






类String
类String特点:
- java中所有带有双引号字符串,都是String这个类的对象
- 字符串被创建后不可更改,若想更改,需使用新的对象做替换。虽然字符串内容不可改变,但是字符串内容可以被共享
字符串常量池:
当使用双引号创建字符串对象时,会检查常量池中是否存在该数据。
存在时,复用;不存在时,创建
String类常见构造方法
- public String():创建一个空白字符串,里面不含任何内容
String s1 = new String(); System.out.printlin(s1); - public String(char[] chs):根据传入的字符数组,创建字符串对象
-
char[] chs = {'a','b','c'}; String s2 = new String(chs); System.out.printlin(s2); - public String(String original):根据传入的字符串对象,来创建字符串对象
String s3 = new String("abc");
System.out.printlin(s3);字符串对象,两种创建方式的区别:
- 双引号直接创建:避免重复创建相同内容的对象,节省内存空间
- 通过构造方法创建:无论常量池中是否存在,都在堆内存中创建新对象
为什么打印字符串的对象名,输出的不是地址值?
答:因为String类重写了Object类中toString()方法,使其调用对象名时,返回的是字符串内容,而不是内存地址
public class String{
@Override
public String toString(){
return this;
}
}下面用四个String类的代码,帮助理解String类两种创建方式的区别
public class StringTest1{
public static void main(String[] args){
String s1 = "abc";
String s2 = "abc";
System.out.printlin(s1==s2);//返回值为true
}
}public class StringTest 2{
public static void main(String[] args){
String s1 = "abc";
String s2 = new String("abc");
System.out.printlin(s1==s2);//返回值为false
}
}public class StringTest3{
public static void main(String[] args){
String s1 = "abc";
String s2 = "ab";
String s3 = s2 + "c";
Sysytem.out.printlin(s1==s3);//返回值为false
}
}public class StringTest4{
pubilc static void main(String[] args){
String s1 = "abc";
String s2 = "a" + "b" + "c";
System.out.printlin(s1==s2);//返回值为true
}
}String类中用于比较的方法
代码原型
public boolean equals(Object anObject)//考虑大小写
public boolean equalsIgnoreCase(String anotherString)//不考虑大小写示例代码
public static void main(String[] args){
String s1 = "abc";
String s2 = new String("abc");
System.out.printlin(s1==s2); //false
System.out.printlin(s1.equals(s2)); //true
String ss1 = "abc";
String ss2 = "ABC";
System.out.printlin(ss1.equals(ss2)); //false
System.out.printlin(ss2.equalsIgnoreCase(ss2)); //true
}
}String类用于遍历的方法
代码原型
public char[] toCharArray()//将字符串转换为一个新的字符数组
public char charAt(int index)//返回指定索引处的char值示例代码
public static void main(String[] args){
String s = "it";
char[] chars = s.toCharArray();
for(int i = 0; i < chars.length; i++){
System.out.printlin(chars[i]);
}
for(int j = 0; j < s.length(); j++){
char c = s,charAt(j);
System.out.printlin(c);
}
}String类的截取方法
代码原型
public String substring(int beginIndex)//根据传入索引开始截取,截取到字符串末尾
public String substring(int beginIndex,int endIndex)//包头不包尾注意:截取出来的内容,作为新字符串返回,需要变量进行接收
获取时间
public static void main(String[] args){
long time = System.currentTimeMillis();
System.out.printlin(time);
long start = System.currentTimeMillis();
......
long end = System.currentTimeMillis();
System.out.printlin(end-start);
}StringBuilder与StringBuffer
作用:提高字符串的操作效率
区别:后者更安全(多用),但是前者效率更高
介绍:
- 可变字符序列
- StringBuilder是字符串缓冲区,理解为容器,可存储任意数据类型,但是只要进入此容器,全变成字符串
StringBuilder构造方法
public StringBuilder()//创建一个空白的字符串缓冲区(容器),初始容量为16个字符
public StringBuilder(String str)//创建容器后,容器内会带有参数的内容StringBuilder常用成员方法
| 方法名 | 说明 |
|---|---|
| public StringBuilder append(任意类型) | 添加数据,并返回对象本身 |
| public StringBuilder reverse() | 反转容器内内容 |
| public int length() | 返回长度(字符个数) |
| public String toString() | 将缓冲区内容StringBuilder转为String |
链式编程:调用的方法,返回结果是对象,就可以继续向下调用方法
如:sb.append().append
包
定义:本质来说是文件夹,用于管理类文件
建包的语法格式:package公司域名倒写.技术名称。
package com.itheima.domain;
public class Student{
}建包语句必须在第一行,一般IDEA工具会帮助创建
导包
导包格式:import包名.类名;
相同包下的类可以直接访问,不同包下的类要导包才可以使用。
若一个类中需要不同类,而这两个类的名称是一样的,那么默认只能导入一个类,另一个类要带包名访问。
示例代码如下:
com.itheima.b.Student stu2 = new com.itheima.b.Student();
//使用全类名创建对象:包名+类名抽象类
抽象类:特殊的父类,内部允许编写抽象方法
抽象类的定义格式:public abstract class 类名{ }
抽象方法:子类中共性方法的视线逻辑在父类中不具体明确,但子类中必须有并且重写
抽象方法的定义格式:public abstract 返回值类型 方法名(参数列表);
public abstract class Fu{
public abstract void 行善();
}
public class Zi1 extends Fu{
@Override
public void 行善(){
System.out.printlin("送衣做饭");
}
public class Zi2 extends Fu{
@Override
public void 行善(){
System.out.printlin("送书");
}API
API:应用程序编程接口
Object类
所有的类都直接或者间接的继承了Object类(祖宗类)
tostring类
存在意义:父类toString()方法存在的意义就是为了被子类重写,以便返回对象的内容信息,而非地址信息
| 方法名 | 说明 |
|---|---|
| public String tostring() | 默认返回当前对象在堆内存中的地址信息:类的全类名@十六进制哈希值 |
//public String tostring() 返回该对象的字符串表示
public String tostring{
return getClass().getName()+"@"+Integer.toHexString(hashCode());
}| getClass().getName() | 类名称,全类名(包名+类名) |
| Integer.toHexString() | 转十六进制 |
| hashCode() | 返回的是对象内存地址+哈希算法,算出来的整数(哈希值) |
注意:使用打印语句,打印对象名时,printlin方法,源码层面,会自动调用该对象的tostring方法
public static String valueOf(Object obj){
return (obj==null)?"null":obj.tostring()
}equals方法
| 方法名 | 说明 |
|---|---|
| public boolean equals(Object obj) | 默认比较当前对象与另一个对象地址是否相同,相同返回true,不同返回false |
equals存在意义:父类equals方法存在的意义就是为了被子类重写,以便子类自己定制比较规则
Objects.equals方法的好处:内部带有非null判断
public boolean equals(Object obj){
return (this==obj);
}
//结论:Object类中的equals方法,默认比较对象内存地址。
// 通常会重写equals方法,让对象之间比较内容。原理代码:
@Override
public boolean equals(Object o){
if(this == o){
//两个对象做地址值比较,若地址相同,内容肯定相同,直接返回true
return true;
}
//代码要是走到这里,代表地址肯定不相同
//代码要是走到这里,代表stu1肯定不是null
//stu1不是null,stu2是null,直接返回false
//this.getClass() != o.getClass():两个对象的字节码是否相同
//如果字节码不同,意味着类型不同,直接返回false
if(o == null || this.getClass() != o.getClass()){
return false;
}
//代码要是走到这里,代表字节码相同,类型肯定相同
//向下转型
Student student = (Student) o;
//比较
return this.age == student.age && Objects.equals(this.name, student.name);
}思考:如果stu1 == null,stu2 == null,则a == b,返回true
示例代码:
public class Student{
private String name;
private int age;
@Override
public booolean equals(Object obj){
if(obj instanceof Student){
//向下转型的目的,是为了调用子类的特有成员
Student stu = (Student) obj;
return this.age == stu.age && this.name == stu.name);
}
else{
return false;
}
}
public Student(){
}
public Student(String name, int age){
this.name = name;
this.age = age;
}
}
public static void main(String[] args){
Student stu1 = new Student("张三","23");
Student stu2 = new Student("张三","23");
System.out.printlin(stu1.equals(stu2)); //true
}public static void main(String[] args){
Student stu1 = new Student("张三","23");
Student stu2 = new Student("李四","24");
Arraylist<String> list = new Arraylist<>();
stu1.equals(list);
System.out.printlin(stu1.equals(stu2)); //false
}| 方法名 | 说明 |
|---|---|
| public static boolean equals(Object a, Object b) | 比较两个对象,地层会先进行飞快判断,从而避免空指针异常,再进行equals比较 |
| public static boolean isNull(Object obj) | 判断变量是否为null |
static关键字
作用:修饰符,可以修饰成员变量,成员方法
特点:
- 被类的所以对象共享
- 多了一种调用方式,可以通过类名进行调用(推荐使用类名调用)
- 随着类的加载而加载,优先于对象存在
static成员变量:共享数据
static成员方法:常用于制作工具类
工具类:不是描述事物的,而是帮我们完成一些事情的(如打工)
如果一个类中的所以方法都是static修饰:
- 私有该类的构造方法
- 目的:为了不让其他类,在创建对象
注意:static方法中,只能访问静态成员(直接访问);static中不允许使用this关键字
pubilc class staticDemo{
static int num1 = 10;
int num2 = 20;
public static void method(){
System.out.printlin("static……method");
}
public void print(){
System.out.printlin("print……");
}
public static void main(String[] args){
//在静态方法中,只能访问静态成员(直接访问)
System.out.printlin(num1);l
method();
StaticDemo sd = new StaticDemo();
System.out.printlin(sd.num2);
sd.print();
}
}重新认识main方法
| public | 被JVM调用,访问权限足够大 |
| static | 被JVM调用,不用创建对象,因为main方法是静态的,所以测试类中其他方法也需要是静态的 |
| void | 被JVM调用,不需要给JVM返回值 |
| main | 一个通用名称,虽然不是关键字,但被JVM识别 |
| String[] args | 以前用于接收键盘录入数据的,现在没用,但保留了书写的格式 |
Math类
定义:包含执行基本数字运算的方法
| public static int abs(int a) | 获取参数绝对值 |
| public static double ceil(double a) | 向上取整 |
| public static double floor(double a) | 向下取整 |
| public static int round(float a) | 四舍五入 |
| public static int max(int a, int b) | 获取两个int值中的较大值 |
| public static double pow(double a, double b) | 返回a的b次幂的值 |
| public static double random() | 返回值为double的随机值,范围[0.0, 1.0) |
System类
System类功能是静态的,直接用类名调用即可
System类常用方法
| 方法名 | 说明 |
|---|---|
| public static void exit(int status) | 终止当前运行的java虚拟机,非零表示异常终止 |
| public static long currentTimeMillis() | 返回当前系统的时间毫秒值形式 |
| public static void arraycopy(数据源数组Object src,起始索引int srcPos,目的地数组Object dest,起始索引int destPos,拷贝个数int length) | 数组拷贝 |
BigDecimal类
作用:用于解决小数运算中,出现的不精确问题
public class BigDecimalDemo{
public static void main(String[] args){
double num1 = 0.1;
double num2 = 0.2;
System.out.printlin(num1+num2); //运算结果不精确
}
}BigDecimal创建对象:
- public BigDecimal(double val):不推荐,无法保证小数运算的精确
- public BigDecimal(String val)
- public static BigDecimal valueOf(double val)
public static void main(String[] args){
BigDecimal bd1 = new BigDecimal(0.1);
BigDecimal bd2 = new BigDecimal(0.2);
System.out.printlin(bd1.add(bd2)); //0.300...166533453
}
}public static void main(String[] args){
BigDecimal bd1 = new BigDecimal("0.1");
BigDecimal bd2 = new BigDecimal("0.2");
System.out.printlin(bd1.add(bd2)); //0.3
}
}public static void main(String[] args){
BigDecimal bd1 = new BigDecimal.valueOf(0.1);
BigDecimal bd2 = new BigDecimal.valueOf(0.2);
System.out.printlin(bd1.add(bd2)); //0.3
}
}BigDecimal常用成员方法
- public BigDecimal add(Bigdecimal b):加法
- public BigDecimal subtract(BigDecimal b):减法
- public BigDecimal mutiply(BigDecimal b):乘法
- public BigDecimal divide(BigDecinmal b):除法
- public Bigdecimal divide(另一个Bigdecimal对象,精确几位,舍入模式):除法
注意:如果使用BigDecimal运算,出现了除不尽的情况,就会出现异常
divide除法细节
BigDecimal divide = bd1.divide(参与运算的对象,小数点后精确到多少位,舍入模式);
- 参数1,表示参与运算的BidDecimal对象
- 参数2,表示小数点后精确到多少位
- 参数3,舍入模式
| RoundingMode.UP | 进一法 |
| RoundingMode.DOWN | 去尾法 |
| RoundingMOde.HALF_UP | 四舍五入 |
public static void main(String[] args){
BigDecimal bd1 = BigDecimal.valueOf(10.0);
BigDecimal bd2 = BigDecimal.valueOf(3.0);
System.out.printlin(bd1.divide(bd2,2,RoundingMode.HALF_UP)); //3.33
System.out.printlin(bd1.divide(bd2,2,RoundingMode.UP)); //3.34
System.out.printlin(bd1.divide(bd2,2,RoundingMode.DOWN)); //3.33
BigDecimal result = bd1.divide(bd2,2,RoundingMode.HALF_UP));
double v = result.doubleValue();
Math.abs(v);
}
包装类
作用:将基本数据类型,包装乘类(变成引用数据类型)
好处:变成类就可以创建对象,对象就可以调用方法,从而方便的解决问题
public class IntergerDemo{
public static void main(String[] args){
String s = "123";
System.out.printlin(s + 100); //223
//转换为十六进制,八进制,二进制……
int num = 666;
}
}| 基本数据类型 | 引用数据类型 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| float | Float |
| double | Double |
| boolean | Boolean |
Integer类
作用:将基本数据类型,手动包装为类
手动装箱:调用方法,手动将基本数据类型,包装成类
| public Integer(int value) | 通过构造方法 |
| public static Integer valueOf(int i) | 通过静态方法 |
手动拆箱:调用方法,手动将包装类,拆成(转换)基本数据类型
| public int intValue() | 以int类型返回该Integer的值 |
public static void main(String[] args){
int num = 10;
Integer i1 = Integer.valueOf(num);
int i = i1.intValue();
System.out.printlin(i);
}注意:JDK5版本开始,出现了自动拆装箱:
- 自动装箱:将基本数据类型直接赋值给包装类的变量
- 自动拆箱:将包装类的数据直接赋值给基本数据类型变量
注意:自动装箱的时候,如果装箱的数据范围,是-128~127,==号比较的true,反之就是false
Integer类中,底层存在一个长度为256个大小的数组,Integer[] cache
在数组中,存储了256个Integer对象,分别是-128~127
public static Integer valueOf(int i){
if(i >= -128 && i <= 127){
return IntegerCache,cache[i + (-IntegerCache.low)]
}
return new Integer(i);
}
//自动装箱原理:自动帮我们调用了Integer.valueOf(i);
//如果装箱的数据,不在-128~127之间,会重新创建新的对象
//如果装箱的数据,在-128~127之间,不创建新的对象
//而是从底层数组中取出一个提前创建好的Integer对象,返回public static void main(String[] args){
Integer i1 = 127;
Integer i2 = 127;
System.out.printlin(i1 == i2); //true
//在-128~127范围中,不创建新对象,从底层数组中直接获取
Integer i3 = 129;
Integer i4 = 129;
System.out.printlin(i3 == i4); //false
//不在-128~127范围中,new出新的Integer对象
}结论:基本数据类型,和对应的包装类,可以直接做运算,不需要担心转换问题
public static void main(String[] args){
int num = 10;
Integer i1 = num;
int i = i1;
System.out.printlin(i);
}Integer常用方法
| 方法名 | 说明 |
|---|---|
| public static String toBinaryString(int i) | 转二进制 |
| public static String toOctalString(int i) | 转八进制 |
| public static String toHexString(int i) | 转十六进制 |
| public static int parseInt(String s) | 将字符串类型的整数转换为int类型的整数 |
public static void main(String[] args){
String s = "123";
System.out.printlin(Integer.parseInt(s) + 100); //223
}递归
定义:方法直接或者间接调用本身
思路:将大问题,层层转化为一个个小问题解决
使用场景:常用与一些逻辑类似的业务
异常
介绍:指程序在编译或执行过程中,出现的非正常的情况(错误)
注意:语法错误不是异常
阅读异常信息时:从下往上看
- 找异常错误位置
- 异常名称
- 异常原因
异常体系
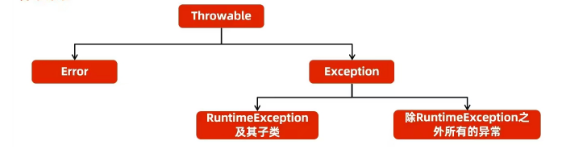
Error:严重级别问题,通常跟系统有关
- 常见的:栈内存 溢出(StackOverflowError)、堆内存溢出(OutofMemoryError)
Exception:异常类,程序常见的错误
- RuntimeException及其子类:运行时异常(已编译,运行期间可能会出现的错误)
- 除RuntimeException之外所有的异常:编译时异常(编译阶段出现的,主要起到提醒作用,需要在运行前,给出解决方案)
| 运行时异常 | |
|---|---|
| 数组索引越界异常 | ArrayIndexOutOfBoundsException |
| 空指针异常 | NullPointerException |
| 数学操作异常 | ArithmeticException |
| 类型转换异常 | ClassCastException |
| 数字转换异常 | NumberFormatException |
Java对于异常的默认处理方式:向上抛出
异常的默认处理流程
- 虚拟机在出现异常的代码那里自动创建一个异常对象
- 异常会从方法中出现的点抛出给调用者,调用者最终抛出给JVM虚拟机
- 虚拟机接收到异常对象后,先在控制台直接输出异常信息数据
- 终止java程序运行
- 后续代码不再执行,程序已经嘎了
异常的处理方式
- try...catch捕获异常
- 好处:异常对象可以被捕获,后续代码可继续执行
- 注意:如果使用多个catch,最大的异常需要放在最后
- 格式:
try{ //可能会出现异常的代码 }catch (异常类型1 变量){ //异常的处理方案 }catch (异常类型2 变量){ //异常的处理方案 }执行流程:①执行try{}中的代码,看是否有异常对象产生;②没有:catch就不会捕获,后续代码继续执行;③有:catch捕获异常对象,执行catch{}中的处理方案,后续代码继续执行
-
throws抛出异常
-
出现问题,程序会在错误点停止,不会继续执行
-
格式:
public void method() throws 异常1,异常2,异常3……{ }
两种异常处理方式的示例代码:
int age = 0;
while(true){
try{
age = Integer.parseInt(sc.nextLine());
stu.setAge(age);
break;
}catch(NumberFormatException e){
System.out.printlin("年龄输入有误,请重新输入整数年龄:");
}catch(Exception e){ //Exception e = new Exception("年龄范围有误,需要0~120之间的年龄");
String message = e.getMassage();
System.out.printlin(message);
}public void setAge(int age) throws Exception{
//throws:用在方法名后面,起到声明作用
if(age >= 0 && age <= 120){
this.age = age;
}else{
//错误的年龄
throw new Exception("年龄范围有误,需要0~120之间的年龄");
//throw:用在方法中,后面跟异常对象
}
}两种异常处理方式如何选?
答:看问题是否需要暴露出来:
- 需要:抛出
- 不需要:try……catch
细节:抛出的异常对象如果是编译时异常,必须使用throws声明;如果是运行时异常,则不需要写throws
自定义异常
- 自定义编译时异常:创建一个类,继承Exception
- 自定义运行时异常:创建一个类,继承RunTimeException
异常的细节
- Throwable的常用方法
方法名 说明 public String getMessage() 获取异常的错误原因 public void printStackTrace() 展示完整的异常错误信息 - 子类重写父类方法时,不能抛出父类没有的异常,或者比父类更大的异常
Array类
定义:数组操作工具类,专门用于操作数组元素
| 方法名 | 说明 |
|---|---|
| public static String toString(类型[] a) | 将数组元素拼接为带有格式的字符串 |
| public static boolean equals(类型[] a, 类型[] b) | 比较两个数组内容是否相同 |
| public static int binarySearch(int[] a,int key) | 查找元素在数组中的所以(二分查找法) |
| public static void sort(类型[] a) | 对数组进行默认升序排序 |
集合
集合:一个长度可变的容器
| Collection接口 | ||
|---|---|---|
| Arraylist | List接口:存取有序、有索引、可以存储重复的 | 单列集合:一次添加一个元素 |
| Linkedlist | ||
| TreeSet | Set接口:存取无序、没有索引、不可以存储重复的 | |
| HashSet | ||
| LinkedHashSet | ||
| Map接口 | |
|---|---|
| TreeMap | 双列集合:一次添加两个元素 |
| HashMap | |
| LinkedHashMap | |
集合的通用遍历方式
ArrayList<String> list = new ArrayList();
for(int i = 0; i < list.size(); i++){
String s = list.get(i);
}| 集合的通用遍历方式 |
|---|
| 迭代器 |
| 增强for循环 |
| foreach方法 |
迭代器遍历
| public Iterator<E> iterator() | 获取遍历集合的迭代器 |
| public E next() | 从集合中获取一个元素,并将指针向后移动 |
| public boolean hasNext() | 如果仍有元素可以迭代,则返回true |
注意:在循环过程中next方法最好只调用一次,如果next()方法调用次数过多,会出现NoSuchElementException
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
System.out.printlin(s);
}- 迭代器源码解析
private class Itr implements Iterator<E>{ int cursor; public boolean hasNext(){ return cursor != size; } public E next(){ int i = cursor; cursor = i + 1; return (E) elementData[lastRet = i]; } }
增强for循环
-
简化迭代器的代码书写
-
JDK5之后出现的,其内部原理就是一个iterator迭代器
//格式: for(元素的数据类型 变量名 : 数组或者集合){ } //例子 for(String s : list){ System.out.printlin(s); }foreach方法遍历集合
c.foreach(stu -> System.out.printlin(stu));Collection接口的使用
方法名称 说明 public boolean add(E e) 把给定的对象添加到当前集合中 public void clear() 清空集合中所有的元素 public boolean remove(E e) 把给定的对象在当前集合中删除 public boolean contains(Object obj) 判断当前集合中是否包含给定的对象 public boolean isEmpty() 判断当前集合是否为空 public int size() 返回集合中元素的个数/集合的长度
list接口
- 特点:存取有序,有索引,可以存储重复的
- 和索引有关的API:
| public void add(int index, E element) | 在指定位置,添加元素 |
| public E remove(int index) | 根据索引删除集合中的元素,返回值为被删除的原元素 |
| public E set(int index, E element) | 根据索引修改集合中的元素,返回值为被修改的原元素 |
| public E get(int index) | 返回指定索引处的元素 |
- 注意:remove(Object o)来源于Collection接口;remove(int index)来源于list接口
list<Integer> list2 = new Arraylist<>();
//自动装箱 原型add(Integer e) 调用时Integer e = 111;
list2.add(111);
list2.add(222);
list2.add(333);
//存储元素为整数,且需要根据元素内容删除时,需要手动装箱
list2.remove(Integer.valueOf(222));
System.out.printlin(list2);- list集合的遍历方式
- 迭代器遍历
- 增强for循环
- foreach方法
- 普通for循环
- ListIterator(List集合特有的迭代器)
ListIterator<String> it = list.ListIterator();
while(it.hasNext()){
String.s = it.next();
System.out.printlin(s);
}
while(it.hasPrevious()){
String s = it.previous();
System.out.printlin(s);
}
//用逆序遍历列表前,一定要先用正序遍历,将指针移到最后- 并发修改异常:ConcurrentModificationException
- 场景:使用迭代器遍历集合过程中,调用了集合对象的添加、删除方法,就会出现此异常
- 解决方案:迭代器遍历过程中,不用集合对象的添加或删除,用迭代器自己的添加或删除方法
- 迭代过程中做删除:使用Iterator自带的remove方法
- 迭代过程中做添加:使用ListIterator自带的add方法
- 小细节:用List集合方法删除倒数第二个元素时,不会报错
Iterator<String> it = list.iterator(); while(it hasNext()){ String s = it.next(); if("def".equals(s)){ list.remove("def"); } } //异常是在next()中的checkForComodification方法抛出的,当删除倒数第二个元素时,长度size = cursor,不再进入循环,就不会引发next()抛出异常 //原理部分代码 private class Itr implements Iterator<E>{ int cursor; public boolean hasNext(){ return cursor != size; } public E next(){ checkForComodification(); int i = cursor; cursor = i + 1; return (E) elementData[i]; } }ArrayList类
- ArrayList类底层是基于数组实现的,根据查询元素快,增删相对慢
- ArrayList底层是属猪结构的,数组默认长度为10
- 当数组添加满后,会自动扩容为1.5倍
- ArrayList长度可变原理
- 当创建ArrayList集合容器的时候,底层会存在一个长度为10个大小的数组(当未添加元素时,数组长度为0)
- 扩容原数组1.5倍大小的数组
- 将源数组数据,拷贝到新数组中
- 将新元素添加到新数组
public class A{
public static void main(STtring[] args){
ArrayList<String> list = new ArrayList<>();
list.add("abc");
}
}
//仅创建集合容器,未进行添加操作,底层数组默认长度为0
public ArrayList(){
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
traansient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};Arraylist类 数组初始长度 底层代码

Arraylist类 数组扩容长度 底层代码

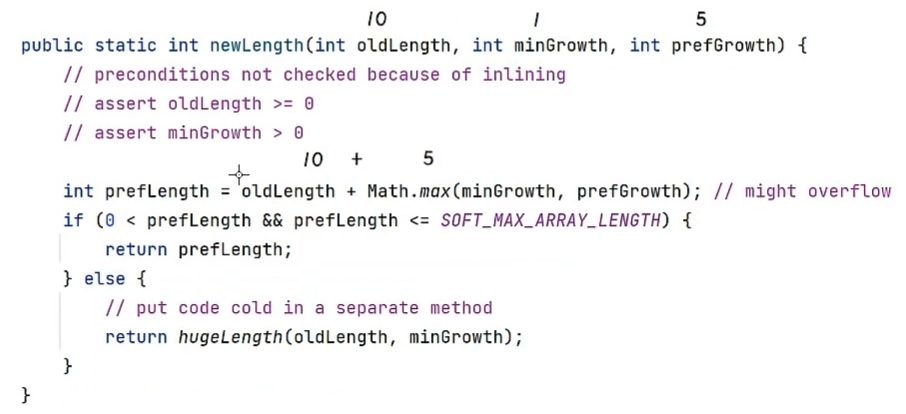
图中SOFT_MAX_ARRAY_LENGTH = Integer.MAX_VALUE - 8 = 2147483639
ArrayList源码解析
- 使用空参构造器创建的集合,在底层创建一个默认长度为0的数组
- 添加第一个元素时,底层会创建一个新的长度为10的数组
- 存满时,数组会扩容1.5倍
LinkedList类
- LinkedList类底层基于双链表实现的,查询元素慢,增删首尾元素非常快
| 特有方法 | 说明 |
|---|---|
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addList(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |
- LinkedList集合,底层是双向链表结果,查找元素会从头部或尾部逐个查找
- 但是它属于List体系中的集合,可以使用get方法,根据索引直接获取元素(底层逻辑还是遍历)
Node<E> node(int index){ if(index < (size >> 1){ Node<E> x = first; for(int i = 0; i < index; i++) x = x.next; return x; else{ Node<E> x = last; for(int i = size - 1; i > index; i--) x = x.prev; return x; } }TreeSet集合
- 作用:对集合中的元素进行排序操作(底层红黑树实现)
- 特点:排序、去重
- 注意:当我们调用add方法,向TreeSet添加元素的时候,内部会自动调用compareTo方法(当),根据这个方法的返回值,来决定节点怎么走
- 取出的顺序:左,中,右
| compareTo返回值 | 节点怎么走 |
|---|---|
| 0 | 集合中只存入根节点(一样的不存) |
| 正数 | 正序排列(大的右边走) |
| 负数 | 倒序排列(小的左边走) |
| TreeSet两种排序方式 |
|---|
| 自然排序 |
| 比较器排序 |
自然排序
- 类实现Comparable接口
- 重写compareTo方法
- 根据方法返回值,来组织排序规则
public class Student implements Comparable<Student>{
//this.xxx - o.xxx 正序
//o.xxx - this.xxx 降序
@Override
public int compareTo(Student o){
//根据年龄做主要排序条件
int ageResult = o.age - this.age;
//根据姓名做次要排序条件
int nameResult = ageResult == 0 ? o.name.compareTo(this.name) : ageResult;
//判断姓名是否相同
int result = nameResult == 0 ? 1 : nameResult;
return result;
}
}
TreeSet<Student> ts = new TreeSet<>();
ts.add(new Student("王五", 25));
ts.add(new Student("张三", 23));
ts.add(new Student("李四", 24));
ts.add(new Student("赵六", 26));比较器排序
- 在TreeSet的构造方法中,传入Comparator接口的实现类对象
- 重写compare方法
- 根据方法的返回值,来组织排序规则
public static void main(Stirng[] args){
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>(){
@Override
public int compare(Student o1, Student o2){
int ageResult = o1.getAge() - o2.getAge();
return ageResult == 0 ? o1.getName().compareTo(o2.getName()) : ageResult;
}
});
ts.add(new Student("王五", 25));
ts.add(new Student("张三", 23));
ts.add(new Student("李四", 24));
ts.add(new Student("赵六", 26));
System.out.printlin(ts);
}public static void main(String[] args){
TreeSet<String> ts = new TreeSet<>(new Comparator<String>(){
@Override
public int compare(String o1, String o2){
return o2.length() - o2.length();
}
});
ts.add("aa");
ts.add("aaaaa");
ts.add("aaa");
ts.add("a");
System.out.printlin(ts);
}public static void main(String[] args){
//因为comparator接口是函数式接口,所以可以使用Lambda表达式进行实现
TreeSet<String> ts = new TreeSet<>((o1,o2) -> o2.length() - o1.length());
ts.add("aa");
ts.add("aaaaa");
ts.add("aaa");
ts.add("a");
System.out.printlin(ts);
}- 重点:如果同具备自然排序,和比较器排序,会优先按照比较器进行排序操作

HashSet集合类
- 介绍:底层采取哈希表存储数据
- 哈希表是一种对于增删改查数据性能都较好的结果
- 特征:去重
- 遍历:迭代器,增强for,foreach方法
- 优点:保证元素唯一性
- 哈希表JDK8版本之前:数组+链表
①创建一个默认长度16的数组,数组名table ②根据元素的哈希值跟数组的长度求余计算出应存入的位置 ③判断当前位置是否为null,如果是null直接存入 ④如果位置不为null,表示有元素,则调用equals方法比较 ⑤如果一样,则不存,如果不一样,则存入数组:
#JDK7新元素占老元素位置,指向老元素(头插法)
#JDK8中新元素挂在老元素下面(尾插法)
- 哈希表JDK8版本(含)之后:数组+链表+红黑树




hashCode方法介绍
-
哈希值:是JDK根据某种规则算出来的int类型的整数
-
Object类的API
@IntrinsicCandidate
public native int hashCode();public int hashCode():调用底层C++代码计算出的一个随机数(被人称为地址值)
hashCode方法和equals方法的配合流程
- 当添加对象的时候,会先调用对象的hashCode方法计算出一个应该存入的索引位置,查看该位置上是否存在元素
- 不存在:直接存
- 存在:调用equals方法比较内容,false:存,true:不存
publci class Student{
private String name;
private int age;
@Override
public boolean equals(Object o){
if (this == o) return true;
if(o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
//如果hashCode方法固定返回相同的值,数据都会挂在一个索引下面
@Override
public int hashCode(){
return 1;
//改进为:return Objects.hash(name,age);
}
//HashSet集合存储自定义对象,需要同时重写hashcode方法和equals方法
public class HashSetDemo{
public static void main(String[] args){
HashSet<Student> hs = new HashSet<>();
hs.add(new Student("张三", 23));
hs.add(new Student("李四", 24));
hs.add(new Student("王五", 25));
hs.add(new Student("王五", 25));
System.out.printlin(hs);
}
}- 问题:该如何重写hashCode方法?
- 回答:应该将该类的所以属性,参与到哈希值的计算当中,这样(哈希值冲突)的概率才会比较小
public static void main(String[] args){
//String类重写过hashCode方法,是根据字符串的每一个字符进行计算
System.out.printlin("通话".hashCode());
System.out.printlin("重地".hashCode());
}LinkedHashSet集合
-
特点:有序、不重复、无索引
-
原理:底层数据机构是哈希表,每个元素又额外多了一个双链表的机制记录存储的顺序
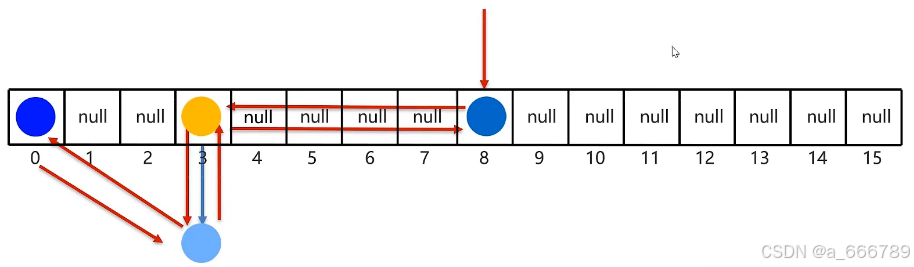
总结

Map的常见API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以集成使用的
| 方法名称 | 说明 |
|---|---|
| V put(K key, V value) | 添加元素,返回的是键原来所对应的值的值 |
| V remove(Object key) | 根据键删除键值对元素,返回的是删除键所对应值的值 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean comtainsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
public static void main(String[] args){
Map<String, String> map = new HashMap<>();
map.put("张三","北京");
map.put("李四","北京");
String s3 = map.put("王五","北京");
String s4 = map.put("王五","上海");
System.out.printlin(s3); //null
System.out.printlin(s4); //北京
String value = map.remove("王五");
System.out.printlin(value); //北京
map.clear();
System.out.printlin(map.isEmpty()); //true
System.out.printlin(map.size()); //0
}public static void main(String[] args){
Map<String, String> map = new HashMap<>();
map.put("张三","北京");
map.put("李四","北京");
map.put("王五","上海");
map.remove("王五");
System.out.printlin(map.isEmpty()); //false
System.out.printlin(map.size()); //2
System.out.printlin(map.containsKey("张三")); //true
System.out.printlin(map.containsValue("上海")); //false
map.clear();
}- 双列集合底层的数据结构,都是针对键有效,跟值没有关系
- HashMap:键唯一(重写hashCode和equals方法)
- TreeMap:键排序(实现Comparable接口,重写compareTo方法)
- LinkedList:键唯一,且可以包装存取顺序
HashMap的底层原理
- 利用键计算哈希值,与值无关
- JDK8开始,长度超过8&数组长度>=64,自动转成红黑树
- 底层是哈希表结构
- 依赖hashCode方法和equals方法保证键的唯一
- 如果键存储的是自定义对象,需要重写hashCode和equals方法
Map接口
- Map集合定义:Map集合是一种双列集合,每个元素包含两个数据
- Map集合的每个元素的格式:key = value(键值对元素)
- key(键):不允许重复
- value(值):允许重复
- 键和值是一一对应的,每个键只能找到自己对应的值
- Map接口定义 :双列集合的数据结构,都只针对于键有效,和值没有关系
| 类型 | 特点 |
|---|---|
| TreeSet | 键(红黑树),键排序 |
| HashMap | 键(哈希表),键唯一 |
| LinkedHashMap | 键(哈希表+双向链表)键唯一,并保证存储顺序 |
Map集合的三种遍历方式
- 通过键找值
方法名称 说明 V get(Object key) 根据键查找对应的值 Set<K> keySet() 获取Map集合中所有的键 public static void main(String[] args){ HashMap<String, String> hm = new HashMap<>(); hm.put("张三","北京"); hm.put("李四","上海"); hm.put("王五","成都"); //1.获取到所有的键 Set<String> keySet = hm.keySet(); //2.遍历Set集合,获取每一个键 for(String key : keySet){ //3.调用Map集合的get方法,根据键查找对应的值 String value = hm.get(key); System.out.printlin(key + value); } }总结 1.调用keySet方法获取所有的键(得到的是Set集合) 2.遍历Set集合,获取每一个键 3.遍历的过程中调用get方法,根据键找值 - 通过键值对对象获取键和值
方法名称 说明 Set<Map.Entry<K,V>> entrySet() 获取集合中所有的键值对对象 方法名 说明 getKey() 获取键 getValue() 获取值 public static void main(String[] args){ HashMap<String, String> hm = new HashMap<>(); hm.put("张三","北京"); hm.put("李四","上海"); hm.put("王五","成都"); //1.获取到所有的键 Set<Map.Entry<String, String>> entrySet = hm.entrySet(); //2.遍历Set集合,获取每一个键值对对象 for(Map.Entry<String, String> entry : entrySet();){ //3.通过键值对对象,获取键和值 System.out.printlin(entry.getKey() + entry.getValue()); } }总结 1.调用entrySet方法获取所以得键值对对象(得到的是Set集合) 2.遍历Set集合,获取每一个键值对对象 3.通过键值对对象的getKey() getValue()获取键和值 注意:Entry是Map外部类中的一个内部类接口
- 通过foreach方法遍历
| 方法名称 | 说明 |
|---|---|
| default void foreach(BigConsumer<? super K,? super V> action) | 遍历Map集合,获取键和值 |
public static void main(String[] args){
HashMap<String, String> hm = new HashMap();
hm.put("张三","北京");
hm.put("李四","上海");
hm.put("王五","成都");
hm.forEach(new BigConsumer<String, String>(){
@Override
public void accept(String key, String value){
System.out.printlin(key + value);
}
});
//或者:hm.forEach((key, value) -> System.out.printlin(key + value));
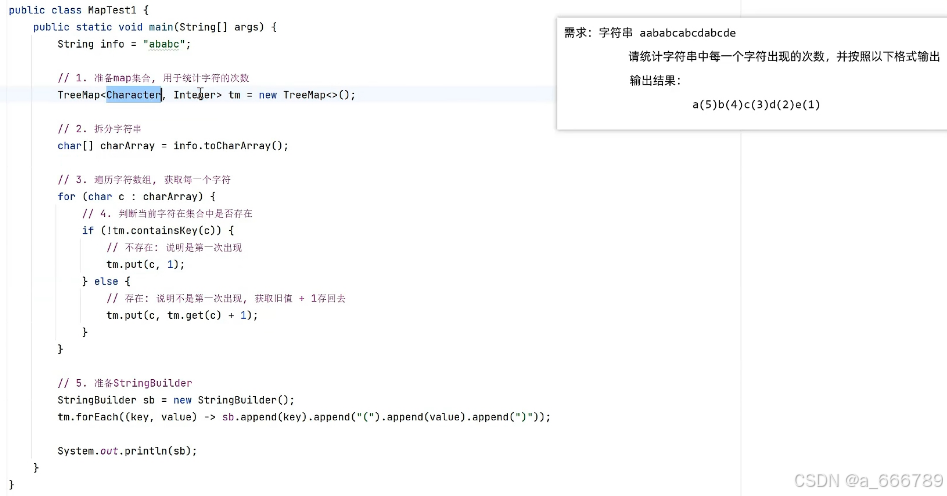
}示例:Map<店铺对象, List集合<商品对象>>

Collections集合工具类
-
java.utils.Collections:是集合工具类
-
作用:Collections并不属于集合,是用来操作集合的工具类
Collections常用API
| 方法名称 | 说明 |
|---|---|
| public static <T> boolean addAll(Collection<? super T> c, T ... elements) | 给集合对象批量添加元素 |
| public static void shuffle(List<?> list) | 打乱List集合元素的顺序 |
| public static <T> int binarySearch (List<T> list, T key) | 以二分查找法查找元素 |
| public static <T> void max/min(Collection<T> coll) | 根据默认的自然排序获取最大/小值 |
| public static <T> void swap(List<?> list, int i, int j) | 交换集合中指定位置的元素 |
publc staic void main(String[] args){
System.out.printlin(getSum(1,2,3));
System.out.printlin(getSum(1,2,3,4));
int[] arr = {1,2,3,4,5};
getSum(arr);
}
public static int getSum(int... nums){
int sum = 0;
for(int num : nums){
sum += num;
}
return sum;
}
public static void main(String[] args){
//批量添加
TreeSet<String> list = new TreeSet<>();
Collection.addAll(list, "a", "b", "c", "d");
System.out,printlin(list);
//二分查找(前提:必须是排好序的数据)
System.out.printlin(Collections.binarySearch(list, "b"));
//洗牌
Collections.shuffle(list);
System.out.printlin(list);
ArrayList<Integer> nums = new ArrayList<>();
Collections.addAll(nums, 1,2,3,4,5,6);
//从集合中找最值
System.out.printlin(Collections.max(nums));
System.out.printlin(Collections.min(nums));
//从集合中找最值(如果是自定义对象):需要重写compareTo和equals方法
ArrayList<Integer> nums = new ArrayList<>();
Collections.addAll(nums, new Student("张三",23), new Student("王五",25), new Student("李四",24));
System.out.printlin(Collections.max(nums));
System.out.printlin(Collections.min(nums));
}Collections排序相关API
- 使用范围:只能对于List集合的排序
- 排序方式1:
注意:本方式不可以直接对自定义类型的List集合排序,除非自定义类型实现了比较规则Comparable接口方法名称 说明 public static <T> void sort(List<T> list) 将集合中元素按照默认规则排序 - 排序方式2:
| 方法名称 | 说明 |
|---|---|
| public static <T extends Comparable<? super T>> void sort(List<T> list) | 将集合中元素按照默认规则排序 |
//sort:对集合进行排序
ArrayList<Integer> box = new ArrayList<>();
Collections.addAll(box, 1, 3, 5, 2, 4);
//可写为:Collections.sort(box, (o1, o2) -> o2 - o1);
Collections.sort(box, new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2){
return o2-o1;
}
});
System.out.printlin(box);
//sort:对集合进行排序
ArrayList<Integer> box = new ArrayList<>();
Collections.addAll(box, 1, 3, 5, 2, 4);
Collections.sort(box);
System.out.printlin(box);数据结构
介绍:计算机地层存储、组织数据的方式,是指数据相互之间是以什么方式排列在一起的,根据实际情况选择特定数据结构,可以提高运行或者存储效率
| 常见的数据结构 |
|---|
| 栈 |
| 队列 |
| 数组 |
| 链表 |
| 二叉树 |
| 二叉查找树 |
| 平衡二叉树 |
| 红黑树 |
| 哈希表 |
栈、队列
- 栈
- 一端开口(栈顶),一段封闭(栈底)
- 进栈/压栈(栈顶),出栈/弹栈(栈顶)
- 后进先出,先进后出
- 比作弹夹
- 队列
- 一端开口(后端),一端开口(前端)
- 入队列(后端),出队列(前端)
- 先进先出,后进后出
数组
- 查询速度快:通过地址值和索引定位,查询任意数据耗时相同
- 增、删效率低:有可能需要大批量的移动数组中的其他元素
链表
- 分为单向链表和双向链表
- 链表中结点是独立对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址
- 链表查询慢,无论查询哪个数据都要从头开始找
- 链表增删相对于数组而言,较快
- 比如:在数据A、C之间添加一个数据B
- 数据B对应的下一个数据地址指向数据C
- 数据A对应的下一个数据地址指向数据B
- 比如:在数据B、D之间的数据C
- 数据B对应的下一个数据地址指向数据D
- 数据C删除
| 数据结构 | 特点和作用 |
|---|---|
| 栈 | 后进先出,先进后出 |
| 队列 | 先进先出,后进后出 |
| 数组 | 内存连续区域,查询快,增删慢 |
| 链表 | 元素是游离的,查询慢,收尾操作极 |
树
| 节点 | 父节点地址、值、左子节点地址、右子节点地址 |
| 度 | 每一个节点的子节点数量(二叉树中,任意节点的度<=2) |
| 树高 | 树的总层数 |
| 根节点 | 最顶层的节点 |
| 左(右)子节点 | 左(右)下方的节点 |
| 左(右)子树 |
普通二叉树
定义:基本的树形数据结构,对节点的值没有任何限制,无特定排序规则
二叉查找树
- 定义:又称二叉排序树或者二叉搜索树
- 特点:
- 每一个节点上最多有两个子节点
- 任意节点左子树上的值都小于当前节点
- 任意节点右子树上的值都大于当前节点
- 添加节点规则:小的存左边、大的存右边、一样的不存
- 弊端:高度不平衡导致效率低下
平衡二叉树
- 规则:任意节点左右子树高度差不超过1
- 旋转机制:
- 左旋
- 右旋
- 触发时机:当添加一个节点之后,该树不再是一棵平衡二叉树
- 左(右)旋:
- 确定支点:从添加的节点开始,不断的往父节点找不平衡的节点
- 步骤A【不平衡的节点无左(右)子节点】:①以不平衡的点作为支点;②把支点左(右)旋降级,变成左(右)子节点;③晋升原来的右(左)子节点
- 步骤B【不平衡的节点有左(右)子节点】:①以不平衡的点作为支点;②将根节点的右(左)侧往左拉;③原先的右(左)子节点变成新的父节点,并把多余的左(右)子节点出让,给已经降级的根节点当右(左)子节点
| 需要旋转的四种情况 | 出现原因 | 处理方式 |
|---|---|---|
| 左左 | 当根节点左子树的左子树有节点插入,导致二叉树不平衡 | 一次右旋 |
| 左右 | 当根节点左子树的右子树有节点插入,导致二叉树不平衡 | 先局部左旋,再整体右旋 |
| 右右 | 当根节点右子树的右子树有节点插入,导致二叉树不平衡 | 一次左旋 |
| 右左 | 当根节点右子树的左子树有节点插入,导致二叉树不平衡 | 先局部右旋,再局部左旋 |
红黑树
- 定义:平衡的二叉查找树,特殊的二叉查找树,每一个节点有存储位表示节点的颜色
- 节点:父节点地址、值、左子节点地址、右子节点地址、颜色
- 每一个节点可以是红或者黑,高度不平衡,平衡通过“红黑规则”实现
| 红黑规则 |
|---|
| ①每一个节点是红色或者黑色 |
| ②根节点必须是黑色 |
| ③如果一个节点无子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的 |
| ④如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况) |
| 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点 |
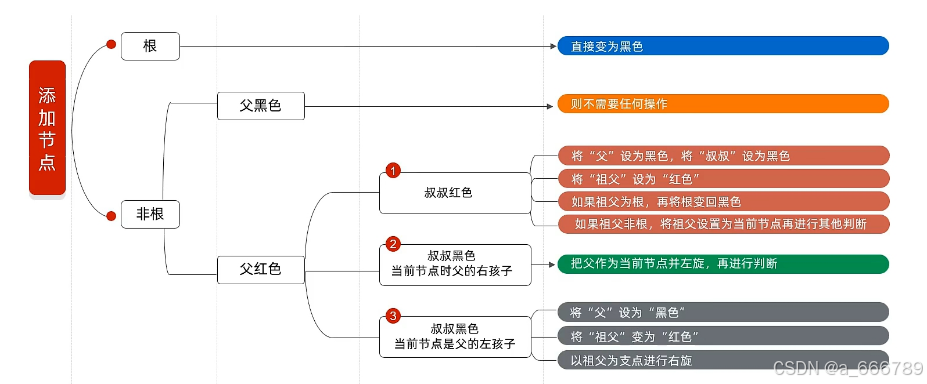
- 添加节点的规则:添加节点默认是红色的(效率高)
泛型
泛型介绍
- JDK5引入的,可以在编译阶段约束操作的数据类型,并进行检查
- 泛型的好处:统一数据类型,将运行期的错误提升到了编译期
- 泛型只能编写引用数据类型
public static void main(String[] args){ String[] arr1 = {"张三", "李四", "王五"}; Integer[] arr2 = {11, 22, 33}; //若改为int[] arr2则会报错,因为泛型只能编写引用数据类型 Double[] arr3 = {11.1, 22.2, 33.3}; printArray(arr1); printArray(arr2); printArray(arr3); } public static <T> void printArray(T[] arr){ System.out.print("["); for(int i = 0; i < arr.length - 1; i++){ System.out.print(arr[i] + ","); } System.out.printlin(arr[arr.length - 1] + "]"); } - 注意:泛型默认的类型是Object
public static void main(String[] args){ ArrayList list = new ArrayList(); list.add("张三"); list.add("李四"); list.add("王五"); list.add(new Random()); Iterator it = list.iterator(); while(it.hasNext()){ Object o = it.next(); //String s = (String) o; 向下转型,为了调用length()方法 //System.out.printlin(s.length()); } ] Iterator<String> it = list.iterator(); while(it.hasNext()){ String o = it.next(); }
常见的泛型标识符
| 常见的泛型标识符 | 含义 |
|---|---|
| E | Element |
| T | Type |
| K | Key(键) |
| V | Value(值) |
泛型的学习路径
- 泛型类
- 泛型方法
- 泛型接口
- 泛型通配符
- 泛型的限定
泛型类
- 创建对象的时候确定具体类型
//格式
public class ArrayList<E>{
public boolean add(E e){
}
}
//例子
public static void mian(String[] args){
Student<Integer> stu = new Student<>();
stu.setE(//Integer e);
}
class Student<E>{
private E e;
public E getE(){
return e;
}
public void setE(E e){
this.e = e;
}
}
//例子
public class A{
public static void main(String[] args){
ArrayList<String> list = new ArrayList<>();
list.add(//String e);
}
}
public class B{
public static void main(String[] args){
ArrayList list = new ArrayList();
list.add(//Object e);
}
}泛型方法
非静态方法:泛型是根据类的泛型去匹配的
public class ArrayList<E>{
public boolean add(E e){
}
}静态方法:需要声明处自己独立的泛型,在该静态方法被调用,传入实际参数时,确定具体类型
public static<T> void printArray(T[] array){
}泛型接口
- 类实现接口的时候,如果接口带有泛型,有两种操作方式
- 类实现接口的时候,直接确定类型
Interface Inter<E>{ void show(E e); } class InterAIml implements Inter<String>{ @Override public void show(String s){ } } - 延续接口的泛型,等创建对象的时候再确定
public Interface List<E>{ } public class ArrayList<E> implements List<E>{ }泛型通配符
| 泛型通配符 | 含义 |
|---|---|
| ? | 任意类型 |
| ? extends E | 只能接收E或者是E的子类 |
| ? super E | 只能接收E或者是E的父类 |
abstract class Employee{
public abstract void work();
}
abstract Coder extends Employee{
@Override
public void work(){
System.out.printlin("程序员写代码...");
}
abstract Manager extends Employee{
@Override
public void work(){
System.out.printlin("项目经理分配任务...");
}
public static void main(String[] args){
ArrayList<Coder> list1 = new ArrayList<>();
list1.add(new Coder());
ArrayList<Manager> list2 = new ArrayList<>();
list2.add(new Manager());
method(list1);
method(list2);
}
//任何引用数据类型都能传入
public static void method(ArrayList<?> list){
for(Object o : list){
Employee e = (Employee) o;
e.wor();
}
}abstract class Employee{
public abstract void work();
}
abstract Coder extends Employee{
@Override
public void work(){
System.out.printlin("程序员写代码...");
}
abstract Manager extends Employee{
@Override
public void work(){
System.out.printlin("项目经理分配任务...");
}
public static void main(String[] args){
ArrayList<Coder> list1 = new ArrayList<>();
list1.add(new Coder());
ArrayList<Manager> list2 = new ArrayList<>();
list2.add(new Manager());
method(list1);
method(list2);
}
//只能传入Employee及其子类
public static void method(ArrayList<? extends Employee> list){
for(Object o : list){
Employee e = (Employee) o;
e.wor();
}
}abstract class Employee{
public abstract void work();
}
abstract Coder extends Employee{
@Override
public void work(){
System.out.printlin("程序员写代码...");
}
abstract Manager extends Employee{
@Override
public void work(){
System.out.printlin("项目经理分配任务...");
}
public static void main(String[] args){
ArrayList<Coder> list1 = new ArrayList<>();
list1.add(new Coder());
ArrayList<Manager> list2 = new ArrayList<>();
list2.add(new Manager());
ArrayList<Object> list 3 = new ArrayList<>();
method(list1);
method(list2);
method(list3);
}
//只能接收Employee及其父类
public static void method(ArrayList<?> list){
for(Object o : list){
Employee e = (Employee) o;
e.wor();
}
}注明:本文中截图均来自bilibili中黑马程序员up主


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









