







 本文介绍了如何使用Python进行网络爬虫,以获取豆瓣读书新书推荐的数据。通过解析网页元素,利用BeautifulSoup提取书籍的名称、作者和评分,并对二级页面进行迭代访问,展示了爬虫的入门应用。
本文介绍了如何使用Python进行网络爬虫,以获取豆瓣读书新书推荐的数据。通过解析网页元素,利用BeautifulSoup提取书籍的名称、作者和评分,并对二级页面进行迭代访问,展示了爬虫的入门应用。
前言:
数据获取是数据分析师的职场必备技能,其中通过网络爬虫,自动、有组织地爬取一些网站数据,既实用,又有趣。本文通过对豆瓣新书速递页面及其子页面的迭代爬取,介绍python3环境下,网络爬虫的入门级用法。
其中的要点在于通过网页元素信息,定位到目标信息的标签格式,然后通过python的一些网络分析包,如 beautifulsoup 来有效提取相关信息。
一、要爬取的信息说明
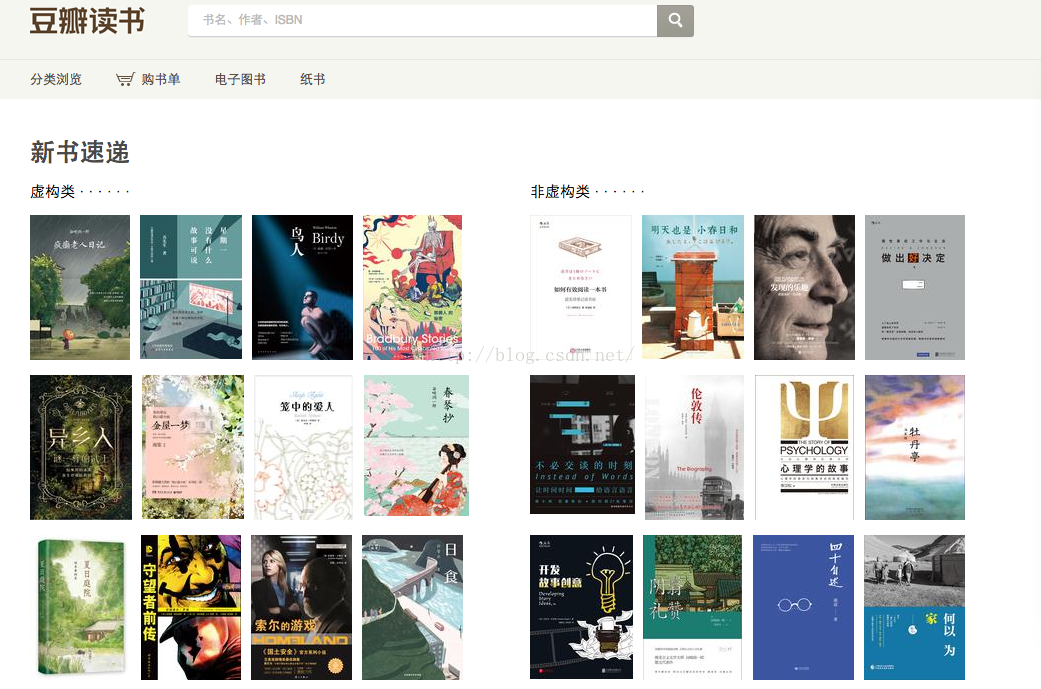
豆瓣读书经常会推荐一些市面上的新书,其页面为https://book.douban.com/latest?icn=index-latestbook-all 。如果想查看每本书的详细信息,需要点击进去二级页面查看。那么,我们这里拿来练手的,就是先访问左下的介绍页面,获取推荐的书的总量,以及每本书的下一步页面链接,然后迭代访问每本书的详情页,找出书名、作者、评分信息。最终统一打印出来。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









