







目录
一,进程间通信预备
(本篇博客代码量偏多,请各位小伙伴酌情阅读~)
①进程具有独立性 --> 导致进程与进程间的信息交流难度比较大 --> 进程间通信本质:让不同进程能看到同一份资源(内存空间)
②进程间通信的必要性:它不是目的而是手段,单进程无法使用并发能力,更加无法实现多进程协同,例如传输数据,同步执行流,消息通知等
③进程间通信的技术背景:1,进程具有独立性:虚拟地址空间+页表,保证进程运行的独立性(进程内核数据结构,进程的代码和数据) 2,通信成本比较高
④进程间通信的本质:让不同的进程看到同一份“内存”,而且这个“内存”不能属于任何一个进程,而应该强调共享性
⑤进程间通信的方式:
- Linux原生提供的通信方式:匿名管道,命名管道
- System -- 多线程 -- 单机通信:共享内存,消息队列(不常用),信号量(了解即可)
- posix -- 多线程 -- 网络通信
二,匿名管道
2.1 管道原理
- 在生活中,管道都是有“入口”和“出口”,且都是单向传输,传输的都是“资源”,天然气,是由,自来水都可以认为是“资源”,而计算机最重要的“资源”就是“数据”,所以计算机通信领域的设计大佬设计了一种单向通信的方式:管道
- 管道是Unix最古老的进程间通信的形式,我们把一个进程连接到另一个进程的一个数据流称为一个“管道”
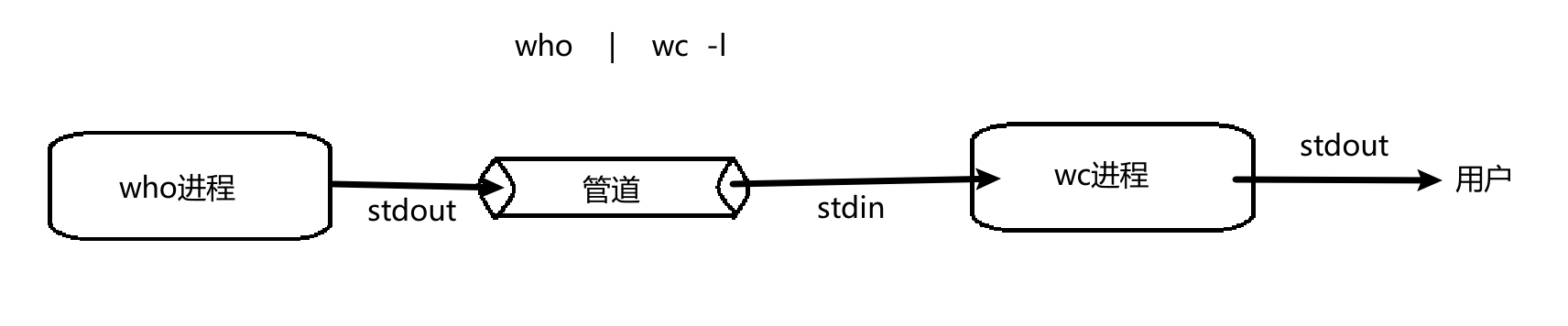
- 我们之前查看进程pid的时候经常在bash上用过一个叫做 | 的管道文件,例如,我们可以统计我们当前云服务器上的登录用户个数

- 其中who和wc命令都是两个可执行程序,当它们运行起来的时候就变成了两个进程,who进程通过标准输出将数据放到“管道”中,wc进程再通过标准输入从“管道”中读取到了数据,完成了一次数据的传输(who是显示当前登录用户名,以行显示,所以wc -l相当于统计行数)
2.2 匿名管道原理
- 匿名管道常用于父子进程间的通信,所以仅限于本地父子进程间通信
- 先创建父进程,系统创建task_struct结构体,结构体中一个制作指向文件描述符数组,然后默认打开三个流文件并创建对应的struct_file,每个struct_file里面有inode结构体和内核缓冲区,然后分配0,1,2三个文件描述符并返回给父进程
- 然后父进程fork创建子进程,拷贝task_struct,同时文件描述符表也拷贝了一份给子进程,其内容和父进程一样,所以父子进程的文件描述符指向的文件是同一份,这也就是父子进程打印时同时往屏幕上打的原因
- 所以打开的文件是没有拷贝的,因为task_struct以及文件描述符表属于进程相关的数据结构,而struct_file是文件的相关数据结构,二者不相关。
- 所以,父子进程都通过同一个文件描述符表找到了同一个文件,意味着父子进程“看到了一份相同的文件”,我们把这种文件就叫做管道文件
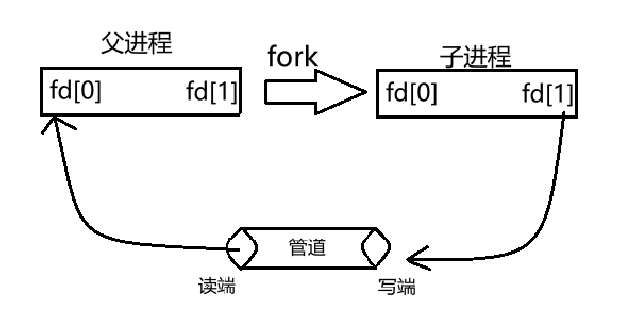
- 由于管道是单向的,父进程进行写入,子进程进行读取,所以父进程会关闭“读”保留“写”,子进程关闭“写”保留“读”,那么就形成了一条“父进程通过3号文件描述符写,子进程通过4号文件描述符读”的一条单向通道,这就是匿名管道的原理。后面会有图解释。
问题:父进程往文件里写,子进程从文件里读,那么写后的文件还要保存到磁盘上吗?
解答: 不要,因为进程间通信我们一定要保证是纯内存级别的通信,因为这样效率最高,完成进程间通信产生的数据大多数都是临时数据
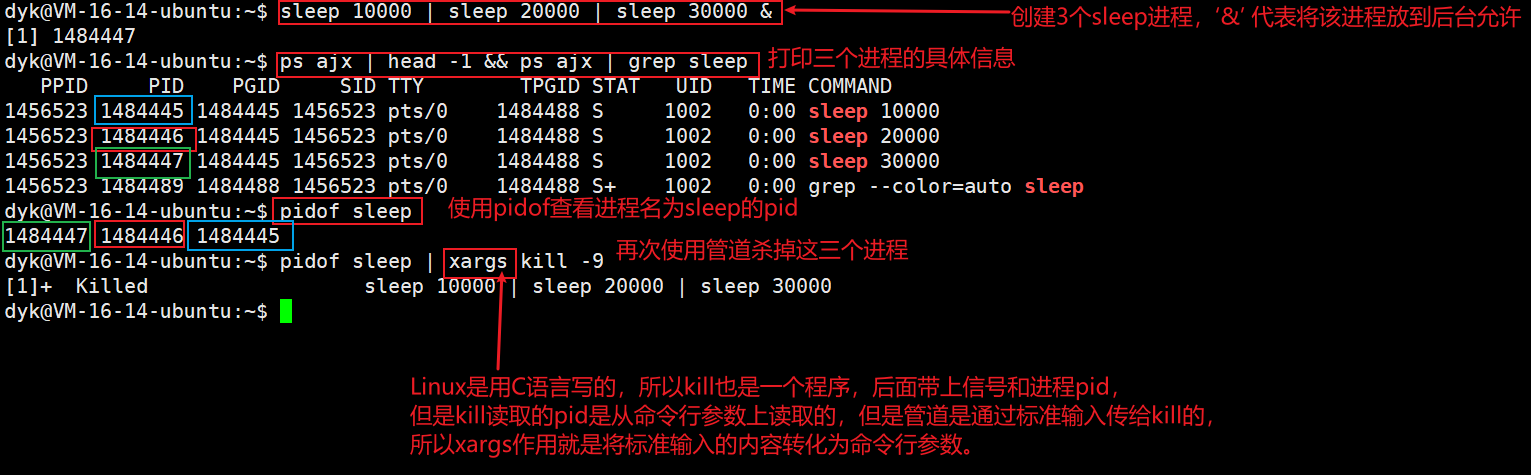
2.3 pidof工具
我们之后会遇到很多后台进程或者守护进程,我们要想关掉后台进程用ps ajs去查后台进程的pid再用kill -9杀掉时会非常麻烦,所以pidof工具就是快速查看进程pid,在后面跟上进程名就可以显示与进程名匹配的所以进程的pid,如下图:
 2.4 pipe()
2.4 pipe()
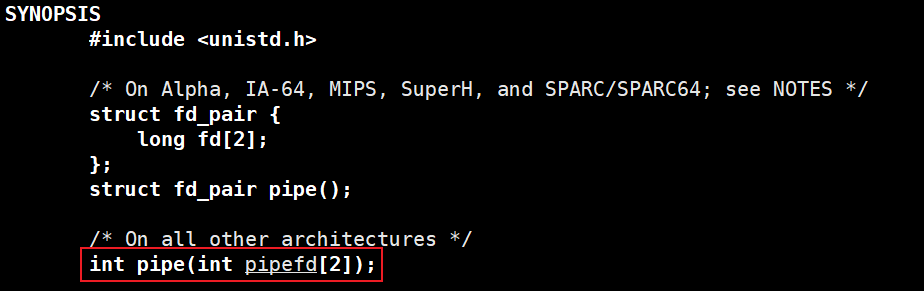
pipe用于创建匿名管道,其参数是一个2个int大小的数组,该数组作为输出型参数,用于返回两个指向管道独断和写端的文件描述符,这有点不好理解,结合上面的原理和下面的图可能好理解:
1,父进程先调用pipe函数创建管道:
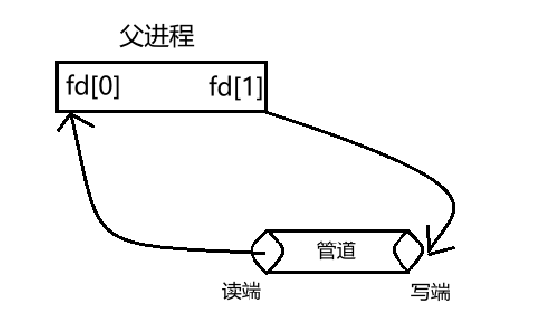
2,父进程创建子进程,拷贝文件描述符表:
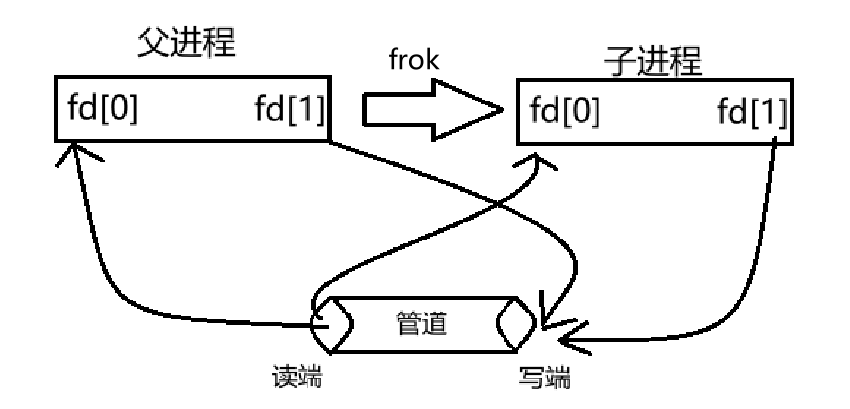
3,父进程关闭写端,子进程关闭读端:
#include <iostream>
#include <assert.h>
#include <unistd.h>
#include <string>
#include <cstdio>
#include <cstring>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
int main()
{
// 1,创建管道
int pipefd[2] = {0}; // pipefd[0]:读端,pipe[1]:写端(父子进程都可以看到)
int n = pipe(pipefd); // 保存管道的数组,pipe[]作为输出型参数
assert(n != -1);
(void)n; // 在debug模式下assert是有效的,但是到了release模式下断言就没了,那么n就会只定义未使用,会出现大量警告,带上这句证明n被使用过
#ifdef DEBUG // 条件编译 -- 如果想调试时打印,就在Makefile的-std=c11++后面加个 -DEBUG,如果想注释掉就在-前面加个#
cout << "pipe[0]:" << pipefd[0] << endl; // 输出3
cout << "pipe[1]:" << pipefd[1] << endl; // 输出3
#endif
// 2,创建子进程
pid_t id = fork();
assert(id != -1);
if (id == 0) // 子进程
{
// 3,构建单向通道的信道,父进程写入,子进程读取
// 3.1 关闭子进程不要的fd
close(pipefd[1]); // 子进程要进行读取,就要关闭pipefd[1]:写端
char buffer[1024]; // 读取管道数据到缓冲区
while (true) // 死循环让子进程不断读取管道文件的数据
{
ssize_t s = read(pipefd[0], buffer, sizeof(buffer) - 1); // 从0号文件里读,读1024大小,读到buffer结尾
if (s > 0) // 读取成功
{
buffer[s] = 0; // 给最后添加0
cout << "child get date: " << buffer << endl;
}
else if (s == 0)
{
// 写入的一方,fd没有关闭,如果有数据就读,没数据就等
// 写入的乙方,fd关闭,读取的一方的read会返回0,表示读到了文件的结尾(因为管道是单向通信的,写端关了就代表不会再有数据写进来了)
cout << "write quit(father), child quit too" << endl;
break;
}
}
exit(0);
}
else // 父进程
{
// 3,构建单向通道的信道,父进程写入,子进程读取
// 3.1 关闭父进程不需要的fd
close(pipefd[0]); // 父进程要进行写u人,就要关闭pipefd[0]:读端
string message = "我是父进程,你好";
int count = 0; // 计数器,记录发送消息的条数
char send_buffer[1024 * 8];
while (true)
{
// 3.2 构建一个变化的字符串
snprintf(send_buffer, sizeof(send_buffer), "%s[%d]", message.c_str(), ++count);
// C语言的printf往显示器上打,sprintf往文件里打,这个snprintf就是往缓冲区里打
// 3.3写入,把send_nuffer里面的数据写到子进程的pipfd[1]里面
write(pipefd[1], send_buffer, strlen(send_buffer));
sleep(1);
if (count == 5) // 父进程写五条消息后停止写入
{
cout << "write quit(father)" << endl;
break;
}
}
close(pipefd[1]); // 父进程写完数据后关闭写端
}
pid_t ret = waitpid(id, nullptr, 0); // 等待子进程退出
assert(ret > 0);
(void)ret;
return 0;
}
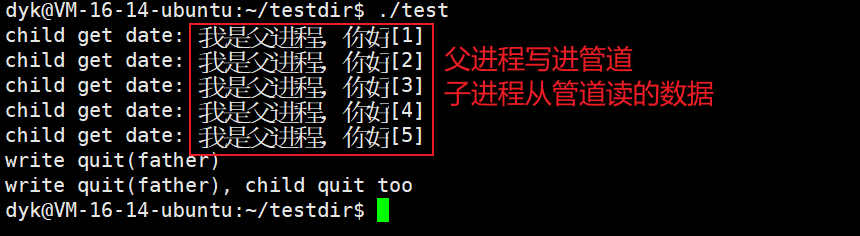
上面代码的大致逻辑是:
1,父进程先定义一个string表示2要传输的数据(此处为“我是父进程,你好”),然后用snprintf把字符串放进缓冲区,然后父进程通过write接口往pipe返回的文件描述符里写,也就是写到管道文件里
2,子进程也通过read接口从pipe返回的文件描述符里读,也就是读管道文件里的数据再打印出来
3,当父进程停止写入,子进程read读取失败会返回-1,然后子进程退出,父进程等待子进程完成也退出
2.6 管道的四种情况
- 写端进程不写,读端进程一直读,那么读端进程会被挂起,直到管道里面有数据后才会被唤醒,这是因为管道有同步互斥机制,我们后面讲
- 与情况一类似,读端进程不读的时候,写端一直写,管道文件也是有大小的,如果管道文件被写满了,那么写端进程会被挂起,只有当读端进程读取后,写端才会被唤醒
- 写端进程写数据后将写端的文件描述符关闭,那么读端读完之后就继续运行不会被挂起
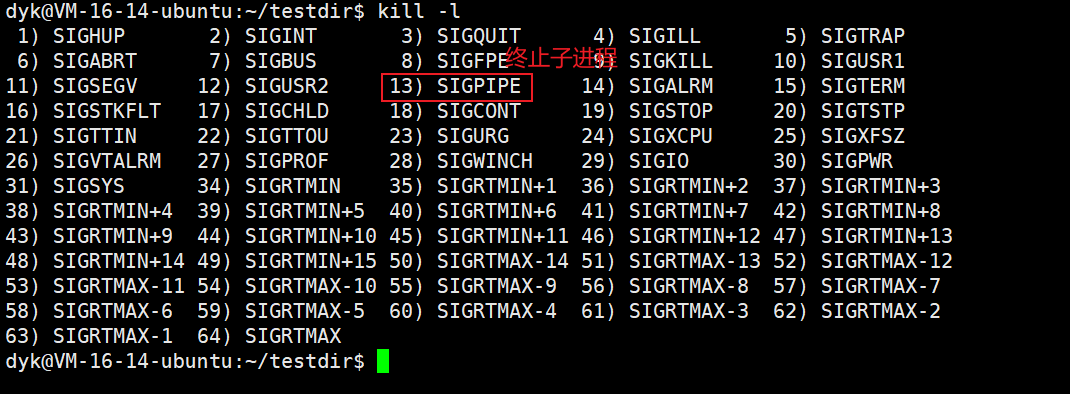
- 当读端关闭,写端会立刻终止,该操作由信号完成
我们可以通过下面的代码查看情况四种子进程退出时收到的是几号信号:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
int main()
{
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n != -1);
(void)n;
pid_t id = fork();
if (id == 0)
{
close(pipefd[0]); // 子进程关闭读端
// 子进程向管道写入数据
const char *msg = "hello father, I am child...";
int count = 10;
while (count--)
{
write(pipefd[1], msg, strlen(msg));
sleep(1);
}
close(pipefd[1]); // 子进程写入完毕,关闭写端
exit(0); // 子进程退出
}
close(pipefd[1]); // 父进程先关闭写端
close(pipefd[0]); // 父进程直接关闭读端 --> 导致子进程被操作系统杀掉
int status = 0;
waitpid(id, &status, 0);
printf("child get signal:%d\n", status & 0x7F); // 打印子进程收到的信号
return 0;
}
可以看到子进程收到的信号是13号信号,我们可以看下信号列表对应的13号信号是什么
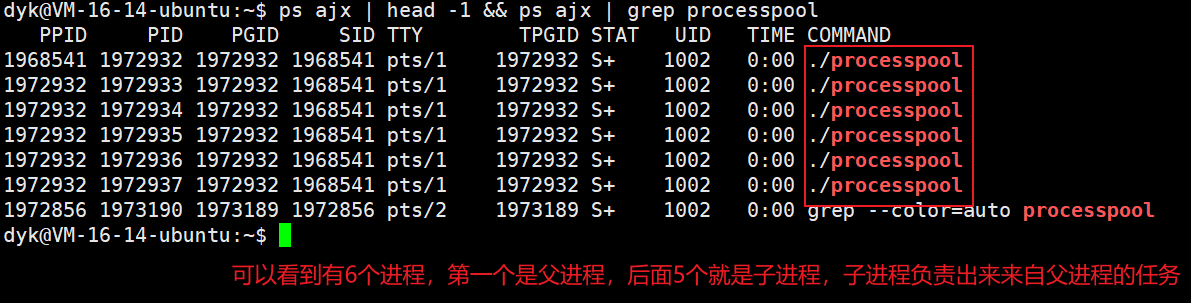
2.8 进程池
如果父进程创建若干个子进程,每一个子进程都建立对应的管道,让每一个子进程都预先放置很多处理任务的方法,父进程一共4个写端,每个写端对应一个子进程,然后父进程就可以读取用户发过来的任务,通过管道派发给子进程让它完成任务,就得到了我们的“内存池”,下面是简单的demo代码:
Task.hpp(由于网络博客还没写,只好用头文件的形式来生成任务)
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <functional>
#include <vector>
#include <unordered_map>
// typedef std::function<void()> func; 两种方法都可以
using func = std::function<void()>;
std::vector<func> callbacks;
std::unordered_map<int, std::string> desc;
void readMySQL()
{
std::cout << "sub process[" << getpid() << "]执行访问数据库的任务" << std::endl;
}
void execuleUrl()
{
std::cout << "sub process[" << getpid() << "]执行url解析的任务"
<< std::endl;
}
void cal()
{
std::cout << "sub process[" << getpid() << "]执行加密的任务" << std::endl;
}
void save()
{
std::cout << "sub process[" << getpid() << "]执行数据持久化的任务" << std::endl;
}
void load()
{
desc.insert({callbacks.size(), "readMySQL: 读取数据库"});
callbacks.push_back(readMySQL);
desc.insert({callbacks.size(), "execuleUrl: 进行url解析"});
callbacks.push_back(execuleUrl);
desc.insert({callbacks.size(), "cal: 进行加密计算"});
callbacks.push_back(cal);
desc.insert({callbacks.size(), "save: 进行数据的文件保存"});
callbacks.push_back(save);
}
void showHandler() // 查看任务列表
{
for (const auto &iter : desc)
{
std::cout << iter.first << "\t" << iter.second << std::endl;
}
}
int handleSize() // 一共有多少个处理方法
{
return callbacks.size();
}
ProcessPool.cc
#include <iostream>
#include <unistd.h>
#include <cstdlib>
#include <ctime>
#include <sys/wait.h>
#include <sys/types.h>
#include <assert.h>
#include <vector>
#include "Task.hpp"
using namespace std;
#define PRCOESS_NUM 5 // 表示要创建进程的个数
int waitCommand(int waitFD, bool &quit) // 如果对方不发,我们就阻塞
{
uint32_t command = 0;
ssize_t s = read(waitFD, &command, sizeof(command));
if (s == 0)
{
quit = true;
return -1;
}
assert(s == sizeof(uint32_t));
return command;
}
void sendAndWakeup(pid_t who, int fd, uint32_t command)
{
write(fd, &command, sizeof(command));
cout << "main process: call process" << who << "execute" << desc[command] << "through"
<< fd << endl;
}
int main()
{
load(); // 加载任务列表
vector<pair<pid_t, int>> slots; // 放的是pid和pipefd,子进程的信息
// 先创建多个进程
int i = 0;
for (i = 0; i < PRCOESS_NUM; i++)
{
// 创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n == 0);
(void)n;
// 创建多个进程
pid_t id = fork();
assert(id != -1);
if (id == 0) // 子进程
{
// 让子进程进行读取,子进程关闭读端pipefd[1]
close(pipefd[1]);
while (true)
{
bool quit = false;
// 等命令
int command = waitCommand(pipefd[0], quit); // 等待命令,如果对方不屑,我们就阻塞
if (quit)
break;
// 执行对应的命令
if (command >= 0 && command < handleSize())
{
callbacks[command](); // 接受服务器发过来的command来执行command对应的方法
}
else
{
cout << "command error" << endl;
}
}
exit(1);
}
// 父进程进行写入,关闭读端pipefd[0]
close(pipefd[0]);
slots.push_back(pair<pid_t, int>(id, pipefd[1])); //
}
// 父进程派发任务(单机版的负载均衡:随机)
srand((unsigned int)time(nullptr) ^ getpid() ^ 23323123123L); // 让随机数数据源更随机
while (true)
{
// 要是不想让人操作而让系统自动做,就只执行下面四条语句就OK了,后面while的全部注释掉
// 如果要想人操作就反过来
int command = rand() % handleSize(); // 选择任务
int choice = rand() % slots.size(); // 选择进程
sendAndWakeup(slots[choice].first, slots[choice].second, command); // 派发任务
sleep(1);
// int select = 0;
// int command = 0;
// cout << "############################################" << endl;
// cout << "### 1.show functions 2.send command ###" << endl;
// cout << "############################################" << endl;
// cout << "Please Select> ";
// cin >> select;
// if (select == 1)
// showHandler();
// else if (select == 2)
// {
// cout << "Enter Your command>";
////选择任务
// cin >> command;
////选择进程
// int choice = rand() % slots.size();
////布置任务,把任务给指定的进程
// sendAndWakeup(slots[choice].first, slots[choice].second, command);
// }
// else
// {
// }
}
// 关闭fd,结束所有进程
for (const auto slot : slots)
{
close(slot.second);
}
// 回收所有的子进程信息
for (const auto slot : slots)
{
waitpid(slot.first, nullptr, 0);
}
}
三,命名管道
3.1 关于命名管道
①匿名管道局限于父子进程之间,而且匿名管道文件输入内存级文件,进程退出后也就销毁了。那么,如何实现两个没有血缘关系的进程之间的通信呢?
②我们可以直接用文件来完成两个毫不相关进程间的通信。假设我们用普通文件进行两个进程间通信,A进程只往文件里写数据,B进程只读,这样也可以完成两个进程间的通信;但是,当AB进程退出后,系统会将缓冲区的数据刷新到磁盘上,如果这样搞效率就会非常低。
③命名管道文件是一种特殊类型的文件,改文件类型为“p”,有自己的文件名和各种属性,可以被多个进程同时打开,但是没有文件内容,也不会刷新数据到磁盘,而且该文件一定在系统路径中,而且路径也具有唯一性,双方进程就都可以通过绝对路径,同时访问该文件
3.2 mkfifo命令创建命名管道
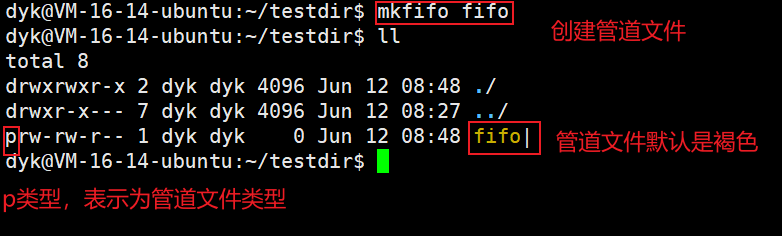
在Ubuntu环境下,fifo文件也有一个 ‘ | ’ ,这玩意儿不就是我们之前用过的“管道”吗?是不是我们也可以像用管道那样用这个文件呢?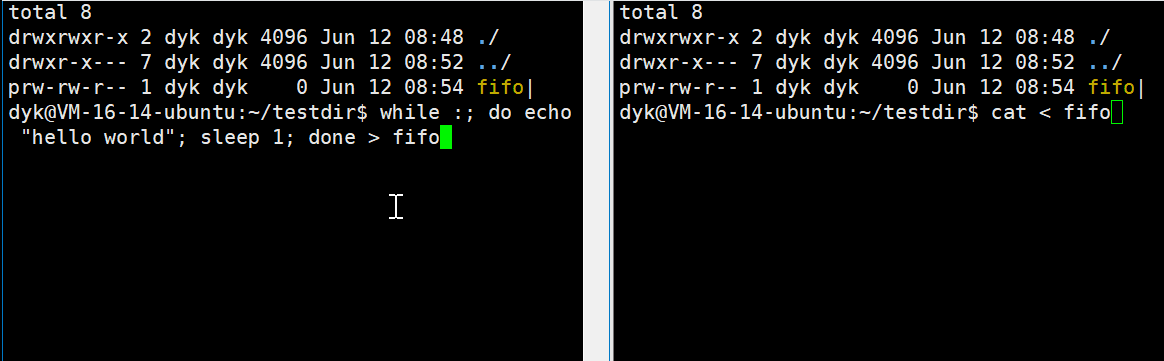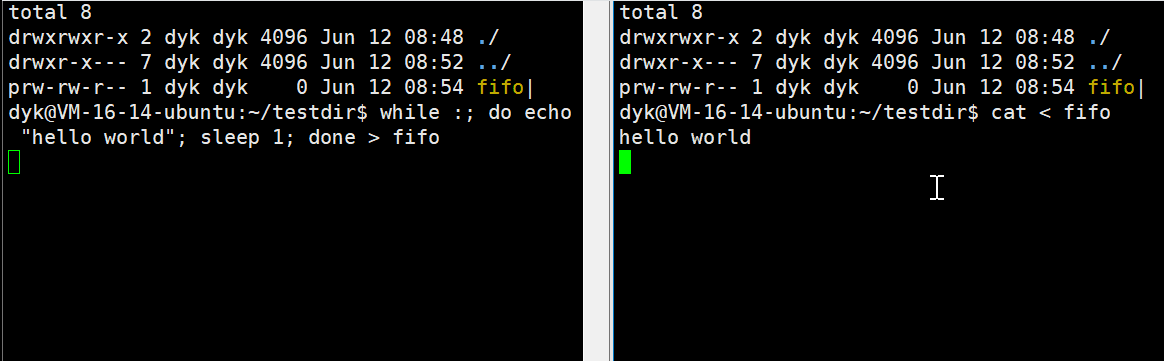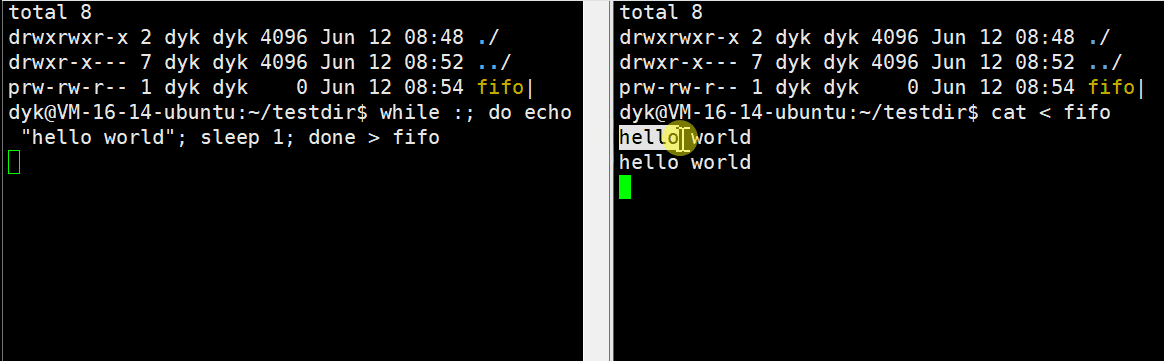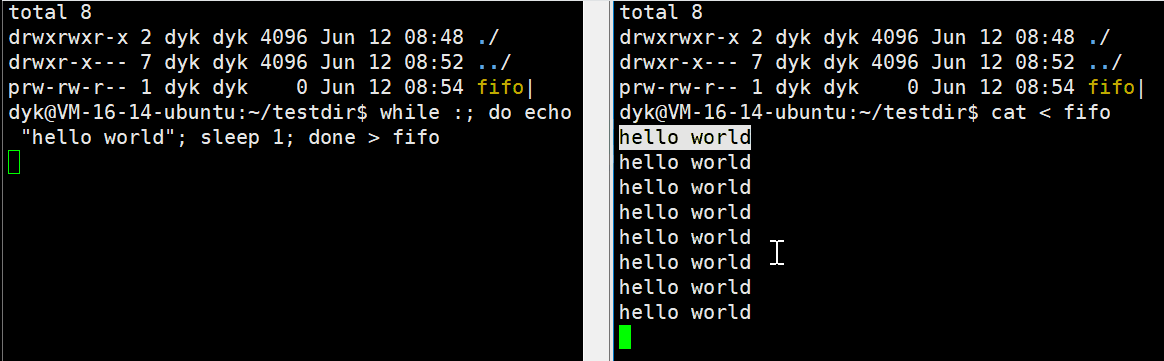
我们使用脚本循环,每一秒往管道文件重定向一个“hello world”字符串,然后再另一个窗口通过cat命令从管道中进行读取,Linux上的各种命令其实也都是可执行程序,所以上面的现象说明了,命名管道可以实现两个不想干进程间的通信。
3.3 mkfifo系统接口创建命名管道
除了mkfifo命令可以创建管道文件,我们也可以在代码中使用对应的接口创建管道文件
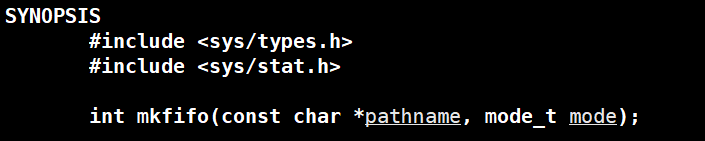
man 3 mkfifo
1,第一个参数pathname以路径的方式给出,将命名管道文件创建在pathname路径下,若pathname以文件名方式给出,则默认创建当前路径下。
2,第二个参数mode则表示创建文件的权限值,老朋友了,同样的野兽umask的影响,创建出来的文件的权限为:mode&(~umask)。
3,如果创建管道文件成功,则返回值返回0,失败返回-1
如下代码:
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
int main()
{
umask(0);
int i = mkfifo("myfifo", 0666);
if (i < 0)
{
perror("mkfifo");
return 1;
}
return 0;
}
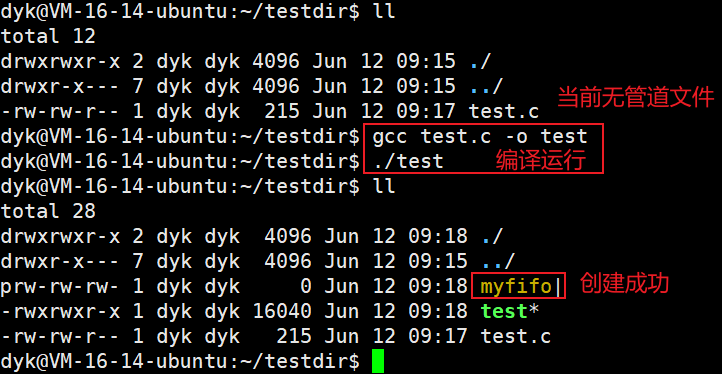
3.4 使用命名管道实现server和client通信
公共头文件
comm.hpp
包含服务端和客户端代码可能会用到的头文件
#ifndef _COMM_H_
#define _COMM_H_
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstdio>
#include <cstring>
#include <unistd.h>
#include "Log.hpp"
using namespace std;
#define MODE 0666
#define SIZE 1024
string ipcPath = "./fifo.ipc";
#endif
Log.hpp
往屏幕输出具体的进程信息,也可以将信息写入日志文件
// 输出日志信息
#ifndef LOG_H_
#define _LOG_H_
#include <iostream>
#include <ctime>
#include <string>
#define Debug 0
#define Notice 1
#define Warning 2
#define Error 3
const std::string msg[] = {
"Debug",
"Notice",
"Warning",
"Error"};
std::ostream &Log(std::string message, int level)
{
std::cout << " | " << (unsigned)time(nullptr) << " | " << msg[level] << " | " << message;
return std::cout;
}
#endifmakefile
.PHONY:all
all:client mutiServer
client:client.cc
g++ -o $@ $^ -std=c++11
mutiServer:server.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f client mutiServer
服务端代码
现代绝大多数网络服务都是以“客户端”和“服务端”的形式,在后面的网络代码中我们会大量使用客户端和服务端的形式。
服务端的任务主要有四个:创建管道文件,打开管道文件,关闭管道文件,删除管道文件。首先服务端代码先运行,创建命名管道文件,然后当客户端运行时,与服务端代码访问到同一个管道文件,于是需要打开管道文件;当客户端退出时,服务器自然也要关闭管道文件,接着删除管道文件
如下代码:
#include "comm.hpp"
int main()
{
// 1,创建管道文件
if (mkfifo(ipcPath.c_str(), MODE) < 0) // 如果小于0就代表创建失败
{
perror("mkfifio");
exit(1);
}
Log("创建管道文件成功 ", Debug) << " step 1 " << endl;
// 2,正常的文件操作
int fd = open(ipcPath.c_str(), O_RDONLY);
if (fd < 0)
{
perror("open");
exit(2);
}
Log("打开管道文件成功 ", Debug) << " step 2 " << endl;
// 3,编写正常的通信代码
char buffer[SIZE];
while (true)
{
memset(buffer, '\0', sizeof(buffer)); // 清空缓冲区
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if (s > 0) //读取成功
{
cout << "client say: " << buffer << endl;
}
else if (s == 0) // 数据读完了
{
cerr << "read is done, client quit, server quit too" << endl;
break;
}
else // 读取错误
{
perror("read");
break;
}
}
// 4,关闭文件
close(fd);
Log("关闭管道文件成功 ", Debug) << " step 3 " << endl;
unlink(ipcPath.c_str()); // 通信完毕,就删除文件
Log("删除管道文件成功 ", Debug) << " step 4 " << endl;
return 0;
}客户端代码和效果演示
服务端创建管道进程,那么客户端只需要以写的方式打开该命名文件即可,之后客户端就可以将信息写入到命名管道文件中,就可以实现和服务端的通信,如下代码:
#include "comm.hpp"
int main()
{
// 1,获取管道文件
int fd = open(ipcPath.c_str(), O_WRONLY);
if (fd < 0)
{
perror("open");
exit(1);
}
// 2,通信过程
string buffer;
while (true)
{
cout << "Please Enter Message Line: ";
getline(cin, buffer); // 从cin里获取一行数据读到buffer里
write(fd, buffer.c_str(), buffer.size()); // 把buffer里面的数据写到fd里面,写buffer.size()个数据
}
// 3,关闭文件
close(fd);
return 0;
}演示如下Gif:
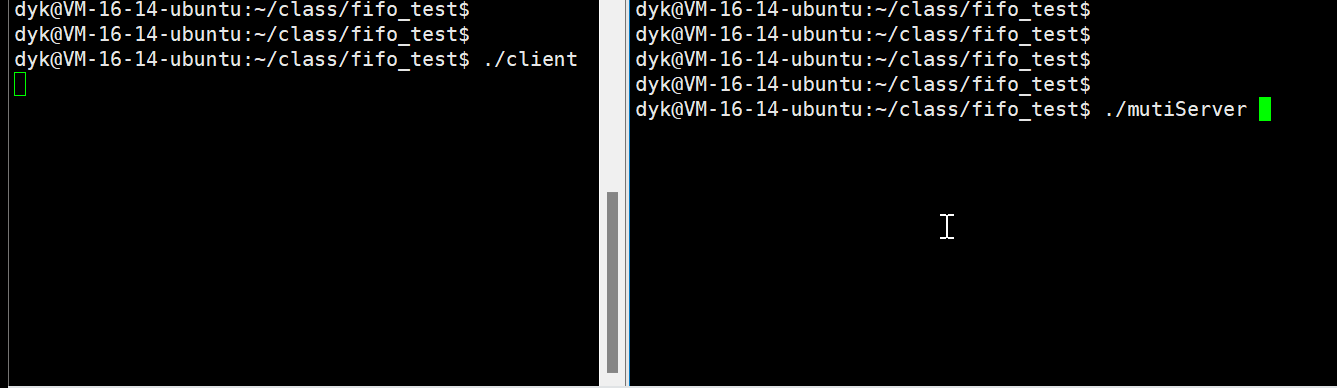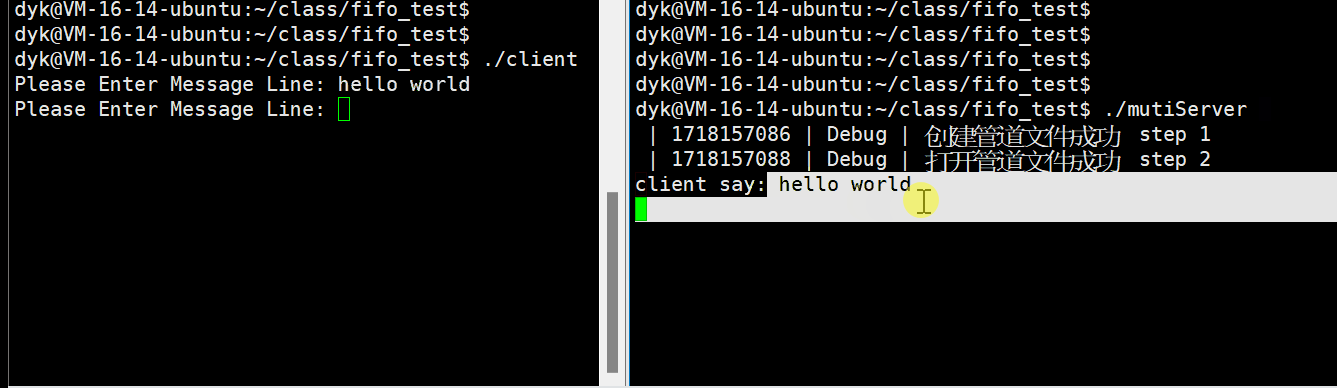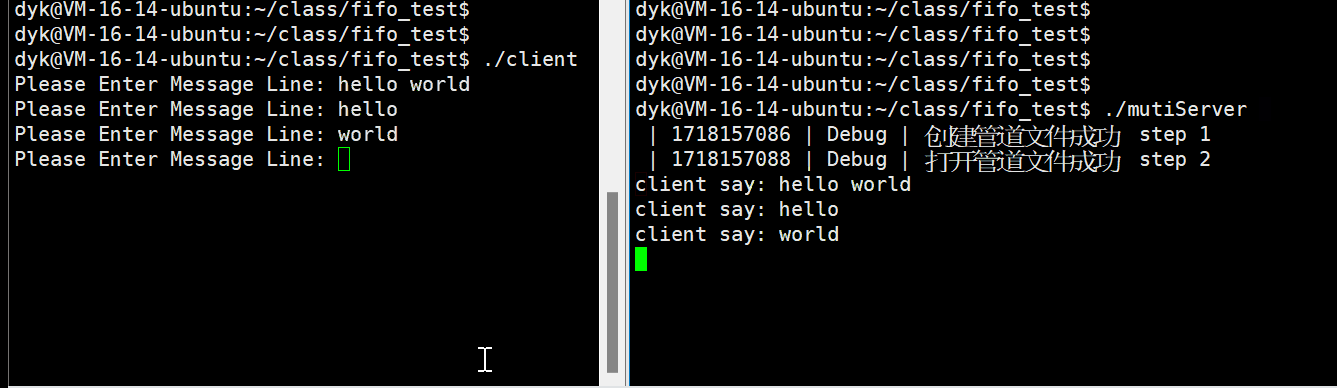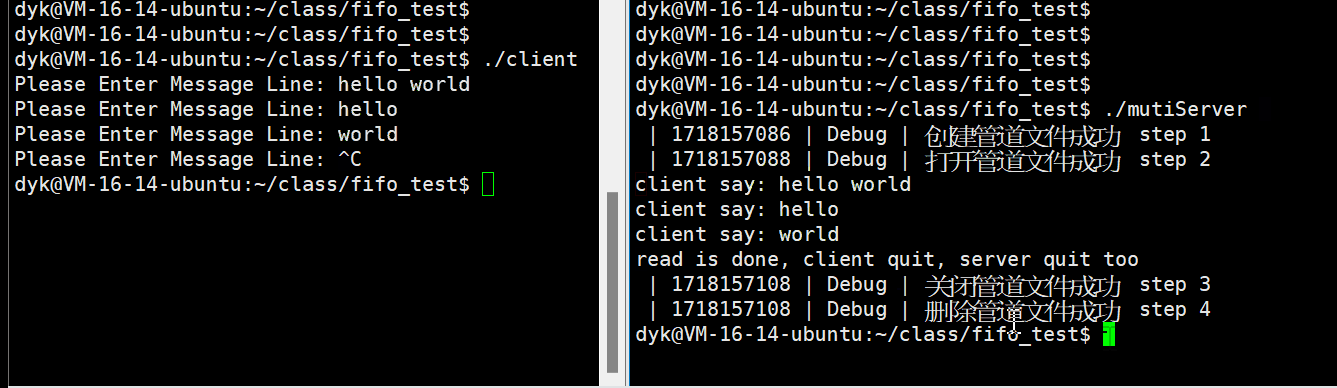
服务端代码优化后演示
我们以后编写服务端代码时,其实很少是直接让服务端执行任务的,绝大多数情况下都是让服务端生成子进程或者线程,让子进程或线程去处理事务,原因大家应该都清楚哈,不管我们到线程部分会细讲,如下代码:我直接在服务端创建三个子进程,让子进程执行打印任务:
#include "comm.hpp"
#include <sys/wait.h>
static void getMessage(int fd)
{
char buffer[SIZE];
while (true)
{
memset(buffer, '\0', sizeof(buffer));
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if (s > 0)
{
cout << "[" << getpid() << "] "
<< "client say> " << buffer << endl;
}
else if (s == 0)
{
// end of file
cerr << "[" << getpid() << "] "
<< "read end of file, clien quit, server quit too!" << endl;
break;
}
else
{
// read error
perror("read");
break;
}
}
}
int main()
{
// 1,创建管道文件
if (mkfifo(ipcPath.c_str(), MODE) < 0) // 如果小于0就代表创建失败
{
perror("mkfifio");
exit(1);
}
Log("创建管道文件成功 ", Debug) << " step 1 " << endl;
// 2,正常的文件操作
int fd = open(ipcPath.c_str(), O_RDONLY);
if (fd < 0)
{
perror("open");
exit(2);
}
Log("打开管道文件成功 ", Debug) << " step 2 " << endl;
int nums = 3, i = 0;
for (i = 0; i < nums; i++)
{
pid_t id = fork();
if (id == 0)
{
// 3. 编写正常的通信代码了
getMessage(fd);
exit(1);
}
}
for (int i = 0; i < nums; i++)
{
waitpid(-1, nullptr, 0);
}
// 4,关闭文件
close(fd);
Log("关闭管道文件成功 ", Debug) << " step 3 " << endl;
unlink(ipcPath.c_str()); // 通信完毕,就删除文件
Log("删除管道文件成功 ", Debug) << " step 4 " << endl;
return 0;
}演示如下:
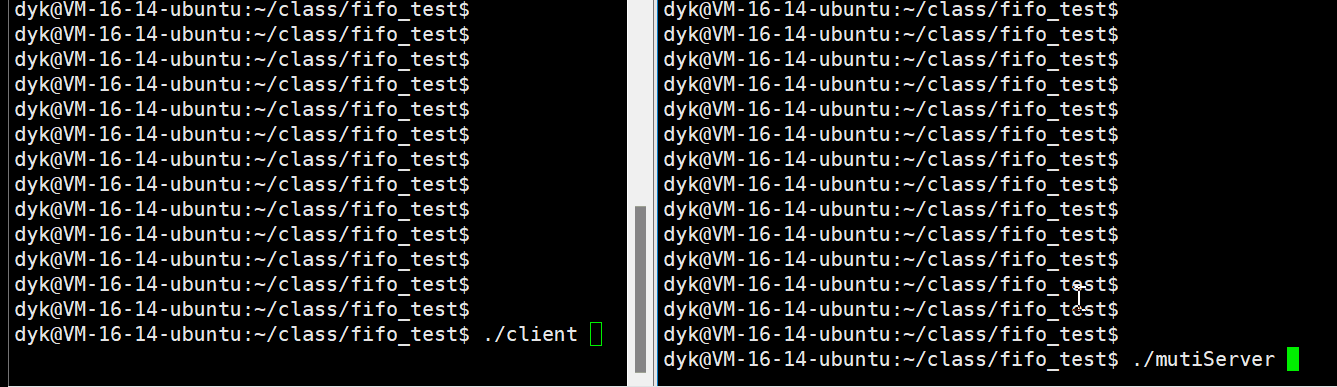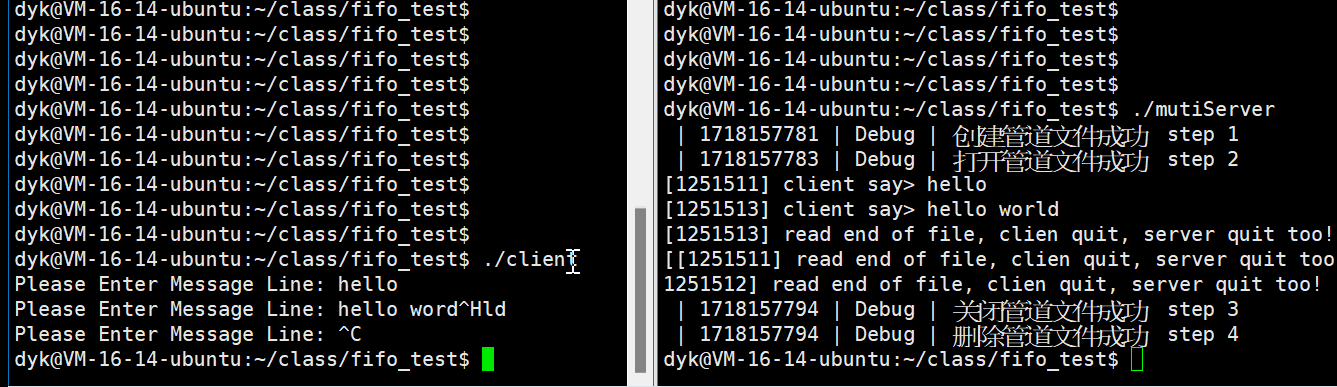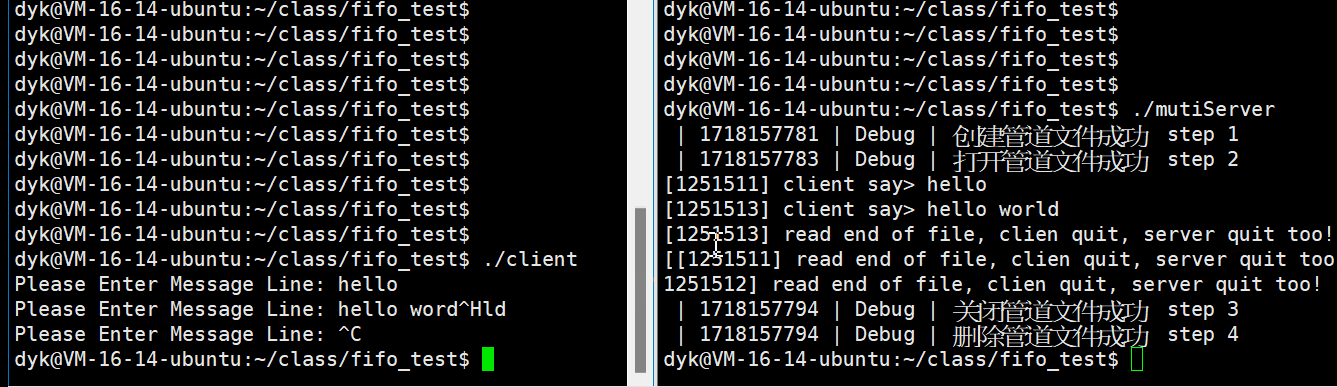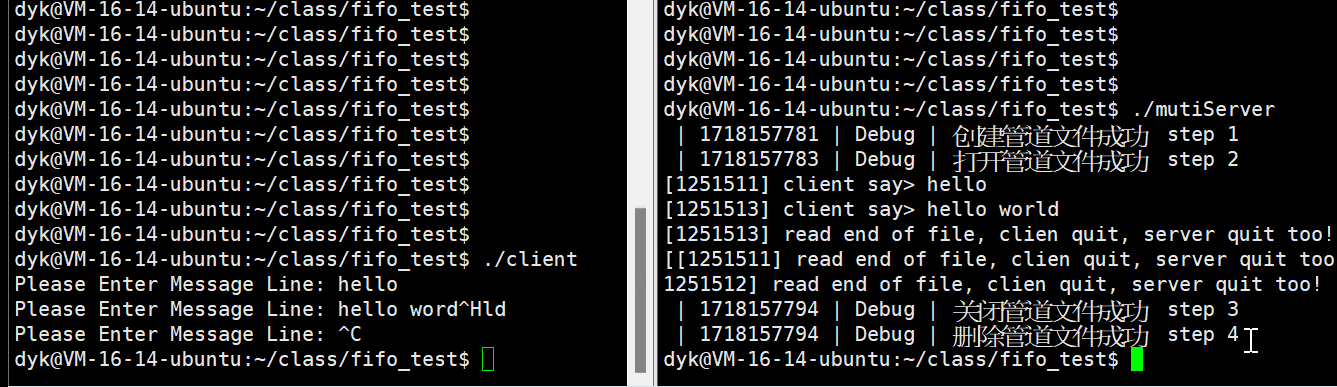
客户端对服务端发命令
其实服务端收到的就是客户端发来的一个字符串,我们可以利用我们进程控制章节的“进程替换”,来实现客户端往服务端发送命令,只需要改变下服务端代码即可,由于是简单实现,只支持无参数命令,例如ls,pwd,whoami等,如下服务端代码:
#include "comm.hpp"
#include <sys/wait.h>
int main()
{
umask(0);
if (mkfifo(ipcPath.c_str(), 0666) < 0)
{
perror("mkfifo");
return 1;
}
int fd = open(ipcPath.c_str(), O_RDONLY); // 以读的方式打开命名管道文件
if (fd < 0)
{
perror("open");
return 2;
}
char buffer[SIZE];
while (1)
{
memset(buffer, '\0', sizeof(buffer)); // 清空缓冲区
// 从命名管道当中读取信息
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if (s > 0)
{
buffer[s] = '\0'; // 手动设置'\0',便于输出
printf("client# %s\n", buffer);
if (fork() == 0)
{
// child
execlp(buffer, buffer, NULL); // 进程程序替换
exit(1);
}
waitpid(-1, NULL, 0); // 等待子进程
}
else if (s == 0)
{
printf("client quit!\n");
break;
}
else
{
printf("read error!\n");
break;
}
}
close(fd); // 通信完毕,关闭命名管道文件
return 0;
}
四,管道特点
①管道内部自带同步互斥机制
1,我们将同一时间只允许一个进程访问的资源称为“临界资源”。而管道在同一时刻只允许一个进程对其进行写入或者是读取操作,所以管道文件是临界资源。
2,而临界资源是需要被保护的,如果不对其进行保护,就会导致多个进程同时对管道文件写,就会导致数据不一致 问题,这个问题对操作系统来说是致命的,所以在设计管道的时候给其加了同步与互斥
3,同步:两个或两个以上的进程在运行过程中协同步调,即按照预定的先后顺序运行。
4,互斥:一个临界资源同一时刻只能允许一个进程访问
②管道具有访问控制机制
实际上同步是一种更复杂的互斥,互斥也是一种特殊的同步。对于管道来说,互斥就是必须等一个进程对其写入完成,另一个才能写
③管道通信是一种面向字节流的通信
在计算机网络中的数据通信有两种:面向字节流和面向数据报。
面向字节流:在管道文件看来,它不管你写入的是什么数据,数字,字符,甚至二进制,管道都不管,统一识别成“字节数据”,因为管道的任务只是完成数据的交换,不参与任何的数据处理等任务。网络协议的TCP就是一种面向字节流的网络协议,我们以后再讲
面向数据报:在网络中,数据的发送都是通过把“报头”和“有效载荷”搞在一起,形成报文,然后进行发送,面向数据报就是报文与报文之间有明确的分割,比如UDP协议采用的是定长报文,所以UDP协议是一种面向数据包的协议,我们以后再讲
④管道生命周期随进程
管道文件也是文件,所以依赖于文件系统,那么打开文件的进程退出后,对应的文件数据也会被释放,所以说管道的生命周期随进程
⑤管道是半双工通信
单工通信(Simplex Communication):表示数据通信是单向,固定一方发送一方接收,很明显管道通信不是单工通信
半双工通信(Half Duplex):表示数据传输可以在一个信号载体的两个方向上传输,但是不能同时传输
全双工通信(Full Duplex):表示允许数据在两个方向上同时传输,相当于两个单工通信的结合,实现双向传输,Tcp协议就是采用的全双工通信,在面试题中,Tcp三次握手的意义之一就是“验证全双工”
五,System V 共享内存
5.1 关于System V 进程间通信
管道通信是基于文件的,所以这种通信方式只是稍微利用了下文件的特性,并没有做很多其它的设计工作。而System V IPC 是操作系统特地设计的一种晋察间通信方式,本质是一样的,就是要让不同的进程看到同一份资源。System V IPC 提供的通信方式有下面三种:
- System V 共享内存
- System V 消息队列
- System V 信号量
其中System V 共享内存和System V 消息队列是以传输数据为目的,System V 信号量是为了包子进程间的同步与互斥而设计的,与通信没有直接关系,但也属于通信范畴。
5.2 关于System V 共享内存
在进程地址空间中,堆栈是相对而生的,但堆栈中间有一块区域,这块区域叫做共享区,共享内存是通过在物理内存中申请一块共享内存空间,然后将这块内存空间分别与各个进程各自的页表建立映射,然后将这块共享内存空间映射到每个进程的共享区,这样就能让多个进程看到同一份物理内存,如下图:
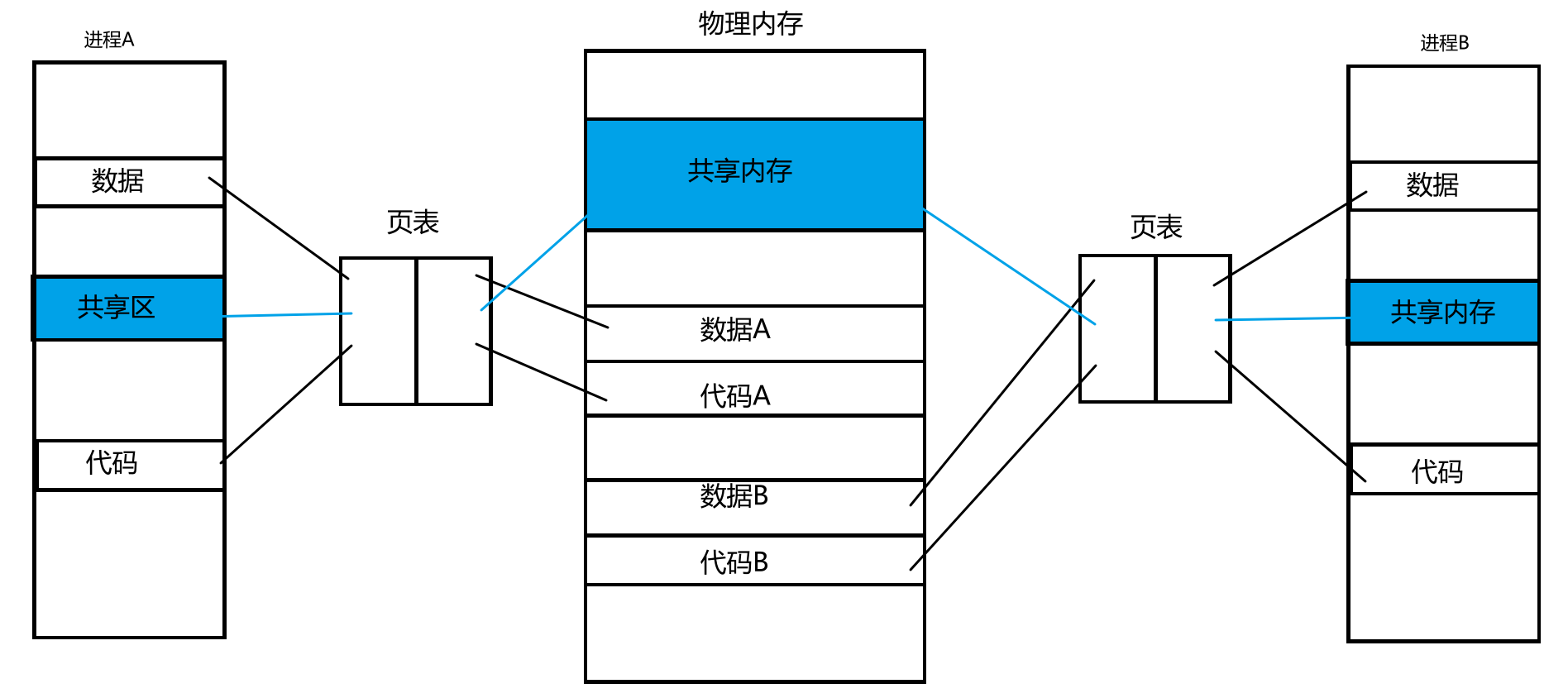
共享内存原理:
①上次介绍共享区的时候是在动态库那里,动态库从磁盘加载到内存,动态库里面的地址采用的是相对地址,当动态库加载到内存通过页表映射到各个进程对应的地址空间的时候,可能被映射到了每个进程的不同位置,但不重要,因为用的是偏移量,所以我们的程序在链接的时候,里面填写的就是自己要调用的函数在库中的偏移量,所以将来我们只要找到了库在地址空间当中所加载的虚拟地址的起始地址,然后访问库函数时直接拿着我们自己代码中偏移量加上库的起始地址,就可以找到库当中的代码。
②库一开始也是要加载到物理内存里才能被映射到进程里的,那么如果OS自己申请一块物理空间,然后将这一部分空间经过每一个进程的页表映射到对应进程的虚拟空间然后返回起始地址,这样的话,两个或者多个进程就都可以通过各自的虚拟地址“共同”访问OS申请的这一块物理内存,进程通信的前提条件成立,我们把这种工作方式叫做:共享内存
③共享内存属于用户空间,也就是不用经过系统调用,直接可以访问,双方进程如果要通信,直接进行内存级的读和写即可。而且释放时也只需要断开各个进程与共享内存的映射关系,然后再释放物理内存就完成了释放。
5.3 共享内存数据结构
在系统中也一定会有大量的进程在进行通信,因此系统中肯定会存在大量的共享内粗你,所以操作系统需要将这些共享内存“先描述,再组织”管理起来,描述维护共享内存的数据结构如下:
vim /usr/include/linux/shm.hstruct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_old_time_t shm_atime; /* last attach time */
__kernel_old_time_t shm_dtime; /* last detach time */
__kernel_old_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
为了保证通信的进程能够看到同一个共享内存,因此每一个共享内存被申请时都会有一个唯一的Key值,用来标识该共享内存的唯一性,上面的第一个成员shm_perm的类型是ipc_perm结构体,key值就存在这个结构体里,如下代码:
vim /usr/include/linux/ipc.hstruct ipc_perm
{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
所以:共享内存 = 共享内存快 + 对应的共享内存的内核数据结构,当我们申请4096大小的共享内存, 操作系统开辟的绝对大于4096字节。
5.4 shmget函数与ftok函数
创建共享内存我们需要用到shmget函数,如下图:

①第一个参数key:表示即将创建的共享内存在系统中的唯一标识,该参数由ftok函数生成,后面讲
②第二个参数size:表示共享内存大小
③第三个参数shmflg:表示创建共享内存方式,有多个参数,后面讲
④返回值:如果创建成功,返回一个共享内存标识符,如果失败,返回-1
然后我们来详细讲讲第一个参数key:
当一个进程把共享内存创建好了,那么要通信的对方进程怎么保证对方能看到并且看到的就是我创建的共享内存呢?
两把钥匙可以打开同一把锁,所以通过key来找 --> key的数值不重要,只要能在系统中唯一存在 --> 两个进程使用同一个key --> 只要key值相同,就是看到了同一个共享内存
假设server创建了一个共享内存,通过特定算法生成一串数字假设为1234,那么给这段内存取名为1234,然后进程client也运行起来了,然后采用和server一样的算法就可以生成和server一样的数字,也就可以找到共享内存了。在代码中key的值由ftok函数生成,如下图:

ftok函数作用就是讲一个已经存在路径名pathname和一个整数标识符proj_id转换成一个key值,称为IPC键值,在使用shmget函数创建共享内存时,这个key就会被填充进共享内存的数据结构中
再然后我们来详细讲讲第三个参数shmflg:
该参数有两个选项:IPC_CREAT 和 IPC_EXCL,有以下几个注意事项:
- 如果单独使用IPC_CREAT,表示创建共享内存,但是如果底层已经有工像内存存在,则获取它的编号并返回,如果不存在,创建一个并返回编号
- 单独使用第二个IPC_EXCL无意义
- IPC_CREAD | IPC_EXCL,就和open接口一样的参数异或传递方式同时使用两个选项,这样传递参数之后,如果底层无共享内存,则创建共享内存;但是,如果底层存在共享内存,则会返回错误,这是为了保证返回的时候一定是一个全新的共享内存
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/dyk/testdir/test.c" // 路径名
#define PROJ_ID 0x6666 // 整数标识符
#define SIZE 4096 // 共享内存的大小
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); // 获取key值
if (key < 0)
{
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL); // 创建新的共享内存
if (shm < 0)
{
perror("shmget");
return 2;
}
printf("key: %x\n", key); // 打印key值
printf("shm: %d\n", shm); // 打印编号
return 0;
}
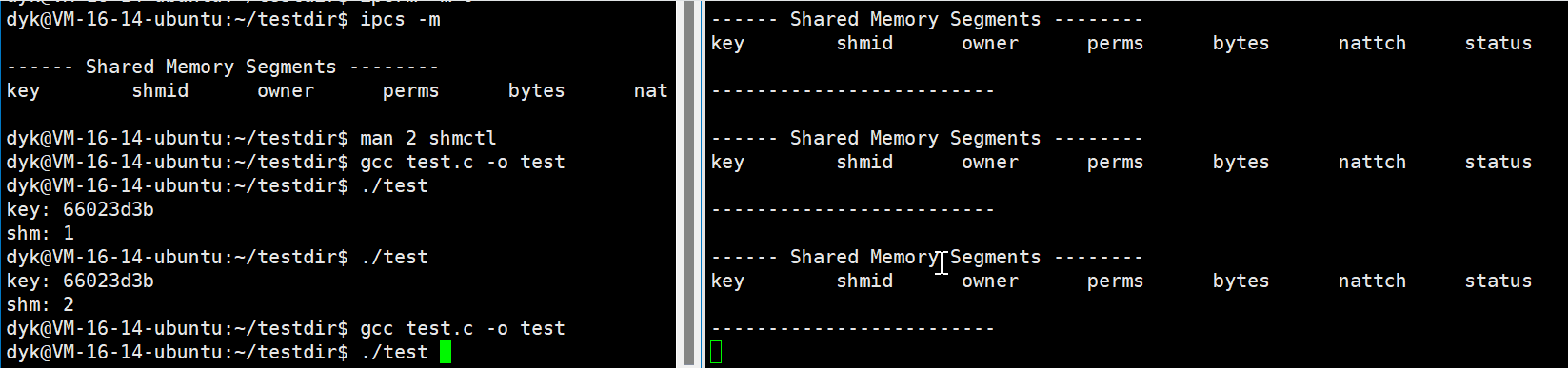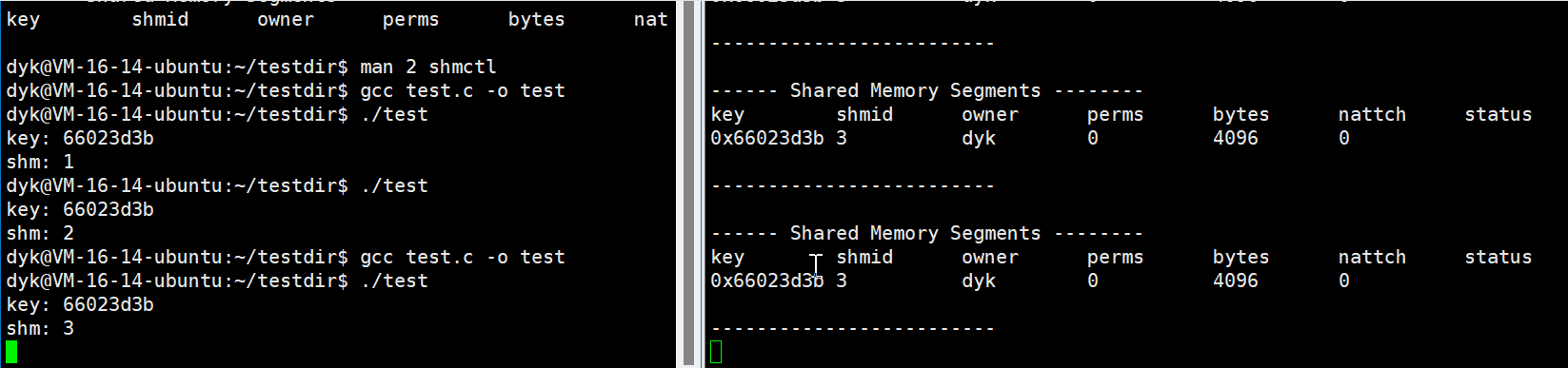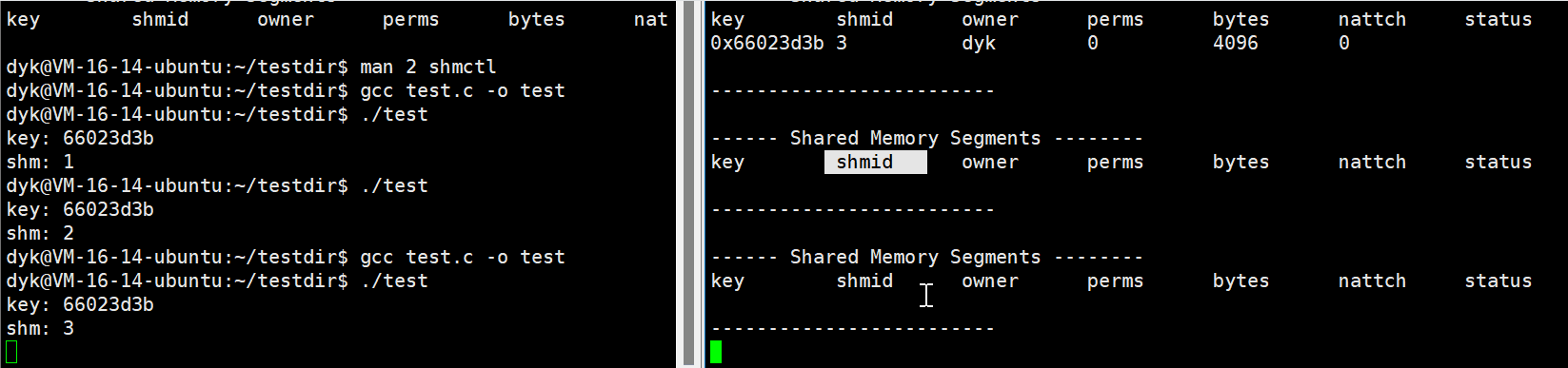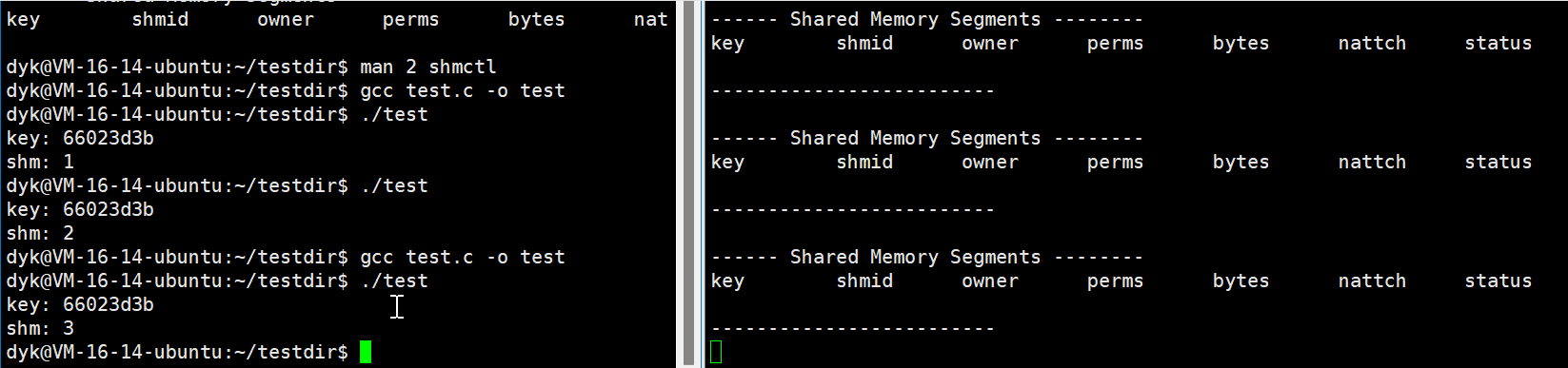
 5.5 ipcs命令查看共享内存
5.5 ipcs命令查看共享内存
ipcs命令是用来查看有关进程间通信载体的信息的:
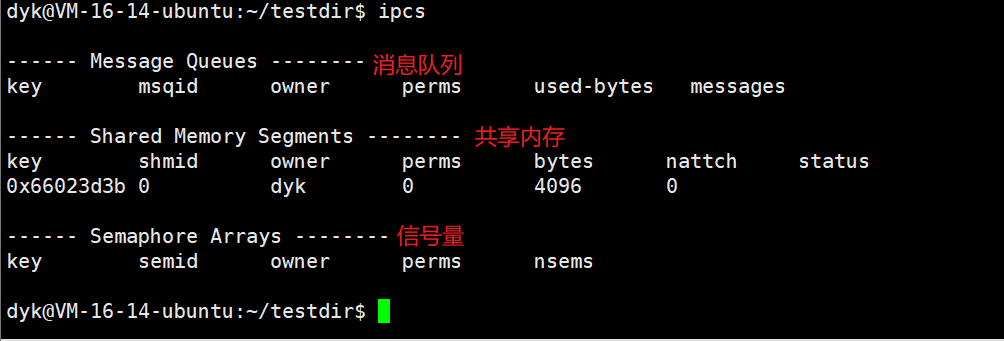
当不用选项时,默认三个都显示,而且上面三个对应的选项为:-q,-m,-s。
我们现在只看共享内存这一条,上面也有很多参数,介绍如下:
| 标题 | 意义 |
|---|---|
| key | 表示各个共享内存的唯一标识符 |
| shmid | 共享内存的编号 |
| owner | 共享内存的拥有者 |
| perms | 共享内存权限 |
| bytes | 共享内存大小,单位bit |
| nattch | 与该共享内存关联的进程数 |
| status | 共享内存状态 |
5.6 共享内存控制函数
上面我们创建共享内存后,可以发现进程退出了但是共享内存还在,这是因为共享内存的生命周期是随操作系统的,如果不主动删除,那么共享内存将会一直存在,知道系统关机,System V IPC 的IPC资源都是如此。
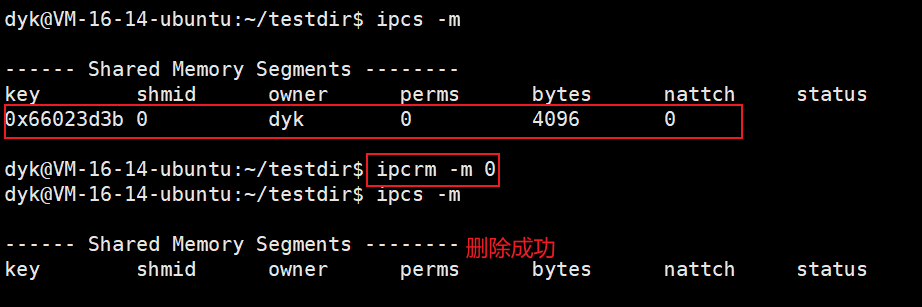
所以我们手动删除共享内存,可以通过命令删除,也可以通过代码删除。
我们先用代码删除:
删除共享内存的命令为ipcrm -m shmid,改变第二个选项也可以删除消息队列和信号量,shmid就是对应的IPC资源的编号,如下图:
然后我们用函数删除共享内存:
删除共享内存我们用到的函数是shmctl,在2号文档可以找到它:

第一个参数不多说,共享内存编号,第二个参数cmd表示具体的控制动作,第三个参数buf用于获取或设置所控制共享内存的数据结构,shmctl成功返回1,失败返回0。
第二个参数有下面三个选项:
- IPC_STAT:获取共享内存当前的关联值,此时buf参数作为输出型参数
- IPC_SET:在进程有足够权限的情况下,将共享内存的当前关联值设置为buf所致的数据结构中的值
- IPC_RMID:删除该共享内存段
所以我们直接改上面的代码,先创建共享内存,然后等待5秒后删除共享内存,如下代码和演示:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/dyk/testdir/test.c" // 路径名
#define PROJ_ID 0x6666 // 整数标识符
#define SIZE 4096 // 共享内存的大小
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); // 获取key值
if (key < 0)
{
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL); // 创建新的共享内存
if (shm < 0)
{
perror("shmget");
return 2;
}
printf("key: %x\n", key); // 打印key值
printf("shm: %d\n", shm); // 打印编号
sleep(5);
shmctl(shm, IPC_RMID, NULL); // 删除共享内存
sleep(5);
return 0;
}
while :; do ipcs -m; echo "-------------------------"; sleep 1; done
5.7 共享内存关联函数
上面单纯只是在内存中创建和删除共享内存,创建和并没有和我们进程的地址空间连接起来,所以连接地址空间需要其它的函数。连接分为建立连接和断开连接,对应的函数是shmat和shmdt
两个函数都可以在2号手册找到它们:

先介绍下shmat函数建立关联:
- 第一个参数是shmid的返回值,表示待关联共享内存编号
- 第二个参数shmaddr表示指定共享内存映射到进程地址空间的某一地址,通常为NULL,表示让内核自己设置地址位置
- 第三个参数shmflg,表示关联共享内存时设置的某些属性
- 关于返回值:如果shmat调用成功,返回共享内存映射到当前进程地址空间中的起始地址,如果调用失败,返回(void*)-1
第三个参数传入的选项有三个:
- SHM_RDONLY:关联共享内存成功后只进行读取操作
- SHM_RHD:若shmaddr不为NULL,则关联地址自动向下调整为SHMLBA的整数倍,公式为:shmaddr-(shmaddr%SHMLBA)
- 0:默认为读写权限
介绍下shmdt函数断开关联:
只有一个参数const void* shmaddr表示待去关联共享内存的起始地址,即调用shmat函数时得到的起始地址。调用成功返回0,调用失败返回1。
下面是演示这两个函数的代码,注意要使用关联函数,前面的shmget创建共享内存时有点变化,具体请看代码注释,如下代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/dyk/testdir/test.c" // 路径名
#define PROJ_ID 0x6666 // 整数标识符
#define SIZE 4096 // 共享内存的大小
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); // 获取key值
if (key < 0)
{
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666); // 创建新的共享内存
// 如果每家0666,则表示创建出来的共享内存权限默认为0,表示无任何权限,因此进程无法关联进程
// 所以创建共享内存时,将权限设置成0666即可关联该内存
if (shm < 0)
{
perror("shmget");
return 2;
}
printf("key: %x\n", key); // 打印key值
printf("shm: %d\n", shm); // 打印编号
printf("下面开始连接共享内存\n");
char *mem = shmat(shm, NULL, 0); // 关联共享内存
if (mem == (void *)-1)
{
perror("shmat");
return 3;
}
printf("连接成功\n");
sleep(3);
printf("准备断开连接\n");
shmdt(mem); // 断开连接
printf("断开成功\n");
sleep(3);
shmctl(shm, IPC_RMID, NULL); // 删除共享内存
sleep(3);
return 0;
}
while :; do ipcs -m; echo "-------------------------"; sleep 1; done
5.8 使用共享内存实现server和client通信
在知道了共享内存的创建,关联,去关联以及释放后,我们可以尝试让两个进程使用共享内存进行通信了,服务端创建共享内存,然后让客户端进行关联。
公共头文件有下面三个:
comm.hpp
#pragma once
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <cassert>
#include <fcntl.h>
#include "Log.hpp"
#include <cstring>
using namespace std;
#define PATH_NAME "/home/dyk"
#define PROJ_ID 0x66
#define SHM_SIZE 4096 // 共享内存的大小,最好是页(PAGE: 4096)的整数倍
#define FIFO_NAME "./fifo"
//
class Init
{
public:
Init()
{
umask(0);
int n = mkfifo(FIFO_NAME, 0666); // 创建管道文件
assert(n == 0);
(void)n;
Log("create fifo success", Notice) << "\n";
}
~Init()
{
unlink(FIFO_NAME); // 删除对应的文件
Log("remove fifo success", Notice) << "\n";
}
};
#define READ O_RDONLY
#define WRITE O_WRONLY
int OpenFIFO(std::string pathname, int flags)
{
int fd = open(pathname.c_str(), flags);
assert(fd >= 0);
return fd;
}
void Wait(int fd)
{
Log("server waiting....", Notice) << "\n";
uint32_t temp = 0;
ssize_t s = read(fd, &temp, sizeof(uint32_t));
assert(s == sizeof(uint32_t));
(void)s;
}
void Signal(int fd)
{
uint32_t temp = 1;
ssize_t s = write(fd, &temp, sizeof(uint32_t));
assert(s == sizeof(uint32_t));
(void)s;
Log("client writing....", Notice) << "\n";
}
void CloseFifo(int fd)
{
close(fd);
}
Log.hpp
#ifndef _LOG_H_
#define _LOG_H_
#include <iostream>
#include <ctime>
#define Debug 0
#define Notice 1
#define Warning 2
#define Error 3
const std::string msg[] = {
"Debug",
"Notice",
"Warning",
"Error"};
std::ostream &Log(std::string message, int level)
{
std::cout << " | " << (unsigned)time(nullptr) << " | " << msg[level] <<
" | " << message;
return std::cout;
}
#endifmakefile
.PHONY:all
all:shmclient shmserver
shmclient:shmClient.cc
g++ -o $@ $^ -std=c++11
shmserver:shmServer.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f shmclient shmserver
下面是服务端代码:
#include "comm.hpp"
Init init;
// RAII:每次创建进程都会加载全局变量,对象创建时自动调用构造函数生成管道文件,然后进程结束时对象调用析构函数删掉管道文件
string TransToHex(key_t k) // 转换成16进制
{
char buffer[32];
snprintf(buffer, sizeof buffer, "0x%x", k);
return buffer;
}
int main()
{
// 所有工作,都是为了让多个进程看到同一份资源(内存)
// 1. 创建公共的Key值
key_t k = ftok(PATH_NAME, PROJ_ID);
assert(k != -1);
Log("create key done", Debug) << " server key : " << k << endl;
// 2. 创建共享内存,建议创建一个全新的共享内存,因为要成为通信的发起者
int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666); // 返回共享内存的标识符
if (shmid == -1)
{
perror("shmget");
exit(1);
}
Log("create shm done", Debug) << " shmid : " << shmid << endl;
// 3. 将指定的共享内存,挂接到自己的地址空间
char *shmaddr = (char *)shmat(shmid, nullptr, 0); // 得到挂接的共享内存的起始地址
Log("attach shm done", Debug) << " shmid : " << shmid << endl;
// 4,开始通信
// for(;;)
// {
// printf("%s\n", shmaddr);
// if(strcmp(shmaddr, "quit") == 0) break; //如果客户端写了个quit就退出
// sleep(1);
// }
int fd = OpenFIFO(FIFO_NAME, READ);
for (;;)
{
Wait(fd); // 等待客户端发数据来
printf("%s\n", shmaddr);
if (strcmp(shmaddr, "quit") == 0)
break; // 如果客户端写了个quit就退出
}
// 4. 将指定的共享内存,从自己的地址空间中去关联
int n = shmdt(shmaddr);
assert(n != -1);
(void)n;
Log("detach shm done", Debug) << " shmid : " << shmid << endl;
// 5. 删除共享内存,IPC_RMID即便是有进程和当下的shm挂接,依旧删
n = shmctl(shmid, IPC_RMID, nullptr);
assert(n != -1);
(void)n;
Log("delete shm done", Debug) << " shmid : " << shmid << endl;
return 0;
}
下面是客户端代码:
#include "comm.hpp"
int main()
{
Log("chile pid: ", Debug) << getpid() << endl;
key_t k = ftok(PATH_NAME, PROJ_ID);
if (k < 0)
{
Log("create key failed", Error) << " client key : " << k << endl;
exit(1);
}
Log("create key done", Debug) << " client key : " << k << endl;
// 获取共享内存
int shmid = shmget(k, SHM_SIZE, 0);
if (shmid < 0)
{
Log("create shm failed", Error) << " client key : " << k << endl;
exit(2);
}
Log("create shm success", Error) << " client key : " << k << endl;
// 挂接
char *shmaddr = (char *)shmat(shmid, nullptr, 0);
if (shmaddr == nullptr)
{
Log("attach shm failed", Error) << " client key : " << k << endl;
exit(3);
}
Log("attach shm success", Error) << " client key : " << k << endl;
// 使用
// 将共享内存看作一个很大的char类型的char biffer[SUM_SIZE]
// char a = 'a';
// for(; a <= 'z'; a++)
// {
// shmaddr[a-'a'] = a;
// snprintf(shmaddr, SHM_SIZE - 1, "hello server, 我是其他进程,pid:%d,inc:%c\n",getpid(), a); //作用是将数据搞到字符串里,每一次都向shmaddr写入
// sleep(5);
// }
// strcpy(shmaddr, "quit");
// 结论1:只要通信双方使用shm,一方直接向共享内存中写入数据,另一方能立马看到对方写的数据
// 共享内存是所有进程间通信(IPC),速度最快的,因为不需要将数据反复拷贝,不需要将数据交给OS处理
// while(true) //实现键盘写入到缓冲区
// {
// ssize_t s = read(0, shmaddr, SHM_SIZE - 1);
// if(s > 0)
// {
// shmaddr[s - 1] = 0; ///-1为了去掉回车
// if(strcmp(shmaddr, "quit") == 0) break;
// }
// }
// 结论2:共享内存无访问控制,会带来并发问题(数据不一致问题)
// 问题:如果我想进行一定的访问控制呢?
// 接下来就是实现一定的访问控制,我让你读的时候你再读
int fd = OpenFIFO(FIFO_NAME, WRITE); // 打开管道文件,当我写数据时,利用管道告诉服务端
while (true)
{
printf("Pleasr write your data >> ");
fflush(stdout);
ssize_t s = read(0, shmaddr, SHM_SIZE - 1);
if (s > 0)
{
shmaddr[s - 1] = 0;
Signal(fd); // 向管道发数据,“告诉”服务端我写数据了
if (strcmp(shmaddr, "quit") == 0)
break;
}
}
CloseFifo(fd);
// 去关联
int n = shmdt(shmaddr);
assert(n != -1);
Log("detach shm success", Error) << " client key : " << k << endl;
// client 要不要chmctl删除呢?不需要!!
return 0;
}
下面是效果演示:

下面是对上面代码的文字说明:
①首先服务端先启动,创建管道文件和共享内存,然后服务端连接上共享内存,进入死循环等待读取数据
②然后客户端启动,根据key值关联到同一个共享内存,然后开始写数据
③暗当客户端写一个数据后,通过管道告诉服务器我客户端已经写数据了,让服务端赶紧来读,达到访问控制的目的
④当客户端输入quit时,客户端退出死循环,断开与管道和共享内存的连接
⑤然后服务端收到quit,也退出死循环,然后释放管道文件,然后通过RAII删除管道文件,完成逻辑
5.9 共享内存和管道的区别
①相较于管道,共享内存其实是一种速度极快的通信方式,它不需要调用read,write等文件接口,所以减少了拷贝
②但是共享内存也有缺点,比如我们创建使用和释放共享内存的工作量比管道大了不少,而且管道有同步互斥机制,但是共享内存没有任何的保护机制,所以需要额外添加,工作量再次提升
六,System V 信号量(了解)
(System V 消息队列现在用的非常少,所以这里就不介绍了,感兴趣的小伙伴可以参考别人的博客哟~)
6.1 关于信号量
我们学习一个东西首先肯定是要先去了解它是什么东西,才能去深入了解它。
下面是一个场景,能帮助我们更好理解什么是信号量:
①一个电影院,有个影厅只有一个座位,每次只能有一个人坐在上面看电影,其他人不许进来,这叫做互斥。人坐在座位上面看电影,相当于临界区代码访问临界资源,然后在放映的电影相当于临界资源。
②但是没有哪个电影院一个厅只有一个座位,而且看电影前需要买票
③座位相当于放映厅里的一个资源,那么这个座位是否属于你,是不是只要你坐在这个座位上这个座位就属于你呢?肯定不是,因为可能会有多个人为了争夺一个座位而争吵(数据不一致问题)
④所以要先买票,只要我买了票,我就拥有了这个座位,所以买票的本质就是:对座位的“预定”机制
⑤所以每一个进程要想访问临界资源的一部分,不能让进程直接去访问(不能让顾客没买票就直接去电影院占座位),需要让进程先申请信号量!(先去买票)
所以,信号量的本质就是一种“买票”机制,而一个放映厅的座位数有限,所以电影票也是有限的,卖出一张少一张;信号量也是如此,它本质类似于一个计数器(int count = n),进程申请信号量其实也就是count--,一旦申请信号量成功,临界资源内部一定给你预留了你想要的资源,而释放信号量就是count++
6.2 信号量注意事项
①既然信号量是一个计数器,那么我把信号量直接存在共享内存里,然后多个进程都进行申请信号量可以吗?不行,因为共享内存没有同步互斥机制;然后呢?没有同步互斥机制带来的问题是什么呢?
②假设两个进程client和server都要对n++,会出问题。n++是一种数据晕眩,而在计算机中只有CPU才能进行运算,而数据存在n变量里
③CPU执行运算指令至少三个步骤:1,将内存中的数据加载到CPU寄存器中(读指令) 2,对n进行++(分析和执行指令) 3,CPU将修改完的数据再写回n(写回结果)。因为在汇编角度,单独一个n++会被编译成三条指令
④执行流在执行的时候在任何时候都可能会被切换,由操作系统的调度器决定,但是CPU可能只有一个且被所有执行流共享,但是每个执行流存在寄存器里的上下文数据只属于单独一个执行流。在进程被切换的时候是会进行“上下文保护”和“上下文恢复”的
⑤回到上面的场景,n为5,假设client和server都对n--,但是client进程在运行--时被切换走了,于是CPU把n的值(5)和client的上下文数据都放寄存器里保存起来了,这时候server依旧n--,当n变成4的时候,server被切走,保存n(4)和server的上下文数据,client回来了,把n(5)的数据恢复上去,重新对n进行--,减完后依旧是4,然后把4写回到内存去了,之后server回来了,它的n也是4,于是它也把4写回到内存,这样一顿操作下来,两个进程都多n--了, 但是最终n的值是4
⑥上面的只是数据不一致的一种最简单的情况,假设进程一多,要计算的值也变多,就会造成大面积的数不一致问题,所以操作系统是不能容忍的。所以退出了“原子性”的概念
⑦所谓“原子性”就是“要么做完,要么不做”,具体我们到多线程再讲
总结:
信号量本质是计数器,是对临界资源的“预定”机制
申请信号量 --> 计数器减减 --> p操作 --> 必须是原子的
释放信号量 --> 计数器加加 --> v操作 --> 也必须是原子的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









