







目录
MySQL数据库基础(重要)
1.1什么是数据库
对于数据库,我们应该先了解几个知识。
- mysql指的是数据库服务的客户端
- mysqld指的是数据库服务的服务器端
- mysql是基于C(mysql)S(mysqld)模式的一种网络服务。
- mysql是一套给我提供数据存取服务的网络程序
- 我们口语上讲的数据库一般指的是:在磁盘或者在内存中存储的有特定结构组织的数据,讲得简单一点就是,在磁盘上存储的一套数据库方案,数据将会以这个数据库方案的方式去存储
- 口语上讲的数据库服务一般指——mysqld
- 数据库的存储介质是——磁盘或者内存
但是可能有个疑问,存储数据不是用文件就行了吗,并且现在的电脑确实也是这样做的,都是用文件来存储数据。
但是文件来存储数据会有以下几个缺点:
- 文件的安全性不够强
- 文件不利于数据的查询和管理
- 文件不利于存储海量数据
- 文件在程序中的控制是相对麻烦的
这样说可能不是很好理解,我来举个例子:
我们知道文件能存储数据,但是文件是不提供很好的管理数据的能力的。
比如一个文件里面存储着几百万个ip地址,有一次我们需要找出以xxx为开头的ip地址,这个时候手动找肯定不现实,因此这个要求就落在了程序员的头上,程序员需要去编写代码,利用语言去提取数据。但是如果每次类似的对数据内容进行管理的需求都由程序员手动解决的话,也是很麻烦的。
因此数据库的存在就非常有必要了。
数据库的本质:对数据内容存储的一套解决的方案。
比如:和数据库提要求,数据库直接把结果给你,不需要再手动编写代码去对数据进行管理。
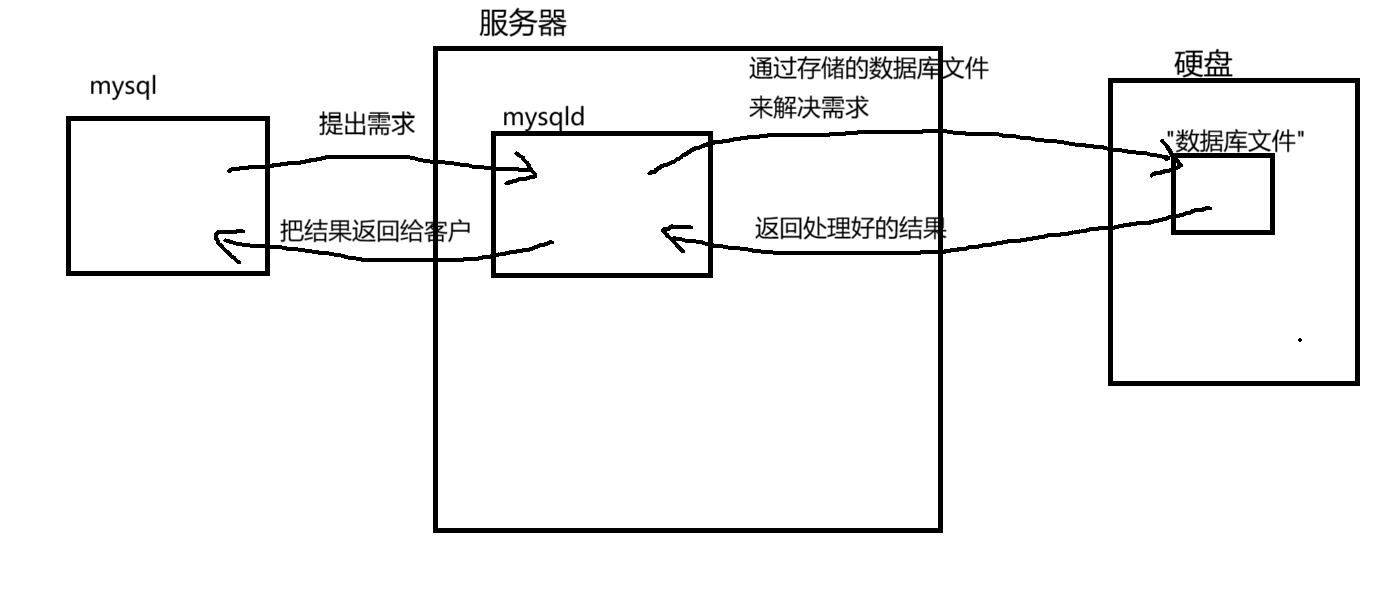
而这个过程往往是,客户通过mysql(数据库客户端)提出需求,mysqld(数据库服务器端)接收到需求之后,用它的一套解决方案,对数据进行处理和分析,再将结果返回给客户
流程如下图所示:
1.2主流数据库
下面这些数据库都是关系型数据库。还有一类数据库NoSQL(Not Only SQL),它是一类范围非常广泛的持久化解决方案。
-
SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
-
Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
-
MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
-
PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。
-
SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
-
H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中
现在的存储都是以MySQL为主,其他的NoSQL为辅,来搭建后端的一套存储服务的。
1.3连接服务器
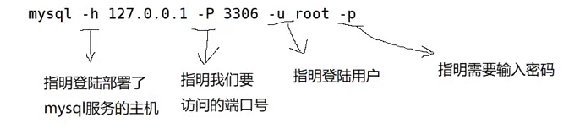
下面这个语句是在linux环境下登录mysql的一条语句
mysql -h 127.0.0.1 -P 3306 -u root -p
这里的每个选项的意思我们来看一下:
注意:
-
如果没有写 -h 127.0.0.1 默认是连接本地
-
如果没有写 -P 3306 默认是连接3306端口号
-
并且输入密码的时候,是不会显示的。
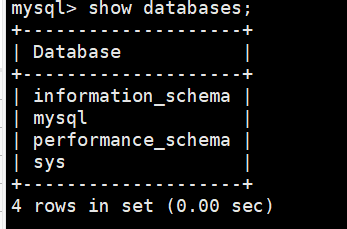
连接服务器后输入
mysql> show databases;
会显示当前数据库下的数据
1.4使用案例
使用mysql建立一个数据库,并创建一个表,并插入一些数据
输入:
create database wzf;
就会创建一个名叫wzf的数据库
并且我们可以打开etc/my.cnf这个配置文件
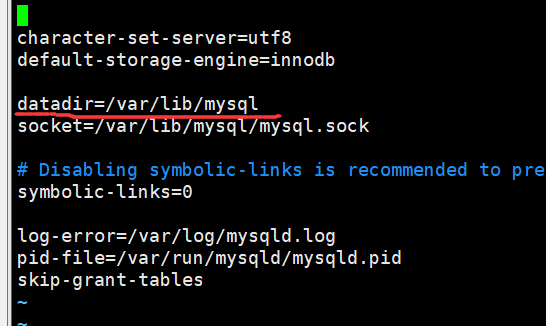
在这个文件当中说明了数据是存放在/var/lib/mysql这个路径下的
因此进入cd /var/lib/mysql的目录下去查看我们创建的数据库是否创建成功
/var/lib/mysql这个目录就是存储数据库的目录
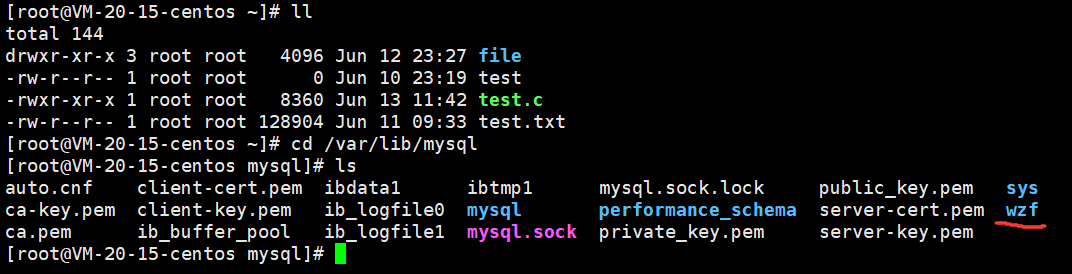
我们看到多了一个目录为wzf

并且这个目录基本什么都没有,有一个mysqld帮我们写好的基础的配置文件
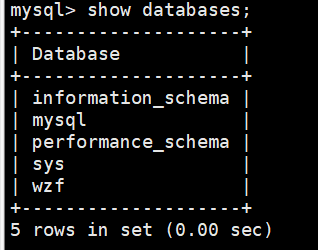
我们回到mysql当中来,我们可以查看数据库,看看wzf数据库是否被创建了
输入:
show databases;
即可查看
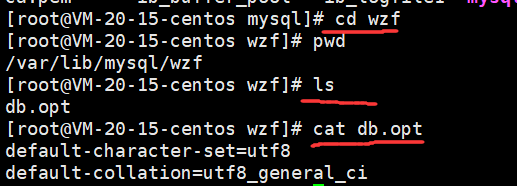
因此,这告诉我们,创建一个数据库,在linux下本质就是创建了一个目录
创建完数据库之后我们就要建表并插入数据
建表之前我们要选择一个数据库去建立。
use wzf
使用wzf这个数据库
然后我们创建一个数据库表
create table Person(
name varchar(32),
age int,
gender varchar(32)
);
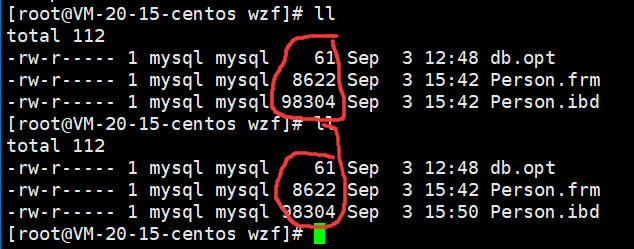
创建了之后,
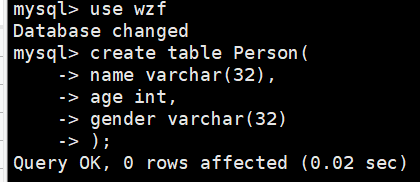
/var/lib/mysql/wzf这个目录就会出现变化,我们发现多了两个文件

因此在数据库内建表,本质就是在linux下在对应目录内创建对应的文件
那我们如何插入数据呢
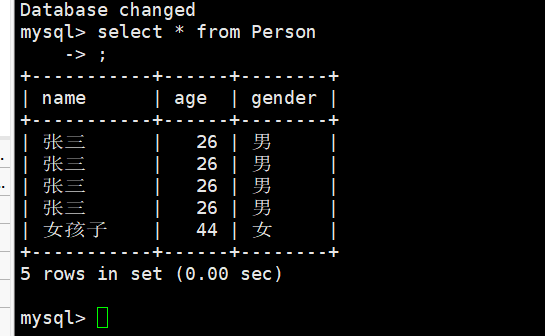
insert into Person(name, age, gender) values('张三', 26, '男');
要注意,name,age,gender要对应好所插入的数据顺序。
插入完数据之后,我们可以查阅表格
select * from Person;
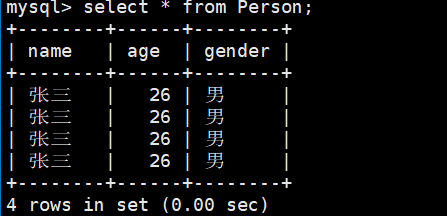
有一个注意的地方,插入数据之后,wzf这个目录的大小不一定会变化,因为mysqld有它自己的优化的一些方法。
总结:
在这个使用案例下,我们可以知道:
- 建立数据库,本质上就是在linux下建立了一个目录
- 创建一个表,本质上就是在你创建的目录(数据库)下,创建了对应的文件。
- 数据库本身也是文件。程序员不在需要对数据库本身这个文件进行处理,而是提出需求(如插入数据,创建表格等)。由mysqld(数据库服务)帮程序员完成需求的操作
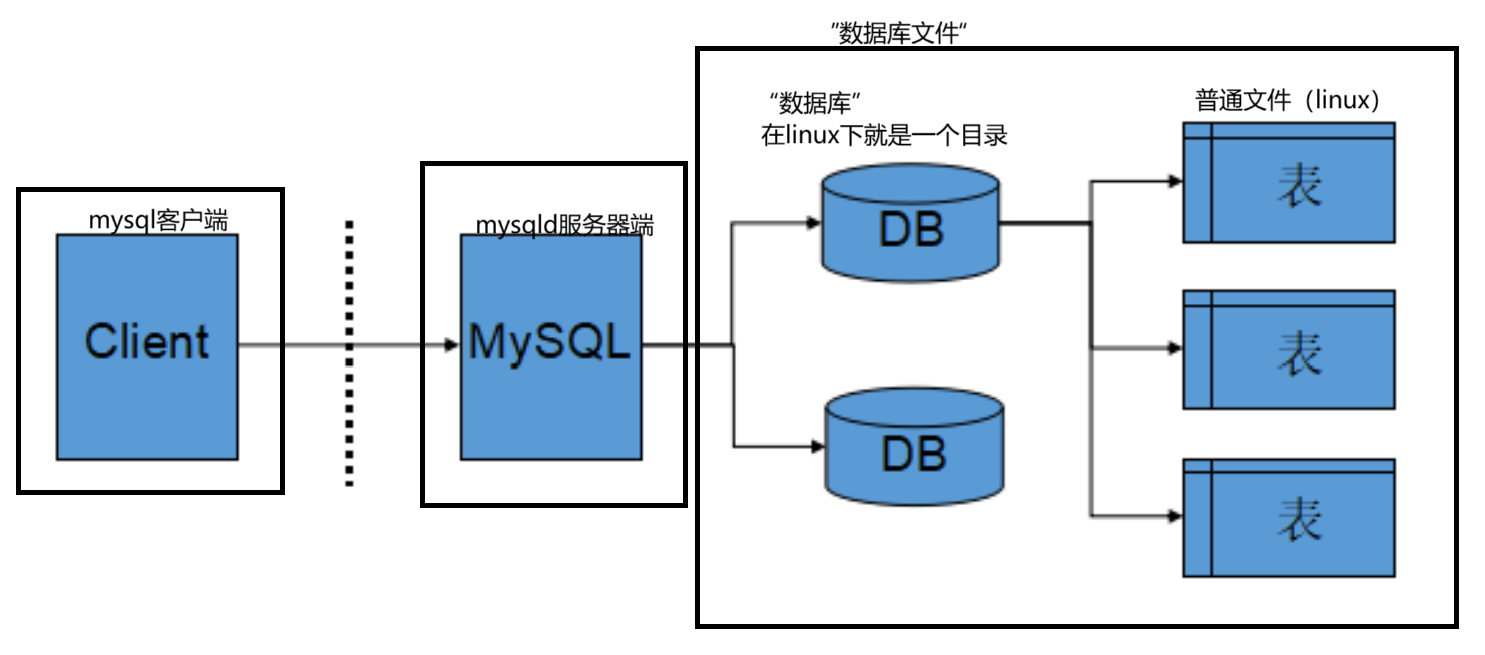
1.5服务器-数据库-表之间的关系
- 所谓安装数据库服务器(mysqld),其实就是在机器上安装了一个数据库管理系统文件(在后台一直运行),这个管理程序可以管理多个数据库、
- 一般开发人员都是针对一个应用创建一个数据库
- 为了保存应用中的数据,一个数据库内一般会创建非常多的表
- 服务器与数据库与表之间的关系如下图所示:
1.6数据逻辑存储
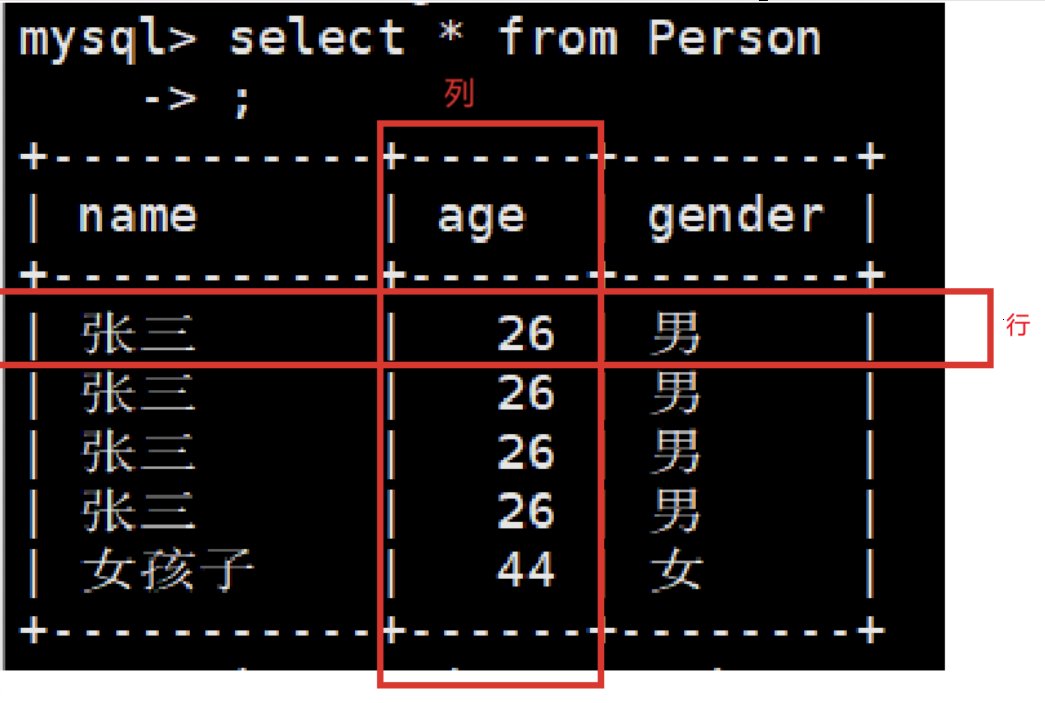
在mysql中,我们存储的数据会以逻辑存储的形式存在硬盘当中。
就像我们将数据存储在表结构,表就是一个行列式结构。
数据将会以行和列的逻辑存储,我们拿Person这个表举例,数据库会将数据以行的形式进行插入,行代表着这个人,列代表着对应的信息。
1.7MySQL架构
mysql是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
注意了:
- mysql最主流的应用方式就是在网络服务器的后端去运行。也就是linux和类linux的环境下去跑的
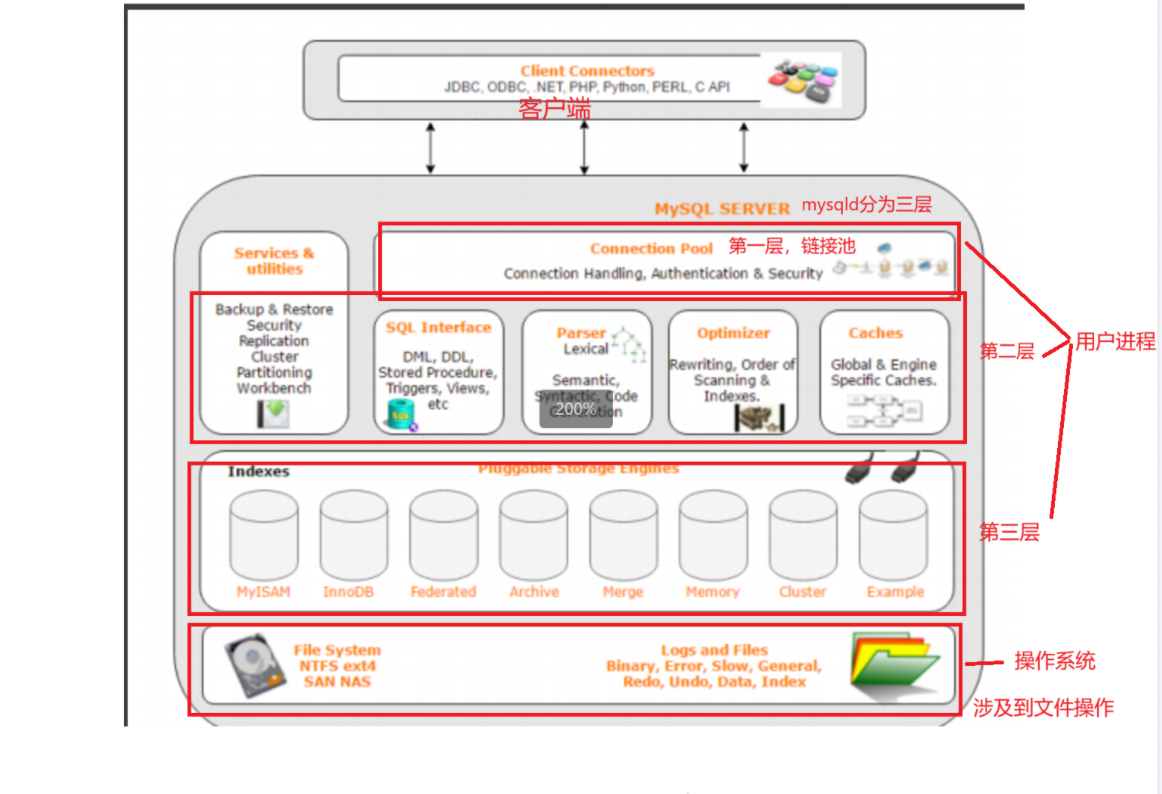
下面这张照片是mysql的架构图:
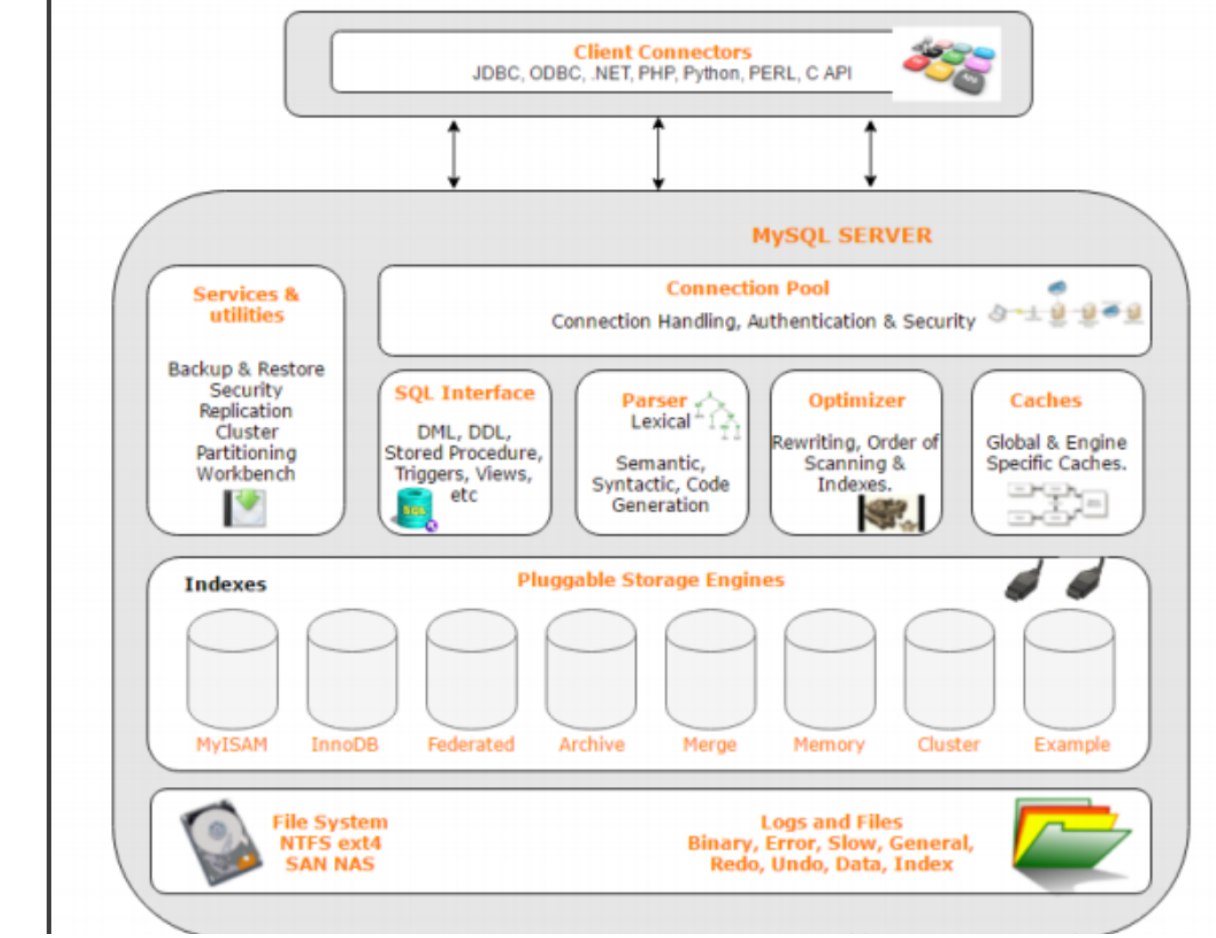
我们对上面的架构进行分析:
首先就是客户端(Client Connectors)
目前我们使用的客户端是命令行式的,我们下达指令和需求都是在这个界面上。
也就是这个
但是以后我们还可以使用c++语言可以连接mysql,从而充当客户端。
还有一种方式就是使用mysql的图形化界面去充当客户端
客户端之后就是服务端,整个服务端分为三层
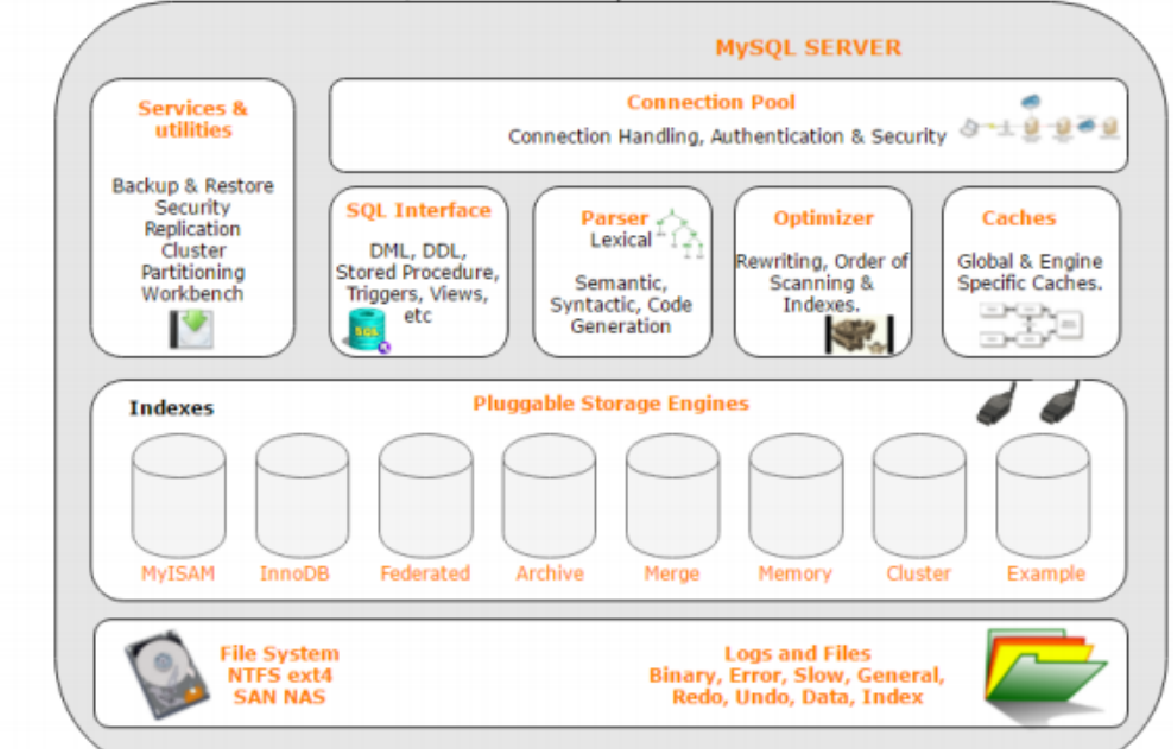
第一层是链接池(Connection Pool)
这个链接池做的事情有
- 连接管理
- 建立权限——鉴别用户的身份权限是否足够。
- 保证安全性的一些策略
第二层是中间那层
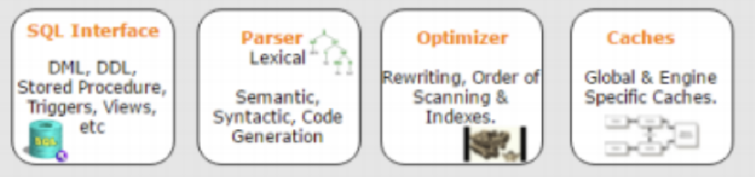
这一层的作用主要是对下达的语句和指令进行词法分析和语法分析,并做一定的优化。将处理后的语句和指令下达给下一层
这个过程类似于c/c++的编译过程
第三层就是存储引擎(支持热插拔)
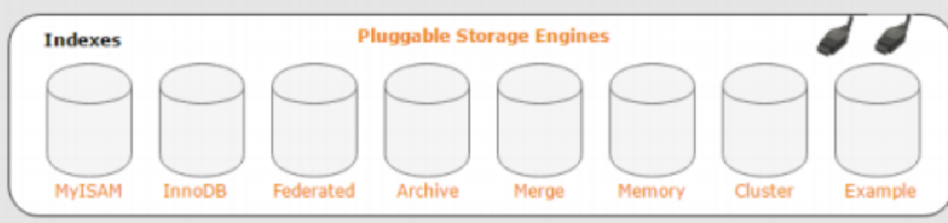
支持热插拔就是想要用某个存储引擎的时候可以单独选用它,不想用了也可以不用。
前面我们说了,第二层—中间层会将用户下达的语句或指令处理之后下达给第三层,那么下达下来的指令就会交给最适合的存储引擎来做。其实这第三层才是真正办事的,存储引擎接受指令之后就会开始根据指令去对存储的数据进行增删查改之类的工作。
那为什么会有这么多的存储引擎呢?
因为数据有非常多的种类,不同种类的数据,同一个引擎处理起来肯定有效率的区别。因此,针对各个种类的引擎,mysql提供了各种各样的存储引擎。支持对不同数据的存储都自动匹配到最适合的存储引擎,这样存储各式各样的数据都可以做到不错的效率。
比如MyISAM引擎——它比较适合大文本的读取。
InnoDB引擎——具有丰富的索引支持,方便进行快速的搜索查找
还有最后一个板块没有讲到

这个板块负责最后一步的任务——把数据以二进制的方式存储在特定的目录或者文件当中
拓展:
从两个视角来看待这个图片
- 从操作系统的视角来看待这个图片的话
整个MySQL Server共三层都是用户进程,最后一个部分涉及到文件的操作,是操作系统
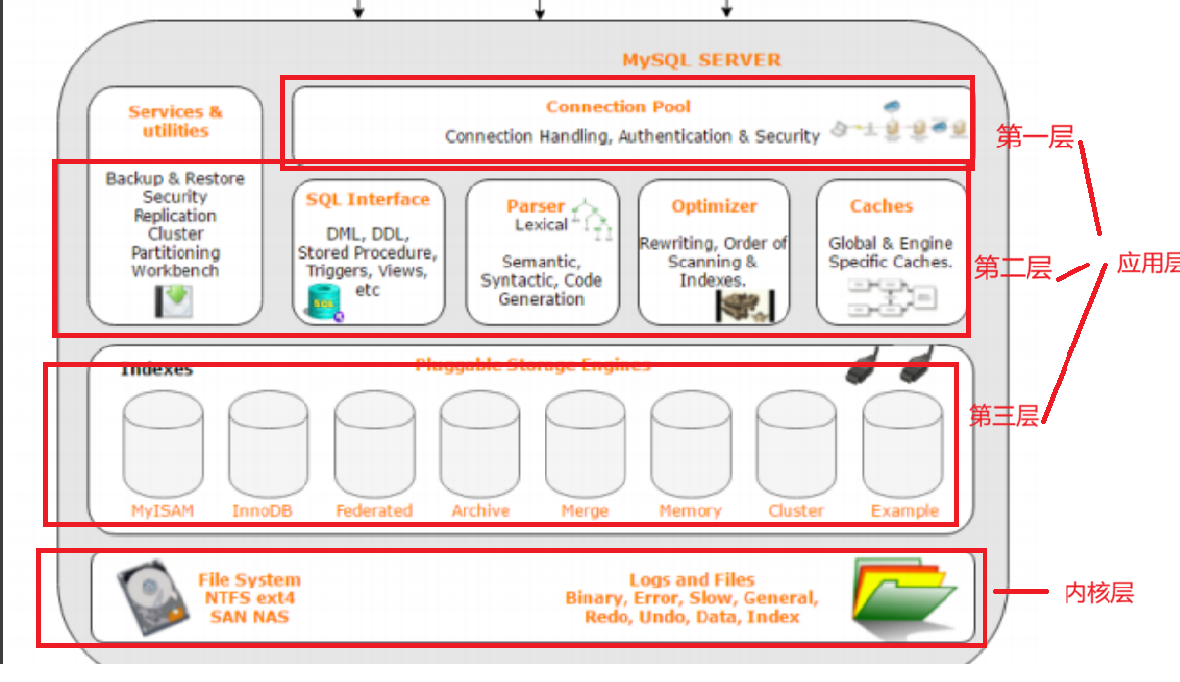
- 从网络的视角来看的话
整个MySQL Server共三层都是应用层,最后一个部分涉及到文件的操作,是内核层
1.8SQL语句分类
宏观上SQL语句分为三种:
- DDL【data definition language】 数据定义语言,用来维护存储数据的结构
比如我们想存储数据,存储数据之前要建个数据库,再建个表,这个定义这个表的语句就是DDL。
比如:create,drop, alter
- DML【data manipulation language】 数据操纵语言,用来对数据进行操作
比如我们往表中插入一个数据或者删除一个数据,用的语句就是DML。
很简单,就是修改数据的语句就是DML。
比如:insert,delete,update
- DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务
它不负责数据库中数据的修改,也不负责处理数据库,主要负责建权和用户管理相关的内容
比如: grant,revoke,commit
1.9存储引擎
存储引擎:是数据库管理系统如何管理数据,如何查询和修改数据,如何为存储的数据建立索引等技术的实现方法
MySQL的核心就是插件式存储引擎,支持多种存储引擎
在mysql中我们也是可以查看存储引擎的:
输入:
show engines;
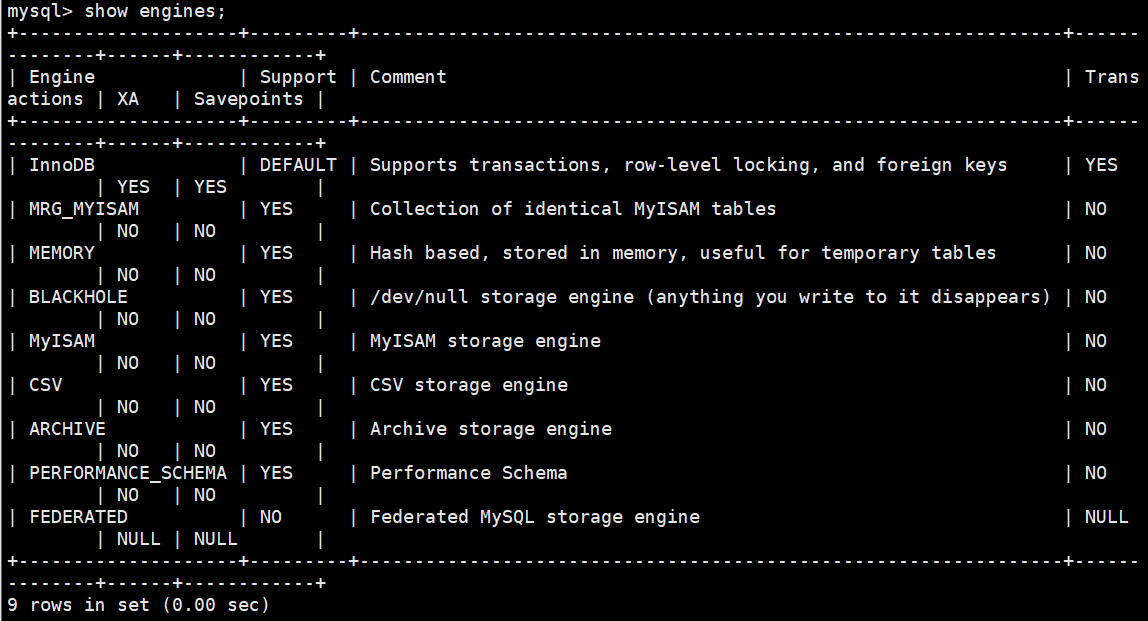
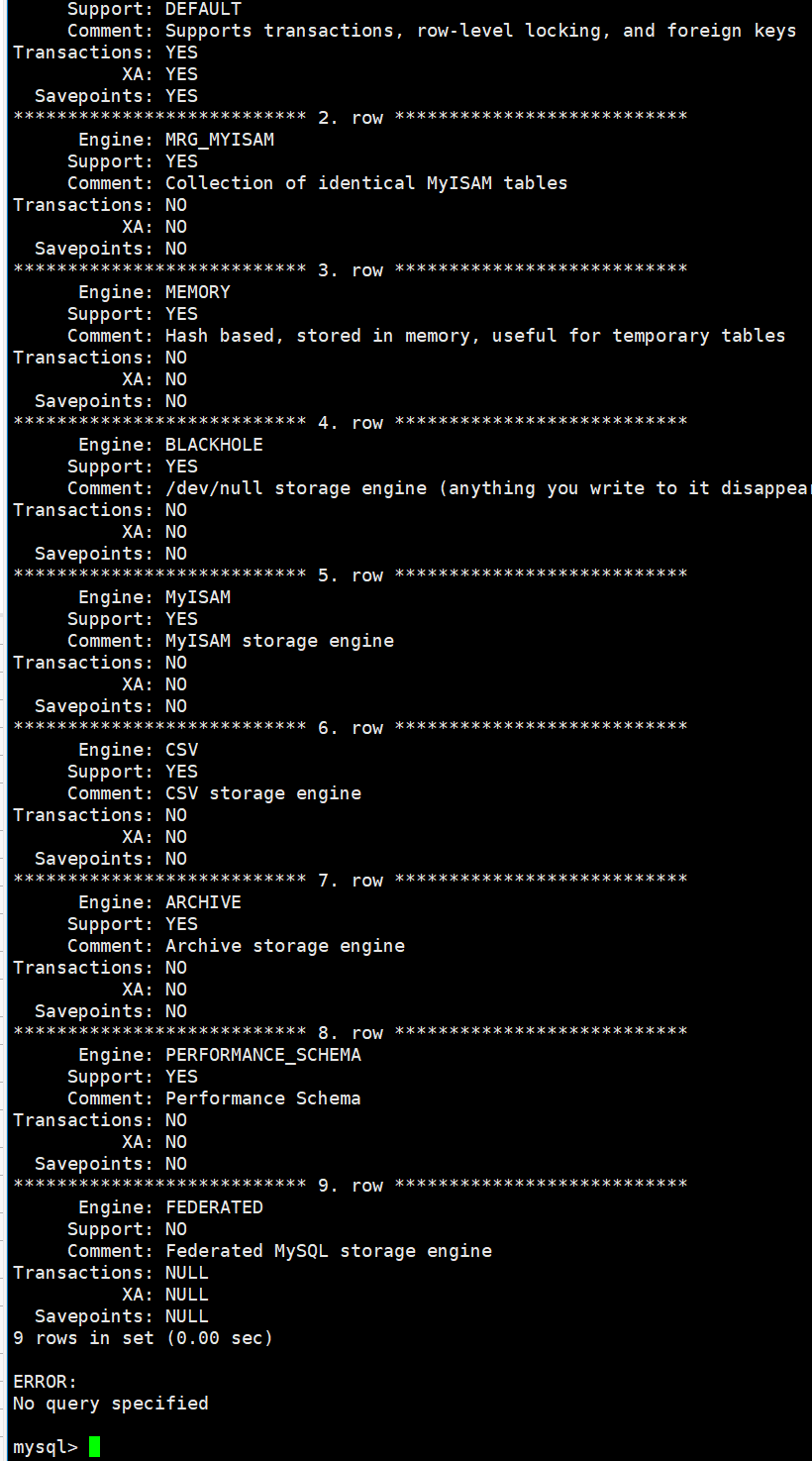
输入:
show engines \G;
可以换一种表达方式
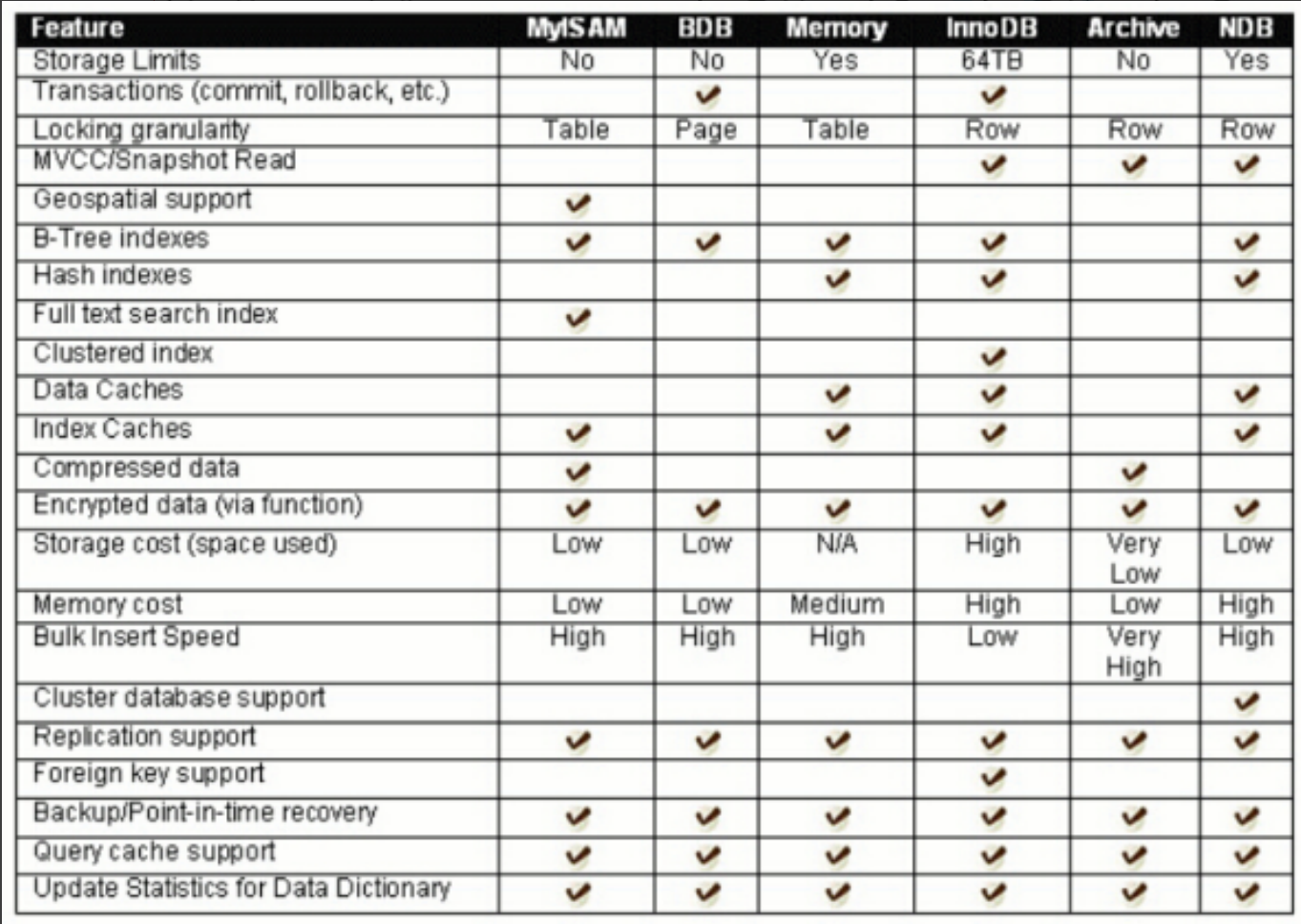
虽然这里的存储引擎很多,但是最常用的就是InnoDB和MyISAM。
下面这个表可能可以看得更清晰















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









