值为 1000, 即达到 1000 条批量提交一次,继续点进去看:

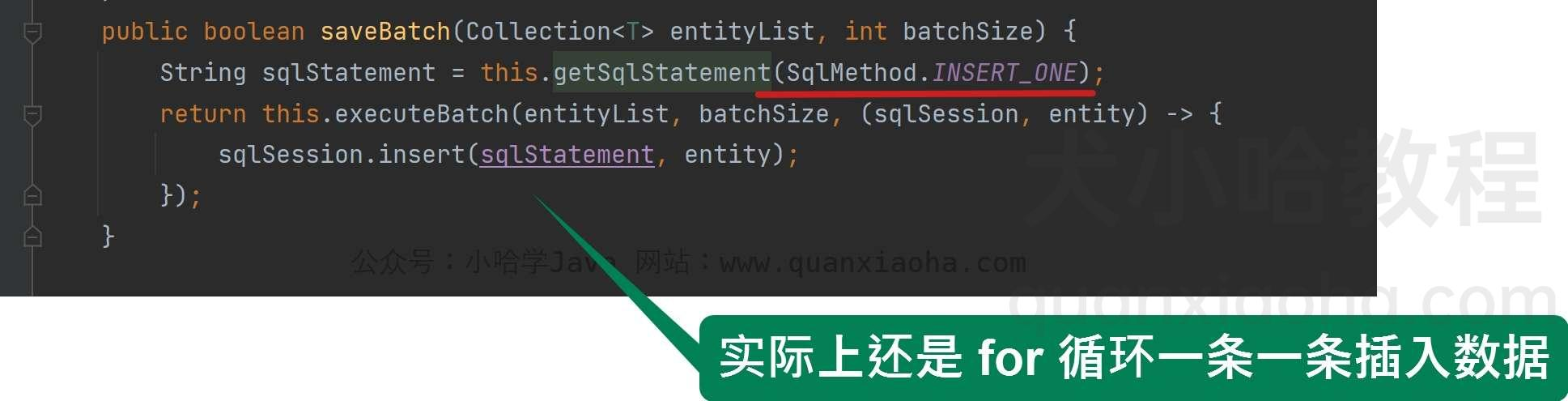
public boolean saveBatch(Collection<T> entityList, int batchSize) {
// 获取预编译的插入 SQL
String sqlStatement = this.getSqlStatement(SqlMethod.INSERT_ONE);
// for 循环执行 insert
return this.executeBatch(entityList, batchSize, (sqlSession, entity) -> {
sqlSession.insert(sqlStatement, entity);
});
}
再看下 SqlMethod.INSERT_ONE 这个枚举,描述信息为插入一条数据:

继续往 executeBatch() 方法里看,瞅瞅它这个批量到底是怎么处理的,具体每行代码的意思,小哈都加了注释:
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
// 断言需要批处理数据集大小不等于1
Assert.isFalse(batchSize < 1, "batchSize must not be less than one", new Object[0]);
// 判空数据集,若不为空,则开始执行批量处理
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, (sqlSession) -> {
int size = list.size();
// 将批处理大小与传入的操作集合大小进行比较,取最小的那个
int idxLimit = Math.min(batchSize, size);
int i = 1;
// 迭代器循环
for(Iterator var7 = list.iterator(); var7.hasNext(); ++i) {
// 获取当前需要执行的数据库操作
E element = var7.next();
// 回调 sqlSession.insert() 方法
consumer.accept(sqlSession, element);
// 判断是否达到需要批处理的阀值
if (i == idxLimit) {
// 开始批处理,此方法执行并清除缓存在 JDBC 驱动类中的执行语句
sqlSession.flushStatements();
idxLimit = Math.min(idxLimit + batchSize, size);
}
}
});
}
相比较自己手动 for 循环执行插入,Mybatis Plus 这个伪批量插入性能会更好些,内部会将每次的插入语句缓存起来,等到达到 1000 条的时候,才会统一推给数据库,虽然最终在数据库那边还是一条一条的执行 INSERT,但还是在和数据库交互的 IO 上做了优化。
savaBatch(Collection, int)
多了个 batchSize 参数,可以手动指定批处理的大小,即多少 SQL 操作执行一次,默认为 1000。
saveOrUpdate(T)
保存或者更新。即当你需要执行的数据,数据库中不存在时,就执行插入操作:
// 实际执行 SQL : INSERT INTO user ( name, age, gender ) VALUES ( '测试', 60, 1 )
User user = new User();
user.setName("测试");
user.setAge(60);
user.setGender(1);
userService.saveOrUpdate(user);
当你需要执行的数据,数据库中已存在时,就执行更新操作。框架是如何判断该记录是否存在呢? 如设置了主键 ID,因为主键 ID 必须是唯一的,Mybatis Plus 会先执行查询操作,判断数据是否存在,存在即执行更新,否则,执行插入操作:
User user = new User();
// 设置了主键字段
user.setId(21L);
user.setName("测试");
user.setAge(60);
user.setGender(1);
userService.saveOrUpdate(user);
saveOrUpdateBatch(Collection)
批量保存或者更新,示例代码如下:
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setId(Long.valueOf(i));
user.setName("测试" + i);
user.setAge(i+1);
user.setGender(1);
users.add(user);
}
userService.saveOrUpdateBatch(users);
saveOrUpdateBatch(Collection, int)
批量保存或者更新(可手动指定批量大小),示例代码如下:
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setId(Long.valueOf(i));
user.setName("测试" + i);
user.setAge(i+1);
user.setGender(1);
users.add(user);
}
userService.saveOrUpdateBatch(users, 100);
2.删除数据
表结构和实体类就沿用之前的
删除数据
Mybatis Plus 对 Mapper 层和 Service 层都将常见的增删改查操作封装好了,只需简单的继承,即可轻松搞定对数据的增删改查。
Mapper 层
定义一个 UserMapper , 让其继承 BaseMapper :
public interface UserMapper extends BaseMapper<User> {
}
@Autowired
private UserMapper userMapper;
删除相关的方法均以 delete 开头,方法如下:

解释一下每个方法的作用:
// 根据主键 ID 删除 (直接传入 ID)
int deleteById(Serializable id);
// 根据主键 ID 删除 (传入实体类)
int deleteById(T entity);
// 根据主键 ID 批量删除
int deleteBatchIds(Collection<?> idList)
// 通过 Wrapper 条件构造器删除
int delete(Wrapper<T> queryWrapper);
// 通过 Map 设置条件来删除
int deleteByMap(Map<String, Object> columnMap);
示例代码
根据主键 ID 删除 (直接传入 ID):
// 实际执行的 SQL : DELETE FROM user WHERE id=9
int count = userMapper.deleteById(9L);
System.out.println("受影响的行数:" + count);
根据主键 ID 删除 (传入实体类):
User user = new User();
user.setId(9L);
// 实际执行的 SQL : DELETE FROM user WHERE id=9
int count = userMapper.deleteById(user);
System.out.println("受影响的行数:" + count);
根据主键 ID 批量删除:
// 根据 ID 批量删除
List ids = new ArrayList<>();
ids.add(1L);
ids.add(2L);
// 实际执行 SQL 为 :DELETE FROM user WHERE id IN ( 1 , 2 )
userMapper.deleteBatchIds(ids);
通过 Wrapper 条件构造器删除:
// 构造删除条件
QueryWrapper wrapper = new QueryWrapper<>();
wrapper.eq("name", "测试");
wrapper.eq("age", 1);
// 实际执行 SQL 为 :DELETE FROM user WHERE (name = '测试' AND age = 1)
userMapper.delete(wrapper);
// Lambda 表达式形式
userMapper.delete(new QueryWrapper<User>()
.lambda()
.eq(User::getName, "测试")
.eq(User::getAge, 1));
通过 Map 设置条件来删除:
// 通过 Map 设置条件来删除
Map<String, Object> columnMap = new HashMap<>();
columnMap.put("name", "测试");
columnMap.put("age", 1);
int count = userMapper.deleteByMap(columnMap);
System.out.println("受影响的行数:" + count);
Service 层
Mybatis Plus 同样也封装了通用的 Service 层 CRUD 操作,并且提供了更丰富的方法。接下来,我们上手看 Service 层的代码结构,如下图:
先定义 UserService 接口 ,让其继承自 IService:
public interface UserService extends IService<User> {
}
再定义实现类 UserServiceImpl,让其继承自 ServiceImpl, 同时实现 UserService 接口,这样就可以让 UserService 拥有了基础通用的 CRUD 功能,当然,实际开发中,业务会更加复杂,就需要向 IService 接口自定义方法并实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
@Autowired
private UserService userService;
Service 层封装的删除方法均以 remove 开头,方法如下:
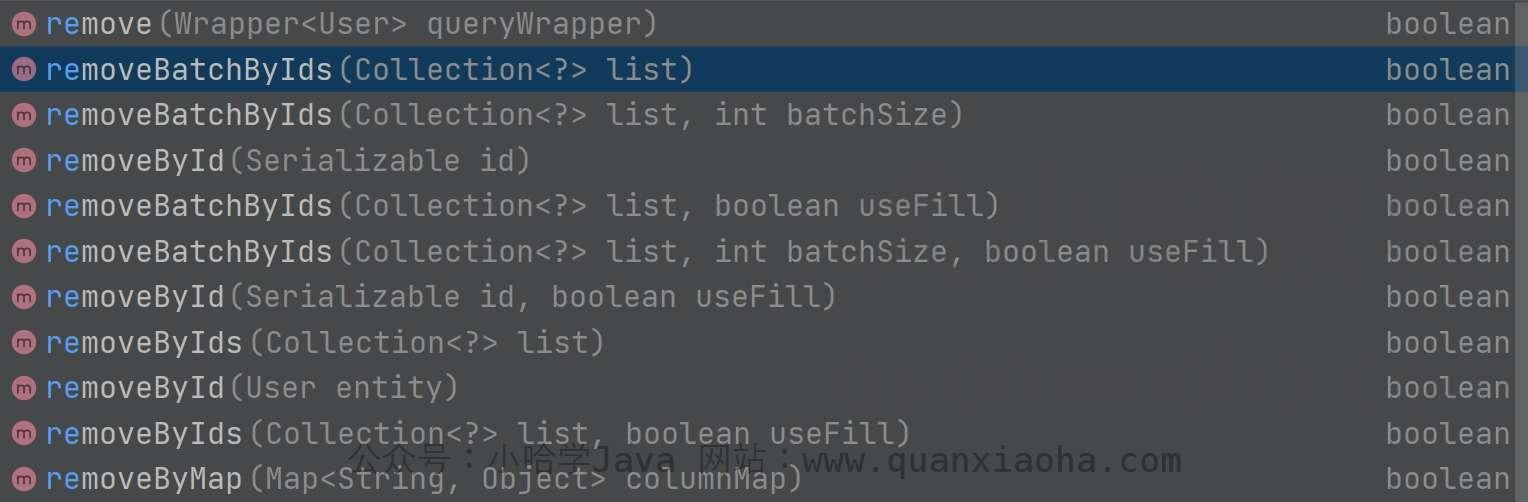
这里把常用的一些删除方法摘出来:
// 根据 entity 条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);
3.更新数据
表结构和实体类就沿用之前的
更新数据
Mybatis Plus 对 Mapper 层和 Service 层都将常见的增删改查操作封装好了,只需简单的继承,即可轻松搞定对数据的增删改查,本文重点讲解修改数据部分。
Mapper 层
定义一个 UserMapper , 让其继承 BaseMapper :
public interface UserMapper extends BaseMapper<User> {
}
@Autowired
private UserMapper userMapper;
BaseMapper 提供的修改方法以 update 开头,方法如下:

解释一下每个方法的作用:
# 根据主键 ID 来更新
int updateById(T entity);
# entity 用于设置更新的数据,wrapper 用于组装更新条件
int update(T entity, Wrapper<T> updateWrapper);
示例代码
根据主键 ID 来更新:
User user = new User();
user.setId(1L);
user.setName("修改后的测试");
user.setGender(0);
// 实际执行的 SQL : UPDATE user SET name='修改后的测试', gender=0 WHERE id=1
int count = userMapper.updateById(user);
System.out.println("受影响的行数:" + count);
entity 用于设置更新的数据,wrapper 用于组装更新条件
User user = new User();
user.setName("修改后的测试");
user.setGender(0);
// 组装更新条件,更新 age = 20 的数据
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("age", 20);
// 实际执行的 SQL : UPDATE user SET name='修改后的测试', gender=0 WHERE (age = 20)
int count = userMapper.update(user, updateWrapper);
System.out.println("受影响的行数:" + count);
Service 层
Mybatis Plus 同样也封装了通用的 Service 层 CRUD 操作,并且提供了更丰富的方法。接下来,我们上手看 Service 层的代码结构,如下图:
先定义 UserService 接口 ,让其继承自 IService:
public interface UserService extends IService<User> {
}
再定义实现类 UserServiceImpl,让其继承自 ServiceImpl, 同时实现 UserService 接口,这样就可以让 UserService 拥有了基础通用的 CRUD 功能,当然,实际开发中,业务会更加复杂,就需要向 IService 接口自定义方法并实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
注入 UserService :
@Autowired
private UserService userService;
Service 层封装的更新方法均以 update 开头,方法如下:
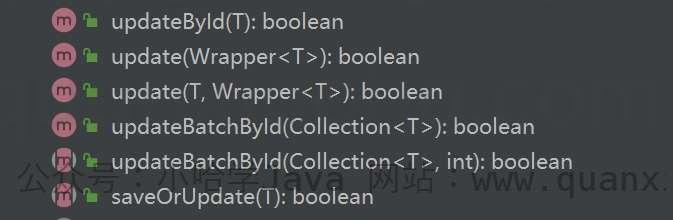
这里把常用的一些删除方法摘出来:
// 根据 ID 来更新,entity 用于设置 ID 以及其他更新条件
boolean updateById(T entity);
// wrapper 用于设置更新数据以及条件
boolean update(Wrapper<T> updateWrapper);
// entity 用于设置更新的数据,wrapper 用于组装更新条件
boolean update(T entity, Wrapper<T> updateWrapper);
// 批量更新
boolean updateBatchById(Collection<T> entityList);
// 批量更新,可手动设置批量提交阀值
boolean updateBatchById(Collection<T> entityList, int batchSize);
// 保存或者更新
boolean saveOrUpdate(T entity);
示例代码
Service 层和上面 Mapper 的使用方法差不多,这里演示一下 boolean update(Wrapper updateWrapper) 使用示例:
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
// set name = '更新后的测试'
updateWrapper.set("name", "更新后的测试");
// where id = 1 AND age = 30
updateWrapper.eq("id", 1L).eq("age", 30);
// 实际执行 SQL : UPDATE user SET name='更新后的测试' WHERE (id = 1 AND age = 30)
boolean isSuccess = userService.update(updateWrapper);
System.out.println("更新是否成功:" + isSuccess);
4.查询数据
表结构和实体类就沿用之前的
查询数据
Mybatis Plus 对 Mapper 层和 Service 层都将常见的增删改查操作封装好了,只需简单的继承,即可轻松搞定对数据的增删改查,本文重点讲解查询相关的部分。
Mapper 层
定义一个 UserMapper , 让其继承自 BaseMapper :
public interface UserMapper extends BaseMapper<User> {
}
然后,注入 Mapper :
@Autowired
private UserMapper userMapper;
BaseMapper 提供的查询相关的方法如下:
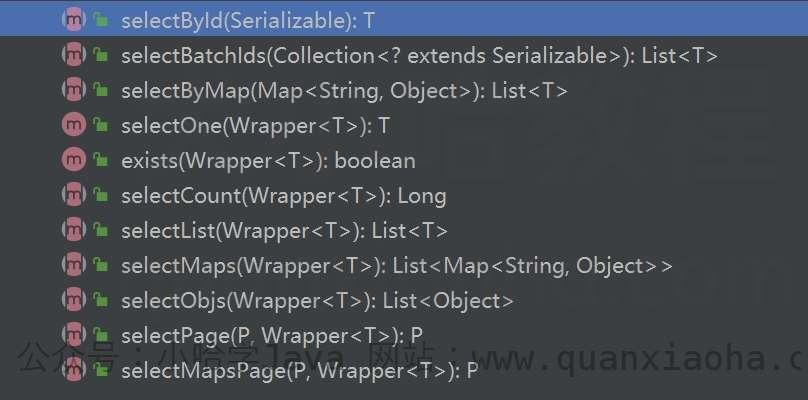
解释一下每个方法的作用:
// 根据 ID 查询
T selectById(Serializable id);
// 通过 Wrapper 组装查询条件,查询一条记录
T selectOne(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
List<T> selectBatchIds(Collection<? extends Serializable> idList);
// 通过 Wrapper 组装查询条件,查询全部记录
List<T> selectList(Wrapper<T> queryWrapper);
// 查询(根据 columnMap 来设置条件)
List<T> selectByMap(Map<String, Object> columnMap);
// 根据 Wrapper 组装查询条件,查询全部记录,并以 map 的形式返回
List<Map<String, Object>> selectMaps(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(Wrapper<T> queryWrapper);
// =========================== 分页相关 ===========================
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(Wrapper<T> queryWrapper);
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Serializable | id | 主键 ID |
| Wrapper | queryWrapper | 实体对象封装操作类(可以为 null) |
| Collection<? extends Serializable> | idList | 主键 ID 列表(不能为 null 以及 empty) |
| Map<String, Object> | columnMap | 表字段 map 对象 |
| IPage | page | 分页查询条件(可以为 RowBounds.DEFAULT) |
示例代码
1、根据 ID 查询:
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE id=1
User user = userMapper.selectById(1L);
2、通过 Wrapper 组装查询条件,查询一条记录:
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// 仅查询 id, name 字段
queryWrapper.select("id", "name");
// where id = 1
queryWrapper.eq("id", 1L);
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE (id = 1)
User user = userMapper.selectOne(queryWrapper);
注意: selectOne 方法期望仅返回一条数据,若实际查询到多条数据,会主动抛出异常,内部源码如下:
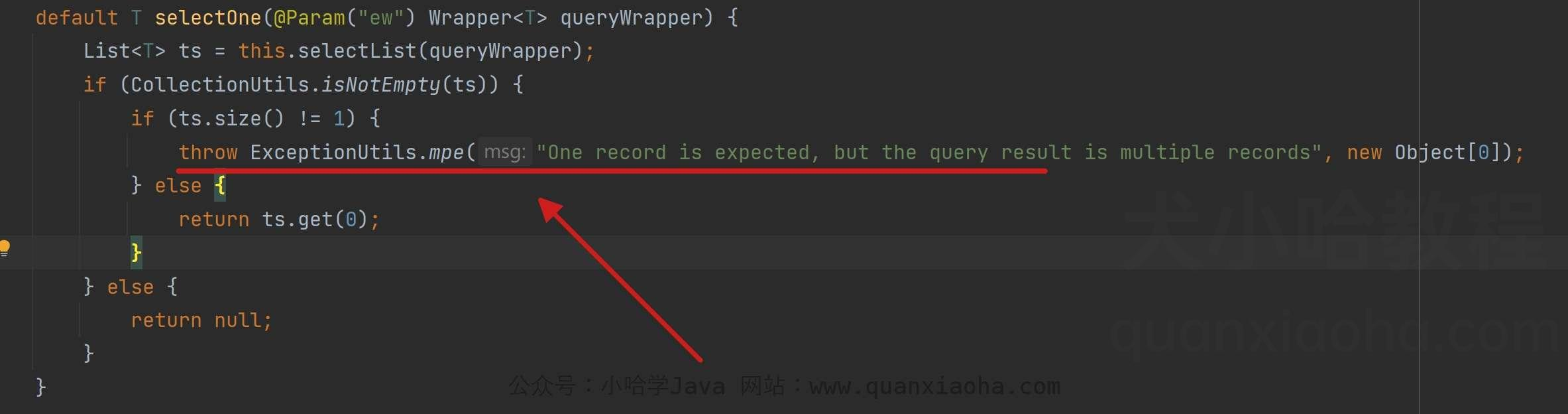
2、查询(根据ID 批量查询):
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE id IN ( 1 , 2 , 3 )
List users = userMapper.selectBatchIds(Arrays.asList(1L, 2L, 3L));
3、通过 Wrapper 组装查询条件,查询全部记录:
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// 仅查询 id, name 字段
queryWrapper.select("id", "name");
// where age = 30
queryWrapper.eq("age", 30);
// 实际执行 SQL : SELECT id,name FROM user WHERE (age = 30)
List<User> users = userMapper.selectList(queryWrapper);
4、查询(根据 columnMap 来设置条件):
// 通过 map 来设置查询条件
Map<String, Object> columnMap = new HashMap<>();
columnMap.put("name", "测试");
columnMap.put("age", 30);
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE name = '测试' AND age = 30
List<User> users = userMapper.selectByMap(columnMap);
5、根据 Wrapper 组装查询条件,查询全部记录,并以 map 的形式返回:
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// 仅查询 id, name 字段
queryWrapper.select("id", "name");
// where age = 30
queryWrapper.eq("age", 30);
// 实际执行 SQL : SELECT id,name FROM user WHERE (age = 30)
List<Map<String,Object>> users = userMapper.selectMaps(queryWrapper);
6、根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值:
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// where age = 30
queryWrapper.eq("age", 30);
// 实际执行 SQL : SELECT id,name FROM user WHERE (age = 30)
List<Object> ids = userMapper.selectObjs(queryWrapper);
7、根据 Wrapper 条件,查询总记录数:
// 组装查询条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name", "测试").eq("age", 30);
// 实际执行 SQL : SELECT COUNT( * ) FROM user WHERE (name = '测试' AND age = 30)
long count = userMapper.selectCount(queryWrapper);
System.out.println("总记录数:" + count);
Service 层
Mybatis Plus 同样也封装了通用的 Service 层 CRUD 操作,并且提供了更丰富的方法。接下来,我们上手看 Service 层的代码结构,如下图:
先定义 UserService 接口 ,让其继承自 IService:
public interface UserService extends IService<User> {
}
再定义实现类 UserServiceImpl,让其继承自 ServiceImpl, 同时实现 UserService 接口,这样就可以让 UserService 拥有了基础通用的 CRUD 功能,当然,实际开发中,业务会更加复杂,就需要向 IService 接口自定义方法并实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
注入 UserService :
@Autowired
private UserService userService;
Service 层封装的查询方法注意分为 4 块:
- getXXX : get 开头的方法;
- listXXX : list 开头的方法,用于查询多条数据;
- pageXXX : page 开头的方法,用于分页查询;
- count : 用于查询总记录数;
get 相关方法
get 开头的相关方法用于查询一条记录,方法如下:
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。如果结果集是多个会抛出异常
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录,以 map 的形式返回数据
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Serializable | id | 主键 ID |
| Wrapper | queryWrapper | 实体对象封装操作类 QueryWrapper |
| boolean | throwEx | 有多个 result 是否抛出异常 |
| T | entity | 实体对象 |
| Function<? super Object, V> | mapper | 转换函数 |
示例代码
这里挑两个具有代表性的方法:
1.根据 ID 查询
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE id=1
User user = userService.getById(1L);
2.根据 Wrapper,查询一条记录。如果结果集是多个会抛出异常:
// 组装查询条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("id", 1L).eq("name", "测试");
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE (id = 1 AND name = '测试')
User user = userService.getOne(queryWrapper);
list 相关方法
list 开头的相关方法用于查询多条记录,方法如下:
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表, 以 map 的形式返回
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper | queryWrapper | 实体对象封装操作类 QueryWrapper |
| Collection<? extends Serializable> | idList | 主键 ID 列表 |
| Map<String, Object> | columnMap | 表字段 map 对象 |
| Function<? super Object, V> | mapper | 转换函数 |
示例代码
这里挑几个具有代表性的方法:
// 组装查询条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// where name = '测试' and age >= 20
queryWrapper.eq("name", "测试").ge("age", 20);
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE (name = '测试' AND age >= 20)
List<User> users = userService.list(queryWrapper);
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE id IN ( 1 , 2 , 3 )
List<User> users = userService.listByIds(Arrays.asList(1L, 2L, 3L));
Map<String , Object> columnMap = new HashMap<>();
columnMap.put("name", "测试");
columnMap.put("age", 30L);
// 实际执行 SQL : SELECT id,name,age,gender FROM user WHERE name = '测试' AND age = 30
List<User> users = userService.listByMap(columnMap);
page 分页相关方法
count 查询总记录数
查询总记录数 count 相关方法如下:

// 查询总记录数(不带查询条件)
count();
// 查询总记录数(可以带查询条件)
count(Wrapper<T>)
示例代码
// 组装查询条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// where age = 30
queryWrapper.eq("age", 30);
// 实际执行 SQL : SELECT COUNT( * ) FROM user WHERE (age = 30)
long count = userService.count(queryWrapper);
System.out.println("总记录数:" + count);
5.分页查询数据
为什么需要分页查询?
- 前端页面能够展示的内容有限;
- 当数据库中数据量太多,比如 100W 条,一次性全部返回,查询速度慢,而且内存也顶不住;
表结构和实体类就沿用之前的
新增测试数据
// 循环插入 100 条测试数据
for (int i = 0; i < 100; i++) {
User user = new User();
user.setName("测试" + i);
user.setAge(i);
user.setGender(1);
userMapper.insert(user);
}
添加分页插件
接着,在 MybatisPlusConfig 配置类中,添加分页插件 PaginationInnerInterceptor:

@Configuration
@MapperScan("com.quanxiaoha.mybatisplusdemo.mapper")
public class MybatisPlusConfig {
/**
* 分页插件
* @return
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return interceptor;
}
}
分页查询数据
Mybatis Plus 对 Mapper 层和 Service 层都将常见的增删改查操作封装好了,只需简单的继承,即可轻松搞定对数据的增删改查,本文重点讲解分页查询相关的部分。
Mapper 层
定义一个 UserMapper , 让其继承自 BaseMapper :
public interface UserMapper extends BaseMapper<User> {
}
然后,注入 Mapper :
@Autowired
private UserMapper userMapper;
BaseMapper 提供的分页查询相关的方法如下:

解释一下每个方法的作用:
// 分页查询,page 用于设置需要查询的页数,以及每页展示数据量,wrapper 用于组装查询条件
IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper);
// 同上,区别是用 map 来接受查询的数据
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, Wrapper<T> queryWrapper);
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper | queryWrapper | 实体对象封装操作类(可以为 null) |
| IPage | page | 分页查询条件(可以为 RowBounds.DEFAULT) |
示例代码
// 组装查询条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// where age = 30
queryWrapper.eq("age", 30);
// 查询第 2 页数据,每页 10 条
Page<User> page = new Page<>(2, 10);
page = userMapper.selectPage(page, queryWrapper);
System.out.println("总记录数:" + page.getTotal());
System.out.println("总共多少页:" + page.getPages());
System.out.println("当前页码:" + page.getCurrent());
// 当前页数据
List<User> users = page.getRecords();
Page 类说明:
该类继承了 IPage 类,实现了 简单分页模型 ,如果你要实现自己的分页模型可以继承 Page 类或者实现 IPage 类
| 属性名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| records | List | emptyList | 查询数据列表 |
| total | Long | 0 | 查询列表总记录数 |
| size | Long | 10 | 每页显示条数,默认 10 |
| current | Long | 1 | 当前页 |
| orders | List | emptyList | 排序字段信息,允许前端传入的时候,注意 SQL 注入问题,可以使用 SqlInjectionUtils.check(…) 检查文本 |
| optimizeCountSql | boolean | true | 自动优化 COUNT SQL 如果遇到 jSqlParser 无法解析情况,设置该参数为 false |
| optimizeJoinOfCountSql | boolean | true | 自动优化 COUNT SQL 是否把 join 查询部分移除 |
| searchCount | boolean | true | 是否进行 count 查询,如果指向查询到列表不要查询总记录数,设置该参数为 false |
| maxLimit | Long | 单页分页条数限制 | |
| countId | String | xml 自定义 count 查询的 statementId |
Service 层
Mybatis Plus 同样也封装了通用的 Service 层 CRUD 操作,并且提供了更丰富的方法。接下来,我们上手看 Service 层的代码结构,如下图:

先定义 UserService 接口 ,让其继承自 IService:
public interface UserService extends IService<User> {
}
再定义实现类 UserServiceImpl,让其继承自 ServiceImpl, 同时实现 UserService 接口,这样就可以让 UserService 拥有了基础通用的 CRUD 功能,当然,实际开发中,业务会更加复杂,就需要向 IService 接口自定义方法并实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
注入 UserService :
@Autowired
private UserService userService;
Service 层封装的分页相关方法如下:
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
示例代码
Service 层的分页方法入参和 Mapper 差不多:
// 组装查询条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// where age = 30
queryWrapper.eq("age", 30);
// 查询第 2 页数据,每页 10 条
Page<User> page = new Page<>(2, 10);
page = userService.page(page, queryWrapper);
System.out.println("总记录数:" + page.getTotal());
System.out.println("总共多少页:" + page.getPages());
System.out.println("当前页码:" + page.getCurrent());
// 当前页数据
List<User> users = page.getRecords();
6.多表联查
表结构
DROP TABLE IF EXISTS user;
CREATE TABLE `t_user` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男',
PRIMARY KEY (`id`)
) COMMENT = '用户表';
INSERT INTO `t_user` (`id`, `name`, `age`, `gender`) VALUES (1, '犬小哈', 30, 1);
INSERT INTO `t_user` (`id`, `name`, `age`, `gender`) VALUES (2, '关羽', 46, 1);
INSERT INTO `t_user` (`id`, `name`, `age`, `gender`) VALUES (3, '诸葛亮', 26, 1);
CREATE TABLE `t_order` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`order_id` bigint(20) UNSIGNED NOT NULL COMMENT '订单ID',
`user_id` bigint(20) UNSIGNED NOT NULL COMMENT '下单用户ID',
`goods_name` varchar(30) NOT NULL COMMENT '商品名称',
`goods_price` decimal(10,2) NOT NULL COMMENT '商品价格',
PRIMARY KEY (`id`),
INDEX idx_order_id(`order_id`)
) COMMENT = '订单表';
INSERT INTO `t_order` (`id`, `order_id`, `user_id`, `goods_name`, `goods_price`) VALUES (1, 805646264648356, 1, 'Switch 游戏机', 1400.00);
INSERT INTO `t_order` (`id`, `order_id`, `user_id`, `goods_name`, `goods_price`) VALUES (2, 551787441310504, 1, '小米手机', 2000.00);
INSERT INTO `t_order` (`id`, `order_id`, `user_id`, `goods_name`, `goods_price`) VALUES (3, 938562101633493, 2, '《三国演义》', 66.00);
INSERT INTO `t_order` (`id`, `order_id`, `user_id`, `goods_name`, `goods_price`) VALUES (4, 791129917310894, 3, '华为手机', 1200.00);
INSERT INTO `t_order` (`id`, `order_id`, `user_id`, `goods_name`, `goods_price`) VALUES (5, 208722395587361, 3, '《西游记》', 56.00);
需求分析
假设前端需要展示数据有如下几个字段:订单号、商品名称、商品价格、下单用户姓名、下单用户年龄、下单用户性别
则对应的关联 SQL 语句如下:
select o.order_id, o.goods_name, o.goods_price, u.name, u.age, u.gender
from t_order as o left join t_user as u on o.user_id = u.id
实体类
接下来,我们定义实体类。创建一个 OrderVO 视图类,用于传输给前端展示:
@Data
public class OrderVO {
/**
* 订单ID
*/
private Long orderId;
/**
* 下单用户ID
*/
private Long userId;
/**
* 商品名称
*/
private String goodsName;
/**
* 商品价格
*/
private BigDecimal goodsPrice;
/**
* 用户名
*/
private String userName;
/**
* 年龄
*/
private Integer userAge;
/**
* 性别
*/
private Integer userGender;
}
关联查询
简单的关联查询
创建 UserMapper , 让其继承自 BaseMapper , 并自定义一个查询订单列表的方法:
public interface UserMapper extends BaseMapper<User> {
// 查询订单列表
List<OrderVO> selectOrders();
}
在项目的 resource 目录下新建 mapper 文件夹,并在 mapper 文件夹中创建 UserMapper.xml 文件:
UserMapper.xml 中编写关联语句,以及需要映射的对象,内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.quanxiaoha.mybatisplusdemo.mapper.UserMapper">
<resultMap id="orderMap" type="com.quanxiaoha.mybatisplusdemo.model.OrderVO">
<result property="userName" column="name"/>
<result property="userAge" column="age"/>
<result property="userGender" column="gender"/>
<result property="orderId" column="order_id"/>
<result property="userId" column="user_id"/>
<result property="goodsName" column="goods_name"/>
<result property="goodsPrice" column="goods_price"/>
</resultMap>
<select id="selectOrders" resultMap="orderMap">
select o.order_id, o.user_id, o.goods_name, o.goods_price, u.name, u.age, u.gender
from t_order as o left join t_user as u on o.user_id = u.id
</select>
</mapper>
定义关联查询分页方法
在 UserMapper 接口中再定义支持分页的关联查询方法:
public interface UserMapper extends BaseMapper<User> {
//...
IPage<OrderVO> selectOrderPage(IPage<OrderVO> page, @Param(Constants.WRAPPER) QueryWrapper<OrderVO> wrapper);
//...
}
然后在 UserMapper.xml 中创建该方法对应的关联查询:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.quanxiaoha.mybatisplusdemo.mapper.UserMapper">
<resultMap id="orderMap" type="com.quanxiaoha.mybatisplusdemo.model.OrderVO">
<result property="userName" column="name"/>
<result property="userAge" column="age"/>
<result property="userGender" column="gender"/>
<result property="orderId" column="order_id"/>
<result property="userId" column="user_id"/>
<result property="goodsName" column="goods_name"/>
<result property="goodsPrice" column="goods_price"/>
</resultMap>
//...
<select id="selectOrderPage" resultMap="orderMap">
select u.name, u.age, u.gender, o.order_id, o.goods_name, o.goods_price
from t_user as u left join t_order as o on u.id = o.user_id
${ew.customSqlSegment}
</select>
//...
</mapper>
再创建一个单元测试:
@Autowired
private UserMapper userMapper;
@Test
void testSelectOrdersPage() {
// 查询第一页,每页显示 10 条
Page<OrderVO> page = new Page<>(1, 10);
// 注意:一定要手动关闭 SQL 优化,不然查询总数的时候只会查询主表
page.setOptimizeCountSql(false);
// 组装查询条件 where age = 20
QueryWrapper<OrderVO> queryWrapper = new QueryWrapper<>();
queryWrapper.ge("age", 20);
IPage<OrderVO> page1 = userMapper.selectOrderPage(page, queryWrapper);
System.out.println("总记录数:" + page1.getTotal());
System.out.println("总共多少页:" + page1.getPages());
System.out.println("当前页码:" + page1.getCurrent());
System.out.println("查询数据:" + page1.getRecords());
}
7.批量 Insert_新增数据
我们向 MySQL 中新增一条记录,SQL 语句类似如下:
INSERT INTO `t_user` (`name`, `age`, `gender`) VALUES ('测试', 0, 1);
如果你需要添加 100 万条数据,就需要多次执行此语句,这就意味着频繁地 IO 操作(网络 IO、磁盘 IO),并且每一次数据库执行 SQL 都需要进行解析、优化等操作,都会导致非常耗时。
幸运的是,MySQL 支持一条 SQL 语句可以批量插入多条记录,格式如下:
INSERT INTO `t_user` (`name`, `age`, `gender`) VALUES ('测试1', 0, 1), ('测试2', 0, 1), ('测试3', 0, 1);
和常规的 INSERT 语句不同的是,VALUES 支持多条记录,通过 , 逗号隔开。这样,可以实现一次性插入多条记录。
表与实体类
先创建一个测试表 t_user, 执行脚本如下:
DROP TABLE IF EXISTS user;
CREATE TABLE `t_user` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男',
PRIMARY KEY (`id`)
) COMMENT = '用户表';
再定义一个名为 User 实体类:
@Data
@TableName("t_user")
public class User {
/**
* 主键 ID, @TableId 注解定义字段为表的主键,type 表示主键类型,IdType.AUTO 表示随着数据库 ID 自增
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
}
利用 SQL 注入器实现真的批量插入
新建批量插入 SQL 注入器
在工程 config 目录下创建一个 SQL 注入器 InsertBatchSqlInjector :
public class InsertBatchSqlInjector extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {
// super.getMethodList() 保留 Mybatis Plus 自带的方法
List<AbstractMethod> methodList = super.getMethodList(mapperClass, tableInfo);
// 添加自定义方法:批量插入,方法名为 insertBatchSomeColumn
methodList.add(new InsertBatchSomeColumn());
return methodList;
}
}
InsertBatchSomeColumn
InsertBatchSomeColumn 是 Mybatis Plus 内部提供的默认批量插入,只不过这个方法作者只在 MySQL 数据测试过,所以没有将它作为通用方法供外部调用,注意看注释:
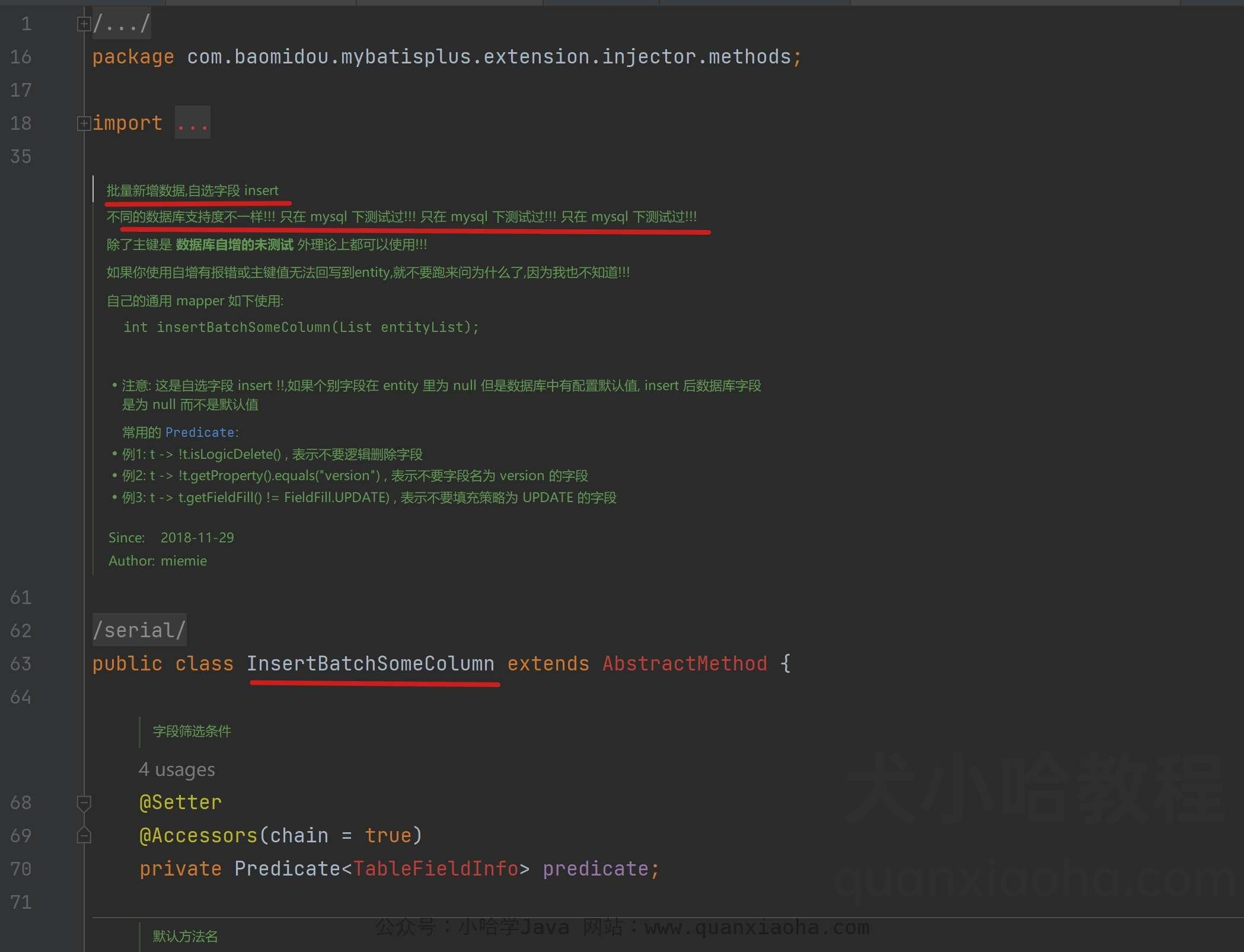
源码复制出来,如下:
/**
* 批量新增数据,自选字段 insert
* <p> 不同的数据库支持度不一样!!! 只在 mysql 下测试过!!! 只在 mysql 下测试过!!! 只在 mysql 下测试过!!! </p>
* <p> 除了主键是 <strong> 数据库自增的未测试 </strong> 外理论上都可以使用!!! </p>
* <p> 如果你使用自增有报错或主键值无法回写到entity,就不要跑来问为什么了,因为我也不知道!!! </p>
* <p>
* 自己的通用 mapper 如下使用:
* <pre>
* int insertBatchSomeColumn(List<T> entityList);
* </pre>
* </p>
*
* <li> 注意: 这是自选字段 insert !!,如果个别字段在 entity 里为 null 但是数据库中有配置默认值, insert 后数据库字段是为 null 而不是默认值 </li>
*
* <p>
* 常用的 {@link Predicate}:
* </p>
*
* <li> 例1: t -> !t.isLogicDelete() , 表示不要逻辑删除字段 </li>
* <li> 例2: t -> !t.getProperty().equals("version") , 表示不要字段名为 version 的字段 </li>
* <li> 例3: t -> t.getFieldFill() != FieldFill.UPDATE) , 表示不要填充策略为 UPDATE 的字段 </li>
*
* @author miemie
* @since 2018-11-29
*/
@SuppressWarnings("serial")
public class InsertBatchSomeColumn extends AbstractMethod {
/**
* 字段筛选条件
*/
@Setter
@Accessors(chain = true)
private Predicate<TableFieldInfo> predicate;
/**
* 默认方法名
*/
public InsertBatchSomeColumn() {
// 方法名
super("insertBatchSomeColumn");
}
/**
* 默认方法名
*
* @param predicate 字段筛选条件
*/
public InsertBatchSomeColumn(Predicate<TableFieldInfo> predicate) {
super("insertBatchSomeColumn");
this.predicate = predicate;
}
/**
* @param name 方法名
* @param predicate 字段筛选条件
* @since 3.5.0
*/
public InsertBatchSomeColumn(String name, Predicate<TableFieldInfo> predicate) {
super(name);
this.predicate = predicate;
}
@SuppressWarnings("Duplicates")
@Override
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
SqlMethod sqlMethod = SqlMethod.INSERT_ONE;
List<TableFieldInfo> fieldList = tableInfo.getFieldList();
String insertSqlColumn = tableInfo.getKeyInsertSqlColumn(true, false) +
this.filterTableFieldInfo(fieldList, predicate, TableFieldInfo::getInsertSqlColumn, EMPTY);
String columnScript = LEFT_BRACKET + insertSqlColumn.substring(0, insertSqlColumn.length() - 1) + RIGHT_BRACKET;
String insertSqlProperty = tableInfo.getKeyInsertSqlProperty(true, ENTITY_DOT, false) +
this.filterTableFieldInfo(fieldList, predicate, i -> i.getInsertSqlProperty(ENTITY_DOT), EMPTY);
insertSqlProperty = LEFT_BRACKET + insertSqlProperty.substring(0, insertSqlProperty.length() - 1) + RIGHT_BRACKET;
String valuesScript = SqlScriptUtils.convertForeach(insertSqlProperty, "list", null, ENTITY, COMMA);
String keyProperty = null;
String keyColumn = null;
// 表包含主键处理逻辑,如果不包含主键当普通字段处理
if (tableInfo.havePK()) {
if (tableInfo.getIdType() == IdType.AUTO) {
/* 自增主键 */
keyGenerator = Jdbc3KeyGenerator.INSTANCE;
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
} else {
if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(this.methodName, tableInfo, builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
}
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = languageDriver.createSqlSource(configuration, sql, modelClass);
return this.addInsertMappedStatement(mapperClass, modelClass, getMethod(sqlMethod), sqlSource, keyGenerator, keyProperty, keyColumn);
}
}
配置 SQL 注入器
在 config 包下创建 MybatisPlusConfig 配置类:
@Configuration
@MapperScan("com.quanxiaoha.mybatisplusdemo.mapper")
public class MybatisPlusConfig {
/**
* 自定义批量插入 SQL 注入器
*/
@Bean
public InsertBatchSqlInjector insertBatchSqlInjector() {
return new InsertBatchSqlInjector();
}
}
新建 MyBaseMapper
在 config 包下创建 MyBaseMapper 接口,让其继承自 Mybatis Plus 提供的 BaseMapper, 并定义批量插入方法:
public interface MyBaseMapper<T> extends BaseMapper<T> {
// 批量插入
int insertBatchSomeColumn(@Param("list") List<T> batchList);
}
新建 UserMapper
在 mapper 包下创建 UserMapper 接口,注意继承刚刚自定义的 MyBaseMapper, 而不是 BaseMapper :
public interface UserMapper extends MyBaseMapper<User> {
}
测试批量插入
完成上面这些工作后,就可以使用 Mybatis Plus 提供的批量插入功能了。我们新建一个单元测试,并注入 UserMapper :
@Autowired
private UserMapper userMapper;
单元测试如下:
@Test
void testInsertBatch() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 3; i++) {
User user = new User();
user.setName("测试" + i);
user.setAge(i);
user.setGender(1);
users.add(user);
}
userMapper.insertBatchSomeColumn(users);
}
性能对比
耗时对比
| 方式 | 总耗时 |
|---|---|
| for 循环插入 | 722963 ms, 约 12 分钟 |
| savaBatch() 伪批量插入 | 95864 ms, 约一分钟30秒左右 |
| 真实批量插入 | 6320 ms, 约 6 秒 |
8.常用注解
实体类常用注解
@TableName
作用:表名注解,标识实体类对应的表。
使用示例:
@TableName("t_user")
public class User {
/**
* 主键 ID
*/
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
}
@TableId
作用:主键注解。
使用示例:
@TableName("t_user")
public class User {
/**
* 主键 ID
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
}
@TableId 注解有两个属性值:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 主键字段名 |
| type | Enum | 否 | IdType.NONE (默认雪花算法生成 ID) | 指定主键类型 |
@IdType
作用:指定主键 ID 类型。
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(默认) |
| INPUT | 插入数据前,需自行设置主键的值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID (默认 default 方法) |
| 分布式全局唯一 ID 长整型类型 (推荐使用 ASSIGN_ID) | |
| 32 位 UUID 字符串 (推荐使用 ASSIGN_UUID) | |
| 分布式全局唯一 ID 字符串类型 (推荐使用 ASSIGN_ID) |
@TableField
作用:指定数据库字段注解(非主键)。
假设表的字段名与实体类的字段名不一致,可通过它来指定,比如表字段名为 user_name 映射到实体类的字段 name 上,代码如下:
@TableName("t_user")
public class User {
/**
* 主键 ID
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
@TableField("user_name")
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
}
@TableLogic
作用:逻辑删除注解。
@TableName("t_user")
public class User {
/**
* 主键 ID
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
/**
* 逻辑删除
*/
@TableLogic
private Integer isDeleted;
}
@Version
作用:乐观锁注解。
@TableName("t_seckill_goods")
public class SeckillGoods {
/**
* 主键 ID
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 商品名称
*/
private String goodsName;
/**
* 库存
*/
private Integer count;
/**
* 乐观锁版本号
*/
@Version
private Integer version;
}
9.Wrapper 条件构造器
Wrapper 继承关系
Wrapper 是个抽象类,先看下它的继承关系图:
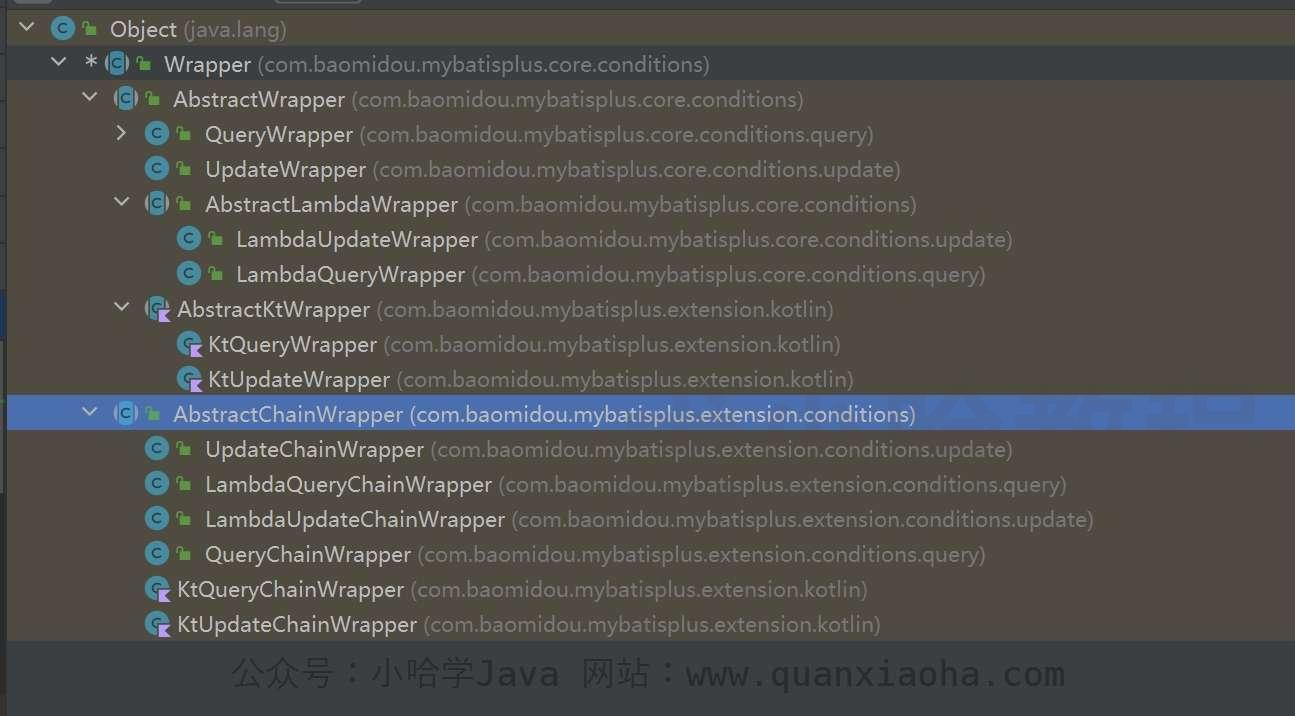
解释一下各个子类的作用:
Wrapper 条件构造抽象类
-- AbstractWrapper 查询条件封装,用于生成 sql 中的 where 语句。
-- QueryWrapper Entity 条件封装操作类,用于查询。
-- UpdateWrapper Update 条件封装操作类,用于更新。
-- AbstractLambdaWrapper 使用 Lambda 表达式封装 wrapper
-- LambdaQueryWrapper 使用 Lambda 语法封装条件,用于查询。
-- LambdaUpdateWrapper 使用 Lambda 语法封装条件,用于更新。
-- AbstractChainWrapper 链式查询条件封装
-- UpdateChainWrapper 链式条件封装操作类,用于更新。
-- LambdaQueryChainWrapper 使用 Lambda 语法封装条件,支持链式调用,用于查询
-- LambdaUpdateChainWrapper 使用 Lambda 语法封装条件,支持链式调用,用于更新
-- QueryChainWrapper 链式条件封装操作类,用于查询。
AbstractWrapper
QueryWrapper (LambdaQueryWrapper) 和 UpdateWrapper (LambdaUpdateWrapper) 的父类 用于生成 sql 的 where 条件, entity 属性也用于生成 sql 的 where 条件
allEq :多字段等于查询
全部自动等于判断,或者个别自动非空判断:
// params : key 为数据库字段名, value 为字段值
allEq(Map<R, V> params)
// null2IsNull : 为 true 则在 map 的 value 为 null 时调用 isNull 方法,为 false 时则忽略 value 为null的
allEq(Map<R, V> params, boolean null2IsNull)
allEq(boolean condition, Map<R, V> params, boolean null2IsNull)
- 代码示例1: allEq({id:1,name:“老王”,age:null}) 相当于条件 id = 1 and name = ‘老王’ and age is null;
- 代码示例2: allEq({id:1,name:“老王”,age:null}, false)相当于条件id = 1 and name = ‘老王’, ;
// filter : 过滤函数,是否允许字段传入比对条件中
allEq(BiPredicate<R, V> filter, Map<R, V> params)
// 同上
allEq(BiPredicate<R, V> filter, Map<R, V> params, boolean null2IsNull)
allEq(boolean condition, BiPredicate<R, V> filter, Map<R, V> params, boolean null2IsNull)
- 代码示例1: allEq((k,v) -> k.contains(“a”), {id:1,name:“老王”,age:null})相当于条件name = ‘老王’ and age is null;
- 代码示例2: allEq((k,v) -> k.contains(“a”), {id:1,name:“老王”,age:null}, false)相当于条件name = ‘老王’;
eq :单字段等于
eq(R column, Object val)
eq(boolean condition, R column, Object val)
- 代码示例: eq(“name”, “老王”)相当于条件name = ‘老王’;
ne :不等于
ne(R column, Object val)
ne(boolean condition, R column, Object val)
- 代码示例:ne(“name”, “老王”)相当于条件name <> ‘老王’;
gt : 大于
gt(R column, Object val)
gt(boolean condition, R column, Object val)
- 代码示例: ge(“age”, 18)相当于条件age >= 18;
ge:大于等于
ge(R column, Object val)
ge(boolean condition, R column, Object val)
- 例: ge(“age”, 18)相当于条件age >= 18;
lt:小于
lt(R column, Object val)
lt(boolean condition, R column, Object val)
- 例: lt(“age”, 18)相当于条件age < 18;
le : 小于等于
le(R column, Object val)
le(boolean condition, R column, Object val)
- 例: le(“age”, 18)相当于条件age <= 18;
between
between(R column, Object val1, Object val2)
between(boolean condition, R column, Object val1, Object val2)
作用:BETWEEN 值1 AND 值2
- 例: between(“age”, 18, 30)相当于条件age between 18 and 30;
notBetween
notBetween(R column, Object val1, Object val2)
notBetween(boolean condition, R column, Object val1, Object val2)
作用:NOT BETWEEN 值1 AND 值2
- 例: notBetween(“age”, 18, 30)相当于条件age not between 18 and 30;
like : 模糊查询
like(R column, Object val)
like(boolean condition, R column, Object val)
作用:LIKE ‘%值%’
- 例: like(“name”, “王”)相当于条件name like ‘%王%’;
notLike
notLike(R column, Object val)
notLike(boolean condition, R column, Object val)
作用:NOT LIKE ‘%值%’
- 例: notLike(“name”, “王”)相当于条件name not like ‘%王%’;
likeLeft
likeLeft(R column, Object val)
likeLeft(boolean condition, R column, Object val)
作用:LIKE ‘%值’
- 例: likeLeft(“name”, “王”)相当于条件name like '%王;
likeRight
likeRight(R column, Object val)
likeRight(boolean condition, R column, Object val)
作用: LIKE ‘值%’
- 例: likeRight(“name”, “王”)相当于条件name like '王%;
isNull :为空
isNull(R column)
isNull(boolean condition, R column)
作用:字段 IS NULL
- 例: isNull(“name”)相当于条件name is null;
isNotNull : 非空
isNotNull(R column)
isNotNull(boolean condition, R column)
作用: 字段 IS NOT NULL
- 例: isNotNull(“name”)相当于条件name is not null;
in
in(R column, Collection<?> value)
in(boolean condition, R column, Collection<?> value)
说明:字段 IN (value.get(0), value.get(1), …)
- 例: in(“age”,{1,2,3})相当于条件age in (1,2,3);
in(R column, Object... values)
in(boolean condition, R column, Object... values)
说明:字段 IN (v0, v1, …)
- 例: in(“age”, 1, 2, 3) 相当于条件age in (1,2,3);
notIn
notIn(R column, Collection<?> value)
notIn(boolean condition, R column, Collection<?> value)
作用:NOT IN (value.get(0), value.get(1), …)
- 例: notIn(“age”,{1,2,3})相当于条件age not in (1,2,3);
inSql :子查询
inSql(R column, String inValue)
inSql(boolean condition, R column, String inValue)
作用:字段 IN ( sql语句 )
- 例: inSql(“age”, “1,2,3,4,5,6”)相当于条件age in (1,2,3,4,5,6);
- 例: inSql(“id”, “select id from table where id < 3”)相当于条件id in (select id from table where id < 3);
notInSql
notInSql(R column, String inValue)
notInSql(boolean condition, R column, String inValue)
作用:NOT IN ( sql语句 )
- 例: notInSql(“age”, “1,2,3,4,5,6”)相当于条件age not in (1,2,3,4,5,6);
- 例: notInSql(“id”, “select id from table where id < 3”)相当于条件id not in (select id from table where id < 3);
groupBy:分组
groupBy(R... columns)
groupBy(boolean condition, R... columns)
说明:分组 GROUP BY 字段。
- 例: groupBy(“id”, “name”)相当于条件group by id,name;
orderByAsc:升序
orderByAsc(R... columns)
orderByAsc(boolean condition, R... columns)
说明:升序排序:ORDER BY 字段, … ASC
- 例: orderByAsc(“id”, “name”)相当于条件order by id ASC,name ASC;
orderByDesc:降序
orderByDesc(R... columns)
orderByDesc(boolean condition, R... columns)
说明:降序排序:ORDER BY 字段, … DESC
- 例: orderByDesc(“id”, “name”)相当于条件order by id DESC,name DESC;
orderBy : 排序
orderBy(boolean condition, boolean isAsc, R... columns)
说明:排序:ORDER BY 字段, …
- 例: orderBy(true, true, “id”, “name”)相当于条件order by id ASC,name ASC;
having
作用:HAVING ( sql语句 )
having(String sqlHaving, Object... params)
having(boolean condition, String sqlHaving, Object... params)
- 例: having(“sum(age) > 10”)相当于条件having sum(age) > 10
- 例: having(“sum(age) > {0}”, 11)相当于条件having sum(age) > 11
func
作用:func 方法主要方便在出现if…else下调用不同方法能不断链
func(Consumer<Children> consumer)
func(boolean condition, Consumer<Children> consumer)
- 例: func(i -> if(true) {i.eq(“id”, 1)} else {i.ne(“id”, 1)})
or
拼接 or :
or()
or(boolean condition)
- 例: eq(“id”,1).or().eq(“name”,“老王”)相当于条件id = 1 or name = ‘老王’;
or 嵌套:
- 例: or(i -> i.eq(“name”, “李白”).ne(“status”, “活着”))相当于条件or (name = ‘李白’ and status <> ‘活着’);
and 嵌套
and(Consumer<Param> consumer)
and(boolean condition, Consumer<Param> consumer)
作用:AND 嵌套
- 例: and(i -> i.eq(“name”, “李白”).ne(“status”, “活着”))相当于条件and (name = ‘李白’ and status <> ‘活着’);
nested
作用:正常嵌套 不带 AND 或者 OR
nested(Consumer<Param> consumer)
nested(boolean condition, Consumer<Param> consumer)
- 例: nested(i -> i.eq(“name”, “李白”).ne(“status”, “活着”))相当于条件(name = ‘李白’ and status <> ‘活着’)
apply
作用:拼接 sql
注意:该方法可用于数据库函数 动态入参的params对应前面applySql内部的{index}部分.这样是不会有sql注入风险的,反之会有!
apply(String applySql, Object... params)
apply(boolean condition, String applySql, Object... params)
- 例: apply(“id = 1”)相当于条件id = 1
- 例: apply(“date_format(dateColumn,‘%Y-%m-%d’) = ‘2008-08-08’”)相当于条件date_format(dateColumn,‘%Y-%m-%d’) = ‘2008-08-08’")
- 例: apply(“date_format(dateColumn,‘%Y-%m-%d’) = {0}”, “2008-08-08”)相当于条件date_format(dateColumn,‘%Y-%m-%d’) = ‘2008-08-08’")
last
作用:无视优化规则直接拼接到 sql 的最后。
注意:只能调用一次,多次调用以最后一次为准 有sql注入的风险,请谨慎使用。
last(String lastSql)
last(boolean condition, String lastSql)
- 例: last(“limit 1”)。
exists
exists(String existsSql)
exists(boolean condition, String existsSql)
作用:拼接 EXISTS ( sql语句 )
- 例: exists(“select id from table where age = 1”)相当于条件exists (select id from table where age = 1);
notExists
notExists(String notExistsSql)
notExists(boolean condition, String notExistsSql)
作用:拼接 NOT EXISTS ( sql语句 )
- 例: notExists(“select id from table where age = 1”)相当于条件not exists (select id from table where age = 1);
QueryWrapper
QueryWrapper 继承自 AbstractWrapper ,自身的内部属性 entity 也用于生成 where 条件。LambdaQueryWrapper 支持以 lambda 形式组装条件, 可以通过 new QueryWrapper().lambda() 方法获取实例。
select
作用:设置查询字段
select(String... sqlSelect)
select(Predicate<TableFieldInfo> predicate)
select(Class<T> entityClass, Predicate<TableFieldInfo> predicate)
TIP :
以上方法分为两类. 第二类方法为:过滤查询字段(主键除外),入参不包含 class 的
调用前需要wrapper内的entity属性有值! 这两类方法重复调用以最后一次为准
- 例: select(“id”, “name”, “age”)
- 例: select(i -> i.getProperty().startsWith(“test”))
UpdateWrapper
UpdateWrapper 继承自 AbstractWrapper ,自身的内部属性 entity 也用于生成 where 条件。LambdaUpdateWrapper 支持以 lambda 形式组装条件, 可以通过 new QueryWrapper().lambda() 方法获取实例。
set
作用:SET 字段
set(String column, Object val)
set(boolean condition, String column, Object val)
- 例: set(“name”, “老李头”)
- 例: set(“name”, “”)—>数据库字段值变为空字符串
- 例: set(“name”, null)—>数据库字段值变为null
setSql
作用:设置 SET 部分 SQL
setSql(String sql)
例: setSql(“name = ‘老李头’”)
lambda
作用:用于获取 LambdaWrapper。
在QueryWrapper中是获取LambdaQueryWrapper;
在UpdateWrapper中是获取LambdaUpdateWrapper.















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









