







“刘郎已恨蓬山远,更隔蓬山一万重”
序
现在做的是从web端给眼镜端发送消息,其实就是web端把消息存到数据库,然后眼镜从数据库获取消息即可。现在在web端的输入框需要直接复制图片进去,于是就用上了富文本编辑器。
正文
在研究了多个富文本编辑器后,基于免费、好用、简洁的原则(主要是基于免费),最终选择使用wangEditor。
使用场景
从Word中复制图片、文字、标题、部分带样式的文字到编辑器中。可实现取出文字和图片的功能,不包含Word上的样式,比如加粗、斜体等样式。
说明:以下内容均基于该使用场景。
使用方法
- 下载wangEditor的JS。
官网首页有个下载,点下载之后进入GitHub,选择要下载的版本后,下载source code压缩包。然后从压缩包中把JS取出来:
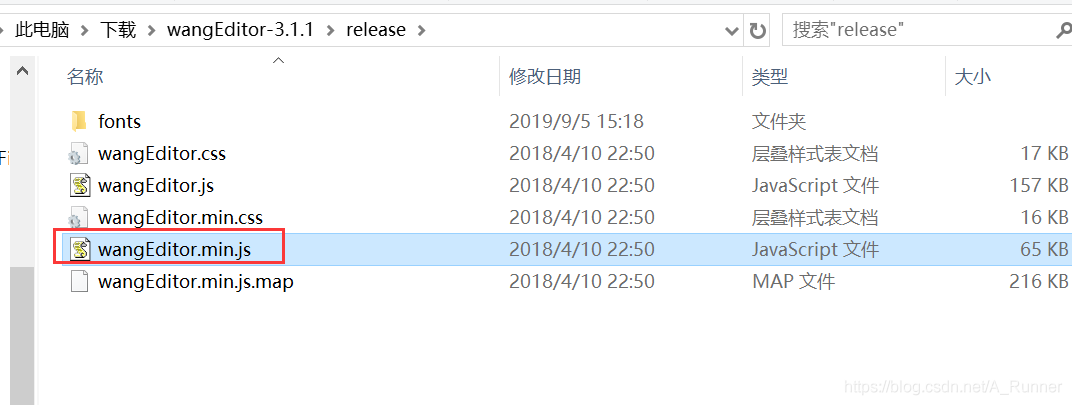
- 将上面说的JS复制你的项目中,然后在页面上引用。
<script src="/js/wangEditor.min.js"></script>
创建一个富文本编辑器:
<script type="text/javascript">
var editor ; //定义全局变量
//富文本编辑器
var E = window.wangEditor;
editor = new E('#textarea');
editor.customConfig.uploadImgShowBase64 = true; // 使用 base64 保存图片,使用这种方式上传图片,然后在服务器端把base64编码转成图片。这样就不需要上传文件了。
editor.customConfig.menus = []; //设置不要工具栏
editor.create();
</script>
- 获取富文本编辑器的内容
var editorData = editor.txt.html();
获取编辑器的内容还有其他方式:
var editorData = editor.txt.text();
//或者
var editorData = editor.txt.getJSON();
具体参考文档:读取内容
- 通过
editor.txt.html();读取的内容都含有样式,(如果是通过通过Word粘贴进去的文本或图片,请看步骤6)比如p标签,img标签之类的,所以需要去除这些标签,直接把p标签里面的内容和img标签图片的base64编码取出来,用到正则表达式:
//获取编辑器的内容
var editorData = editor.txt.html();
//定义一个图片编码和文字的数组
var picArr = new Array();
var wordArr = new Array();
//获取图片编码的正则
var p = /<img\s?src="data\:image\/.*?;base64,(.*?)"/ig;
while(true){
var match = p.exec(editorData);
if(match){
picArr.push(match[1]);
}else{
break;
}
}
//获取p标签中的文字
p = /<p>([^<]*?)<\/p>/ig;
while(true){
var match = p.exec(editorData);
if(match){
//判断是否全是空格
if (!match[1].match(/^[ ]*$/)) {
wordArr.push(match[1]);
}
}else{
break;
}
}
- 通过上面代码就能获取到在编辑器中输入的文字,或者是从Word中粘贴过去的图片。然后通过文字数组和图片编码的数组,传到服务端处理就可以了。
- 但是如果从Word上粘贴文字到编辑器的话,会有很多样式,比如:加粗、斜体、下划线等,这种情况的需要去除这些样式文本,我把整个的代码都贴出来:
直接可以用的JS代码:
function getEditorData(){
//处理富文本编辑器的数据
var picArr = new Array();
var editorData = editor.txt.html();
//处理Word复制过来的样式
editorData = cleanPastedHTML(editorData);
//获取图片
var p = /<img\s?src="data\:image\/.*?;base64,(.*?)"/ig;
while(true){
var match = p.exec(editorData);
if(match){
picArr.push(match[1]);
}else{
break;
}
}
var wordArr = new Array();
//获取图片后面紧跟的文字,由于紧跟在图片后面,所以通过p标签获取文字的正则获取不到。
p = /">(.*?)<br>/ig;
while(true){
var match = p.exec(editorData);
if(match){
if (match[1] != '') {
wordArr.push(match[1]);
}
}else{
break;
}
}
//获取标题内容,因为Word中的标题,在富文本编辑器中获取出来都带<h1></h1>或<h2></h2>等
p = /<h\d>(.*?)<\/h\d>/ig;
while(true){
var match = p.exec(editorData);
if(match){
//判断是否全是空格
if (!match[1].match(/^[ ]*$/)) {
wordArr.push(match[1]);
}
}else{
break;
}
}
//获取p标签中的文字
p = /<p>([^<]*?)<\/p>/ig;
while(true){
var match = p.exec(editorData);
if(match){
//判断是否全是空格
if (!match[1].match(/^[ ]*$/)) {
wordArr.push(match[1]);
}
}else{
break;
}
}
}
//去掉Word复制过来的样式
function cleanPastedHTML(input) {
// 1. remove line breaks / Mso classes
var stringStripper = /(\n|\r| class=(")?Mso[a-zA-Z]+(")?)/g;
var output = input.replace(stringStripper, ' ');
// 2. strip Word generated HTML comments
var commentSripper = new RegExp('<!--(.*?)-->','g');
var output = output.replace(commentSripper, '');
var tagStripper = new RegExp('<(/)*(meta|link|span|\\?xml:|st1:|o:|font)(.*?)>','gi');
// 3. remove tags leave content if any
output = output.replace(tagStripper, '');
// 4. Remove everything in between and including tags '<style(.)style(.)>'
var badTags = ['style', 'script','applet','embed','noframes','noscript'];
for (var i=0; i< badTags.length; i++) {
tagStripper = new RegExp('<'+badTags[i]+'.*?'+badTags[i]+'(.*?)>', 'gi');
output = output.replace(tagStripper, '');
}
// 5. remove attributes ' style="..."'
var badAttributes = ['style', 'start'];
for (var i=0; i< badAttributes.length; i++) {
var attributeStripper = new RegExp(' ' + badAttributes[i] + '="(.*?)"','gi');
output = output.replace(attributeStripper, '');
}
//去掉下划线、删除线、斜体、加粗等标签
output = output.replaceAll("<b>","").replaceAll("</b>","").replaceAll("<i>","").replaceAll("</i>","").replaceAll("<u>","")
.replaceAll("</u>","").replaceAll("<s>","").replaceAll("</s>","").replaceAll("<p >","<p>");
return output;
}
//全部替换方法
String.prototype.replaceAll = function(s1,s2){
return this.replace(new RegExp(s1,"gm"),s2);
};
- 我再把后台处理base64编码成图片的方法再贴一下:
//先把base64编码转成流,imgBase64Code就是前台传过来的图片编码,由于我这里把图片编码加到数组里了,所以要先循环数组,这里省略了循环。
byte[] byt = Base64Utils.decode(imgBase64Code);
//再把流写成文件,fileName是随机生成的文件名,filePath是要存储的路径
FileUtil.uploadFile(byt, filePath, fileName);
public static byte[] decode(String s) {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try {
decode(s, bos);
} catch (IOException e) {
throw new RuntimeException();
}
byte[] decodedBytes = bos.toByteArray();
try {
bos.close();
bos = null;
} catch (IOException ex) {
System.err.println("Error while decoding BASE64: " + ex.toString());
}
return decodedBytes;
}
public static void uploadFile(byte[] file, String filePath, String fileName) throws Exception {
File targetFile = new File(filePath);
if (!targetFile.exists()) {
targetFile.mkdirs();
}
FileOutputStream out = new FileOutputStream(filePath +"/"+ fileName);
out.write(file);
out.flush();
out.close();
}
- 特别说明一下,上面的
cleanPastedHTML方法,引用了这篇博客中的方法。声明感谢!














 1845
1845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









