







 本文通过一个实际案例,演示如何使用Python爬取新浪微博评论,Spark进行文本预处理,R进行文字云可视化,展示数据科学工作流程中的数据获取、处理到展示的全过程。
本文通过一个实际案例,演示如何使用Python爬取新浪微博评论,Spark进行文本预处理,R进行文字云可视化,展示数据科学工作流程中的数据获取、处理到展示的全过程。
日常情况下,我们常常是从整洁的数据仓库表中读取数据,进行数据分析,但事实上,数据科学工作往往需要进行数据获取,预处理,分析,展示这样整个的流程。本文从一个实际的案例出来,将不同的分析工具串联起来(虽然仅用一种工具也能实现全流程工作,但不是本文的侧重点),目的是为了体现不同工具的特点和实际使用方法,有利于开拓思路。
任务说明
从新浪微博上爬取天猫超市微博消息的评论,进行分词,使用文字云的形式进行可视化。包括以下步骤:
1. 爬取新浪微博消息;本文使用python处理
2. 中文文本预处理,包括分词,剔除停用词,词频统计;本文使用spark处理
3. 文字云展示; 本文使用R处理
1. 数据获取
以下是天猫超市新浪微博最近发布的某条消息,下面有一些评论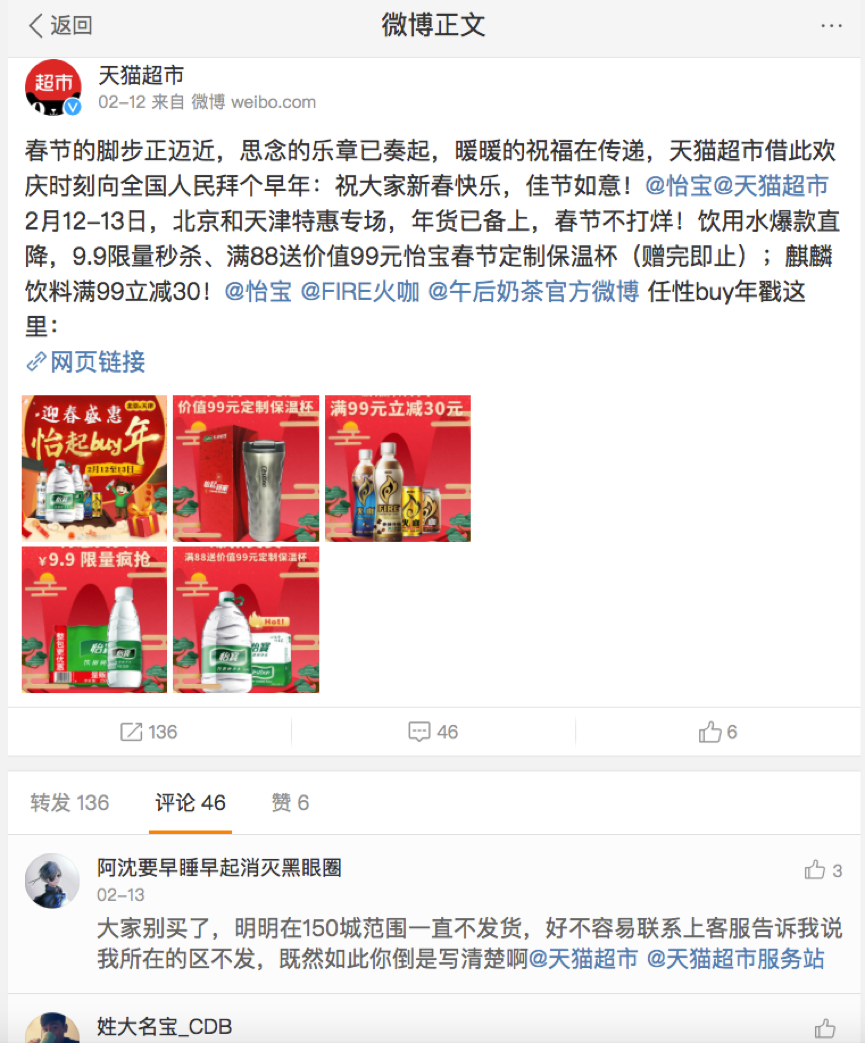
爬取的时候,从较容易的移动端网页入手,这里采用m.weibo.cn作为入手点,从浏览器窗口中可观察到每个微博消息的ID,如下图所示:
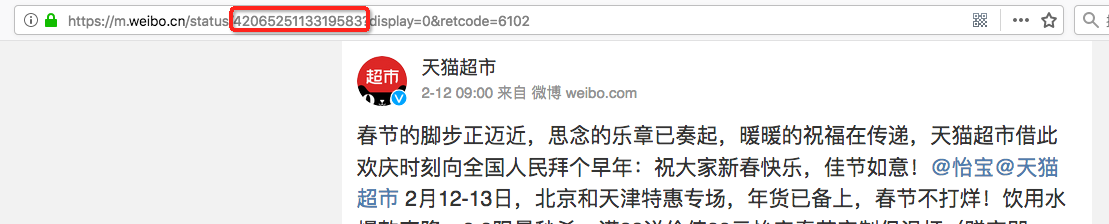
微博评论页面的链接格式为“
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









