







 本文介绍如何利用Python结合requests、bs4和Pandas库,从TripAdvisor抓取酒店评论。通过分析页面HTML结构,提取酒店ID,利用GraphQL端点获取评论数据,并生成CSV文件,为机器学习分析做准备。
本文介绍如何利用Python结合requests、bs4和Pandas库,从TripAdvisor抓取酒店评论。通过分析页面HTML结构,提取酒店ID,利用GraphQL端点获取评论数据,并生成CSV文件,为机器学习分析做准备。
我从TripAdvisor抓取一些酒店评论,然后发现了一种从它们那里刮掉数十万条酒店评论的好方法。
让我们假设,例如,我们要从大加那利岛刮掉酒店评论。如果转到TripAdvisor,我们将看到URL为:
https://www.tripadvisor.com/Hotels-g187471-Gran_Canaria_Canary_Islands-Hotels.html
复制
首先,我们需要从该位置检索酒店的完整列表。为此,我们将使用下载完整的HTML requests.get(url),然后尝试从HTML中获取此值:

如果我们仔细查看页面HTML,我们将看到此值在此<span>标记内:
由于该范围没有任何标识符,并且该类似乎是自动生成的,因此我们将在.MOBILE_SORT_FILTER_BUTTONS旁边的div中选择范围。就像是:
.MOBILE_SORT_FILTER_BUTTONS + div span
复制
首先,我们将需要PIP的产品requests和bs4包装。我们还将安装Pandas,以快速生成Excel并在以后使用DataFrame。
$ pip install requests bs4 pandas
复制
获取页数
安装库之后,我们可以编写以下代码来获取页数:
import requests
from bs4 import BeautifulSoup
import math, time
BASE_URL = 'https://www.tripadvisor.com/Hotels-g187471-Gran_Canaria_Canary_Islands-Hotels.html'
PER_PAGE = 30
response = requests.get(BASE_URL).text
soup = BeautifulSoup(response)
span = soup.select('.MOBILE_SORT_FILTER_BUTTONS + div span')[0]
N_PROPERTIES = int(re.sub('([^0-9\.])', '', span.text))
print(f'There are {N_PROPERTIES} properties')
N_PAGES = math.ceil(N_PROPERTIES / PER_PAGE)
print(f'There are {N_PAGES} different pages')
如果导航到页面2,我们将看到URL更改为:
https://www.tripadvisor.com/Hotels-g187471-oa30-Gran_Canaria_Canary_Islands-Hotels.html
获取酒店列表
如我们所见,URL的唯一更改是-oa30在酒店ID之后添加的。如果导航到第二页,则将使用-oa60代替-oa30。这发生在每个页面上。这样,我们可以创建一个函数来:
- 从网址中提取酒店ID
- 为每个页面生成URL
def get_id_from_url(URL):
# Split URL by -g to divide it before the ID
prefix, suffix = url.split('-g', maxsplit=1)
# Divide the URL after the ID (first dash)
id, slug = suffix.split('-', maxsplit=1)
return int(id)
def get_listing_url(page, base_url=BASE_URL, per_page=PER_PAGE):
assert page >= 0
id = get_id_from_url(base_url)
if page == 0:
return BASE_URL
return BASE_URL.replace(f'-g{id}-', f'-g{id}-oa{page * per_page}-')
编写N_PAGES完此代码后,我们可以从0循环到并为每个页面生成URL:
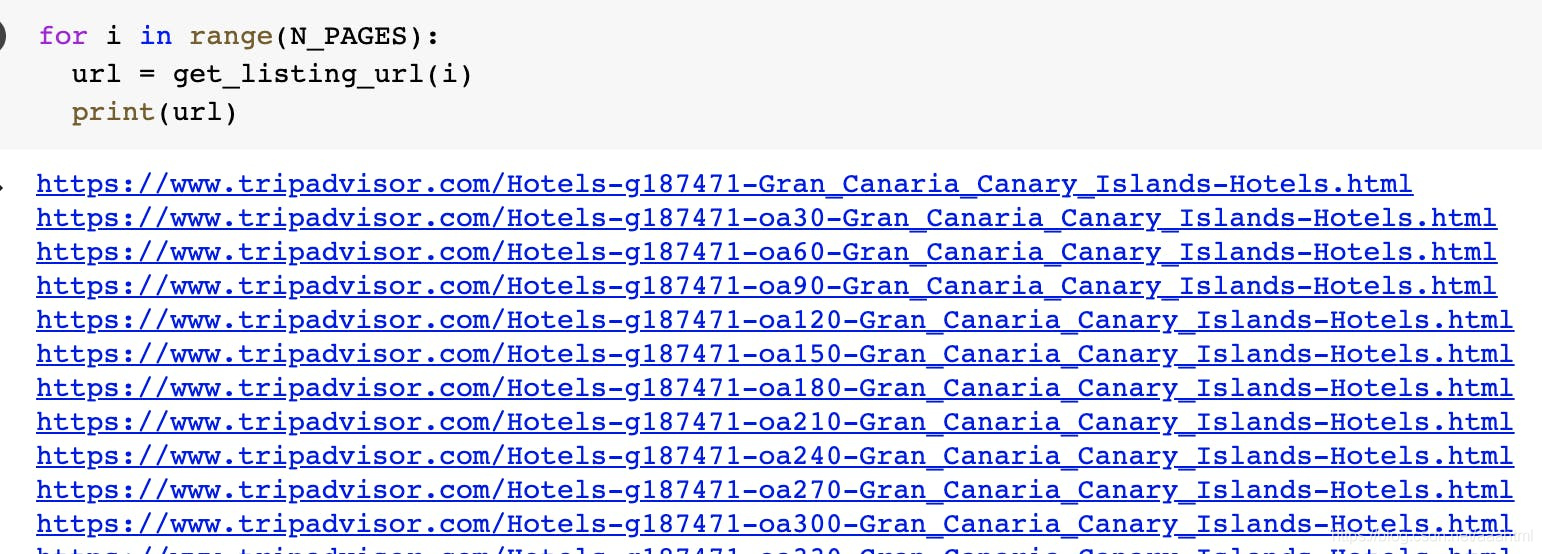
现在,让我们下载每个酒店列表页面,并使用每个酒店URL生成一个数组:
listings = []
for i in range(N_PAGES):
url = get_listing_url(i)
# Random delay to avoid TripAdvisor blocking us
time.sleep(random.randint(2, 8))
# Download current page
listing_html = requests.get(url)
listing_soup = BeautifulSoup(listing_html.text, 'html.parser')
# Add hotels to listings
raw_listings = listing_soup.select('.listing')
for raw_listing in raw_listings:
listings.append('https://www.tripadvisor.com' + raw_listing.a['href'])
几分钟后,我们应该listings用每个酒店URL填充变量🤩
分析数据
现在,让我们看看如何从每个酒店刮取评论...这就是我们在TripAdvisor上可以看到的内容:
如果向下滚动,我们将看到每个URL仅获得5条评论,这不是很好(每个酒店可能有数千条评论!)。好的,让我们打开我们的Chrome DevTools并检查在与本节进行交互时发生了什么:
如果现在更改评论语言(例如,更改为德语),我们将看到对此的请求/data/graphql/batched似乎很有趣:
TripAdvisor正在使用某种结构向其GraphQL端点发送请求,并发送了一个名为的属性locationId:
再一次,这locationId与我们在URL(在本例中Hotel_Review-g562819-d296922-Reviews-Bohemia_Suites_Spa...)中使用的完全相同。如果我们可以使用此端点从每个酒店获取评论怎么办?🤔
首先,让我们尝试从酒店URL中提取位置ID和地理位置ID。每个酒店网址都与此类似:
https://www.tripadvisor.com/Hotel_Review-g562819-d296922-Reviews-Bohemia_Suites_Spa-Playa_del_Ingles_Maspalomas_Gran_Canaria_Canary_Islands.html
复制
我们将需要后面-g的数字和之后的数字-d:
def get_ids_from_hotel_url(url):
url = url.split('-')
geo = url[1]
loc = url[2]
return (int(geo[1:]), int(loc[1:]))
从GraphQL获取数据
现在,让我们尝试模仿TripAdvisor对他们的GraphQL执行的请求。如果我们从“网络”标签中复制原始请求,则会看到类似于以下JSON的内容:
[
{
"query": "mutation LogBBMLInteraction($interaction: ClientInteractionOpaqueInput!) {\n logProductInteraction(interaction: $interaction)\n}\n",
"variables": {
"interaction": {
"productInteraction": {
"interaction_type": "CLICK",
"site": {
"site_name": "ta",
"site_business_unit": "Hotels",
"site_domain": "www.tripadvisor.com"
},
"pageview": {
"pageview_request_uid": "X@2fPQokGCIABGTeHYoAAAES",
"pageview_attributes": {
"location_id": 296922,
"geo_id": 562819,
"servlet_name": "Hotel_Review"
}
},
"user": {
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36",
"site_persistent_user_uid": "web373a.83.56.0.34.17609EB3BAC",
"unique_user_identifiers": {
"sess 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











