







原文:"If you are a student interested in building the next generation of AI systems, don't work on LLMs"
链接:https://x.com/ylecun/status/179
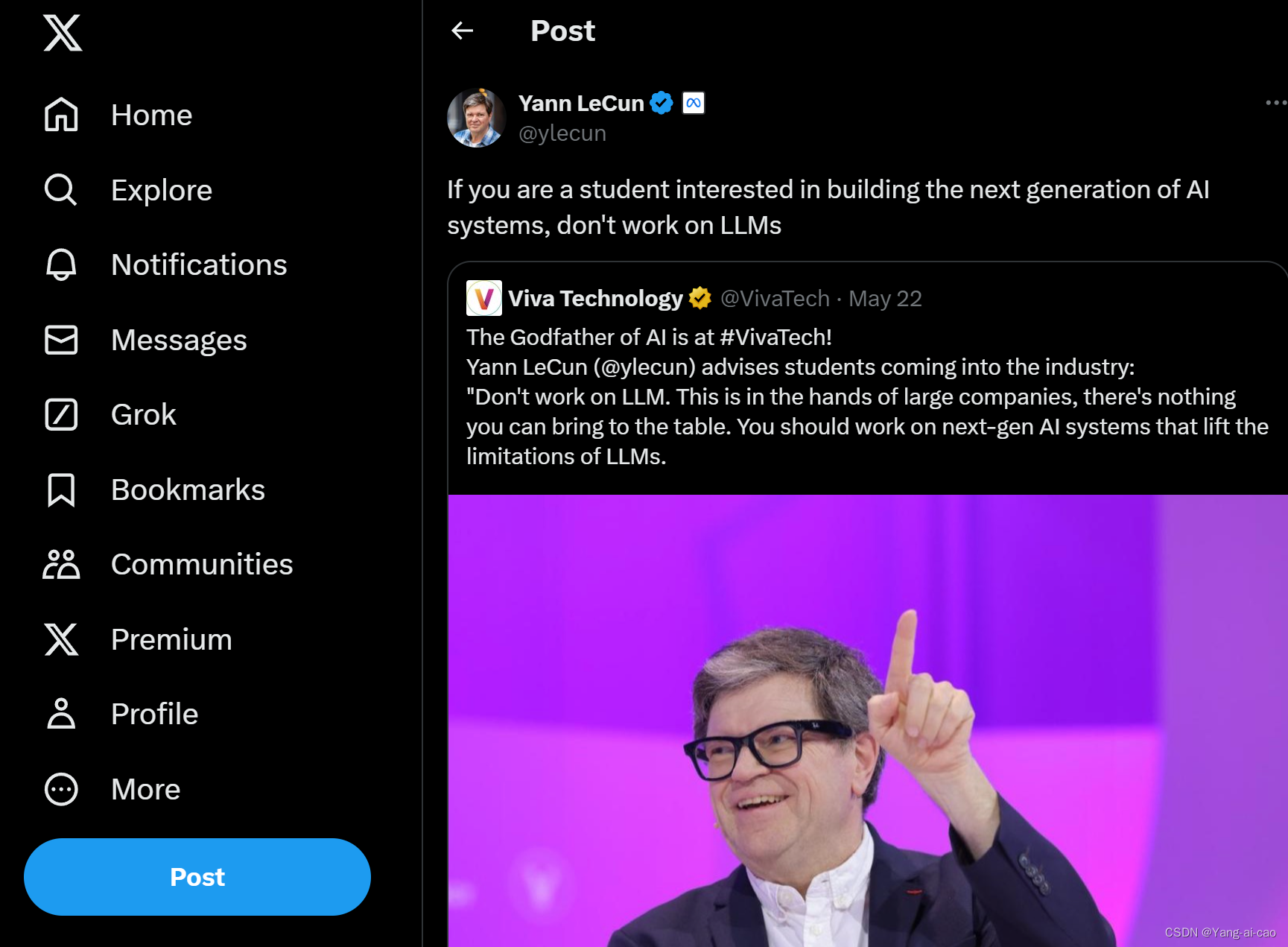
当前,LLM(大型语言模型)方向的研究主要有两种模式:一是通过调用API进行实验,使用少量数据,尽管需要自费购买tokens,但由于OpenAI的费用已降低,这部分成本尚可承受;二是调用开源模型,通常大小在7B左右,目前主流模型从llama2切换到llama3 8b,并在此基础上进行微调和改进,这需要一定的显卡资源。尽管lora、qlora等微调技术对显卡要求不高,但成本依然存在,许多实验室甚至无法负担一块4090显卡。此外,RAG(检索增强生成)方向的研究在2023年还集中于修改检索部分,将大模型视为黑盒,而今年则开始注重微调,缺乏实力的研究者难以发表论文。即便单次微调成本可接受,但代码问题会导致时间和资源浪费。因此,在学校中研究大模型并不是一个好的方向。
从企业需求来看,微调技术发展迅速ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









