






一、实验目的
- 理解不同体系结构风格的具体内涵。
- 学习体系结构风格的具体实践。
二、实验环境
硬件: 计算机一台(win7 64位)
软件:Java语言,IntelliJ IDEA
三、实验内容
“上下文关键字”KWIC(Key Word in Context,文本中的关键字)检索系统接受有序的行集合:每一行是单词的有序集合;每一个单词又是字母的有序集合。通过重复地删除行中第一个单词,并把它插入行尾,每一行可以被“循环地移动”。KWIC检索系统以字母表的顺序输出一个所有行循环移动的列表。
尝试用不同的策略实现这个系统。选择2-3种体系结构风格来实现。
四、实验步骤
1、面向对象风格
1、体系结构图:

2、简述体系结构各部件的主要功能,实现思想。
上述的面向对象的方法,分为三个对象,四个函数:
inputFile:存放文本里的单词对象
line:存放inputFile中的值的对象
kwicList:存放结果的对象
fileopen():从text中读取数据
readLine():获取inputFile中的每一行
parseLine():对line的数据进行循环排序
printOut():打印kwicList的值
3、主要的代码
import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.StringTokenizer; public class KWIC { private static BufferedReader inputFile; private List<String> kwicList; public KWIC (String filename) { kwicList = new ArrayList<String>(); String line=""; fileopen(filename); while (line!= null) { line= readline(); if (line !=null) { parseLine(line, kwicList); } } printOut(kwicList); } public static void fileopen(String InputFilename) { try { inputFile = new BufferedReader(new FileReader(InputFilename)); } catch (IOException e) { System.err.println(("File not open" + e.toString())); System.exit(1); } } public static String readline() { String line =""; try { line = inputFile.readLine(); } catch (Exception e) { e.getStackTrace(); } return line; } public void parseLine(String line,List<String> list) { StringTokenizer tokener = new StringTokenizer(line); String token = new String(); int index; ArrayList<String> tokens = new ArrayList<String>(); int count = tokener.countTokens(); for (int j = 0; j < count; j++) { token = tokener.nextToken(); tokens.add(token); } //对List中的字进行循环移位 for (int i = 0; i < count; i++) { index=i; StringBuffer linebuffer = new StringBuffer(); for (int j = 0; j < count; j++) { if (index >= count) index = 0; linebuffer.append(tokens.get(index)); linebuffer.append(" "); index++; } line = linebuffer.toString(); kwicList.add(line); } //对List中的字进行排序
for (int i = 0; i < kwicList.size()-1; i++) { for (int j = 0; j < kwicList.size()-i-1; j++) { if (kwicList.get(j).compareToIgnoreCase(kwicList.get(j+1)) > 0){ String string = kwicList.get(j+1); kwicList.set(j+1,kwicList.get(j)); kwicList.set(j,string); } } } } public static void printOut(List<String> List) { System.out.println("---------Output---------"); for (int count = 0; count < List.size(); count++) { System.out.println (List.get(count)); } } public static void main(String[] args) { new KWIC("test.txt"); } }
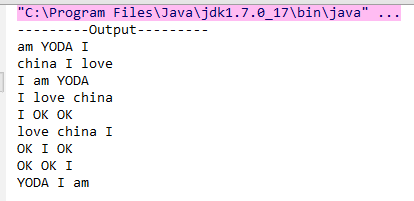
4、显示结果:

2、管道过滤器风格
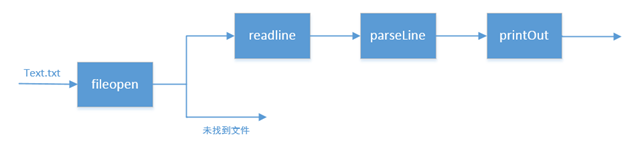
1、体系结构图:
2、简述体系结构各部件的主要功能,实现思想。
上述的管道过滤器风格,分为四个过滤器:
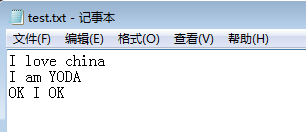
fileopen:从text.txt中读取数据,将结果输出
readLine:获取inputFile中的每一行
parseLine:对readLine的数据进行循环排序
printOut:对parseLine进行打印输出
3、主要的代码
import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.StringTokenizer; public class PipKWIC { private static BufferedReader inputFile; private static List<String> kwicList; public static void fileopen(String InputFilename) { try { inputFile = new BufferedReader(new FileReader(InputFilename)); } catch (IOException e) { System.err.println(("File not open" + e.toString())); System.exit(1); } } public static String readline() { String line =""; try { line = inputFile.readLine(); } catch (Exception e) { e.getStackTrace(); } return line; } public static void parseLine(String line,List<String> list) { StringTokenizer tokener = new StringTokenizer(line); String token = new String(); int index; ArrayList<String> tokens = new ArrayList<String>(); int count = tokener.countTokens(); for (int j = 0; j < count; j++) { token = tokener.nextToken(); tokens.add(token); } //对List中的字进行循环移位 for (int i = 0; i < count; i++) { index=i; StringBuffer linebuffer = new StringBuffer(); for (int j = 0; j < count; j++) { if (index >= count) index = 0; linebuffer.append(tokens.get(index)); linebuffer.append(" "); index++; } line = linebuffer.toString(); kwicList.add(line); } //对List中的字进行排序 for (int i = 0; i < kwicList.size()-1; i++) { for (int j = 0; j < kwicList.size()-i-1; j++) { if (kwicList.get(j).compareToIgnoreCase(kwicList.get(j+1)) > 0){ String string = kwicList.get(j+1); kwicList.set(j+1,kwicList.get(j)); kwicList.set(j,string); } } } } public static void printOut(List<String> List) { System.out.println("---------Output---------"); for (int count = 0; count < List.size(); count++) { System.out.println (List.get(count)); } } public static void main(String[] args) { kwicList = new ArrayList<String>(); String line=""; fileopen("test.txt"); while (line!= null) { line= readline(); if (line !=null) { parseLine(line, kwicList); } } printOut(kwicList); } }
4、显示结果:

五、实验总结
实现排序的时候,相用List的sort排序,但是没有这个方法,所以就使用冒泡排序法实现。















 2428
2428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









