







在事务中Redis提供了队列,可以批量执行任务,这样性能就比较高,但使用multi…exec事务命令是有系统开销的,因为它会检测对应的锁和序列化命令。有时我们希望在没有任何附加条件的情况下使用队列批量执行一系列命令,这时可以使用Redis的流水线(pipelined)技术。
实际中Redis的读写速度十分快,而系统的瓶颈往往是在网络通信中的延时。比如当命令1在T1时刻发送到Redis服务器后,服务器很快执行完命令1,而命令2在T2时刻却没有通过网络送达Redis服务器,这样就变成了Redis服务器在等待命令2的到来,当命令2到达且被执行后,命令3还没到,又得继续等待,以此类推,这样Redis的等待时间就会很长,很多时候在空闲的状态,而问题出现在网络的延迟中,造成了系统的瓶颈。
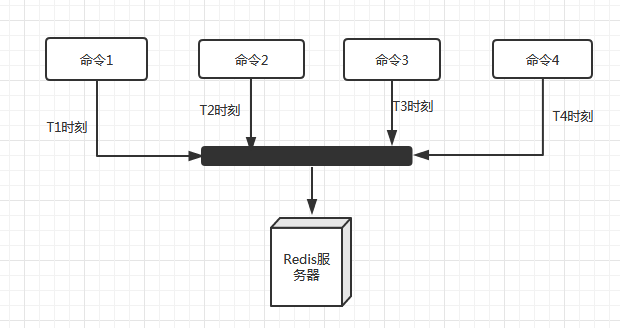
为了解决这个问题,可以使用Redis的流水线,但Redis的流水线是一种通信协议,没有办法通过客户端演示,不过可以通过Java API或使用Spring操作它。
/**
* 测试Redis流水线
* @author liu
*/
public class TestPipelined {
/**
* 使用Java API测试流水线的性能
*/
@SuppressWarnings({ "unused", "resource" })
@Test
public void testPipelinedByJavaAPI() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(20);
jedisPoolConfig.setMaxTotal(10);
jedisPoolConfig.setMaxWaitMillis(20000);
JedisPool jedisPool = new JedisPool(jedisPoolConfig,"localhost",6379);
Jedis jedis = jedisPool.getResource();
long start = System.currentTimeMillis();
// 开启流水线
Pipeline pipeline = jedis.pipelined();
// 测试10w条数据读写
for(int i = 0; i < 100000; i++) {
int j = i + 1;
pipeline.set("key" + j, "value" + j);
pipeline.get("key" + j);
}
// 只执行同步但不返回结果
//pipeline.sync();
// 以list的形式返回执行过的命令的结果
List<Object> result = pipeline.syncAndReturnAll();
long end = System.currentTimeMillis();
// 计算耗时
System.out.println("耗时" + (end - start) + "毫秒");
}
/**
* 使用RedisTemplate测试流水线
*/
@SuppressWarnings({ "resource", "rawtypes", "unchecked", "unused" })
@Test
public void testPipelineBySpring() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
RedisTemplate rt = (RedisTemplate)applicationContext.getBean("redisTemplate");
SessionCallback callback = (SessionCallback)(RedisOperations ops)->{
for(int i = 0; i < 100000; i++) {
int j = i + 1;
ops.boundValueOps("key" + j).set("value" + j);
ops.boundValueOps("key" + j).get();
}
return null;
};
long start = System.currentTimeMillis();
// 执行Redis的流水线命令
List result = rt.executePipelined(callback);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
书上写的测试结果为:使用Java API耗时在550ms到700ms之间,也就是不到1s就完成了10万次读写,使用Spring 耗时在1100ms到1300ms之间。
我的测试结果:使用Java API耗时在13s左右,使用Spring直接内存溢出,这说明我得换电脑了。















 5501
5501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









