







单链表经典算法
注意!:
本文章中的所有头节点的说法 其实都是不太正确,不太严谨的,在本文章中为了便于理解,我将使用头节点作为链表的第一个节点的说法。
实际上头节点(放哨位)是带头链表中的的一个说法
1.1 移除链表元素
题目:
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
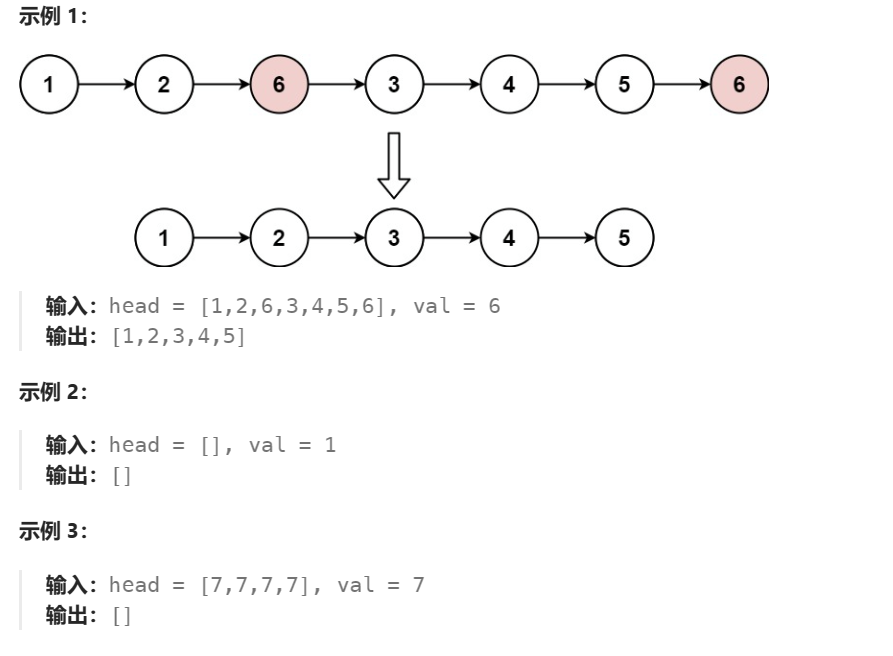
解答:
思路1:
- 遍历整个链表,让pcur指向第一个节点 然后向后去找
- 如果pcur指向的节点的数据是val那么就进行删除的操作
- 就是让prev指向前一个指针,next指向后一个指针
- 然后将pcur指向的指针删除,然后再让prev和next指向的节点链接起来
- 然后继续往后找 ,找到了就删除,没找到就一直往后找

思路2:
- 创建一个新链表 同样也是让pcur去遍历整个链表
- 当pcur指向的节点存储的数据 != val的时候,就将该节点尾插到新链表中
- 要让newTail指向新的尾节点,让新的尾节点具备指向下一个新的尾节点的能力
- 这样才能不断地进行尾插
- 如果pcur指向的节点存储的数据 == val的时候,就跳过接着往后找

解题代码:
这里我们采用思路2进行解题
struct ListNode
{
int val;
struct ListNode* next;
};
// 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点
typedef struct ListNode ListNode;
struct ListNode* removeElements(ListNode* head, int val)
{
// 创建一个新的链表
ListNode* newhead, * newtail;
newhead = newtail = NULL;
ListNode* pcur = head;
// 遍历原链表
while (pcur)
{
// 找节点数据不是val的节点
if (pcur->val != val)
{
// 要分类 新链表是否为空链表
if (newhead == NULL)
{
// 空链表就让pcur节点插入,同时作为新的头和尾
newhead = newtail = pcur;
}
else
{
newtail->next = pcur;
newtail = newtail->next;
}
}
// 走到这里说明插入节点到新链表完毕
pcur = pcur->next;
}
// 走到这里说明 不为val的节点 都已经放到新链表中了
// 但是我们要注意一个问题,就是最后一个节点所存储的指针要置为NULL
// 因为其有可能指向的是原链表的下一个值为val的节点
if (newhead) // 加一个判断是为了防止链表为空的情况
newtail->next = NULL;
return newhead;
}
1.2 反转链表
题目:
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。

思路1:
- 首先我们创建一个新的链表
- 然后我们去遍历原链表
- 把原链表的每一个节点都头插到我们的新链表中
- 记得要不断的让newHead更新 这样我们才能访问这个新链表

思路2:
- 首先我们创建三个指针, n1指向头节点,n2,n3分别指向下一个节点和下下个节点
- 然后让n2的next指针不再指向n3 而是指向n1
- 再让n1指向n2,n2指向n3,让n3指向n3的next指针 也就是n3的下一个节点
- 第2、3步做完就可以让一个节点倒着指向前面的节点
- 接着重复上述操作
- 直至将链表反转
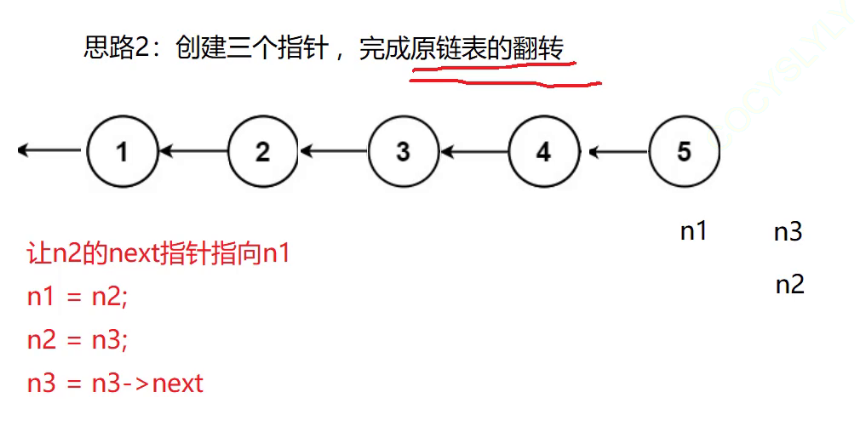
这里代码的实现我们采用思路2:
struct ListNode
{
int val;
struct ListNode *next;
};
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
if(head == NULL)
{
return head;
}
// 创建三个指针
ListNode* n1,*n2,*n3;
n1 = NULL; n2 = head; n3 = n2->next;
// 遍历原链表 并进行反转
while(n2)
{
n2->next = n1;
n1 = n2;
n2 = n3;
if(n3) // n3为NULL 无法进行解引用
n3 = n3->next;
}
// 走到这里说明反转完成
return n1;
}
思路1的代码也有:
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
// 创建一个新链表
ListNode* newHead = NULL;
ListNode* pcur = head;
// 遍历原链表 并将其节点 头插到新链表当中
while (pcur)
{
ListNode* temp = pcur; // 保存原链表的头节点
pcur = pcur->next;// 移动到下一个节点
temp->next = newHead; // 将当前节点头插到新链表的节点
newHead = temp; // 更新新链表的头节点
}
return newHead;
}
1.3 合并两个有序链表
题目:
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
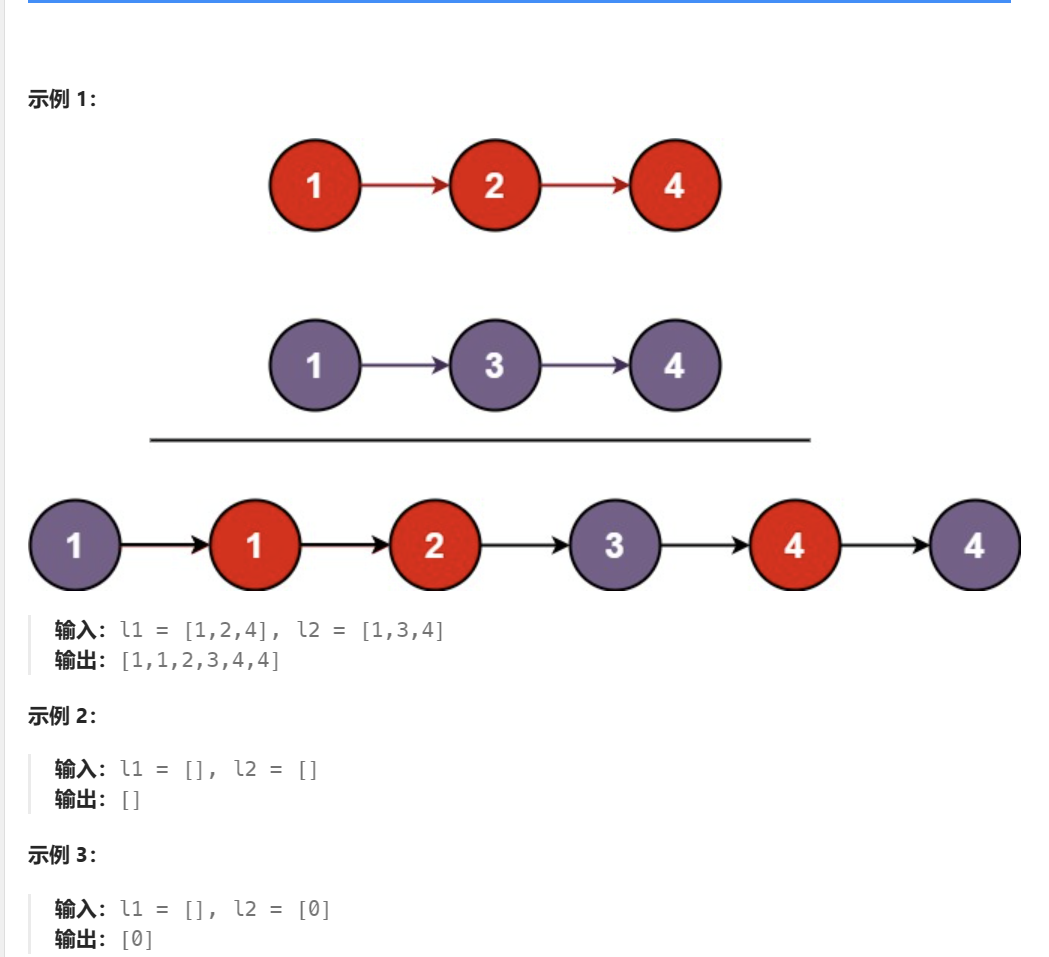
思路:
- 创建一个新链表
- 创建两个指针l1,l2分别指向第一个链表和第二个链表
- 通过l1,l2来比较链表中的数据谁小,谁小谁就尾插到新链表中。并让其指针向后走 指向下一个节点
- 最后停止循环的时候,只可能是l1为NULL 或者l2为NULL
- 这个时候判断是l1还是l2为NULL
- 判断完毕之后将 将另一个链表的剩余数据全部尾插到新链表中
注意:
要记得对空链表的情况进行处理,如果合并的两个有序链表中 有一个或者两个都是空链表 就返回另一个链表就行
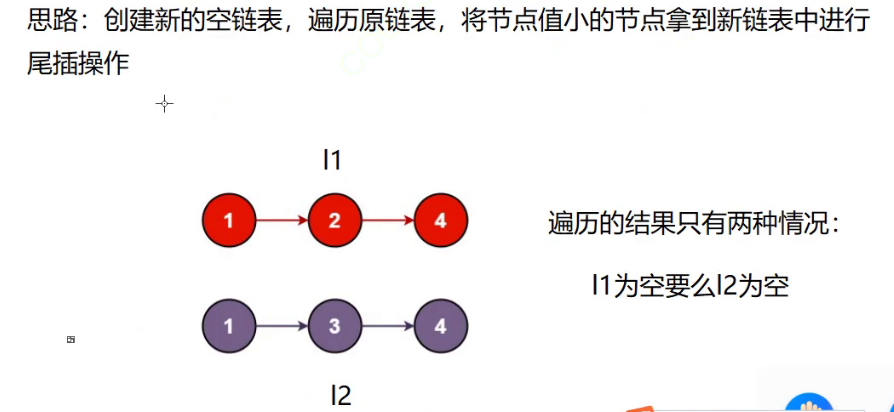
我们来看一下代码是如何是实现的:
struct ListNode
{
int val;
struct ListNode *next;
};
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
// 对原链表进行判空
if(list1 == NULL)
{
return list2;
}
if(list2 == NULL)
{
return list1;
}
// 首先创建一个新链表
ListNode *newHead, *newTail;
newHead = newTail = NULL;
// 创建l1 和 l2 指针去访问两个链表
ListNode* l1 = list1;
ListNode* l2 = list2;
// 去分别遍历链表并比较 指向的节点存储的数据谁大谁小
while(l1 && l2) // 当l1或者l2 访问完毕链表就退出循环
{
if(l1->val < l2->val) // l1节点的数据 小于 l2节点的数据
{
if(newHead == NULL) // 判断新链表是否为空
{
newHead = newTail = l1;
}
else
{
newTail->next = l1; // 将l1尾插到 新链表中
newTail = newTail->next;// 及时更新新链表的尾节点
}
l1 = l1->next; // 让l1向后遍历
}
else
{
if(newHead == NULL)
{
newHead = newTail = l2;
}
else
{
newTail->next = l2;
newTail = newTail->next;
}
l2 = l2->next;
}
}
// 退出循环代表着 l1 或者l2 已经遍历完链表了 已经是NULL了
//此时另外一个链表中还存在数据 要将这个剩下的数据全部尾插到我们的新链表当中
if(l2)
{
// l2 还有数据 但是我们不知道里面还有多少数据 用循环把l2全部数据尾插到我们的新链表
while(l2)
{
newTail->next = l2;
newTail = newTail->next;
l2 = l2->next;
}
}
if(l1)
{
while(l1)
{
newTail->next = l1;
newTail = newTail->next;
l1 = l1->next;
}
}
// 此时两个有序链表的数据 全部有序的放到了我们的新链表当中
return newHead; // 我们返回访问新链表头节点的指针
}
但是我们会发现一个问题:
那就是每次我们判断完谁大谁小的时候 准备尾插的时候,我们都要去判断新链表是否为空,但实际上我们只有一开始需要判断一次而已,那后面所有的执行都是重复执行了。


那我们要怎么去优化这个代码呢?
思路:
- 首先我们在一开始的时候不在给新链表初始化为NULL
- 而是给他动态的申请一个节点的空间,但是里面不存储有效的数据
- 这个时候我们两个链表的节点全部尾插到这个不存储数据的节点的后边
- 这样我们就不用去判断这个新链表是否为空链表
- 但是需要注意,动态内存的申请到后边需要释放
- 释放之前要拿一个变量去存储 访问新链表的指针
代码如下:
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
// 对原链表进行判空
if(list1 == NULL)
{
return list2;
}
if(list2 == NULL)
{
return list1;
}
// 首先创建一个新链表
ListNode *newHead, *newTail;
// newHead = newTail = NULL;
// 给新链表动态申请一个节点的空间,但是不存储有效数据
// 这样后边就不用判断该链表是否为空链表
newHead = newTail = (ListNode*)malloc(sizeof(ListNode));
// 创建l1 和 l2 指针去访问两个链表
ListNode* l1 = list1;
ListNode* l2 = list2;
// 去分别遍历链表并比较 指向的节点存储的数据谁大谁小
while(l1 && l2) // 当l1或者l2 访问完毕链表就退出循环
{
if(l1->val < l2->val) // l1节点的数据 小于 l2节点的数据
{
newTail->next = l1; // 将l1尾插到 新链表中
newTail = newTail->next;// 及时更新新链表的尾节点
l1 = l1->next; // 让l1向后遍历
}
else
{
newTail->next = l2;
newTail = newTail->next;
l2 = l2->next;
}
}
// 退出循环代表着 l1 或者l2 已经遍历完链表了 已经是NULL了
//此时另外一个链表中还存在数据 要将这个剩下的数据全部尾插到我们的新链表当中
if(l2)
{
// l2 还有数据 但是我们不知道里面还有多少数据 用循环把l2全部数据尾插到我们的新链表
while(l2)
{
newTail->next = l2;
newTail = newTail->next;
l2 = l2->next;
}
}
if(l1)
{
while(l1)
{
newTail->next = l1;
newTail = newTail->next;
l1 = l1->next;
}
}
// 此时两个有序链表的数据 全部有序的放到了我们的新链表当中
ListNode* ret = newHead->next;
free(newHead);
newHead = NULL;
return ret; // 我们返回访问新链表头节点的指针
}
注意:
在我们优化的代码中,我们有给新链表一个不存储任何数据的节点
这种链表其实是链表分类当中的一种——带头链表
那么这个不存储任何数据的节点叫做头节点也叫哨兵位
其实之前我们说的链表的头节点 都是不太正确的说法,只是为了便于理解而已
1.4链表的中间节点
题目:
链接
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
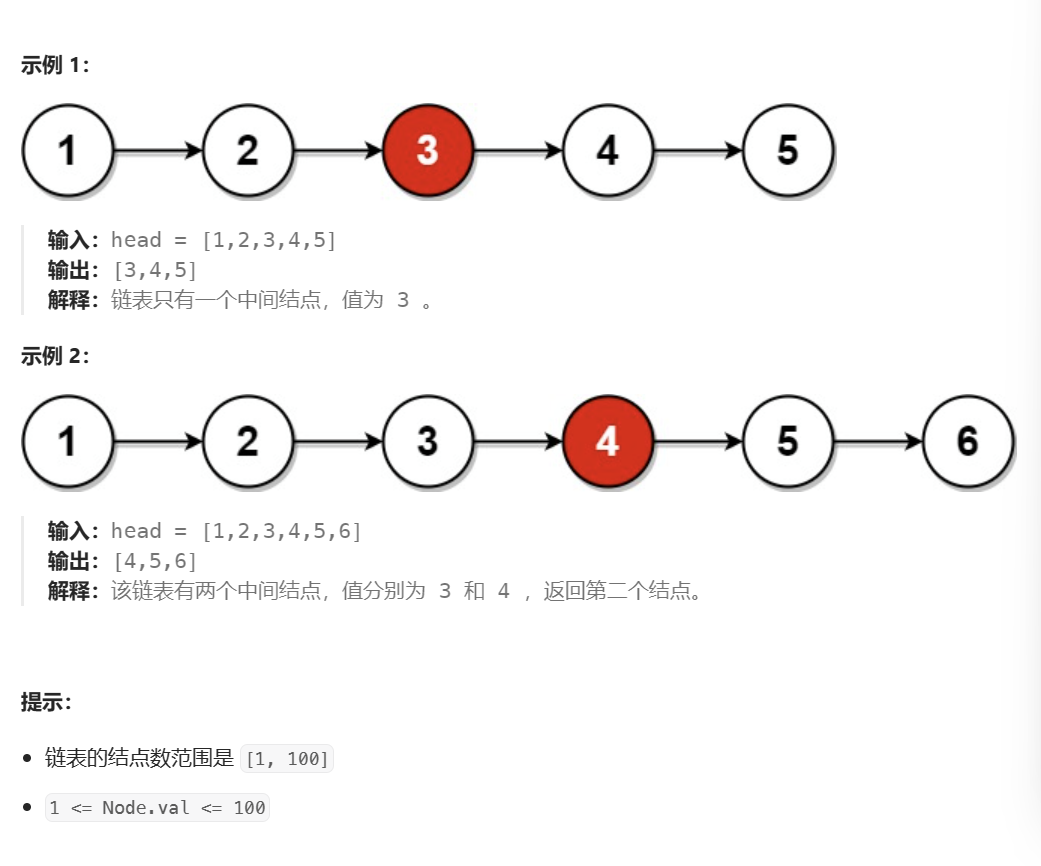
思路1:
- 遍历原链表 ,通过count来统计节点个数 , 最后返回第(count/2)的节点的next指针指向的节点—— 这个就是题目要求的中间节点
思路1的代码实现:
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
ListNode* pcur = head;
int count = 0;
// 遍历原链表统计 一共有多少个节点
while(pcur)
{
pcur = pcur->next;
count++;
}
// 找到中间节点
ListNode* midnode = NULL;
pcur = head;
for(int i = 0; i<count/2 + 1; i++)
{
midnode = pcur;
pcur = pcur->next;
}
// 找到中间节点之后就返回
return midnode;
}
由于使用了两次循环遍历 ,导致效率没有思路2高效
思路2:
快慢指针
我们分为奇数个节点的链表 和偶数个节点的两种情况
首先是奇数个节点 的链表
- 我们让slow和fast两个指针都指向头节点
- 然后slow指针往后走一步, fast指针往后走两步
- 由于是奇数个节点,当fast->next == NULL 的时候,fast就走到尾节点了
- 此时的slow指针指向的节点就是中间节点
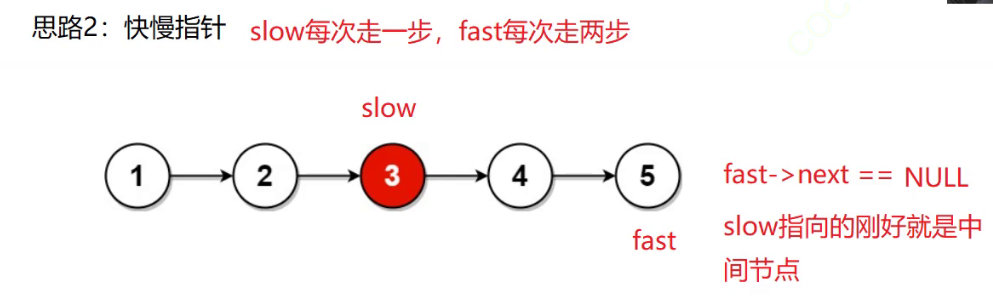
我们再来看偶数个节点的链表:
- 首先让slow和fast指针都指向头节点
- 也是让slow往后走一步,让fast往后走两步
- 当fast==NULL 的时候,
- 此时slow指针指向的节点就是中间节点
思路2的好处是,我们只需要通过一次循环就可以完成题目的要求
我们来看思路2的代码是如何实现的:
struct ListNode
{
int val;
struct ListNode *next;
};
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
// 创建快慢指针
ListNode* slow = head;
ListNode* fast = head;
// 开始遍历链表 让slow往后走一步, 让fast往后走两步 2slow = fast
while(fast && fast->next) // 注意fast和fast->next的顺序不能掉换
{
slow = slow->next; // 往后走一步
fast = fast->next->next; // 往后走两步
}
// 走到这里说明slow就是中间节点了
return slow;
}
注意:
为什么说fast和fast->next的顺序不能掉换?
我们知道fast指针在奇数个节点的链表和在偶数个节点的链表的中止条件是不一样的
我们放在一个表达式里面判断
但是实际上 如果是 偶数个节点的情况
fast = fast->next->next; 在最后一次循环的时候 会让其 fast = NULL
如果是while(fast->next && fast)的话
那么会先执行fast->next ,但是你对一个NULL进行解引用 就会报错!!!

1.5 环形链表的约瑟夫问题(有些难度)
这个是问题是循环链表的经典应用
题目:
想要解决这个问题, 那么我们就得知道循环列表是什么
其实就是让最后一个节点的指针next不指向NULL ,而是指向第一个节点
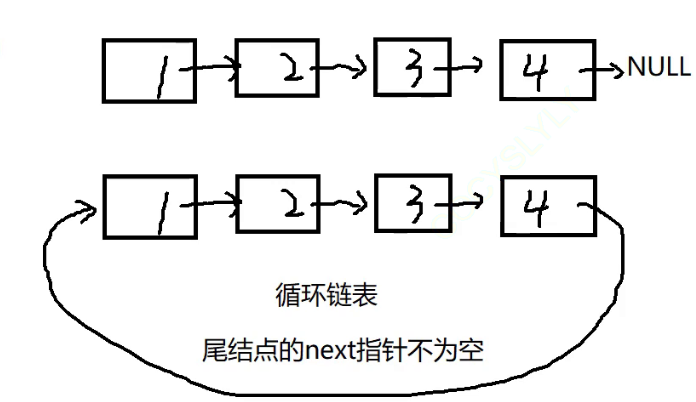
知道了循环链表的定义之后,我们来看看题目:
编号为 1 到 n 的 n 个人围成一圈。从编号为 1 的人开始报数,报到 m 的人离开。
下一个人继续从 1 开始报数。
n-1 轮结束以后,只剩下一个人,问最后留下的这个人编号是多少?
数据范围: 1≤𝑛,𝑚≤100001≤n,m≤10000
进阶:空间复杂度 𝑂(1)O(1),时间复杂度 𝑂(𝑛)O(n)
示例1:

示例2:

要想做题,首先得思考,要有思路。
思路:
- 首先根据输入的n值编写一个函数创建一个环形链表,n是节点的个数
- 既然要创建链表,就要创建节点,编写一个函数用来创建节点,创建节点的时候记得往节点存储数据
- 有了节点之后就是链接了,将n个节点,通过尾插,链接成环形链表
- 用ptail 和 phead两个指针完成这个链接,ptail指向最后一个节点,phead指向第一个节点,最后让ptail->next = phead;
- 返回ptail的值,让prev和pcur 分别指向ptail和 ptail->next 也就是phead
- 这个时候做一个while循环,循环内要根据输入的m去删除 第m个节点,
- 删除就是让prev指向pcur的下一个节点
- 删除完pcur这个节点要让 pcur往后走 pcur = pcur->next,
- 然后继续让pcur报数,报到m,再删除,循环到只剩下一个节点的时候
- 返回该节点的地址,此时pcur的next指针指向自己
来看代码是如何实现的:
struct ListNode
{
int val;
struct ListNode* next;
};
typedef struct ListNode ListNode;
ListNode* BuyNode(int x)
{
ListNode* node = (ListNode*)malloc(sizeof(ListNode));
if (node == NULL)
{
perror("malloc");
exit(1);
}
node->val = x;
node->next = NULL;
return node;
}
ListNode* CreateCircleList(int n)
{
// 创建n个节点
// 先创建第一个节点出来
ListNode* phead = BuyNode(1);
ListNode* ptail = phead;
// 通过for循环 去尾插剩下要插入的n-1个节点
for (int i = 2; i <= n; i++)
{
ListNode* node = BuyNode(i); // 创建节点
// 将节点尾插到链表当中
ptail->next = node;
ptail = ptail->next;
}
// 走到这里创建了一个n个节点的链表 但是还不是环形链表
// 让最后一个节点的next指针指向phead 也就是第一个节点
ptail->next = phead; // 链表成环
return ptail; // 返回最后一个节点才能找到第一个节点和第一个节点前面的节点
}
int ysf(int n, int m)
{
// 根据n创造一个环形链表,n个节点
ListNode* prev = CreateCircleList(n);
ListNode* pcur = prev->next; // pcur指向链表的第一个节点
// 这个时候开始约瑟夫删除节点 根据给的m来删除节点
while (pcur->next != pcur) // 当剩下一个节点的时候才能退出循环 也就是pcur的next指针指向自己的时候
{
// 遍历链表 当pcur往后走了m - 1步之后 删除pcur指向的节点
for (int i = 0; i < m - 1; i++)
{
prev = pcur; // prev是用来指向pcur的前一个节点的
pcur = pcur->next;
}
// 此时的pcur指向的节点 要进行删除
prev->next = pcur->next;// 让prev指向pcur的下一个节点
free(pcur); // 删除pcur指向的节点
pcur = prev->next; // 让pcur指向下一次要走m步的起点
}
// 这个时候就剩下一个节点 就是幸存者
ListNode* ret = pcur->val;
free(pcur); // 释放掉自己申请的动态内存空间
pcur = NULL;
return ret;
}
在删除节点的思路上 还可以有另外一个思路:
通过让count来储存 pcur向后走的此时 , 每走一次就count++
当count == m的时候就说明 pcur指向的节点是要删除的节点
// int ysf函数还可以有另外一个思路
int ysf(int n, int m)
{
// 根据n创造一个环形链表,n个节点
ListNode* prev = CreateCircleList(n);
ListNode* pcur = prev->next; // pcur指向链表的第一个节点
int count = 1;
// 这个时候开始约瑟夫删除节点 根据给的m来删除节点
while (pcur->next != pcur) //当剩下一个节点的时候才能退出循环 也就是pcur的next指针指向自己的时候
{
// 要让pcur向后走到count = m才行能删除pcur指向的节点
// 分为不删除节点的情况和不删除的情况
if (count == m) // 删除
{
// 删除pcur指向的节点
prev->next = pcur->next;
free(pcur);
pcur = prev->next;
count = 1; // 置为1
}
else // 不删除
{
// 此时不删除pcur 指向的节点
// 让pcur往后走就行
prev = pcur; // prev是用来指向pcur的前一个节点的
pcur = pcur->next;// pcur往后走
count++; // 让count统计此时pcur指向的的节点是否要删除
}
}
// 这个时候就剩下一个节点 就是幸存者
ListNode* ret = pcur->val;
free(pcur); // 释放掉自己申请的动态内存空间
pcur = NULL;
return ret;
}
这个思路的效率稍高,但基本没有什么区别。
1.6 分割列表(面试题,难度:中等)
题目:
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你不需要 保留 每个分区中各节点的初始相对位置。

思路1:
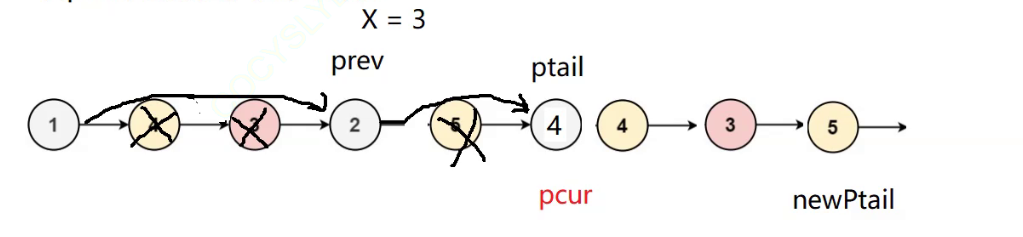
- 在原链表上修改
- 若pcur节点的值小于x,就往后走。
- 若pcur节点的值 大于或等于x,就尾插到原链表后,删除旧节点
- 删除就是让prev的next指针指向pcur的下一个节点,删除pcur指向的节点,再让pcur = prev-》next 让pcur指向下一个节点
- 当pcur走到ptail也就是原链表的最后一个节点的时候,不再需要去判断其节点的数据是否大于小于x 。 因为此时刚好是分界点
思路2:
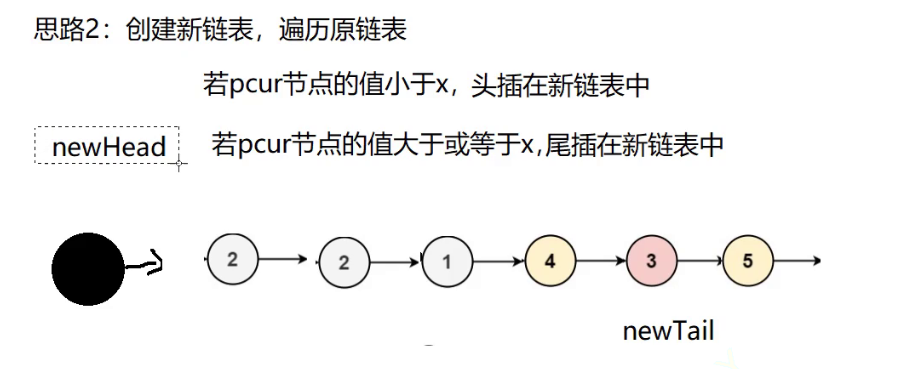
创建一个新链表,将节点的值小于x的都放到新链表的左边,大于x的都放到新链表的右边
- 创建一个新链表,并给与它一个哨兵位(头节点)
- 让一个指针去遍历原链表,如果节点的值小于x就头插, 如果节点的值大于x就尾插
- 注意了,如果新链表是空的,那就不用判断节点的值,直接拿下来头插到哨兵位的后边。
思路3:
创建两个新链表:小链表和大链表
- 首先创建两个链表,一个大链表,一个小链表
- 然后给两个新链表各一个哨兵位(头节点)[这样可以避免重复的判断新链表是否为空]
- 如果pcur指向节点的值小于x就尾插到小链表中
- 如果pcur指向节点的值大于x 就尾插到大链表中
- 将小链表的尾节点和大链表的第一个有效节点首尾相连
- 这样就是一个链表了

我们来看思路3的代码实现:
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x)
{
// 创建两个链表 一个大链表 一个小链表
ListNode* lessHead,* lessTail;
ListNode* greaterHead,* greaterTail;
// 给两个链表一个哨兵位(头节点)
lessHead = lessTail = (ListNode*)malloc(sizeof(ListNode));
greaterHead = greaterTail = (ListNode*)malloc(sizeof(ListNode));
ListNode* pcur = head;
// 遍历原链表, 判断节点该放到小链表还是大链表
while(pcur)
{
// 判断pcur指向的节点的值和x的关系
if(pcur->val >= x)
{
// 放到大链表当中
greaterTail->next = pcur;
greaterTail = greaterTail->next;
}
else
{
lessTail->next = pcur;
lessTail = lessTail->next;
}
pcur = pcur->next;
}
// 此时已经将所有的节点分配完毕
greaterTail->next = NULL; // 注意要让大链表的最后一个节点的next指针指向NULL 不然会导致链表成环 陷入死循环
// 并且当大链表没有插入节点的时候 还可以对哨兵位的next指针初始化 因为此时的greaterTail 指向的就是哨兵位
// 这个时候要让大小链表相连 就是让小链表的尾节点指向大链表的第一个节点
lessTail->next = greaterHead->next;
// 完成了大小链表相连之后 我们就可以返回 访问链表的指针了
ListNode* ret = lessHead->next; // lessHead 是哨兵位
free(lessHead);
free(greaterHead);
lessHead = greaterHead = NULL;
return ret;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









