







mysql架构

网络连接层
- 客户端连接器
服务层(MySQL Server)
- 服务层是MySQL Server的核心
- SQL接口(SQL Interface):用于接受客户端发送的各种SQL命令,并且返回用户需要查询的结果。
- 比如DML、DDL、存储过程、视图、触发器等
- 解析器(Parser):负责将请求的SQL解析生成一个"解析树"。然后根据一些MySQL规则进一步检查解析树是否合法。
- 查询优化器(Optimizer):当“解析树”通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互
- select uid,name from user where gender=1;选取–》投影–》联接 策略
- 1)select先根据where语句进行选取,并不是查询出全部数据再过滤
- 2)select查询根据uid和name进行属性投影,并不是取出所有字段
- 3)将前面选取和投影联接起来最终生成查询结果
- 连接池(Connection Pool):负责存储和管理客户端与数据库的连接,一个线程负责管理一个连接
- 缓存(Cache&Buffer): 缓存机制是由一系列小缓存组成的。
- 比如表缓存,记录缓存,权限缓存,引擎缓存等。
- 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据
- 系统管理和控制工具(Management Services & Utilities):例如备份恢复、安全管理、集群管理等
存储引擎层(Pluggable Storage Engines)
- 存储引擎负责MySQL中数据的存储与提取,与底层系统文件进行交互。
- MySQL存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异 。
- 包含了几十个不同用途的底层函数,比如"读取索引第一条记录 11 11读取索引下一条记录" "插入记录"等
- server 层和存储引擎层交互时,一般是以记录为单位的
- 以 SELECT 语句为例, server 层根据执行计划先向存储引擎层取一条记录,然后判断是否符合 where条件
- 如果符合, 先将其发送到一个缓冲区,待到该缓冲区满了,才向客户端发送真正的记录。
- 否则跳过该记录
- 以 SELECT 语句为例, server 层根据执行计划先向存储引擎层取一条记录,然后判断是否符合 where条件
- 然后继续向存储引擎索要下一条记录 : 依此类推
- 现在有很多种存储引擎,各有各的特点,最常见的是MyISAM和InnoDB
文件系统层(File System)
- 该层负责将数据库的数据和日志存储在文件系统之上,并完成与存储引擎的交互,是文件的物理存储层
- 配置文件:用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等
- 数据文件:
- db.opt 文件:记录这个库的默认使用的字符集和校验规则。
- frm 文件:存储与表相关的元数据(meta)信息,包括表结构的定义信息等,每一张表都会有一个frm 文件。
- ibd文件和 IBDATA 文件:存放 InnoDB 的数据文件(包括索引)。
- InnoDB 存储引擎有两种表空间方式:独享表空间和共享表空间。
- 独享表空间使用 .ibd 文件来存放数据,且每一张InnoDB 表对应一个 .ibd 文件。
- 共享表空间使用 .ibdata 文件,所有表共同使用一个(或多个,自行配置).ibdata 文件。

- 日志文件:
- 二进制日志(binary log)
- 记录了对MySQL数据库执行的更改操作,并且记录了语句的发生时间、执行时长;
- 但是它不记录select、show等不修改数据库的SQL。
- 主要用于数据库恢复和主从复制。
- 通用查询日志(General query log)
- 记录一般查询语句
- show variables like ‘%general%’;
- 慢查询日志(Slow query log)
- 记录所有执行时间超时的查询SQL,默认是10秒
- 错误日志(Error log)
- 默认开启
- show variables like ‘%log_error%’
- 二进制日志(binary log)
- pid 文件:在Unix/Linux 系统中特有的文件,存放着自己的进程 id
- socket 文件:在Unix/Linux 系统中特有的文件,直接使用Unix/Linux的socket连接
mysql运行机制

- 建立连接(Connectors&Connection Pool),通过客户端/服务器通信协议与MySQL建立连接。
- MySQL 客户端与服务端的通信:TCP协议,3306端口
- 连接池,与客户端断开连接后,不会销毁线程,而是新来连接后复用,因此需要限制数量
- 对于每一个 MySQL 的连接,时刻都有一个线程状态来标识这个连接正在做什么。
- show processlist; //查看用户正在运行的线程信息,root用户能查看所有线程,其他用户只能看自己的
- 查询缓存(Cache&Buffer),
- 如果开启了查询缓存且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端;
- 如果没有开启查询缓存或者没有查询到完全相同的 SQL 语句则会由解析器进行语法语义解析,并生成“解析树”。
- 查询缓存的机制
- 缓存Select查询的结果和SQL语句
- 执行Select查询时,先查询缓存,判断是否存在可用的记录集,要求是否完全相同(包括参数值),这样才会匹配缓存数据命中
- 开启查询缓存时,缓存失效的情况
- 主动失效:查询语句使用SQL_NO_CACHE
- 查询的结果大于query_cache_limit设置
- 查询中有一些不确定的参数,比如now()
- 任何对表的修改都会导致这些表的所有缓存无效
- show variables like ‘%query_cache%’; //查看查询缓存是否启用,空间大小,限制等
- show status like ‘Qcache%’; //查看更详细的缓存参数,可用缓存空间,缓存块,缓存多少等
- mysql8中去掉了查询缓存
- 适用范围小
- 解析器(Parser)
- 将客户端发送的SQL进行语法解析,生成"解析树"。
- 预处理器根据一些MySQL规则进一步检查“解析树”是否合法,
- 例如这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义
- 最后生成新的“解析树”
- 查询优化器(Optimizer)
- 根据“解析树”生成最优的执行计划。
- MySQL使用很多优化策略生成最优的执行计划,可以分为两类:静态优化(编译时优化)、动态优化(运行时优化)。
- 等价变换策略
- 5=5 and a>5 改成 a > 5
- a < b and a=5 改成b>5 and a=5
- 基于联合索引,调整条件位置等
- 优化count、min、max等函数
- InnoDB引擎min函数只需要找索引最左边
- InnoDB引擎max函数只需要找索引最右边
- MyISAM引擎count(*),不需要计算,直接返回
- 提前终止查询
- 使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
- in的优化
- MySQL对in查询,会先进行排序,再采用二分法查找数据。比如where id in (2,1,3),变成 in (1,2,3)
- 等价变换策略
- 查询执行引擎
- 负责执行 SQL 语句
- 根据 SQL 语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互,得到查询结果并返回给客户端
- 若开启用查询缓存,这时会将SQL 语句和结果完整地保存到查询缓存(Cache&Buffer)中
- 返回结果过多,采用增量模式返回

详细参考:https://www.cnblogs.com/annsshadow/p/5037667.html
innodb结构


内存结构
- Buffer Pool:缓冲池
- 在InnoDB访问表记录和索引时会在Page页中缓存,以后使用可以减少磁盘IO操作,提升效率
- 以Page页为单位,Page页默认大小16K,链表结构
- page根据状态分为3类
- free page : 空闲page,未被使用
- free list :表示空闲缓冲区,管理free page
- clean page:被使用page,数据没有被修改过
- lru list:表示正在使用的缓冲区,管理clean page和dirty page,
- 缓冲区以midpoint为基点,
- 前面链表称为new列表区,存放经常访问的数据,占63%;
- 后面的链表称为old列表区,存放使用较少数据,占37%
- 普通LRU:末尾淘汰法,新数据从链表头部加入,释放空间时从末尾淘汰
- 改性LRU:
- 链表分为new和old两个部分,
- 加入元素时并不是从表头插入,而是从中间midpoint位置插入,
- 如果数据很快被访问,那么page就会向new列表头部移动,
- 如果数据没有被访问,会逐步向old尾部移动,等待淘汰。
- lru list:表示正在使用的缓冲区,管理clean page和dirty page,
- dirty page:脏页,被使用page,数据被修改过,页中数据和磁盘的数据产生了不一致
- flush list:表示需要刷新到磁盘的缓冲区,管理dirty page,
- 内部page按修改时间排序。
- 脏页即存在于flush链表,也在LRU链表中,但是两种互不影响,
- LRU链表负责管理page的可用性和释放,而flush链表负责管理脏页的刷盘操作
- flush list:表示需要刷新到磁盘的缓冲区,管理dirty page,
- free page : 空闲page,未被使用
- page页的管理:
- 每当有新的page数据读取到buffer pool时,InnoDb引擎会判断是否有空闲页,是否足够,
- 如果有就将free page从free list列表删除,放入到LRU列表中。
- 没有空闲页,就会根据LRU算法淘汰LRU链表默认的页,将内存空间释放分配给新的页
- 每当有新的page数据读取到buffer pool时,InnoDb引擎会判断是否有空闲页,是否足够,
- Adaptive Hash Index:自适应哈希索引
- 用于优化对BP数据的查询
- InnoDB存储引擎会监控对表索引的查找,
- 如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应。
- InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引
- Change Buffer:写缓冲区
- 当更新一条记录时,
- 该记录在BufferPool存在,直接在BufferPool修改,一次内存操作。
- 如果该记录在BufferPool不存在(没有命中),
- 会直接在ChangeBuffer进行一次内存操作,不用再去磁盘查询数据,避免一次磁盘IO。
- 当下次查询记录时,会先进性磁盘读取, 然后再从ChangeBuffer中读取信息合并,最终载入BufferPool中
- 写缓冲区,仅适用于非唯一普通索引页
- 如果在索引设置唯一性,在进行修改时,InnoDB必须要做唯一性校验,因此必须查询磁盘,做一次IO操作。
- 会直接将记录插入到BufferPool中,然后在缓冲池修改,不会在ChangeBuffer操作
- ChangeBuffer占用BufferPool空间,默认占25%,最大允许占50%
- 可以根据读写业务量来进行调整。参数innodb_change_buffer_max_size
- 当更新一条记录时,
- Log Buffer:日志缓冲区
- 在DML操作时会产生Redo和Undo日志,被缓冲在日志缓冲区。
- 日志的刷新:innodb_flush_log_at_trx_commit参数控制日志刷新行为,默认为1
- 0:每隔1秒写日志文件和刷盘操作(写日志文件LogBuffer–>OS cache,刷盘OScache–>磁盘文件),最多丢失1秒数据
- 1:事务提交,立刻写日志文件和刷盘,数据不丢失,但是会频繁IO操作
- 2:事务提交,立刻写日志文件,每隔1秒钟进行刷盘操作
- 日志缓冲区满时会自动将其刷新到磁盘,当遇到BLOB或多行更新的大事务操作时,增加日志缓冲区可以节省磁盘I/O。
线程
Master Thread
- 主循环loop
- 每1秒的操作
- 日志刷新到磁盘,即使事务还没提交,
- 刷新脏页到磁盘,
- 执行合并插入缓冲操作
- 产生checkpoint
- 清楚无用的table cache
- 当前没有操作切换到background loop
- 每10秒的操作
- 日志刷新到磁盘,即使事务还没提交
- 刷新脏页到磁盘
- 执行合并插入缓冲操作
- 产生checkpoint
- 删除无用的undo
- 每1秒的操作
- 后台循环 background loop
- 刷新循环 flush loop
- 暂停循环 supsend loop
IO Thread
- read thread:读请求线程(默认值都是4个,可以适当调大)
- write thread:写请求线程(默认值都是4个,可以适当调大)
- redo log thread:负责把日志缓冲区的内容刷新到redo log(默认值都是4个,可以适当调大)
- change buffer thread:把插入缓冲区内容刷新到磁盘(默认值都是4个,可以适当调大)
锁监控
错误监控
Purge Thread
删除无用的undo页,通过innodb_purge_thread参数调整线程数默认是1个,最大调整为32个
Page Cleaner Thread
将脏页刷到缓存中,可以调为多个
磁盘结构
B+索引的组成
- 数据页
- page中User Records , 真正存储我们插入的记录。
- 每个记录的头信息中都有一个 next record 属性,从而可以使页中的所有记录串联成一个单向链表
- Page Directory:
- 页中的记录划分为若干个组
- 每个组最多8条记录
- 每个组的最后一个记录的地址偏移量作为一个槽,存放在 Page Directory 中
- 一个槽占用 2 字节
- 在一个页中根据主键查找记录是非常快
- 通过二分法确定该记录所在分组对应的槽,并找到该糟所在分组中主键值最小的那条记录
- 最小的记录是上个槽的下一个记录
- 通过记录的 next record 属性遍历该槽所在的组中 的各个记录
- 通过二分法确定该记录所在分组对应的槽,并找到该糟所在分组中主键值最小的那条记录
- 每个数据页的File Header 部分都有上一个页和下一个页的编号,所以所有的数据页会组成一个双向链表
- 索引页
- 存放每条记录是:主键+页号
- 二级索引
- 索引页是索引列+主键+页号,因为可能不唯一,使用主键保证唯一,唯一好有序
- 相当于(索引列+主键)的联合索引
- 叶子节点也是索引列+主键
- 通过主键回表查询
- 索引页是索引列+主键+页号,因为可能不唯一,使用主键保证唯一,唯一好有序
- 页空间的维护
- 根节点不变
- 插入,页分裂
文件
- 单表表空间
- 表名.frm 表的定义
- 表名.ibd 表的数据

- 一个区是64个页,连续分配,保证近似顺序读写
- 段:将索引区和数据区分开管理,保证顺序读写
- 一个索引两个段
- 分配:
- 开始从碎片区分配
- 一个段超过32个区,会以区为单位分配。原来的碎片区不动。
- 区:
- 空闲的区
- 有剩余空闲页的碎片区
- 没有剩余空间的碎片区
- 属于某个段的区
表空间
- 系统表空间(The System Tablespace)
- 数据字典(InnoDB Data Dictionary)
- InnoDB数据字典由内部系统表组成,这些表包含用于查找表、索引和表字段等对象的元数据。
- 元数据物理上位于InnoDB系统表空间中。
- 由于历史原因,数据字典元数据在一定程度上与InnoDB表元数据文件(.frm文件)中存储的信息重叠
- 双写缓冲区(Doublewrite Buffer)
- 作用:防止将脏页刷新到磁盘中,出现部分写的问题。
- innodb的页大小默认是16K,Linux的block size是4K,
- 刷新过程中os crash或者停电,会导致部分数据写入到磁盘中,导致数据不一致。
- innodb现将buffer pool中的数据写入到doublewrite buffer中,再刷新到磁盘中。
- 如果是刷盘过程中出现问题。innodb将doublewrite 中的数据刷新到数据库即可,
- 若写到doublewrite出错,则用原始数据和redo日志恢复
- 参考:https://www.cnblogs.com/geaozhang/p/7241744.html
- 写缓冲区 change buffer
- 撤销日志(Undo Logs)
- 用户在系统表空间创建的表数据和索引数据
- 系统表空间是一个共享的表空间因为它是被多个表共享的。
- 该空间的数据文件通过参数innodb_data_file_path控制,默认值是ibdata1:12M:autoextend(文件名为ibdata1、12MB、自动扩展)
- 数据字典(InnoDB Data Dictionary)
- 单表表空间(File-Per-Table Tablespaces)
- 默认开启
- 被.ibd文件代表
- 共享表空间(General Tablespaces)
- CREATE TABLESPACE ts1 ADD DATAFILE ts1.ibd Engine=InnoDB; //创建表空间ts1
- CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1; //将表添加到ts1表空间
- 临时表空间(Temporary Tablespaces)
- session temporary tablespaces 存储的是用户创建的临时表和磁盘内部的临时表。
- global temporary tablespace储存用户临时表的回滚段(rollback segments )。
- mysql服务器正常关闭或异常终止时,临时表空间将被移除,每次启动时会被重新创建。
- 撤销表空间(Undo Tablespaces)
- 撤销表空间由一个或多个包含Undo日志文件组成
- 撤消日志是在事务开始之前保存的被修改数据的备份,用于例外情况时回滚事务。
- 撤消日志属于逻辑日志,根据每行记录进行记录。
- 撤消日志存在于系统表空间、撤消表空间和临时表空间中。
重做日志(Redo Log)
- https://mp.weixin.qq.com/s/QaN-ROOW06b6rm-HoiSX3g
- 用于在崩溃恢复期间更正不完整事务写入的数据。
- 两个文件循环写
- 记录InnoDB中对Buffer Pool中Page修改的日志,即物理日志,区别于binLog的具体操作日志,即逻辑日志

- 日志写入硬盘时无需doublewrite
- 重做日志(内存和硬盘文件)按512字节存储,成为redo block
- 如果大于 512字节会拆分成多个块存储
- 写入硬盘时按照redo block写入,即512字节,是硬盘层面最小的写入单位,保证写入必定是原子的
- 当出现实例故障(像断电),导致数据未能更新到数据文件,则数据库重启时须redo,重新把数据更新到数据文件。

undo log
- 数据的逻辑变化,当发生回滚时,反向操作,即可以恢复到原来的样子。
- 目的是发生错误时回滚,MVCC
- 存在表空间的undo段中
- 事务开启后,修改记录前,将前值记录undo日志中
- 写undo的redo
- 写undo
- 修改数据页
- 写Redo
mysql缓存、文件的设计
支持事务
- 持久性:持久化到硬盘
- redo日志可以算持久性的保证,且必须设置为每次事务提交时将redo日志刷新到硬盘中
- 原子性:
- undo日志
- 事务开启后,修改记录前,将前值记录undo日志中。
- 如果事务回滚,则使用undo日志记录中的前值恢复。
- 页写入的原子性
- 双写缓冲区
- 先将页内存copy到双写缓冲内存中2M
- 分两次顺序写入双写缓冲文件中,每次1M。调用fsync同步磁盘
- 在将页中的变更随机写入到数据库中。
- 双写缓冲区
- undo日志
- 隔离性:undo日志
- MVCC
- 一致性:
提升效率
- B+树聚簇索引,提升了读取效率
- 利用硬盘连续读取快而随机读取慢的特性,使用的更加矮胖B+数,数据存放的叶子节点
- 使用内存缓存,提升了读取效率
- 需要保证内存和硬盘的数据一致性,缓存命中率
- 缓冲池,缓存热点的索引和记录
- 自适应hash索引:对有必要的缓冲池的数据自动建立hash索引
- 日志缓冲
- 使用redo日志,将随机写入转为顺序写入,提升写入效率
- 使用变更缓存,提升了写入效率
- 适用于 非唯一 索引 页
- Change buffer的主要目的是
- 将对二级索引的数据操作缓存下来,以此减少二级索引的随机IO,并达到操作合并的效果。
- 对表执行 INSERT,UPDATE和 DELETE操作时, 索引列的值(尤其是secondary keys的值)
- 通常按未排序顺序排列,需要大量I / O才能使二级索引更新。
- Change Buffer会缓存这个更新当相关页面不在Buffer Pool中,
- 从而磁盘上的相关页面不会立即被读避免了昂贵的I / O操作。
- 流程:
- 来了一个关于二级索引页面的DML操作,并且这个页面没有在Buffer Pool内,
- 那么把这个操作存入Change Buffer
- 下一次需要加载这个页面的时候,将Change Buffer内的更改合并到Buffer Pool,
- 随后当服务器在空闲的时候,这个更改会刷到disk(磁盘)上。

索引
- 聚簇索引与二级索引
- B+树索引
- 优化
- 组合索引.最左匹配
- like.左匹配
- 回表查询-》覆盖索引
- 排序:
- index,取出的数据就是有序的,省去了排序步骤。
- filesort
- 双路排序,先将排序字段取出排序,再去读取其他字段
- 单路排序,将所有数据取出,直接排序返回
优化
定位慢查询
- 开始慢查询日志
- 使用explain分析
索引优化
- 一般情况下能走索引就走索引
- 不能走现有的索引,则评估后建立适合的索引
- 强制使用某个索引force index
- 正确使用索引
分页优化
- 偏移量少的时候直接使用limit
- 偏移量大的时候改写分页sql
- 覆盖索引
- 子查询
- SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
- join
- SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
事务之隔离级别

- 不可重复读:读取同一条记录的其他事务提交的值。
- 不可重复读:读取其他事务已提交新增的记录。
- 不知道是谁发明了不可重复读和幻读问题,这本质都是一样的东西啊,就是一个事务内两次读取同一些数据,结果不一样。这就是统一的幻读问题啊。行级锁可以解决更新和删除导致的幻读,间隙锁可以解决插入导致的幻读。为啥要分开呢,导致很多人看的时候云里雾里,而且很多人也是跟着人云亦云。
海先生Hision回复:行锁锁数据,同一主键一个可重复读隔离级别下可以被锁住。而幻读是指通过非主键进行匹配,查询出来的数据包含新插入的数据,所以需要更高级别的事物隔离

MVCC与锁
- 参考:https://blog.csdn.net/SnailMann/article/details/94724197
- mvcc也是Copy on Write的思想,支持读读,读写,写读的并行,提供无锁并发支持(特指快照读,当前读需要加锁)
- 而写写并发控制由乐观锁和悲观锁控制
- MVCC支持 Read Commited 和 Repeatable Read 两种隔离级别
- 在每次事务修改操作前,在undo日志中记录修改之前的数据状态和事务号,可以提供给其他事务读取
- MVCC读取分为两类: 快照读(Snapshot Read)与当前读 (Current Read)
- 快照读:读取的是记录的快照版本(有可能是历史版本),不用加锁。(select)
- 当前读:读取的是记录的最新版本,并且当前读返回的记录,都会加锁,保证其他事务不会再并发修改这条记录。(select… for update 或lock in share mode,insert/delete/update)
- 实现
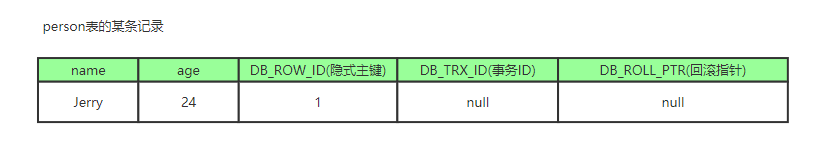
- 记录的隐式字段

- DB_ROW_ID 是数据库默认为该行记录生成的唯一隐式主键
- DB_TRX_ID 是当前操作该记录的事务 ID
- DB_ROLL_PTR 是一个回滚指针,用于配合 undo日志,指向上一个旧版本
- undo日志
- insert undo log:事务在 insert 新记录时产生的 undo log, 只在事务回滚时需要,并且在事务提交后可以被立即丢弃
- update undo log:
- 事务在进行 update 或 delete 时产生的 undo log ;
- 不仅在事务回滚时需要,在快照读时也需要;
- 所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被 purge 线程统一清除
- 举例
- 比如一个有个事务插入 persion 表插入了一条新记录,记录如下,name 为 Jerry , age 为 24 岁,隐式主键是 1,事务 ID和回滚指针,我们假设为 NULL
- 现在来了一个事务 1对该记录的 name 做出了修改,改为 Tom
- 在事务 1修改该行(记录)数据时,数据库会先对该行加排他锁
- 然后把该行数据拷贝到 undo log 中,作为旧记录,既在 undo log 中有当前行的拷贝副本
- 拷贝完毕后,修改该行name为Tom,并且修改隐藏字段的事务 ID 为当前事务 1的 ID, 我们默认从 1 开始,之后递增,回滚指针指向拷贝到 undo log 的副本记录,既表示我的上一个版本就是它事务提交后,释放锁
 * 又来了个事务 2修改person 表的同一个记录,将age修改为 30 岁
* 又来了个事务 2修改person 表的同一个记录,将age修改为 30 岁
- 比如一个有个事务插入 persion 表插入了一条新记录,记录如下,name 为 Jerry , age 为 24 岁,隐式主键是 1,事务 ID和回滚指针,我们假设为 NULL
- 在事务2修改该行数据时,数据库也先为该行加锁
- 然后把该行数据拷贝到 undo log 中,作为旧记录,发现该行记录已经有 undo log 了,那么最新的旧数据作为链表的表头,插在该行记录的 undo log 最前面
- 修改该行 age 为 30 岁,并且修改隐藏字段的事务 ID 为当前事务 2的 ID, 那就是 2 ,回滚指针指向刚刚拷贝到 undo log 的副本记录
- 事务提交,释放锁

从上面,我们就可以看出,不同事务或者相同事务的对同一记录的修改,会导致该记录的undo log成为一条记录版本线性表,既链表,undo log 的链首就是最新的旧记录,链尾就是最早的旧记录
当然就像之前说的该 undo log 的节点可能是会 purge 线程清除掉,向图中的第一条 insert undo log,其实在事务提交之后可能就被删除丢失了,不过这里为了演示,所以还放在这里 - Read View 读视图
Read View 就是事务进行快照读操作的时候生产的读视图 (Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的 ID (当每个事务开启时,都会被分配一个 ID , 这个 ID 是递增的,所以最新的事务,ID 值越大)
- 记录的隐式字段
所以我们知道 Read View 主要是用来做可见性判断的, 即当我们某个事务执行快照读的时候,对该记录创建一个 Read View 读视图,把它比作条件用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据。
Read View遵循一个可见性算法,主要是将要被修改的数据的最新记录中的 DB_TRX_ID(即当前事务 ID )取出来,与系统当前其他活跃事务的 ID 去对比(由 Read View 维护),如果 DB_TRX_ID 跟 Read View 的属性做了某些比较,不符合可见性,那就通过 DB_ROLL_PTR 回滚指针去取出 Undo Log 中的 DB_TRX_ID 再比较,即遍历链表的 DB_TRX_ID(从链首到链尾,即从最近的一次修改查起),直到找到满足特定条件的 DB_TRX_ID , 那么这个 DB_TRX_ID 所在的旧记录就是当前事务能看见的最新老版本
锁
分类
- 粒度
- 表级锁
- 行级锁
- 页级锁:innoDB没有
- 操作
- 读锁:共享锁
- 事务A对记录添加了S锁,可以对记录进行读操作,不能做修改,
- 其他事务可以对该记录追加S锁,但是不能追加X锁,
- 需要追加X锁,需要等记录的S锁全部释放
- 写锁 :排它锁
- 事务A对记录添加了X锁,可以对记录进行读和修改操作,其他事务不能对记录做读和修改操作
- IS锁、IX锁:意向读锁、意向写锁,属于表级锁,S和X主要针对行级锁。在对表记录添加S或X锁之前,会先对表添加IS或IX锁。
- 读锁:共享锁
InnoDB行锁
- 通过对索引数据页上的记录加锁实现的,分为Record Lock、Gap Lock 和 Next-key Lock
- RecordLock锁:锁定单个行记录的锁。(记录锁,RC、RR隔离级别都支持)
- GapLock锁:间隙锁,锁定索引记录间隙,确保索引记录的间隙不变。(范围锁,RR隔离级别支持)
- Next-key Lock 锁:记录锁和间隙锁组合,锁住一个前开后闭区间。(记录锁+范围锁,RR隔离级别支持)
- RR隔离级别
- 对于记录加锁行为都是先采用Next-Key Lock,
- 但是当SQL操作含有唯一索引时,Innodb会对Next-Key Lock进行优化,降级为RecordLock,仅锁住索引本身而非范围。
- select … from 语句:InnoDB引擎采用MVCC机制实现非阻塞读,所以对于普通的select语句,InnoDB不加锁
- select … from lock in share mode语句:
- 追加了共享锁,InnoDB会使用Next-Key Lock锁进行处理,
- 如果扫描发现唯一索引,可以降级为RecordLock锁。
- select … from for update语句:
- 追加了排他锁,InnoDB会使用Next-Key Lock锁进行处理,
- 如果扫描发现唯一索引,可以降级为RecordLock锁
- insert语句:InnoDB会在将要插入的那一行设置一个排他的RecordLock锁。
- update/delete … where 语句:
- InnoDB会使用Next-Key Lock锁进行处理,
- 如果扫描发现唯一索引,可以降级为RecordLock锁
- 主键加锁:仅在id=10的主键索引记录上加X锁。
- 唯一键加锁:现在唯一索引id上加X锁,然后在id=10的主键索引记录上加X锁。
- 非唯一键加锁:对满足id=10条件的记录和主键分别加X锁,然后在(6,c)-(10,b)、(10,b)-(10,d)、(10,d)-(11,f)范围分别加Gap Lock
- 无索引加锁:表里所有行和间隙都会加X锁。(当没有索引时,会导致全表锁定,因为InnoDB引擎锁机制是基于索引实现的记录锁定)






- 在快照读(简单select)读情况下,mysql通过mvcc实现了一致性不锁定读(Consistent Nonlocking Reads),读取的是快照版本,从而避免了(非当前读下)幻读
- 在当前读读情况下,mysql通过next-key来避免幻读。原理是通过显式加锁,不仅锁定符合条件的索引,也锁定间隙(如果是非唯一索引),使得其他事务不能新增修改或删除同条件的数据。
mysql高可用架构与复制
mysql复制类型
- 异步复制
- 半同步复制
- 有损半同步复制
- 无损半同步复制
- 多源复制:数仓
- 延迟复制:数据库快照
- 组复制
mysql高可用架构
扩展性
- 读写分离
- 优点:扩展了读能力,适用读多写少的场景
- 分库分表
高可用
- 主备
- 主从
- 双主
- 组复制:MGR-MySQL Group Replication
原理:
- 数据一致性:无损半同步复制
- 发现故障:Keepalived
- 转移故障:VIP
容灾与备份
- 宕机分类
- 机房级宕机: 机房光纤不通/被挖断,机房整体掉电(双路备用电源也不可用);
- 城市级宕机: 一般指整个城市的进出口网络,骨干交换机发生的故障(这种情况发生的概率很小)。
- 容灾分类:
- 机房内容灾: 机房内某台数据库服务器不可用,切换到同机房的数据库实例,保障业务连续性;
- 同城容灾: 机房不可用,切换到同城机房的数据库实例,保障业务连续性;
- 跨城容灾: 单个城市机房都不可用,切换到跨城机房的数据库实例,保障业务连续性。
- 场景与数据
- 跨城机房距离超过 200KM,延迟超过 25ms,对业务影响极大。一般采用异步复制
- 方案模型
- 同城容灾:一地三中心
- 两中心如果网络波动,会造成主机房事务提交被hang住。
- 3中心配置 rpl_semi_sync_master_wait_for_slave_count =1,有一个从库返回ack即可提交


异步复制实现读写分离
延时复制实现数据备份
- 同城容灾:一地三中心
- 高可用套件
- MHA
- MMM
- MGR
分布式数据库

- 计算层就是之前单机数据库中的 SQL 层,用来对数据访问进行权限检查、路由访问,以及对计算结果等操作。
- 元数据层记录了分布式数据库集群下有多少个存储节点,对应 IP、端口等元数据信息是多少。
- 当分布式数据库的计算层启动时,会先访问元数据层,获取所有集群信息,才能正确进行 SQL 的解析和路由等工作。
- 另外,因为元数据信息存放在元数据层,那么分布式数据库的计算层可以有多个,用于实现性能的扩展。
- 存储层用来存放数据,但存储层要和计算层在同一台服务器上,甚至不求在同一个进程中。
mysql分布式

ShardingSphere

- 功能
- 数据分片
- 读写分离
- 弹性伸缩
- 分布式事务
- 控制台,权限和审计功能
- 概念
- 表
- 逻辑表
- 真实表
- 绑定表:分片规则一致的主表和子表。
- 例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。
- 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
- 广播表:所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。
- 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
- 分片键和分片算法
- hash
- 主键生成策略,
- 分布式事务
- XA两阶段事务
- SEATA 柔性事务
- 弹性伸缩


- 表
- seata
- TM (事务管理器)
- RM (资源管理器)
- TC (事务协调器)
- 周期
- TM 要求 TC 开始一个全新的全局事务。
- TC 生成一个代表该全局事务的 XID,XID 贯穿于微服务的整个调用链。
- 作为该 XID 对应到的 TC 下的全局事务的一部分,RM 注册本地事务。
- TM 要求 TC 提交或回滚 XID 对应的全局事务。
- TC 驱动 XID 对应的全局事务下的所有分支事务完成提交或回滚。

TiDB

- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
架构
- TiKV
- 使用RocksDB ,是KV存储引擎,
- 使用Raft协议
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多。
- 以 Region 为单位做 Raft 的复制和成员管理。

- 计算
- 表数据与 Key-Value 的映射关系
- 元信息管理:如数据库和表定义的关系
- TiDB Server
- SQL 翻译成 Key-Value 操作,将其转发给共用的分布式 Key-Value 存储层 TiKV,
- 然后组装 TiKV 返回的结果,最终将查询结果返回给客户端

- 调度
- PD (Placement Driver)是TiDB 集群的管理模块,同时也负责集群数据的实时调度。
- TiKV 集群是 TiDB 数据库的分布式 KV 存储引擎,
- 数据以 Region 为单位进行复制和管理,每个 Region 会有多个副本 (Replica),这些副本会分布在不同的 TiKV 节点上,
- 其中 Leader 负责读/写,Follower 负责同步 Leader 发来的 Raft log。
- 目标
- 必要
- 副本数量不能多也不能少
- 副本需要根据拓扑结构分布在不同属性的机器上
- 节点宕机或异常能够自动合理快速地进行容灾
- 进阶
- 维持整个集群的 Leader 分布均匀
- 维持每个节点的储存容量均匀
- 维持访问热点分布均匀
- 控制负载均衡的速度,避免影响在线服务
- 管理节点状态,包括手动上线/下线节点
- 必要
- 手段
- 增加一个副本
- 删除一个副本
- 将 Leader 角色在一个 Raft Group 的不同副本之间 transfer(迁移)。
- 实现:通过Raft 协议的AddReplica、RemoveReplica、TransferLeader 这三个命令,可以支撑上述三种基本操作。
- 信息搜集
- 每个 TiKV 节点会定期向 PD 汇报节点的状态信息
- 每个 Raft Group 的 Leader 会定期向 PD 汇报 Region 的状态信息
分布式数据库
- 架构
- 共享存储架构
演进方式
- 单体+中间件:mysql+ShardingSphere,在单体数据库上进行分布式的扩展
- nosql->newsql,分布式数据库:从一开始就考虑分布式环境,
- 分布式共识算法保证数据一致性
- 存储计算分离
- 存储节点有状态
- 计算节点无状态,可直接扩展
- raft:leader写入,follower读取,读取能力扩展了,但是写入没有扩展
- 如果3副本,3机器,3分段。则每台机器都可以写入,写入能力也扩展了















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









