







 本文详细介绍了正则表达式的各种匹配规则,包括单字符、任意字符、一组字符、取非、元字符、数字匹配、字母数字匹配、空白字符、重复匹配、边界匹配、子表达式、回溯引用、替换操作以及向前和向后查找等。旨在帮助读者理解和掌握正则表达式的高效使用。
本文详细介绍了正则表达式的各种匹配规则,包括单字符、任意字符、一组字符、取非、元字符、数字匹配、字母数字匹配、空白字符、重复匹配、边界匹配、子表达式、回溯引用、替换操作以及向前和向后查找等。旨在帮助读者理解和掌握正则表达式的高效使用。
前言
在工作中使用正则表达式可以提高我们的效率,这篇博客就是一篇字典类型的博客,需要的时候回来看即可。但我尽量避免死记硬背。(学习书籍----《正则表达式必知必会》)
匹配单个字符
如果匹配单个字符的话,直接输入要查找的内容即可:
匹配字符“hello”,直接搜索即可:

匹配任意字符
匹配任意字符可使用符号“.”,它可以代替任何一个符号。
匹配字符“hello”,前后使用“.”来代替:

匹配一组字符
匹配一组字符可以使用“[]”,它的含义是只要这一个字符在这个中括号当中,就可以被匹配到。
匹配a到d的text,如下操作:

也可以直接输入[a-d] 表示a到d之前的任意一个符号都可以被匹配到

数字也可以使用区间符号“-”进行匹配,如下匹配带有字母和数字的两个字的文本:

一个集合里可以支持多个区间,如下匹配a到f或者1到3的一个字的文本:

取非匹配
如果我们想避免匹配到某些字符,可以使用符号“^”,表示不匹配这些区间里的任意一个字符,注意:这个符号只有在区间里表示取非。
匹配纯字母的文本,忽略掉数字:

元字符
元字符的概念是无法用它本身来表示它本身,需要进行转义,因为它是用来描述其他正则规则的,如果要想匹配元字符,就需要特殊处理。
比如上面的区间符号[],如果要想直接匹配是行不通的,如下并没有匹配成功:

针对匹配元字符的场景,需要使用转义符“\”。
如下操作即可匹配成功:

同理,“\”本身也是元字符,匹配的时候也需要使用“\”转义

匹配数字
\d表示匹配所有数字(digit)
\D表示匹配所有非数字,在正则中,小写对应的大写都是取非的意思。
匹配所有数字:

匹配所有非数字

匹配所有字母和数字
\w 匹配所有字母+数字(word)
\W 匹配所有非字母+数字
匹配所有字母+数字:

匹配所有非字母+数字

匹配空白字符
\s 表示匹配所有空白符号 (space)
\S 表示匹配所有非空白符号
匹配所有空白字符:

匹配所有非空白字符:

重复匹配
“+” 表示匹配一个或者多个字符(至少一个)
匹配my后面加上任意几个数字的文本:

“+”表示至少匹配一个
“*”表示匹配0个或多个,类似sql 中的select * … 意味着也可以没有
匹配my后面加上任意几个数字(也可以没有数字)的文本:
 “?”表示匹配0个或1个字符,最多出现一次
“?”表示匹配0个或1个字符,最多出现一次
匹配my后面加上1个数字(也可以没有数字)的文本:

"{}“可以给重复匹配设立一个精确的值,想要匹配几次,“{}”里填入对应的数字即可。
匹配数字出现3次的文本:

除了上面使用的方法外,”{}"还可以设立一个区间,比如“{2,4}” 表示出现至少2次,最多3次。
匹配数字出现至少1次,最多3次的文本:
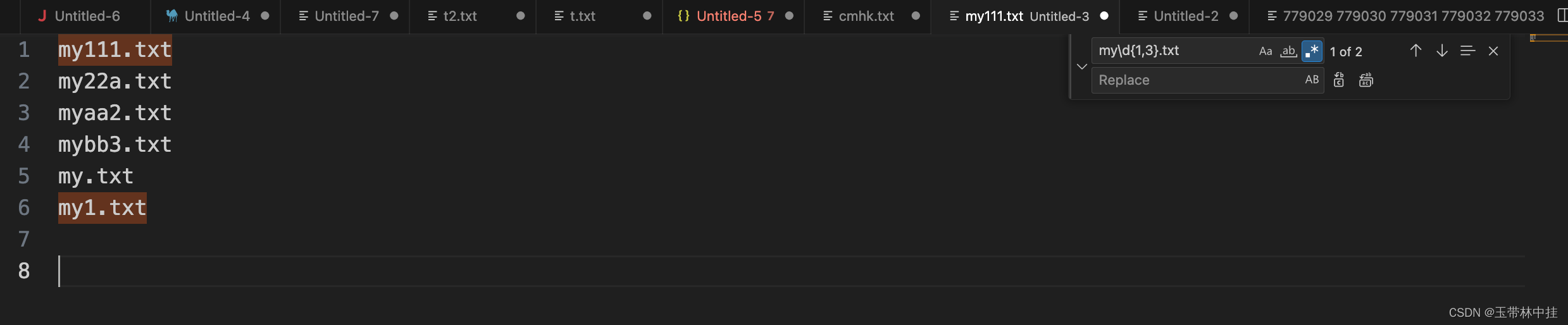
除此之外,“{}” 还可以匹配至少出现几次,“{2,}” 表示至少出现几次,但最多没有上限(但是反过来不会生效,即匹配最多次,不需匹配最少次)。
匹配数字出现至少2次,最多N次的文本:

避免过度匹配
“*” 符号可以匹配多个,但有时会出现过度匹配的情况,如下,我想匹配所有的txt文本,但是会从头匹配到尾,会包含中间的空格

出现上述原因是因为开头是my, 结尾是txt,所以就都会匹配上。
解决方法可以使用“ *?” ,在“ * ” 后面加一个“?”,表示避免匹配过度,该含义是 只会匹配每一个以my开头,txt结尾的文本。

“ * ” 表示贪婪匹配,“ *?” 表示懒惰型匹配,常用的几个贪婪型匹配和对应的懒惰型匹配如下:
| 贪婪型 | 懒惰型 |
|---|---|
| * | *? |
| + | +? |
| {n,} | {n,}? |
边界匹配
“\b” 可以匹配单词的边界 (border)它可以独立出一个单词
我想匹配如下文本中的所有cat 单词,如果直接匹配的话,效果如下:

不符合我的预期,会匹配其他包含cat字母的单词;可以加上 \b ,表示对要搜索的单词加上一个边界:

相反,“\B”可以去除单词的边界

字符串边界
“^”表示匹配字符串的开头
“$”表示匹配字符串的结尾
匹配所有以a开头d结尾的文本行:

子表达式
“()”表示子表达式,它可以实现复用,将“()”里面的的内容抽出来,作为独立的元素来使用。
匹配下面的ip:

这个解释下:
(\d{1,3}.) 把1到3位的数字加上一个.作为一个子表达式
{3} 表示前面的子表达式连续出现了3次,也就是ip地址的前3组数字
\d{1,3}表示匹配ip的最后一组数字
再举一个例子,找出所有19世纪和20世纪的出生人的年份:

(19|20)表示19或者20开头,把它作为一个子表达式
\d{2}表示后面跟随2位数字
回溯引用
回溯引用的概念是模式的后半部父引用在前半部分中定义的子表达式。
找出单词连续出现两次的文本:

[ ]+(\w+)[ ]+ 表示匹配空格+多个字符+空格 中间的多个字符是一个子表达式
\1 表示再续上一个和前面第1个子表达式一模一样的内容
再举一个例子
如下匹配所有对应html内容:

(<[h]\d>)是一个子表达式,匹配开头
.*匹配所有中间内容
\1 表示前面的第1个子表达式的内容在这里再出现一次。
这样就会过滤掉最后一个标签,因为它开头是H3,结尾是H2,不符合预期。
\1 就表示前面的第1个子表达式,\n就表示前面的第n个子表达式
回溯引用中的替换操作
回溯引用不仅可以用来搜索,还可以用来替换。需要两个正则表达式,一个用来搜索,一个用来替换之前的文本,第一个模式里的子表达式可以在第二个模式里使用。
将所有电话的开头加上括号:

结果:

当匹配出来之后,用“$n” 来表示第一个模式中的第n个子表达式。
向前查找
有些时候,被匹配的单词并不是我们想要的,我们只是拿它作为一个边界,但搜索出来的内容不应该包含它。
向前查找实际上是一个子表达式,是以“?=”开头的,需要匹配的文本跟在“=”的后面。
匹配http 或https,但是不包括后面的“:”

.* 表示匹配开头
(?=:)是向前查找,查找到“:”即可,但是不包含“:”,只是“:”之前的即可,所以叫向前查找。
向后查找
?<=
向后查找相对于向前查找来说增加了一个“<”,含义为查找小于“=”后面的内容,即向后查找。

感谢您的观看,欢迎一起探讨。

















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









