






 文章介绍了不同时间复杂度的排序,从常数阶到阶乘阶,并通过例子解释了最差与最佳时间复杂度的情况。同时,讨论了空间复杂度,包括循环与递归的空间占用,并提到了尾递归的概念。数据结构部分,文章阐述了数组和链表的特点,以及它们在内存分配和操作上的优势与局限性。
文章介绍了不同时间复杂度的排序,从常数阶到阶乘阶,并通过例子解释了最差与最佳时间复杂度的情况。同时,讨论了空间复杂度,包括循环与递归的空间占用,并提到了尾递归的概念。数据结构部分,文章阐述了数组和链表的特点,以及它们在内存分配和操作上的优势与局限性。
时间复杂度分析
常见类型:
0(1) < 0(log n) < 0(n) < 0(n log n) < 0() < 0(
) < 0(n!)
常数阶 0(1):
数量大小与输入数据 n 大小无关
线性阶 0(n)
数量大小与输入数据n成正比
平方阶 0(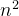 )
)
数量大小与输入数据成平方关系
指数阶 0(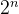 )
)
数量每轮一分为二,形成数列 1,2,4,8,16,......,
对数阶 0(log n)
数量每轮缩减一半,形成数列,如:,
,
,....,16,8,4,2,1
线性对数阶 0(nlog n)
数量每轮缩减一半后再与输入数据成正比增加
阶乘阶 0(n!)
数量每轮依次加上 自身与(1 ~ n)
最差与最佳时间复杂度
当 nums = [?,?,...,1],即当末尾元素是1时,则需完整遍历数组,此时达到最差时间复杂度 0(n);
当 nums = [1,?,?,...],即当首个数字为1时,无论数组多长都不需要继续遍历,此时达到最佳时间复杂度
空间复杂度分析
算法相关空间
通常情况下空间复杂度的统计范围:输入空间 (输入数据)->暂存空间 [暂存数据(变量,对象),栈桢空间(调用函数),指令空间 ]->输出空间(输出数据)
推算方法
循环空间复杂度 0(1) :每一次循环都会重新释放空间
递归空间复杂度 0(n) :递归调用自身,其实是n个相同函数同时进行,因此递归空间复杂度为0(n)
常见类型
0(1) < 0(log n) < 0(n) < 0() < 0(
)
常数阶 0(1)
空间数量与数据大小无关,常数、变量、对象占用 0(1)空间。
平方阶 0()
空间数量与数据大小成平方关系,矩阵、二维列表、递归函数占用0()空间。
指数阶 0()
常见于二叉树
对数阶 0(log n)
常见于分治算法、数据类型转换、归并排序
甜点1
介绍
若函数在尾位置调用自身(或是一个尾调用本身的其他函数等等),则称这种情况为尾递归
特点
尾递归在普通尾调用的基础上,多出了2个特征;
1.在尾部调用函数本身(Self-cellded)
2.可通过优化,使计算仅占常量栈空间(Stack-Space)
原理
当编译器检测到一个函数调用是尾递归的时候,就会覆盖当前活动记录,而不是在栈重新创建一个新的空间
所谓数据结构
简介
数据结构是在计算机中的组织与存储数据的方式
分类
数据结构主要可根据逻辑结构和物理结构两种角度进行分类
数组
简介
数组是将相同类型元素存储在连续空间的数据结构,将元素在数组的位置称为元素的索引;
初始化
int[] arr = new int[5]//{ 0, 0, 0, 0, 0}
int[] nums = { 1, 3, 2, 5, 4}优点
能高效访问元素
元素内存地址 = 数组内存地址 + 元素长度*元素索引
缺点
1.基于数组创建的数据结构是静态的,长度不可扩展
2.不便在数组的索引出插入元素
3.不便删除索引处元素
常用操作
1.遍历数组
2.在数组中查找指定元素
典型应用
甜点2
通用:
栈内存分配由翻译器自动完成,而堆内存由程序员在代码中分配(请注意这里的栈和堆不是数据结构中的栈和堆)
链表
定义
链表是将相同类型元素存储在离散空间的数据结构,对空间长度要求低,每个元素都是单独的对象,通过指针连接
存储链表节点的内存空间:存储节点值+存储节点指针(引用)
建立链表
1.初始化各个节点对象
2.构建引用
优点
方便元素的插入和删除
缺点
不便于访问元素节点
常见操作
遍历链表
常见链表类型
单项链表、环形链表、双向链表
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









